文章目录
- 🌷 1.索引
- ⭐️ 1.1 定义
- ⭐️ 1.2 为什么要用索引
- ⭐️ 1.3 作用
- ⭐️ 1.4 使用场景
- ⭐️ 1.5 使用
- 🍁 1.5.1 查看索引
- 🍁 1.5.2 创建索引
- 🍁 1.5.3 删除索引
- ⭐️ 1.6 创建索引的⽅式
- ⭐️ 1.7 选择索引的数据结构(面试常问)
- 🍁 1.7.1 HASH
- 🍁 1.7.2 ⼆叉搜索树
- 🍁 1.7.3 N叉搜索树,B 树
- 🍁 1.7.4 B+树
- ⭐️ 1.8 ⽤explain 查看执⾏计划
- 🍁 使用explain
- ⭐️ 1.9 索引覆盖
- ⭐️ 1.10 索引失效
- 🌷 2. 事务
- ⭐️ 2.1 为什么使用事务
- ⭐️ 2.2 事务的概念
- ⭐️ 2.3 使用
- ⭐️ 2.4 事务的特性
- ⭐️ 2.5 事务的隔离级别
- 🍁 2.5.1 什么是隔离级别?
- 🍁 2.5.2 mysql中的四种事务隔离级别
- 🍁 2.5.3 使用
- 🍁 2.5.4 不同隔离级别的现象
- 1. `脏读`
- 解决脏读问题:
- 2. `不可重复读`
- 解决不可重复读问题
- 3. `幻读`
🌷 1.索引
⭐️ 1.1 定义
索引:为了提高查询效率而使用一种数据结构把数据组织起来。可以把索引理解在书的⽬录或字典的检索表(拼⾳检索)。
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
⭐️ 1.2 为什么要用索引
为了提⾼查询效率。
这是⼀个是典型的以空间换时间的操作,刚才说了,创建索引也要占⼀定的空间,⽽且在数据新增和删除的时间开销还是⽐较⼤的,因为不但要更新数据⾏,还是更新索引
⽐如,⼀书本在修订的时候增加或删除了⼀部分内容,那么后⾯的内容对应的⻚码全都改变了,所以⽬录也要做相应的调整。
如果没有索引,那么查找时可能需要全整的遍历整个数据集,时间复杂度最坏就是O(N)
有了索引之后,就可以通过⻚码,快速定位⼀个范围,然后再这个⼩范围内去找,这时的时间复杂度就⼤⼤降低了。
⭐️ 1.3 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
⭐️ 1.4 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
数据量较大,且经常对这些列进行条件查询。- 该数据库表的
插入操作,及对这些列的修改操作频率较低。- 索引会
占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。索引一般创建在频繁查询的列上,且这个列中的值重复较少。
⭐️ 1.5 使用
🍁 1.5.1 查看索引
show index from 表名;
案例:查看学生表已有的索引
show index from student;

🍁 1.5.2 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引(字段名可以有多个,用逗号隔开,一个索引包含多个字段就叫组合索引)
create index 索引名 on 表名(字段名);
create index 索引名 on 表名(字段名1,字段名2...);
案例:创建班级表中,name字段的索引
create index idx_classes_name on classes(name);
🍁 1.5.3 删除索引
drop index 索引名 on 表名;
案例:删除班级表中name字段的索引
drop index idx_classes_name on classes;
⭐️ 1.6 创建索引的⽅式
- 创建
主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。 - ⼿动创建,业务中我想对学⽣的身份证号建⽴⼀个索引:
create index idx_student_idcard on student(idcard); - ⼀张表⾥⾄少会有⼀个索引
a. 如果⼀张表⾥没有主键,MySql会为每⼀⾏⽣成⼀个唯⼀的字段,并⽤这个字段当前做索引
b. 如果⼀张表⾥有主键,那么主键必然是索引,主键索引也叫聚簇索引, ⽽且⼀直存在这也是我们绝⼤部分情况下的使⽤场景
c. 如果⾃⼰⼿动创建索引,那会会为这个列或是列的组合(多个列)创建单独的索引,⾮聚簇索引 - 分类:
a. 按使⽤场景分:普通索引,主键索引,唯⼀索引,全⽂索引
b. 按数据组织⽅式分:聚簇索引,⾮聚索引
c. 还有⼀种数据查找过程中出现的现象叫索引覆盖
⭐️ 1.7 选择索引的数据结构(面试常问)
题外话:推荐一个做数据结构图的链接(非常好用!!!):
Data Structure Visualizations
🍁 1.7.1 HASH
查询和插⼊的时间复杂度是O(1).
Hash这种数据结构快是快,但是他不适合做数据库的索引,为什么叫呢?因为他不⽀持做范围查询,⼤于号⼩于号 between and 这种操作,是不⽀持的。
不清楚为什么不支持范围查询的朋友可以看一下这篇:哈希表
🍁 1.7.2 ⼆叉搜索树
⼆叉搜索树的时间复杂度是多少,O(logN), O(N)
红⿊树是O(logN),因为红⿊树可以动态调整树⾼,不会出现单边树的情况.
那红⿊适合不适合做索引底层的数据结构呢?
答:不适合, 为什么呢? ⼆叉搜索树的中序遍历是⼀个有序数组。
它没有办法控制树的⾼度,树的⾼度决定了磁盘的访问次数,咱们先这么理解,每向孩⼦节点访问⼀级,就发⽣了些磁盘IO,⽽在⼀个系统中,对性能影响最⼤的就是磁盘IO,所以就要有⼀种数据结构能有效控制树的⾼度。
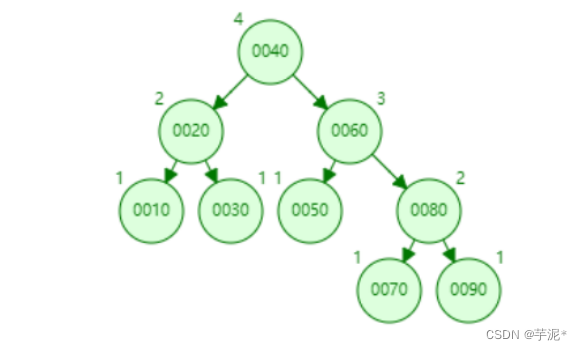
🍁 1.7.3 N叉搜索树,B 树
可以规定每⼀个节点可以存多少个元素,当节点中达到了规定的元素个数时,才去调整,B树就可以解决树⾼的问题,那么N叉搜索树可以做为索引的数据结构吗,看上去好像是可以的,但是Mysql没有选这种数据结构,⽽是在这B树的基础上⼜做了优化。
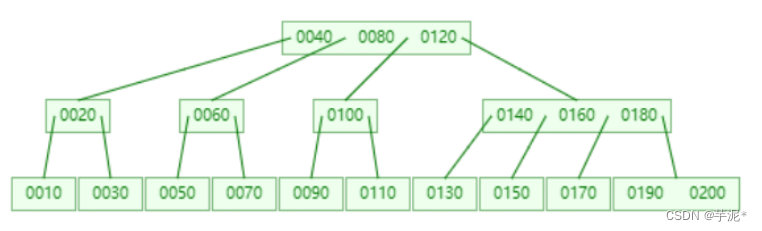
🍁 1.7.4 B+树

观察上图可以发现:
1️⃣ ⾮叶⼦节点中的每个数据都存在于叶⼦节点中,并且都是对应所在叶⼦节点中的第⼀条数据
2️⃣ Mysql中的B+树是⼀个循环双向链表,相邻节点是通过双向链表连接的,这样组织数据更有利⽤范围查找
3️⃣ 最重要的是,叶⼦节点中的数据是有序的,所以支持范围查找!
4️⃣ N叉搜索树,有效的降低了树的⾼度,从⽽减少了磁盘IO次数
5️⃣ 对于B+树⽽⾔,在相同树⾼的情况下,查找任⼀元素的时间复杂度都⼀样,中间⽐较次数也差不多,也就是说性能均衡,只要控制树⾼,就可以达到性能可控的效果
6️⃣ 只有叶⼦⻚点存储了真实完整的数据,⾮叶⼦⻚点,只保存了主键(索引)的值和⼦节点的引⽤
⭐️ 1.8 ⽤explain 查看执⾏计划
语法:
explain 查询语句;
案例:
explain select id,sn,name from student where id = 1 or sn = '09982' or qq_mail = '123';
explain select id,sn,name from student where id = 1 or sn = '09982';
explain select sn from student where sn = '09982';
以下全部详细解析explain各个属性含义:

各属性含义:
id:查询的序列号
select_type: 查询的类型,主要是区别普通查询和联合查询、⼦查询之类的复杂查询
- SIMPLE:查询中不包含⼦查询或者UNION,也就是单独的⼀条SQL
- 查询中若包含任何复杂的⼦部分,最外层查询则被标记为:PRIMARY
- 在SELECT或WHERE列表中包含了⼦查询,该⼦查询被标记为:SUBQUERY
table: 输出的⾏所引⽤的表
type:访问类型

从左⾄右,性能由差到好。
ALL:扫描全表index:扫描全部索引树range:扫描部分索引,索引范围扫描,对索引的扫描开始于某⼀点,返回匹配值域的⾏,常
⻅于between、<、>等的查询ref:使⽤⾮唯⼀索引或⾮唯⼀索引前缀进⾏的查找,不是主键或不是唯⼀索引
(eq_ref和const的区别:)eq_ref:唯⼀性索引扫描,对于每个索引键,表中只有⼀条记录与之匹配。常⻅于主键或唯⼀
索引扫描const, system:单表中最多有⼀个匹配⾏,查询起来⾮常迅速,例如根据主键或唯⼀索引查
询。system是const类型的特例,当查询的表只有⼀⾏的情况下, 使⽤system。NULL:不⽤访问表或者索引,直接就能得到结果,如:

possible_keys: 表示查询时可能使⽤的索引。如果是空的,没有相关的索引。这时要提⾼性能,可通过检验WHERE⼦句,看是否引⽤某些字段,或者检查字段不是适合索引
key: 显示MySQL实际决定使⽤的索引。如果没有索引被选择,是NULL
key_len: 使⽤到索引字段的⻓度
注:key_len显示的值为索引字段的最⼤可能⻓度,并⾮实际使⽤⻓度,即key_len是根据表定义计算⽽得,不是通过表内检索出的。
ref: 显示哪个字段或常数与key⼀起被使⽤
rows: 这个数表示mysql要遍历多少数据才能找到,表示MySQL根据表统计信息及索引选⽤情况,估算的找到所需的记录所需要读取的⾏数,在innodb上可能是不准确的
Extra: 执⾏情况的说明和描述。包含不适合在其他列中显示但⼗分重要的额外信息。
Using index:表示使⽤索引,如果只有 Using index,说明他没有查询到数据表,只⽤索引表就完成了这个查询,这个叫覆盖索引。Using where:表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where。
针对⾃定义或是普通索引、⾃定义索引组合索引⽽⾔
🍁 使用explain
(1)在student中创建索引
create index idx_sn_name on student(sn,name);

(2)执⾏查询计划
explain select * from student where sn = '09982';
① 查询所有使⽤主键索引
explain select * from student where id = 1;

② 查询所有使⽤了复合索引
- 有回表查询
explain select * from student where sn = '9982';
- ⽆回表查询(索引覆盖)
explain select sn student where sn = '09982';
explain select sn,name from student where sn = '09982';
explain select id,sn,name from student where sn = '09982';
⭐️ 1.9 索引覆盖
select name, mail from student where name = '张三' and mail = 'zs@163.com';
如果索引中包含要查询的所列,那么直接从索引中返回结果,这个现在叫做索引覆盖.
当查询列表中为*或索引不能完全满足查询满足,那么会使用id 到主键索引中查询完整的结果,主键索引中包含当前数据行中所有列的值
⭐️ 1.10 索引失效
create index idx_SM声⺟_YM韵⺟_SD声调 ON 字典(声⺟,韵⺟,声调);
最左原则:类似于字典的⽬录,这就是⼀个典型的复合索引判断不等:每个都要判断类型转换:与原类型不符like '%xxx':第⼀个字符都不能确定,怎么去索引中⽐较呢?索引列运算 age + 1:改了原来的值is null 或 is not null: 全表扫描了
🌷 2. 事务
⭐️ 2.1 为什么使用事务
准备测试表:
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('十四大盗', 1000);
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元。
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 十四大盗账户增加2000
update accout set money=money+2000 where name = '十四大盗';
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是十四大盗的账户上就没有了增加的金额。
解决:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败。
⭐️ 2.2 事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
⭐️ 2.3 使用
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
⭐️ 2.4 事务的特性
原⼦性(Atomicity)
事务中的SQL要么都执⾏要么都不执⾏,通过commit/rollback控制⼀致性(Consistency)
官⽹上描述:数据库从⼀个⼀致性状态变换到另外⼀个⼀致性状态。
事务执⾏之前与执⾏之后,要保持的正确的结果,可以⽤转账说明隔离性(Isolation)
多个事务执⾏的过程中不能互相⼲扰持久性(Durability)
事务⼀旦提交就会写⼊磁盘永久保留,即使是数据库服务故障也不会影响数据的内容
⭐️ 2.5 事务的隔离级别
MYSQL是以服务的形式发布⽹络上的,可以同时⽀持多个客户端的访问,那么多个客户端如果同时访问MYSQL时可能会出现互相影响的情况。
🍁 2.5.1 什么是隔离级别?
对并发访问的⼀种限制刚才介绍了,MYSQ可以被多个客户端访问,
如果隔离级别越低,那么可以⽀持同时访问的客户端数就越多,性能变⾼,数据安全性变低;如果隔离级别越⾼,那么可以⽀持同时访问的客户端数就越少,性能变低,数据安全性变⾼。
🍁 2.5.2 mysql中的四种事务隔离级别
read uncommitted(读未提交数据):允许事务读取未被其他事务提交的变更。(脏读、不可重复读和幻读的问题都会出现)。read committed(读已提交数据):只允许事务读取已经被其他事务提交的变更。(可以避免脏读,但不可重复读和幻读的问题仍然可能出现)repeatable read(可重复读):确保事务可以多次从一个字段中读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新(update)。(可以避免脏读和不可重复读,但幻读仍然存在)serializable(串行化):确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作,所有并发问题都可避免,但性能十分低下(因为你不完成就都不可以弄,效率太低)
隔离级别从低到⾼,“并发访问”的数据从⾼到低,数据安全性从低到⾼,性能越低
MYSQL默认的事务隔离级别是,可重复读。
🍁 2.5.3 使用
(1)查看当前事务的隔离级别
show variables like '%tx_isolation';
(2)修改事务的隔离级别
set @@global.tx_isolation = 'READ-UNCOMMITTED'; //全局
set @@session.tx_isolation = 'READ-UNCOMMITTED'; //当前session
set @@tx_isolation = 'READ-UNCOMMITTED'; //仅对下⼀个事务⽣效
🍁 2.5.4 不同隔离级别的现象
1. 脏读
事务B读到了另⼀个事务A还没有提交的数据,当事务A回滚后,事务中所有的修改都回滚了,那么事务B读到的数据就没有意义了,把这个称之为脏读。

解决脏读问题:
(1)给⼀个写操作的事务加上⼀把锁,在写这个事务从开始时加锁,事务提交或加滚的时候释放锁,被加锁的事务不能与其他事务共存,写锁也叫排他锁

(2)可以把当前数据库的隔离级别设置成READ-COMMITTED读已提交,就避免了脏读问题
2. 不可重复读
解决了脏读问题,⼜出现了新的问题,⽐如事务提交后对于这个事务来说就结束了,但是当⼀个新的事务A在读⼀条记录时,另⼀个事务B对这条记录做出了修改,当事务A再次读这条记录时,就发现两次读到的结果不⼀致,那么这种情况就是不可重复读
也就是当数据库的隔离级别为 READ-COMMITTED时,可能出现不可重复读的现象
解决不可重复读问题
(1)给读的事务也加上⼀把锁,但是这个锁是⼀把读锁(共享锁),多个读锁可以共存,但是由于写锁是排他锁,所以读锁不能与写锁共存,也就是说,在加了读锁之后,不能进⾏写操作。

(2)可以把当前数据库的隔离级别设置成REPEATABLE-READ,可以避免不可重复读问题。
3. 幻读
解决了不可重复读问题,也就是说对于⼀条记录来说,在读的时候别的事务不能修改这条记录,但是可以添加别的记录,那么当事务A对某记录进⾏修改的时候,事务B往这个表中添加了条新的记录,当然也可以删除,那么事务A再去查询所有记录时,发现与上⼀次查到的所有记录条数不⼀致,或多或少,这种现象就是幻读。
MySQL数据事务的默认隔离级别虽然是可重复读,但是最⼤限度的解决了幻读问题,但是并没有完全解决,有些场景还是会出现幻读现象,这个⼤家⼼⾥要有⼀个认识,如果要彻底解决幻读问题,那么只能把事务的隔离级别设置成SERIALIZABLE,也就是串⾏化,那事务⼀下接⼀个的执⾏,全完放弃并发执⾏,那么效率也就会变的低,但是是最安全的。