目录
一、环境要求
二、提交结果要求
三、数据描述
四、功能要求
1.数据准备
2.使用 Spark,加载 HDFS 文件系统 meituan_waimai_meishi.csv 文件,并分别使用 RDD和 Spark SQL 完成以下分析(不用考虑数据去重)。
(1)配置环境
(2)RDD加载文件
①统计每个店铺分别有多少商品(SPU)。
②统计每个店铺的总销售额。
③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
(3) SparkSQL解析上面的需求
3.创建 HBase 数据表
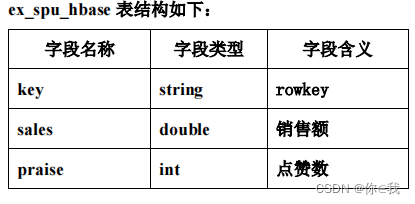
4. 请 在 Hive 中 创 建 数 据 库 spu_db ,在 该 数 据 库 中 创 建 外 部 表 ex_spu 指 向/app/data/exam 下的测试数据 ;创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu表的 result 列族
5. 统计查询
一、环境要求
Hadoop+Hive+Spark+HBase 开发环境。
二、提交结果要求
1.必须提交源码或对应分析语句,如不提交则不得分。
2.带有分析结果的功能,请分析结果的截图与代码一同提交。
三、数据描述
meituan_waimai_meishi.csv 是美团外卖平台的部分外卖 SPU(Standard Product Unit ,标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下:
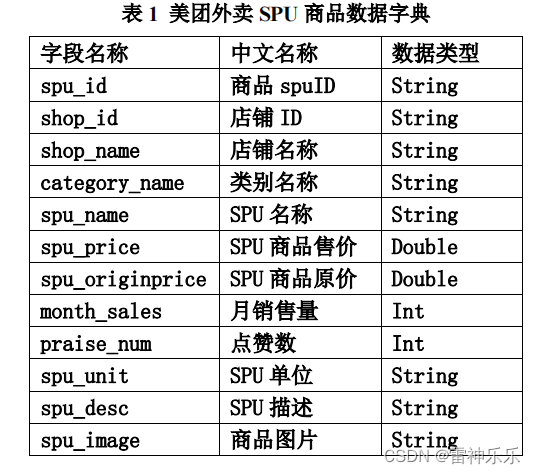
四、功能要求
1.数据准备
请在 HDFS 中创建目录/app/data/exam,并将 meituan_waimai_meishi.csv 文件传到该目录。并通过 HDFS 命令查询出文档有多少行数据。
# 开启hadoop集群
start-all.sh
# 递归创建目录
hdfs dfs -mkdir -p /app/data/exam
# 上传文件到目录
hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam
# 查看文件总行数
hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
983
# 查看头文件
hdfs dfs -head /app/data/exam/meituan_waimai_meishi.csv
spu_id,shop_id,shop_name,category_name,spu_name,spu_price,spu_originprice,month_sales,praise_num,spu_unit,spu_desc,spu_image
2.使用 Spark,加载 HDFS 文件系统 meituan_waimai_meishi.csv 文件,并分别使用 RDD和 Spark SQL 完成以下分析(不用考虑数据去重)。
(1)配置环境
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[1]").setAppName("SparkSQL01_Demo")
//创建 SparkSession 对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._(2)RDD加载文件
val fileRDD: RDD[String] = sc.textFile("hdfs://lxm147:9000/app/data/exam/meituan_waimai_meishi.csv")
println(fileRDD.count())// 983①统计每个店铺分别有多少商品(SPU)。
split(",")与split(",",-1)的区别:
val a: RDD[String] = sc.parallelize(List("a,b,c", "a,b,c,d", "a,b,,,"))
a.map(x => x.split(",")).foreach(x => println(x.toList))
/*
List(a, b, c, d)
List(a, b, c)
List(a, b)*/
a.map(x => x.split(",", -1)).foreach(x => println(x.toList))
/*
List(a, b, c, d)
List(a, b, c)
List(a, b,,,)*/
val b: RDD[String] = sc.parallelize(List("a,b,c", "a,b,c,d", "a,b,,,g"))
b.map(x => x.split(",", -1)).foreach(x => println(x.toList))
/*
List(a, b, c, d)
List(a, b, c)
List(a, b,,, g)*/过滤数据:
// TODO 过滤数据
val spuRDD: RDD[Array[String]] = fileRDD
.filter(x => !x.startsWith("spu_id")) // 过滤首行
.map(x => x.split(",", -1)) // 拆分csv文件
.filter(x => x.length == 12)
// 第一行已经过滤掉了
println(spuRDD.count())// 982
spuRDD.foreach(x => println(x.toList))
/*List(1400227781, 966888510343524, 蒙阁轩羊肉焖面, 凉菜, 酸辣鱼皮, 22.0, 22.0, 0, 0, , , http://p0.meituan.net/xianfudwm/1debda2746fe8cca6e786b110c70e86b210255.jpg)
List(1400267216, 966888510343524, 蒙阁轩羊肉焖面, 凉菜, 蒜片乳瓜, 12.0, 12.0, 0, 0, , , http://p0.meituan.net/xianfudwm/0f3de1f3e412d65210ce725b80dfaa76141214.jpg)
List(1400227743, 966888510343524, 蒙阁轩羊肉焖面, 凉菜, 椒圈花生米, 20.0, 20.0, 0, 0, , , http://p1.meituan.net/xianfudwm/a16f929f8a121d36a7daa5a9e835afe7180379.jpg)
*/计算店铺SPU:
spuRDD.map(x => (x(2), 1))
.reduceByKey(_ + _) // 相同的店铺名为key,后面的1累加
.foreach(println)
/*
(万和祥羊肉馆户县店,29)
(青木土豆粉,17)
(老城红油米线(丰润美食城店),23)
(蒙阁轩羊肉焖面,71)
(冰火虾神小龙虾(西影路店),102)
(喜辣屋泡泡鱼(小寨店),48)
(鄠邑印象小厨,85)
(老台门(百脑汇店),72)
(悦香驴蹄子面(曲江大悦城店),18)
(尚品米洛克,36)
(一菜一味,40)
(人人家美食城,113)
(中国兰州拉面(乐居场店),136)
(云锦港式烧腊饭,42)
(煲状元煲仔饭,32)
(三顾冒菜(曼城国际店),92)
(强社包子铺,26)*/②统计每个店铺的总销售额。
import scala.util._
spuRDD.map(x => (x(2), Try(x(5).toDouble).toOption.getOrElse(0.0) * Try(x(7).toInt).toOption.getOrElse(0)))
// 如果转换出错就toOption,如果没有值,就返回0.0;如果x(7)转换异常就返回0
.reduceByKey(_ + _) // 相同店铺的销售额累加
.filter(x => x._2 > 0) // 过滤掉没有销售额的店铺
.foreach(println)
/*
(万和祥羊肉馆户县店,633.0)
(蒙阁轩羊肉焖面,972.0)
(冰火虾神小龙虾(西影路店),4919.099999999999)
(喜辣屋泡泡鱼(小寨店),3901.0)
(鄠邑印象小厨,3676.0)
(老台门(百脑汇店),6250.199999999999)
(悦香驴蹄子面(曲江大悦城店),222.0)
(一菜一味,2297.0)
(中国兰州拉面(乐居场店),842.0)
(云锦港式烧腊饭,144.0)
(煲状元煲仔饭,3728.0)
(三顾冒菜(曼城国际店),9497.7)
(强社包子铺,3389.08)
*/③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
方法一:
// todo 方法一:
spuRDD.map(x => (x(2), x(3), Try(x(5).toDouble).toOption.getOrElse(0.0) * Try(x(7).toInt).toOption.getOrElse(0)))
.filter(_._3 > 0)
.groupBy(x => x._1) // 相同的店铺分组,遍历出一个二元组
.flatMapValues(_.toList.sortBy(-_._3).take(3)) // 二元组中第二个元素的第三个值进行排序
.map(_._2) // 只遍历二元组中第二个元素
.foreach(println)方法二:
// TODO 方法三:
spuRDD.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) * Try(x(7).toInt).toOption.getOrElse(0)))
.filter(x => x._3 > 0)
/*
店铺名 商品名 销售额
(蒙阁轩羊肉焖面,排骨焖面,90.0)
(蒙阁轩羊肉焖面,羊肉焖面,286.0)
(蒙阁轩羊肉焖面,酸菜炒土豆粉,16.0)
(蒙阁轩羊肉焖面,姜汁皮蛋,13.0)
(蒙阁轩羊肉焖面,西红柿鸡蛋拌面,14.0)*/
.groupBy(x => x._1)
// 分组后就是一个二元组
// (强社包子铺,
// CompactBuffer((强社包子铺,芹菜酸菜包,253.00000000000003),
// (强社包子铺,胡萝卜丝,64.0),
// (强社包子铺,蒸红薯,30.0),
// (强社包子铺,菜疙瘩,77.0)))
.map(x => {
val shop_name: String = x._1;
val topThree: List[(String, String, Double)] = x._2.toList.sortBy(-_._3).take(3)
val shopNameAndSumMoney: List[String] = topThree.map(it => it._2 + "\t" + it._3)
shopNameAndSumMoney.flatMap(x => x.split(","))
(shop_name, shopNameAndSumMoney)
})方法三:
spuRDD.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) * Try(x(7).toInt).toOption.getOrElse(0)))
.filter(_._3 > 0)
.groupBy(_._1)
// TODO 这里使用flatMap和mapValues都可以
// todo flatMap中进来的是key和value的二元组
// todo flatMapValues中进来的是二元组中的value
.flatMap(x => x._2.toList.sortBy(-_._3).take(3))
/*(强社包子铺,香葱大肉包,329.6)
(强社包子铺,香葱大肉包,329.6)
(强社包子铺,芹菜酸菜包,253.00000000000003)*/
// .mapValues(value => value.toList.sortBy(x => 0 - (x._3)).take(3))
/*
(万和祥羊肉馆户县店,List(
(万和祥羊肉馆户县店,水盆羊杂,240.0),
(万和祥羊肉馆户县店,辣子炒羊血,120.0),
(万和祥羊肉馆户县店,优质水盆羊肉,96.0),
(万和祥羊肉馆户县店,特色炒肉片(牛肉),78.0),
(万和祥羊肉馆户县店,月牙烤饼,46.0),
(万和祥羊肉馆户县店,烩羊肉,38.0),
(万和祥羊肉馆户县店,素拼凉菜,15.0)))*/
// TODO 这里使用flatMap和flatMap都可以
// .flatMapValues(x=>x)
/*
(强社包子铺,(强社包子铺,香葱大肉包,329.6))
(强社包子铺,(强社包子铺,香葱大肉包,329.6))
(强社包子铺,(强社包子铺,芹菜酸菜包,253.00000000000003))*/
// .flatMap(x => x._2)
/*(强社包子铺,香葱大肉包,329.6)
(强社包子铺,香葱大肉包,329.6)
(强社包子铺,芹菜酸菜包,253.00000000000003)*/
// .map(_._2)
/*
(强社包子铺,香葱大肉包,329.6)
(强社包子铺,香葱大肉包,329.6)
(强社包子铺,芹菜酸菜包,253.00000000000003)*/
.foreach(println)(3) SparkSQL解析上面的需求
// TODO SparkSQL操作
val spuDF: DataFrame = spark.read.format("csv").option("header", value = true).option("inferSchema", value = true).load("hdfs://lxm147:9000/app/data/exam/meituan_waimai_meishi.csv")
spuDF.printSchema()
/*root
|-- spu_id: integer (nullable = true)
|-- shop_id: long (nullable = true)
|-- shop_name: string (nullable = true)
|-- category_name: string (nullable = true)
|-- spu_name: string (nullable = true)
|-- spu_price: double (nullable = true)
|-- spu_originprice: double (nullable = true)
|-- month_sales: integer (nullable = true)
|-- praise_num: integer (nullable = true)
|-- spu_unit: string (nullable = true)
|-- spu_desc: string (nullable = true)
|-- spu_image: string (nullable = true)*/
spuDF.show(5,truncate = false)
/*
+----------+----------------+--------------------------+-------------+------------------------+---------+---------------+-----------+----------+--------+-----------------------------------------------+---------------------------------------------------------------------------+
|spu_id |shop_id |shop_name |category_name|spu_name |spu_price|spu_originprice|month_sales|praise_num|spu_unit|spu_desc |spu_image |
+----------+----------------+--------------------------+-------------+------------------------+---------+---------------+-----------+----------+--------+-----------------------------------------------+---------------------------------------------------------------------------+
|907742996 |1036149152976425|冰火虾神小龙虾(西影路店)|折扣 |爆款麻辣小龙虾 ±20g/只 1|55.06 |88.8 |3 |0 |斤 |克重:±20g/只,不吃龙虾辜负胃,狂撸三斤不嫌累!|http://p1.meituan.net/wmproduct/022b0eec55c894ee64b6faa4382163a91424176.jpg|
|1355635876|1036149152976425|冰火虾神小龙虾(西影路店)|折扣 |爆款蒜香小龙虾 |59.5 |88.8 |1 |0 |null |克重:±20g只,不吃龙虾辜负胃,狂撸三斤不嫌累。 |http://p0.meituan.net/wmproduct/d2528c410dc183eeb61299803611dcca169083.jpg |
|844976891 |1036149152976425|冰火虾神小龙虾(西影路店)|折扣 |麻辣小龙虾 ±20g/只 1斤 |59.5 |88.8 |4 |0 |斤 |克重:±20g/只,不吃龙虾辜负胃,狂撸三斤不嫌累!|http://p0.meituan.net/wmproduct/af63ec8d3af74546331c868f978956c21628800.jpg|
|844977553 |1036149152976425|冰火虾神小龙虾(西影路店)|折扣 |麻辣小龙虾 ±25g/只 1斤 |70.15 |98.8 |4 |0 |斤 |克重:±25g/只,不吃龙虾辜负胃,狂撸三斤不嫌累!|http://p0.meituan.net/wmproduct/af63ec8d3af74546331c868f978956c21628800.jpg|
|898263414 |1036149152976425|冰火虾神小龙虾(西影路店)|折扣 |卤辣小龙虾 ±25g/只 1斤 |70.15 |98.8 |3 |0 |斤 |克重:±25g/只,不吃龙虾辜负胃,狂撸三斤不嫌累!|http://p1.meituan.net/wmproduct/989af3988e547e5448887f006ce2c85a1358387.jpg|
+----------+----------------+--------------------------+-------------+------------------------+---------+---------------+-----------+----------+--------+-----------------------------------------------+---------------------------------------------------------------------------+
*/
// TODO ①统计每个店铺分别有多少商品(SPU)。
spuDF.createOrReplaceTempView("sputb")
spark.sql("select shop_name,count(spu_name) as num from sputb group by shop_name").show(false)
/*
+----------------------------+---+
|shop_name |num|
+----------------------------+---+
|冰火虾神小龙虾(西影路店) |102|
|悦香驴蹄子面(曲江大悦城店) |18 |
|蒙阁轩羊肉焖面 |71 |
|万和祥羊肉馆户县店 |29 |
|一菜一味 |40 |
|尚品米洛克 |36 |
|鄠邑印象小厨 |85 |
|云锦港式烧腊饭 |42 |
|老城红油米线(丰润美食城店) |23 |
|人人家美食城 |113|
|喜辣屋泡泡鱼(小寨店) |48 |
|青木土豆粉 |17 |
|老台门(百脑汇店) |72 |
|三顾冒菜(曼城国际店) |92 |
|中国兰州拉面(乐居场店) |136|
|煲状元煲仔饭 |32 |
|强社包子铺 |26 |
+----------------------------+---+*/
// TODO ②统计每个店铺的总销售额。
spark.sql(
"""
|select
| shop_name,
| sum(spu_price*month_sales) as sumMoney
| from sputb
| group by
| shop_name
|""".stripMargin)
.show(false)
/* +----------------------------+-----------------+
|shop_name |sumMoney |
+----------------------------+-----------------+
|冰火虾神小龙虾(西影路店) |4919.099999999999|
|悦香驴蹄子面(曲江大悦城店)|222.0 |
|蒙阁轩羊肉焖面 |972.0 |
|万和祥羊肉馆户县店 |633.0 |
|一菜一味 |2297.0 |
|尚品米洛克 |0.0 |
|鄠邑印象小厨 |3676.0 |
|云锦港式烧腊饭 |144.0 |
|老城红油米线(丰润美食城店)|0.0 |
|人人家美食城 |0.0 |
|喜辣屋泡泡鱼(小寨店) |3901.0 |
|青木土豆粉 |0.0 |
|老台门(百脑汇店) |6250.199999999999|
|三顾冒菜(曼城国际店) |9497.7 |
|中国兰州拉面(乐居场店) |842.0 |
|煲状元煲仔饭 |3728.0 |
|强社包子铺 |3389.08 |
+----------------------------+-----------------+*/
// TODO ③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
// todo 开窗函数
spark.sql(
"""
|select
| t.shop_name,
| t.spu_name,
| t.money
|from (
|select
| shop_name,
| spu_name,
| spu_price*month_sales as money,
| row_number() over(partition by shop_name order by spu_price*month_sales desc) rn
|from sputb
|where month_sales <> 0 ) t
|where t.rn <=3
|""".stripMargin)
.show(false)
/*
+----------------------------+----------------------------+-----+
|shop_name |spu_name |money|
+----------------------------+----------------------------+-----+
|冰火虾神小龙虾(西影路店) |冰火虾神套餐A |396.0|
|冰火虾神小龙虾(西影路店) |冰火虾神套餐A |396.0|
|冰火虾神小龙虾(西影路店) |麻辣小龙虾 ±25g/只 1斤 |280.6|
|悦香驴蹄子面(曲江大悦城店)|经典全套 |60.0 |
|悦香驴蹄子面(曲江大悦城店)|经典全套 |60.0 |
|悦香驴蹄子面(曲江大悦城店)|油泼四合一 |36.0 |
|蒙阁轩羊肉焖面 |瘦肉焖面 |352.0|
|蒙阁轩羊肉焖面 |羊肉焖面 |286.0|
|蒙阁轩羊肉焖面 |鸡块焖面 |176.0|
|万和祥羊肉馆户县店 |水盆羊杂 |240.0|
|万和祥羊肉馆户县店 |辣子炒羊血 |120.0|
|万和祥羊肉馆户县店 |优质水盆羊肉 |96.0 |
|一菜一味 |肉沫粉条 |273.0|
|一菜一味 |鱼香肉丝 |190.0|
|一菜一味 |米饭 |182.0|
|鄠邑印象小厨 |红烧肉 |384.0|
|鄠邑印象小厨 |老碗鱼 |348.0|
|鄠邑印象小厨 |茶树菇爆牛柳 |234.0|
|云锦港式烧腊饭 |叉烧拼玫瑰豉油鸡+烤鸭蛋+例汤|72.0 |
|云锦港式烧腊饭 |叉烧拼玫瑰豉油鸡+烤鸭蛋+例汤|72.0 |
+----------------------------+----------------------------+-----+*/3.创建 HBase 数据表
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有1个列族 result。
开启服务:
[root@lxm147 data]# zkServer.sh start
JMX enabled by default
Using config: /opt/soft/zookeeper345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@lxm147 data]# start-hbase.sh
running master, logging to /opt/soft/hbase235/logs/hbase-root-master-lxm147.out
: running regionserver, logging to /opt/soft/hbase235/logs/hbase-root-regionserver-lxm147.out
[root@lxm147 data]# nohup hive --service metastore &
[root@lxm147 data]# nohup hive --service hiveserver2 &
[root@lxm147 data]# jps
3362 SparkSubmit
6338 Jps
6068 RunJar
1589 DataNode
1814 SecondaryNameNode
5110 QuorumPeerMain
2248 NodeManager
1449 NameNode
2111 ResourceManager
5359 HMaster
5567 HRegionServer
[root@lxm147 data]# hbase shell
创建命名空间、表和列簇:
hbase(main):003:0> create_namespace 'exam'
Took 0.2503 seconds
hbase(main):004:0> list_namespace
NAMESPACE
bigdata
default
exam
hbase
kb21
5 row(s)
Took 0.0303 seconds
hbase(main):005:0> create 'exam:spu','result'
Created table exam:spu
Took 2.3437 seconds
=> Hbase::Table - exam:spu
4. 请 在 Hive 中 创 建 数 据 库 spu_db ,在 该 数 据 库 中 创 建 外 部 表 ex_spu 指 向/app/data/exam 下的测试数据 ;创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu表的 result 列族
show databases;
create database if not exists spu_db;
use spu_db;
-- 创建外部表
create external table if not exists ex_spu
(
spu_id string,
shop_id string,
shop_name string,
category_name string,
spu_name string,
spu_price double,
spu_originprice double,
month_sales int,
praise_num int,
spu_unit string,
spu_desc string,
spu_image string
) row format delimited fields terminated by ","
stored as textfile location "/app/data/exam"
tblproperties ("skip.header.line.count" = "1");
set mapreduce.framework.name=local;
select count(*)
from ex_spu; -- 982
create external table if not exists ex_spu_hbase
(
key string,
sales double,
praise int
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = ":key,result:sales,result:praise")
tblproperties ("hbase.table.name" = "exam:spu");5. 统计查询
① 统计每个店铺的总销售额 sales, 店铺的商品总点赞数 praise,并将 shop_id 和shop_name 的组合作为 RowKey,并将结果映射到 HBase。
insert into ex_spu_hbase
select concat(tb.shop_id, tb.shop_name) as key,
tb.sales,
tb.praise
from (
select shop_id,
shop_name,
sum(spu_price * month_sales) as sales,
sum(praise_num) as praise
from ex_spu
group by shop_id, shop_name) tb;
select * from ex_spu_hbase;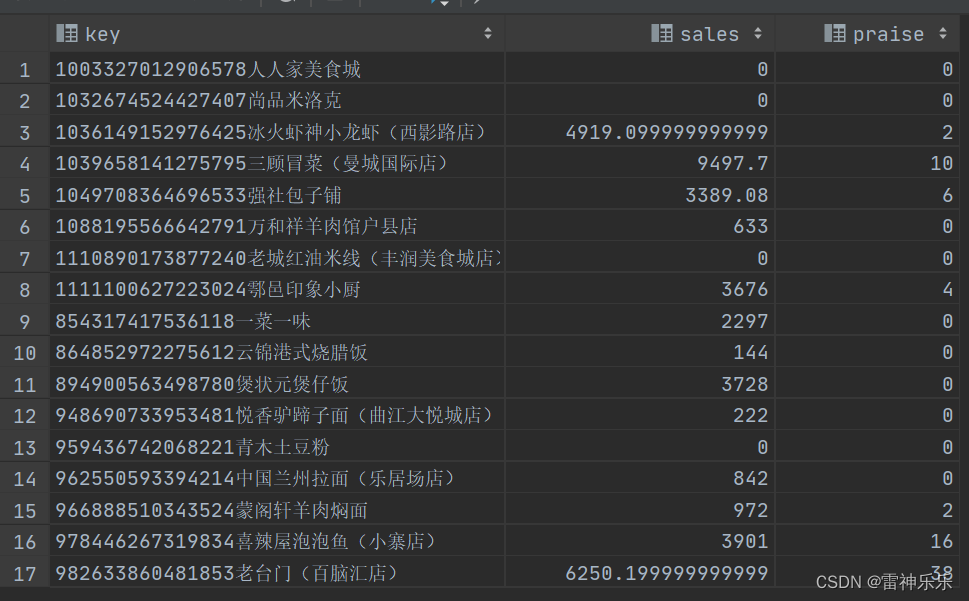
② 完成统计后,分别在 hive 和 HBase 中查询结果数据。
hbase(main):002:0> scan 'exam:spu'