一.为什么要使用数据库?
在我们平时存储数据的时候,往往采用文件存储即可,所以,为什么要使用数据库呢?
原因在于,文件存储数据有以下缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
为了解决上述问题,我们创造了更适合存储数据的软件——数据库.它的存储介质是磁盘或内存,能更有效的管理数据。
数据库可以提供远程服务,即通过远程连接来使用数据库,因此也称为数据库服务器.
二.数据库
1.数据库的分类
数据库可以分为关系数据库和非关系数据库
关系数据库:
关系型数据库指的是使用关系模型(二维表格模型)来组织数据的数据库。
常见关系型数据库管理系统(ORDBMS):
- Oracle
- MySql
- Microsoft SQL Server
- SQLite
- PostgreSQL
- IBM DB2
非关系数据库 :
非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。
常见的NOSQL数据库:
- 键值数据库:Redis、Memcached、Riak
- 列族数据库:Bigtable、HBase、Cassandra
- 文档数据库:MongoDB、CouchDB、MarkLogic
- 图形数据库:Neo4j、InfoGrid
| 关系数据库 | 非关系数据库 | |
|---|---|---|
| 使用SQL | 是 | 一般不使用 |
| 事务支持 | 支持 | 不支持 |
| 复杂操作 | 支持 | 不支持 |
| 海量读写操作 | 效率低 | 效率高 |
| 基本结构 | 基于表和列,结构稳定 | 灵活性比较高 |
| 使用场景 | 业务方面的OLTP系统 | 用于数据的缓存或基于统计分析的OLAP系统 |
2.数据库的操作
2.1数据库的操作
2.1.1显示当前数据库
show databases;2.1.2创建数据库
create database 数据库名;2.1.3使用数据库
use 数据库名;2.1.4删除数据库
drop 数据库名;2.2常见数据类型
2.2.1数值类型
分为整型和浮点型(只列举较常用类型)
| 数据类型 | 大小 | 对应Java类型 |
|
BIT[ (M) ]
|
M
指定位数,默认 为1
|
常用
Boolean
对应
BIT
,此时
默认是
1
位,即只能存
0
和1
|
| INT | 4字节 |
Integer
|
|
DECIMAL(M, D)
|
M/D
最大值+2
|
BigDecimal
|
2.2.2字符串类型
| 数据类型 | 大小 | 对应Java类型 |
|
VARCHAR (SIZE)
|
0-65,535
字节
| String |
| TEXT | 0-65,535字节 | String |
2.2.3日期类型
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| DATATIME | 8字节 |
范围从
1000
到
9999
年,不会进行时区的检索及转换
|
java.util.Date
、
java.sql.Timestamp
|
| TIMESTAMP | 4字节 |
范围从
1970
到
2038
年,自动检索当前时区并进行转换。
|
java.util.Date
、
java.sql.Timestamp
|
2.3表的操作
需要操作数据库中的表的时候,需要先使用该数据库
use 数据库名;2.3.1查看表的结构
desc 表名;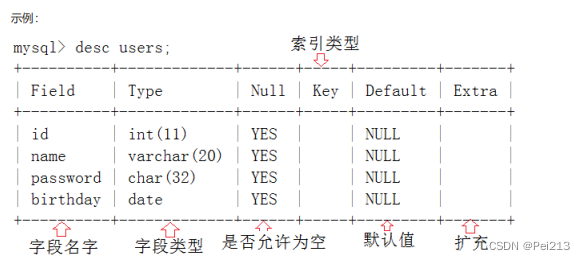
2.3.2创建表
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
);2.3.3删除表
drop table 表名;2.3.4新增
insert into 表名 values(值,值...);
insert into 表名(列名,列名...) values(值,值...),(值,值...)...;2.3.5查询
1.指定列查询
select * from 表名;
2.指定列查询
select 列名,列名...from 表名;
3.表达式查询
select 列名+表达式 from 表名;
4.指定别名查询
select 列名+列名+... as 别名 from 表名;
5.去重查询
select distinct 列名 from 表名;
6.查询结果排序
select 列名,列名... from 表名 order by 列名1,order by 列名2...;
6.1降序排序
select 列名,列名... from 表名 order by 列名 desc;
6.2升序排序
select 列名,列名... from 表名 order by 列名 asc;
7.条件查询:where
比较运算符:
| 运算符 | 说明 |
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = |
等于,
NULL
不安全,例如
NULL = NULL
的结果是
NULL
|
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=,<> | 不等于 |
| BETWEEN a0 AND a1 |
范围匹配,
[a0, a1]
,如果
a0 <= value <= a1
,返回
TRUE(1)
|
| IN(option,...) |
如果是
option
中的任意一个,返回
TRUE(1)
|
|
IS NULL
|
是 NULL
|
|
IS NOT NULL
|
不是
NULL
|
|
LIKE
|
模糊匹配。% 表示任意多个(包括
0
个)任意字符;
_
表示任意一个字符
|
逻辑运算符:
| 运算符 | 说明 |
| AND |
多个条件必须都为
TRUE(1)
,结果才是
TRUE(1)
|
| OR |
任意一个条件为
TRUE(1),
结果为
TRUE(1)
|
| NOT |
条件为
TRUE(1)
,结果为
FALSE(0)
|
8.分页查询:LIMIT
limit用来限制每次查询的结果是几个
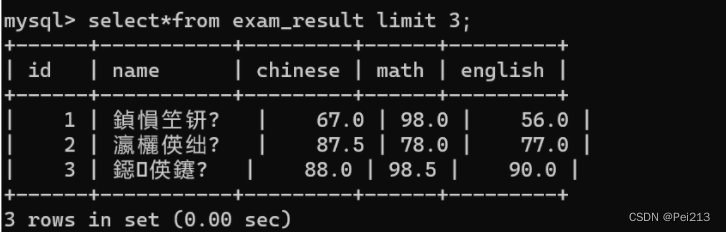
用offset可以指定从哪里开始查询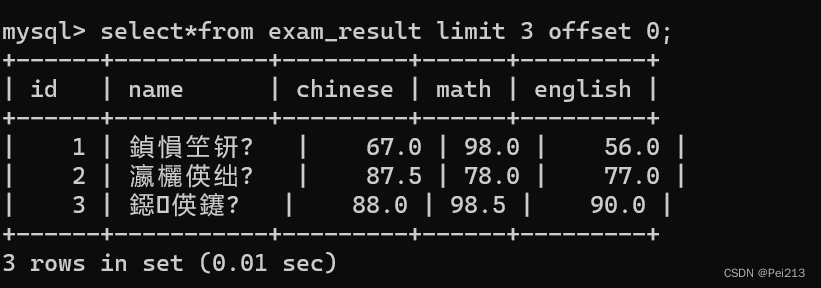

2.3.6修改(update)
update 表名 set 列名=值,列名=值...where 条件;2.3.7删除(delete)
delete from 表名;
delete from 表名 where 条件;2.4数据库约束下的增删改查
例:建立student和class两个表
2.4.1not null
creat table student(id int not null,name varchar(20) not null);2.4.2unique
create table student (id int unique,name varchar(20));2.4.3default
create table student (id int unique,name varchar(20) default '无名氏');2.4.4primary key
主键,身份标识,唯一且不为空,相当于unique 和not null 的综合
一个表里只能有一个主键,用一个列做主键,复合主键不常见
create table student (id int primary key,name varchar(20));自增主键:
create table student (id int primary key auto_increment ,name varchar(20));2.4.5foreign key 外键
创建了两张表
create table class(classId int primary key auto_increment,classNam e varchar(20));
create table student(studentId int primary key auto_increment,name varchar(20), classId int,foreign key(classId) references class(classId));此时就要求student表中每个记录的classId得在class表中的classId存在
2.4.6聚合查询
查询过程中,表的行和行进行一定的运算
1.count 函数
 2.sum求和
2.sum求和
只针对数字列有效,字符串列无效
 3.avg计算平均值
3.avg计算平均值

计算总平均值

4.max/min
2.4.7分组聚合
这些聚合函数,默认都是针对这个表里所有的类进行了聚合,有时候,还需要分组聚合,也就是,按照指定的字段,把记录分成若干组,每一组分别使用聚合函数.
1.group by
按照职位进行分组,查询平均工资
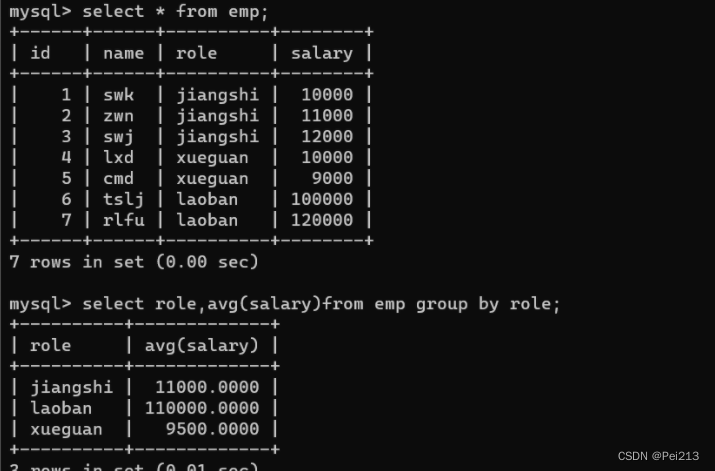
分组的时候,还可以指定条件筛选,先搞清楚是分组前还是分组后
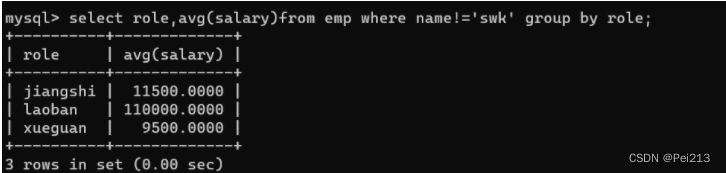
(1).分组前,筛选,使用where条件
求每个岗位的平均工资,但是刨除孙悟空
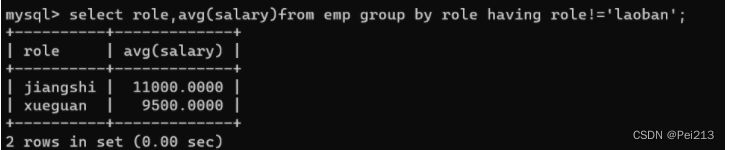
(2).分组后,筛选,使用having条件
求每个岗位的平均工资,但是刨除老板
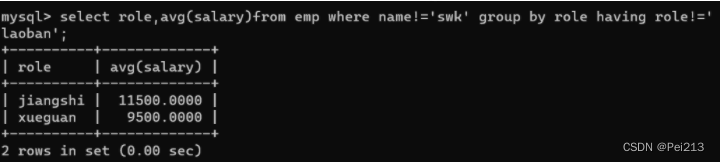
(3).还可以同时使用
2.4.8联合查询/多表查询
笛卡尔积:把表进行排列组合
去掉笛卡尔积组成的表的多余项,就是多表查询

上述联合查询,其实都是内连接(inner join).MySQL还有一种联合查询,叫做外连接

2.5索引
索引 index,即目录
2.5.1查看索引
show index from 表名

2.5.2创建索引
create index 索引名 on 表名(列名);
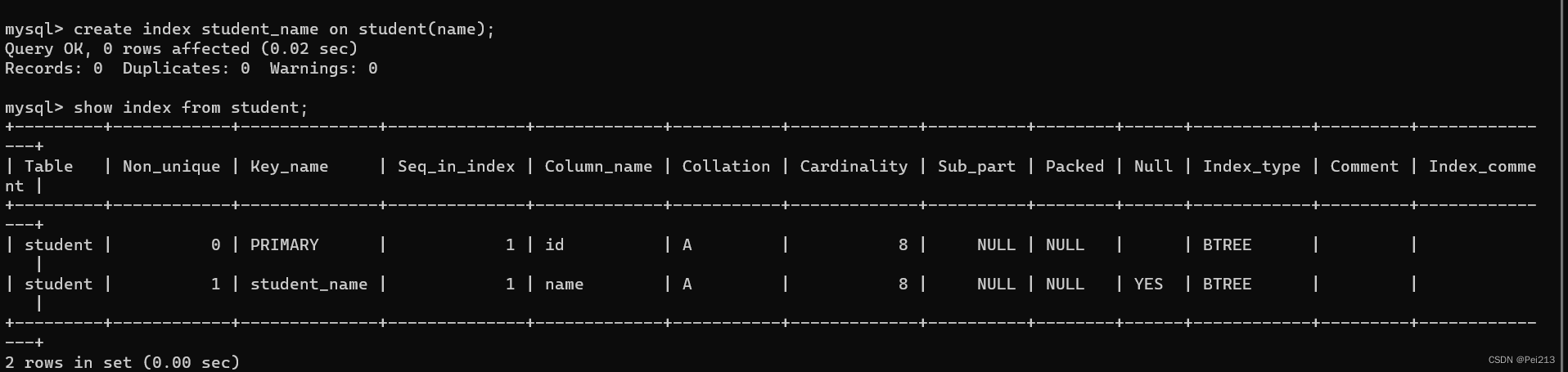
把表中的内容,根据name,又搞了一份目录出来
如果表中已经有很多的数据了,就不要再创建索引了
2.5.3删除索引
drop index 索引名 on 表名