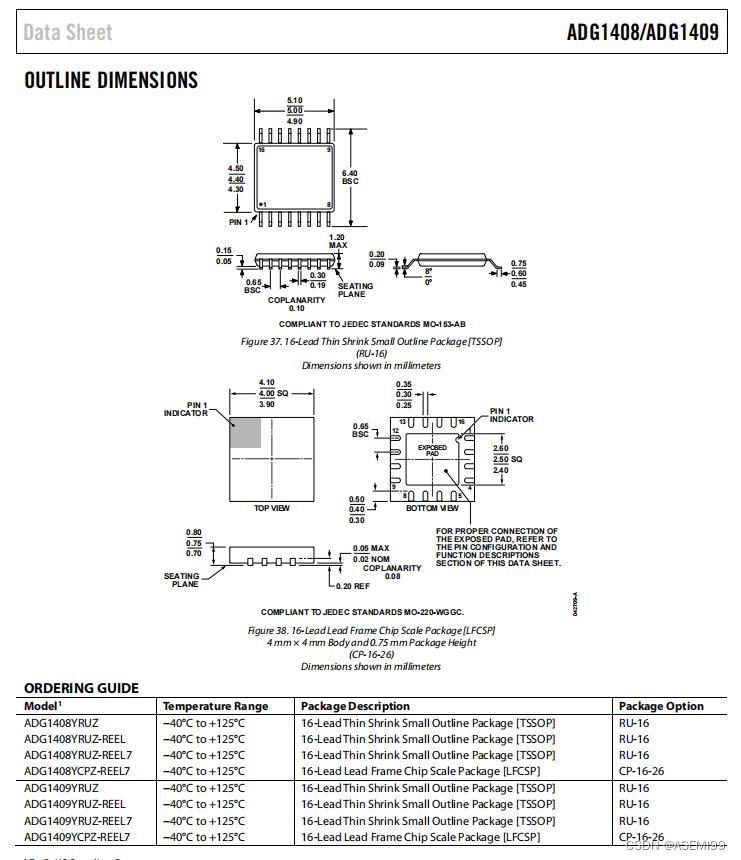
Hadoop
一. 引言
1.1 什么是大数据
大数据:(Big Data):数据量级很大的应用处理。TB级 ,日数据增长GB级
K -- M---- G ---- T ----PB ---- EB ---ZB 1024
通过对海量数据进行分析,挖掘,进而发现数据内在的规律,从而为企业或者国家创造价值。
1.2 大数据特点
4V是大数据典型的特点具体指的是:
# 1.Volume (大量)
数据量很大,至少是TB或者日均增加GB级
# 2.Variety (多样)
a.结构化数据 : 传统关系型数据库中的数据
b.半结构化数据: json xml mongodb存储的数据
c.非结构化数据: 音频 视频
# 3.Velocity(快速)
处理数据速度要快 注意:是相对速度快
# 4.Value (价值)
海量没有价值的数据中,分析出有价值的内容。
1.3 大数据的工作方向
# 1. 业务
电商的推荐系统,智能广告系统,专家系统,智慧城市,智能交通,金融大脑,智慧医疗,灾害预警....
# 2. 工作方向
大数据运维工程师,大数据开发工程师(实时计算,数据仓库,ETL,基本挖掘),数据分析师(算法)
1.4 大数据的起源
Google是最早面临大数据问题的公司。
1. GFS google File System
2. MapReduce
3. BigTable (NoSQL 数据库)
大数据起源可以说是google最早开源的3篇论文,开创了大数据时代
1.5 大数据处理的核心数据类型
大数据处理的核心数据类型通常为:
文本类型
1.6 大数据的数据来源
# 1.自己公司业务系统运行产生的日志 (nginx,log4j,数据库中的日志)
# 2.爬虫
# 3.行业数据 电信 医疗 政府.
1.7 大数据目前面临问题
# 1.存储
如何解决现有大数据中数据存储问题
# 2.统计|计算
如何解决现有大规模的数据集中统计和计算的问题
二. Hadoop的引言
2.1 解决问题
Hadoop主要是用来解决大数据所面临的数据存储和数据计算的问题。
2.2 Hadoop诞生
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop之父
Doug Cutting,可能所有人都间接用过他的作品,他是Lucene、Nutch、Hadoop等项目的发起人。是他,把高深莫测的搜索技术形成产品,贡献给我们;还是他,打造了目前在云计算和大数据领域里如日中天的Hadoop。

# Haoop核心设计
HDFS (Hadoop Distribute File System) -------> GFS
MapReduce -------> MapReduce
HBase -------> Big Table
apache组织正式开源,并将hadoop作为apache顶级的开源项目之一
2.3 Hadoop的发行版本
| 版本 | 是否收费 | 使用难度 |
|---|---|---|
| Apache 开源的Hadoop | 免费 | ★★★★☆ |
| Clouder(CDH) | $4000 (1个节点) | ★★★☆☆ |
| Hortonworks | $12500(10个节点) | ★★★☆☆ |
| 华为hadoop | 未知(内部使用) | ☆☆☆☆☆ |
注意:在实际开发中Appache的Hadoop企业实际使用并不多。最原始(基础)版本。但是却是学习hadoop的基础。
2.4 hadoop的生态圈

# 1.hadoop核心 HDFS,MapReduce
# 2.Hive 通过SQl语句形式执行mapreduce
# 3.Hbase Nosql数据库
# 4.Flume 日志采集工具
# 5.Sqoop sql to hadoop 将数据导入到hadoop中
# 6.Zookeeper 协调服务工具
# 7.Mahout 算法库
# 8.Pig 是MapReduce的一个抽象,它是一个工具/平台,用于分析较大的数据集,并将它们表示为数据流。
三.Hadoop的安装(单机)
说明: hadoop的核心为
HDFS和MapReduce
3.1 Hadoop的核心之HDFS
3.1.1 HDFS引言
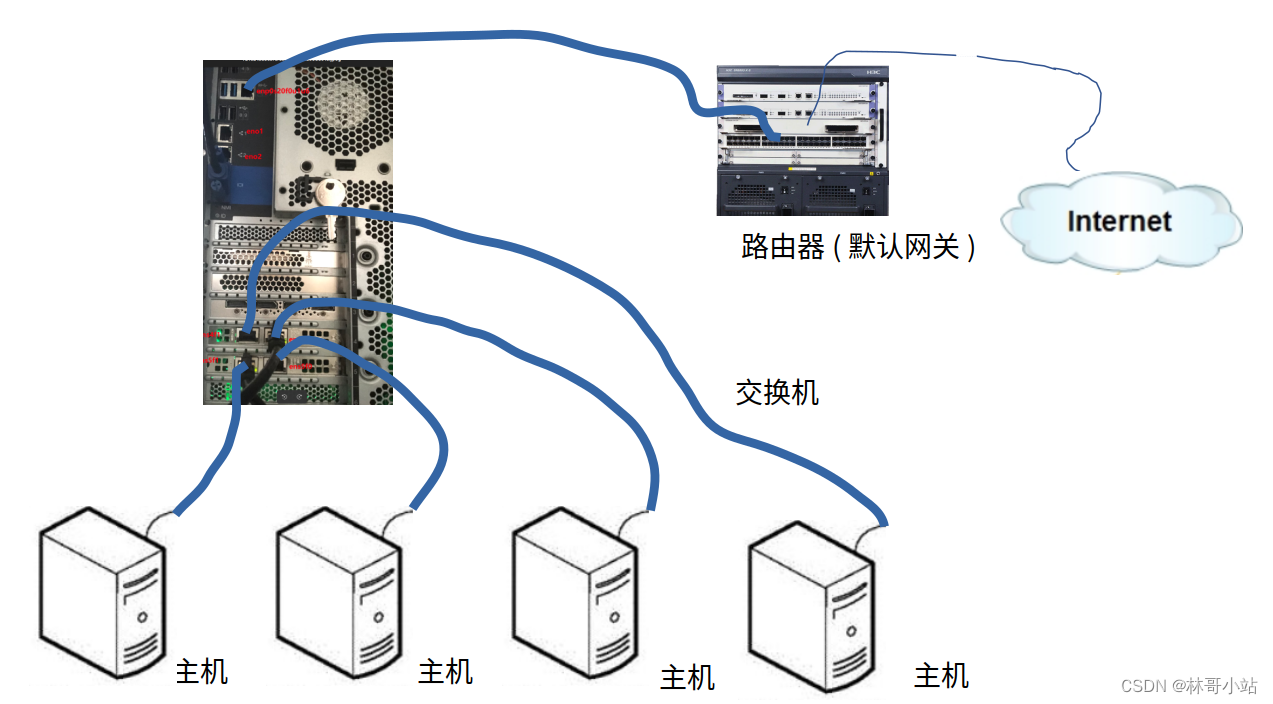
# HDFS (Hadoop Distribute File System): Hadoop 的分布式文件存储系统,他核心解决的大数据的存储问题
3.1.2 HDFS基本架构图

NameNode:是整个HDFS集群的总入口,存储着HDFS的集群的文件元数据(如:client上传文件的文件名 副本数 块数等相关信息)。DataNode:是真正用来负责存储数据的节点,一个DataNode就是一个真实的物理主机。Block:数据块,为了能通过多个节点保存大数据集,HDFS将大数据集文件切分成一块块的数据块,在现有hadoop2版本中默认一个块大小为128M。
3.1.3 Hadoop的安装
准备环境
# 0. 安装centos7.x 虚拟机,并启动
# 1. 输入hostname 查看当前主机名
# 2. 使用vim /etc/hostname 修改主机名
# 3. 重启centos 系统 reboot
# 4. 查看修改之后的主机名 hostname
# 5. 添加主机名与ip映射 vim /etc/hosts
加入 ip(当前ip地址) centos(主机名)
# 6. 检测主机名ip配置是否生效
# 7.关闭防火墙
`systemctl stop firewalld
`systemctl disable firewalld
配置java环境变量
# 0.下载jdk
wget https://download.oracle.com/otn/java/jdk/8u231-b11/5b13a193868b4bf28bcb45c792fce896/jdk-8u231-linux-x64.rpm
# 1. 安装jdk文件
rpm -ivh jdk-8u231-linux-x64.rpm
# 2. 配置环境变量 vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
export PATH=$PATH:$NODE_HOME/bin:$MAVEN_HOME/bin:$JAVA_HOME/bin
# 3. 重新载入配置
source /etc/profile
# 4. 检测配置是否生效
jps
java
javac
安装hadoop
# 0.下载hadoo
wget hadoop-2.9.2.tar.gz 注意:本次课程使用的事hadoop2.9.2版本 和 centos7.x
# 1. 上传hadoop软件包到系统中
hadoop-2.9.2.tar.gz
# 2. 解压到指定文件目录中
tar -zxvf hadoop-2.9.2.tar.gz -C /usr
# 3. 配置hadoop环境变量
export HADOOP_HOME=/usr/hadoop-2.9.2
export PATH=$PATH$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 4. 测试环境变量是否配置成功
直接输入hdfs命令查看效果
# 5. 查看hadoop的安装目录 tree -L 1 /usr/hadoop-2.9.2
[root@hadoop ~]# tree -L 2 hadoop-2.9.2
hadoop-2.9.2
├── bin
│ ├── container-executor
│ ├── hadoop
│ ├── hadoop.cmd
│ ├── hdfs
│ ├── hdfs.cmd
│ ├── mapred
│ ├── mapred.cmd
│ ├── rcc
│ ├── test-container-executor
│ ├── yarn
│ └── yarn.cmd
├── etc
│ └── hadoop
├── include
│ ├── hdfs.h
│ ├── Pipes.hh
│ ├── SerialUtils.hh
│ ├── StringUtils.hh
│ └── TemplateFactory.hh
├── lib
│ └── native
├── libexec
│ ├── hadoop-config.cmd
│ ├── hadoop-config.sh
│ ├── hdfs-config.cmd
│ ├── hdfs-config.sh
│ ├── httpfs-config.sh
│ ├── kms-config.sh
│ ├── mapred-config.cmd
│ ├── mapred-config.sh
│ ├── yarn-config.cmd
│ └── yarn-config.sh
├── LICENSE.txt
├── logs
│ ├── hadoop-root-datanode-hadoop.log
│ ├── hadoop-root-datanode-hadoop.out
│ ├── hadoop-root-datanode-hadoop.out.1
│ ├── hadoop-root-datanode-hadoop.out.2
│ ├── hadoop-root-datanode-hadoop.out.3
│ ├── hadoop-root-datanode-hadoop.out.4
│ ├── hadoop-root-datanode-hadoop.out.5
│ ├── hadoop-root-namenode-hadoop.log
│ ├── hadoop-root-namenode-hadoop.out
│ ├── hadoop-root-namenode-hadoop.out.1
│ ├── hadoop-root-namenode-hadoop.out.2
│ ├── hadoop-root-namenode-hadoop.out.3
│ ├── hadoop-root-namenode-hadoop.out.4
│ ├── hadoop-root-namenode-hadoop.out.5
│ ├── hadoop-root-secondarynamenode-hadoop.log
│ ├── hadoop-root-secondarynamenode-hadoop.out
│ ├── hadoop-root-secondarynamenode-hadoop.out.1
│ ├── hadoop-root-secondarynamenode-hadoop.out.2
│ ├── hadoop-root-secondarynamenode-hadoop.out.3
│ ├── hadoop-root-secondarynamenode-hadoop.out.4
│ ├── hadoop-root-secondarynamenode-hadoop.out.5
│ ├── SecurityAuth-root.audit
│ ├── userlogs
│ ├── yarn-root-nodemanager-hadoop.log
│ ├── yarn-root-nodemanager-hadoop.out
│ ├── yarn-root-nodemanager-hadoop.out.1
│ ├── yarn-root-nodemanager-hadoop.out.2
│ ├── yarn-root-nodemanager-hadoop.out.3
│ ├── yarn-root-nodemanager-hadoop.out.4
│ ├── yarn-root-nodemanager-hadoop.out.5
│ ├── yarn-root-resourcemanager-hadoop.log
│ ├── yarn-root-resourcemanager-hadoop.out
│ ├── yarn-root-resourcemanager-hadoop.out.1
│ ├── yarn-root-resourcemanager-hadoop.out.2
│ ├── yarn-root-resourcemanager-hadoop.out.3
│ ├── yarn-root-resourcemanager-hadoop.out.4
│ └── yarn-root-resourcemanager-hadoop.out.5
├── NOTICE.txt
├── README.txt
├── sbin
│ ├── distribute-exclude.sh
│ ├── FederationStateStore
│ ├── hadoop-daemon.sh
│ ├── hadoop-daemons.sh
│ ├── hdfs-config.cmd
│ ├── hdfs-config.sh
│ ├── httpfs.sh
│ ├── kms.sh
│ ├── mr-jobhistory-daemon.sh
│ ├── refresh-namenodes.sh
│ ├── slaves.sh
│ ├── start-all.cmd
│ ├── start-all.sh
│ ├── start-balancer.sh
│ ├── start-dfs.cmd
│ ├── start-dfs.sh
│ ├── start-secure-dns.sh
│ ├── start-yarn.cmd
│ ├── start-yarn.sh
│ ├── stop-all.cmd
│ ├── stop-all.sh
│ ├── stop-balancer.sh
│ ├── stop-dfs.cmd
│ ├── stop-dfs.sh
│ ├── stop-secure-dns.sh
│ ├── stop-yarn.cmd
│ ├── stop-yarn.sh
│ ├── yarn-daemon.sh
│ └── yarn-daemons.sh
└── share
├── doc
└── hadoop
bin 和 sbin目录用来启动hdfs yarn 等可执行的脚本文件etc目录用来存放hadoop的配置文件logs目录用来存放hadoop的日志文件share用来存放hadoop的依赖jar第三方jar目录lib用来存放hadoop使用核心库文件
# 6.配置core-site.xml
vim /usr/hadoop-2.9.2/etc/hadoop/core-site.xml 加入如下配置:
<configuration>
<!--配置hdfs文件系统默认名称-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop(主机名):9000</value>
</property>
</configuration>
注意:名称是一个HDFS的URL
# 7.配置hdfs-site.xml
vim /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml 加入如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
# 8.配置slaves文件
vim /usr/hadoop-2.9.2/etc/hadoop/slaves 加入如下配置:
hadoop (当前主机名)
# 9.格式化hdfs
hdfs namenode -format (仅仅是第一次使用需要格式化)
`出现如下错误: /usr/hadoop-2.9.2/bin/hdfs:行319: /usr/java/jdk1.8.0_171-amd64/bin//bin/java: 没有那个文件或目录`参考步骤10解决
注意:这里的格式化是格式成hadoop可以识别的文件系统,比如我们买了一块硬盘我们需要格式化成windows或者mac,linux系统识别的文件系统,才能使用这个文件系统。
# 10.配置etc/hadoop目录中中hadoop-env.sh
将原来export JAVA_HOME=$JAVA_HOME ====修改为jdk安装目录==> export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
# 11.启动HDFS
start-dfs.sh 启动
stop-dfs.sh 关闭
# 12. 查看hadoop是否启动成功
jps 存在以下进程名称说明启动成功
5876 SecondaryNameNode
5702 DataNode
5995 Jps
5612 NameNode
注意:只要能看到NameNode 和 DataNode 说明启动成功
# 13. 访问hdfs提供的web界面
http://IP地址:50070/
3.2 查看HDFS日志
# 1.进入hadoop安装目录中logs目录中
hadoop-root-namenode-hadoop.log ---- namenode日志
hadoop-root-datanode-hadoop.log ---- datanode日志
hadoop-root-secondarynamenode-hadoop.log ---- secondnamenode 日志
yarn-root-resourcemanager-hadoop.log ---- resourcemanager 日志
yarn-root-nodemanager-hadoop.log ---- nodemanager 日志
注意:针对于hdfs日志规则为hadoop-用户名-服务名-主机名.log,针对于后续学习的yarn生成规则为yarn-用户名-服务名-主机名.log
3.3 修改hdfs默认数据位置
- 说明: 通过查看日志得知namenode数据和datanode数据默认都是存放在/tmp//tmp/hadoop-root/dfs下,这对于我们来说是不安全的,因为tmp目录为临时目录,系统可能会定期清除目录中文件,因此为了保证数据安全修改数据默认的存放位置
# 1.修改hadoop安装目录下etc/hadoop/core-site.xml 加入如下配置
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/data</value>
</property>
3.4 配置SSH免密登录
SSH 为 [Secure Shell](https://baike.baidu.com/item/Secure Shell) 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。
从客户端来看,SSH提供两种级别的安全验证。
3.4.1基于口令的安全验证
只要你知道自己帐号和口令,就可以登录到远程主机。所有传输的数据都会被加密,但是不能保证你正在连接的服务器就是你想连接的服务器。可能会有别的服务器在冒充真正的服务器,也就是受到“中间人”这种方式的攻击。
3.4.2 基于密匙的安全验证
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。
注意:第二种级别不仅加密所有传送的数据,而且“中间人”这种攻击方式也是不可能的(因为他没有你的私人密匙)。但是整个登录的过程可能需要10秒 。
3.4.3 ssh 登录过程

3.4.4 配置ssh
# 1. 生成ssh秘钥对
ssh-keygen -t rsa 然后回车几次就可以啦
# 2. 查看秘钥对生成位置
ls /root/.ssh 会发现在home目录中生成了两个文件
id_rsa(私钥) id_rsa.pub(公钥)
# 3. 将公钥加入另一台机器的受信列表中
ssh-copy-id hadoop(主机名)
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys (和上面命令一样)
# 4. 再次查看/root/.ssh 目录 多出两个文件其中authorized_keys就是存放公钥列表文件
authorized_keys id_rsa id_rsa.pub known_hosts
# 5. 检测是否配置成功
ssh hadoop 不需要输入密码即可
四. HDFS的基本操作
4.1 Shell基本操作
4.1.1 命令总结
[root@hadoop ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
4.1.2 常见命令
# 1.查看目录结构
[root@hadoop1 ~]# hdfs dfs -ls /

# 2.上传文件到HDFS
[root@hadoop1 ~]# hdfs dfs -put aa.txt /


# 3.创建文件夹
[root@hadoop1 ~]# hdfs dfs -mkdir -p /bbb/cccc
[root@hadoop1 ~]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 1 root supergroup 58 2019-12-18 16:13 /aa.txt
drwxr-xr-x - root supergroup 0 2019-12-18 16:16 /bbb
[root@hadoop1 ~]# hdfs dfs -ls /bbb/cccc
# 4.查看文件内容
[root@hadoop1 ~]# hdfs dfs -cat /aa.txt
chenyn 1
xiaohei 1
wangwu 1
xiaohei 1
chenyn 1
zhangsan 1
[root@hadoop1 ~]# hdfs dfs -text /aa.txt
chenyn 1
xiaohei 1
wangwu 1
xiaohei 1
chenyn 1
zhangsan 1

# 5.删除文件
[root@hadoop1 ~]# hdfs dfs -rm /aa.txt
Deleted /aa.txt


# 6.删除空目录
[root@hadoop1 ~]# hdfs dfs -rm -r /bbb ----- 递归删除
Deleted /bbb
[root@hadoop1 ~]# hdfs dfs -mkdir -p /aa/bb/cc ----- 创建多级目录
[root@hadoop1 ~]# hdfs dfs -rm -r -f /aa ----- 强制删除
Deleted /aa

# 7.追加文件内容
[root@hadoop1 ~]# hdfs dfs -put aa.txt /
[root@hadoop1 ~]# hdfs dfs -cat /aa.txt
chenyn 1
xiaohei 1
wangwu 1
xiaohei 1
chenyn 1
zhangsan 1
[root@hadoop1 ~]# touch bb.txt
[root@hadoop1 ~]# echo "xiaohei 1" >> bb.txt
[root@hadoop1 ~]# cat bb.txt
xiaohei 1
[root@hadoop1 ~]# hdfs dfs -appendToFile bb.txt /aa.txt
[root@hadoop1 ~]# hdfs dfs -cat /aa.txt
chenyn 1
xiaohei 1
wangwu 1
xiaohei 1
chenyn 1
zhangsan 1
xiaohei 1

# 8.查看文件的校验核
[root@hadoop1 ~]# hdfs dfs -checksum /aa.txt
/aa.txt MD5-of-0MD5-of-512CRC32C 000002000000000000000000fb2fbd294298362dbaabfb7fc8724306

# 9.查看文件的权限
[root@hadoop1 ~]# hdfs dfs -ls -R /aa.txt
-rw-r--r-- 1 root supergroup 68 2019-12-18 16:35 /aa.txt
[root@hadoop1 ~]# hdfs dfs -chmod a+x /aa.txt
[root@hadoop1 ~]# hdfs dfs -ls -R /aa.txt
-rwxr-xr-x 1 root supergroup 68 2019-12-18 16:35 /aa.txt

# 10.从本地copy到hdfs中
[root@hadoop1 ~]# hdfs dfs -copyFromLocal bb.txt /bb.txt -----从本地复制文件到HDFS
[root@hadoop1 ~]# hdfs dfs -copyFromLocal bb.txt /bb.txt -----如果文件已经存在hdfs 复制失败
copyFromLocal: `/bb.txt': File exists
[root@hadoop1 ~]# hdfs dfs -copyFromLocal -f bb.txt /bb.txt -----如果文件已经存在hdfs 可以强制覆盖hdfs中文件

# 11.hdfs中复制文件
[root@hadoop1 ~]# hdfs dfs -mkdir /datas
[root@hadoop1 ~]# hdfs dfs -cp /aa.txt /datas
[root@hadoop1 ~]# hdfs dfs -ls /datas
Found 1 items
-rw-r--r-- 1 root supergroup 68 2019-12-18 16:54 /datas/aa.txt
# 12.从hdfs上下载文件到本地
[root@hadoop1 ~]# hdfs dfs -ls /
Found 3 items
-rwxr-xr-x 1 root supergroup 68 2019-12-18 16:35 /aa.txt
-rw-r--r-- 1 root supergroup 10 2019-12-18 16:50 /bb.txt
drwxr-xr-x - root supergroup 0 2019-12-18 16:54 /datas
[root@hadoop1 ~]# ls
aa.txt bb.txt hadoop-2.9.2.tar.gz jdk-8u171-linux-x64.rpm
[root@hadoop1 ~]# hdfs dfs -get /aa.txt /root/down.txt
[root@hadoop1 ~]# ls
aa.txt bb.txt down.txt hadoop-2.9.2.tar.gz jdk-8u171-linux-x64.rpm
# 13.查找某个路径下文件
[root@hadoop1 ~]# hdfs dfs -find / -name "aa.txt"
/aa.txt
/datas/aa.txt
# 14.将hdfs文件移动到hdfs另一个位置
[root@hadoop1 ~]# hdfs dfs -ls /
Found 3 items
-rwxr-xr-x 1 root supergroup 68 2019-12-18 16:35 /aa.txt
-rw-r--r-- 1 root supergroup 10 2019-12-18 16:50 /bb.txt
drwxr-xr-x - root supergroup 0 2019-12-18 16:54 /datas
[root@hadoop1 ~]# hdfs dfs -ls /datas
Found 1 items
-rw-r--r-- 1 root supergroup 68 2019-12-18 16:54 /datas/aa.txt
[root@hadoop1 ~]# hdfs dfs -mv /bb.txt /datas/bb.txt
[root@hadoop1 ~]# hdfs dfs -ls /
Found 2 items
-rwxr-xr-x 1 root supergroup 68 2019-12-18 16:35 /aa.txt
drwxr-xr-x - root supergroup 0 2019-12-18 17:03 /datas
[root@hadoop1 ~]# hdfs dfs -ls /datas
Found 2 items
-rw-r--r-- 1 root supergroup 68 2019-12-18 16:54 /datas/aa.txt
-rw-r--r-- 1 root supergroup 10 2019-12-18 16:50 /datas/bb.txt
4.2 Java操作HDFS
4.2.1 引入依赖
<properties>
<hadoop.version>2.9.2</hadoop.version>
</properties>
<dependencies>
<!--hadoop公共依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--hadoop client 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
4.2.2 获取hdfs客户端
public class TestHDFS {
private FileSystem fileSystem; //hdfs客户端对象
@Before
public void before() throws IOException {
//hadoop文件系统的权限设置为root
System.setProperty("HADOOP_USER_NAME","root");
//用来对core-site.xml hdfs-site.xml进行配置
Configuration conf = new Configuration();
//连接hdfs
conf.set("fs.defaultFS","hdfs://10.15.0.4:9000");
//设置上传文件的副本集
conf.set("dfs.replication","1");
fileSystem = FileSystem.get(conf);
}
@After
public void close() throws IOException {
fileSystem.close();
}
}
注意: FileSystem是java操作HDFS的客户端对象
4.2.3 上传文件到hdfs
@Test
public void testUpload() throws IOException {
FileInputStream is = new FileInputStream("/Users/chenyannan/IdeaProjects/ideacode/hadoop_hdfs/pom.xml");
Path path = new Path("/pom.xml");
FSDataOutputStream os = fileSystem.create(path);
//参数1:输入流 参数2:输出流 参数3:缓冲区大小 参数4:是否关闭流
IOUtils.copyBytes(is,os,1024,true);
}
4.2.4 hdfs下载文件
// 1.第一种方式
@Test
public void testDownload() throws IOException {
Path source = new Path("/pom.xml");
Path des = new Path("/Users/chenyannan");
fileSystem.copyToLocalFile(source,des);
}
// 2.第二种方式
@Test
public void testDownload1() throws IOException {
Path path = new Path("/pom.xml");
FSDataInputStream in = fileSystem.open(path);
FileOutputStream os = new FileOutputStream("/Users/chenyannan/aa.xml");
IOUtils.copyBytes(in,os,1024,true);
}
4.2.5 hdfs创建目录
@Test
public void testMkdirs() throws IOException {
boolean mkdirs = fileSystem.mkdirs(new Path("/aa/cc/cc"));
System.out.println("mkdirs = " + mkdirs);
}
4.2.6 展示hdfs文件列表
@Test
public void testListFiles() throws IOException {
Path path = new Path("/");
RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(path, true);
while (listFiles.hasNext()){
LocatedFileStatus next = listFiles.next();
System.out.println("next = " + next);
}
}
4.2.7 展示hdfs目录和文件
@Test
public void testListDirs() throws IOException {
Path path = new Path("/");
FileStatus[] fileStatuses = fileSystem.listStatus(path);
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.isDirectory()+" "+fileStatus.getPath());
}
}
4.2.8 删除文件
@Test
public void testDelete() throws IOException {
Path path= new Path("/aa");
//参数1:目录路径 参数2:是否递归删除
fileSystem.delete(path,true);
}
4.3 HDFS配置文件的优先级详解

注意:hadoop的配置文件解析顺序java代码客户端优于 > hadoop目录中etc/中配置优于 >share中jar默认配置
五. NameNode的持久化
5.1 NameNode的数据存在哪?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。
5.2 NameNode的持久化
NameNode数据存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。但是,如果一旦长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
总结:通过SecondaryNameNode 定期 对 FsImage 和 Edits文件的合并来保证NameNode中数据的高可用
5.3 持久化机制工作原理
# 第一阶段:NameNode启动
1>.第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
2>.客户端对元数据进行增删改的请求。
3>.NameNode记录操作日志,更新滚动日志。
4>.NameNode在内存中对数据进行增删改。
# 第二阶段:Secondary NameNode工作
1>.Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
2>.Secondary NameNode请求执行CheckPoint。
3>.NameNode滚动正在写的Edits日志。
4>.将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
5>.Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
6>.生成新的镜像文件fsimage.chkpoint。
7>.拷贝fsimage.chkpoint到NameNode。
8>.NameNode将fsimage.chkpoint重新命名成fsimage。

1>.NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。
2>.Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
3>.由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。
4>.SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
5>.SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。
6>.SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。
7>.NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中
5.4 Checkpoint的时间参数设置
修改hdfs-site.xml配置合并时间
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
修改hdfs-site.xml中操作次数和检查操作次数周期
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
六.HDFS完全分布式(简单版)
6.1 集群选型
# 1.NameNode 内存大 性能好一点的机器
# 2.DataNode 硬盘大 性能中等一般的机器即可
# 3.可以让NameNode 同时充当DataNode节点
6.2 集群搭建
# 1.克隆三台机器通过CRT连接
10.15.0.6
10.15.0.7
10.15.0.8

# 2.配置主机名以
vim /etc/hostname
NameNode修改为 : hadoop2
DataNode1修改为: hadoop3
DataNode2修改为: hadoop4

修改完成后必须重新启动
# 3.配置主机名与ip映射
vim /etc/hosts 三个机器配置一致
10.15.0.6 hadoop2
10.15.0.7 hadoop3
10.15.0.8 hadoop4

注意:配置完成后可以使用ping命令测试下是否配置成功
# 4.配置ssh免密登录
NameNode中执行: ssh-copyid root@hadoop2 ssh-copyid root@hadoop3 ssh-copyid root@hadoop4
# 5.安装jdk配置环境变量省略

# 6.安装hadoop 并配置环境变量省略

# 7.配置三个机器 hadoop-env.sh中环境变量设置
vim /usr/hadoop-2.9.2/etc/hadoop/hadoop-env.sh 文件

# 8.配置三台机器的core-site.xml文件
vim /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/data</value>
</property>

注意:在配置core-site.xml时想要使那台节点作为NameNode节点,就在配置文件中使用那个节点主机名作为fs.defaultFS的名字使用,图中使用的是Hadoop2作为NameNode,所以配置全部为Hadoop2
# 9.配置三台机器hdfs-site.xml配置文件
vim /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml

注意:这里将副本数量修改为了3份,默认配置也是3份
# 10.配置三个机器slaves文件
vim /usr/hadoop-2.9.2/etc/hadoop/slaves
hadoop2
hadoop3
hadoop4

注意:slaves文件用来决定哪些节点为datanode,因为Hadoop2节点既要是NameNode也要是DataNode因此也要讲hadoop2放在salves文件中,这样才会认为自己也是一个dataNode节点
# 4.在hadoop2节点上进行Namenode格式化
[root@hadoop2 ~]# hdfs namenode -format

# 5.启动hdfs集群
在hadoop2上执行: start-dfs.sh 关闭使用: stop-dfs.sh

# 6.查看各个节点进程

# 7.上传文件到hdfs上测试


七.ZK搭建高可用HDFS集群
7.1 原理解析
QJM(Quorum Journal Manager)是Hadoop专门为Namenode共享存储开发的组件。其集群运行一组Journal Node,每个Journal 节点暴露一个简单的RPC接口,允许Namenode读取和写入数据,数据存放在Journal节点的本地磁盘。当Namenode写入edit log时,它向集群的所有Journal Node发送写入请求,当多数节点回复确认成功写入之后,edit log就认为是成功写入。例如有3个Journal Node,Namenode如果收到来自2个节点的确认消息,则认为写入成功。
而在故障自动转移的处理上,引入了监控Namenode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在Namenode的宿主机器上,与Zookeeper集群协作完成故障的自动转移。整个集群架构图如下:

7.2 搭建HDFS高可用集群
# 0.集群规划 和 环境准备
hadoop1 10.15.0.5 ---(zk cluster 这里zk集群放在单独一台机器搭建的是一个伪分布式,我们重点关注hdfs集群)
hadoop2 10.15.0.6 --- namenode(active) & datanode & DFSZKFailoverController(zkfc) & journalnode
hadoop3 10.15.0.7 --- datanode & namenode(standby) & DFSZKFailoverController(zkfc) & journalnode
hadoop4 10.15.0.8 --- datanode & journalnode
环境准备: centos7.x 必须安装: yum install psmisc -y
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等 省略
# 1.安装zk(在一个机器上实现zk集群)

# 2.准备3个数据存放目录
mkdir -p /root/zkdata1
mkdir -p /root/zkdata2
mkdir -p /root/zkdata3

# 3.在每个数据文件夹中准备一个myid文件
touch /root/zkdata1/myid
touch /root/zkdata2/myid
touch /root/zkdata3/myid

# 4.编辑每个data目录中myid
vim /root/zkdata1/myid 输入 1
vim /root/zkdata2/myid 输入 2
vim /root/zkdata3/myid 输入 3

# 5.将zk配置文件复制三份到zkdata目录中
cp zk安装目录中/conf/zoo.cfg /root/zkdata1
cp zk安装目录中/conf/zoo.cfg /root/zkdata2
cp zk安装目录中/conf/zoo.cfg /root/zkdata3

# 6.分别修改zkdata目录中zoo.cfg配置端口号和数据目录位置
-
配置节点1 vim /root/zkdata1/zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/root/zkdata clientPort=3001 server.1=主机名:3002:3003 server.2=主机名:4002:4003 server.3=主机名:5002:5003

-
配置节点2 vim /root/zkdata2/zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/root/zkdata clientPort=4001 server.1=主机名:3002:3003 server.2=主机名:4002:4003 server.3=主机名:5002:5003

-
配置节点3 vim /root/zkdata3/zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/root/zkdata clientPort=5001 server.1=主机名:3002:3003 server.2=主机名:4002:4003 server.3=主机名:5002:5003

# 7.启动zk节点
[root@c60 zookeeper]# ./bin/zkServer.sh start /root/zkdata1/zoo.cfg
[root@c60 zookeeper]# ./bin/zkServer.sh start /root/zkdata2/zoo.cfg
[root@c60 zookeeper]# ./bin/zkServer.sh start /root/zkdata3/zoo.cfg

# 8.查看zk角色信息
[root@c60 zookeeper]# ./bin/zkServer.sh status /root/zkdata1/zoo.cfg

# 9.查看其它3个hadoop机器主机名 回顾集群规划
hadoop1 10.15.0.5 --- (zkcluster 上面我们已经构建zk集群)
hadoop2 10.15.0.6 --- namenode(active) & datanode & DFSZKFailoverController(zkfc)
hadoop3 10.15.0.7 --- datanode & namenode(standby) & DFSZKFailoverController(zkfc)
hadoop4 10.15.0.8 --- datanode

# 1.配置hadoop的core-site.xml 三个机器一致内容如下:
vim /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<!--hdfs主要入口不再是一个具体机器而是一个虚拟的名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.9.2/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:3001,hadoop1:4001,hadoop1:5001</value>
</property>

注意:ha.zookeeper.quorum 用来指定zk集群的节点数
# 2.配置hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop2:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop2:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop3:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop3:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop2:8485;hadoop3:8485;hadoop4:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
# 修改slaves文件指定哪些机器为DataNode
hadoop2
hadoop3
hadoop4
注意:由于配置内容比较多,这里就不截图了,保证三个机器配置一致即可
# 3.在任意一个namenode上执行如下命令:
[root@hadoop2 ~]# hdfs zkfc -formatZK

# 4.启动journalnode(分别在在hadoop2、hadoop3、hadoop4上执行)
[root@hadoop2 ~]# hadoop-daemon.sh start journalnode
[root@hadoop3 ~]# hadoop-daemon.sh start journalnode
[root@hadoop4 ~]# hadoop-daemon.sh start journalnode

使用:jps查看如过都出现如下进程说明启动成功

# 5.在hadoop2上执行(NameNode active)节点执行:
[root@hadoop2 ~]# hdfs namenode -format ns

# 6.启动hdfs集群
[root@hadoop2 ~]# start-dfs.sh

# 7.在standby 的 NameNode节点上执行如下命令:
[root@hadoop3 ~]# hdfs namenode -bootstrapStandby

[root@hadoop14 ~]# hadoop-daemon.sh start namenode
注意:启动standby的NameNode的
# 8.查看namenode(standby) 进程 和 hadoop4 进程
- namenode (standby)

- hadoop4 进程

# 9.访问namenode(active) 与 namenode(standby) hdfsweb界面
- hadoop2(namenode active)

- Hadoop3 (standby namenode)

# 10.停止正常NameNode进行测试

[root@hadoop2 ~]# jps
7426 DFSZKFailoverController
8499 NameNode
8631 Jps
7128 DataNode
5519 JournalNode
[root@hadoop2 ~]# kill 8499
[root@hadoop2 ~]# jps
7426 DFSZKFailoverController
7128 DataNode
8669 Jps
5519 JournalNode
- hadoop2(namenode down)

- hadoop3(namenode active)

八. MapReduce
8.1 计算
计算实际上也可以说是统计和分析,就是在大量的数据集中通过计算从而统计、分析出我们关注的数据,从而为我们创造相应的价值
8.2 如何解决大规模数据计算问题
- 抽样统计分析 ------> 结果不准确
- 全部数据统计 -------> 计算机性能要求极高
MapReduce就更好的解决了我们在处理大数据集的计算问题
8.2 MapReduce 引言
MapReduce是hadoop体系下的一种计算模型(计算框架|编程框架),主要是用来对存储在hdfs上的数据进行统计,分析的。
8.3 MapReduce的核心思想

Map Reduce: 计算框架分为两个部分: Map (局部统计) 和 Reduce (局部统计,汇总计算)
Yarn: 资源调度,任务监控 主要用来整合hadoop集群中的资源(CPU 内存),进行统一调度 同时监控任务的执行情况
Job作业: 一组MapReduce又统称为一个Job作业,在一个Hadoop集群中有很多job作业。
8.4 搭建yarn集群
8.4.1 配置mapred-site.xml
# 0.启动hdfs集群
# 1.复制 cp hadoop-2.9.2/etc/hadoop/mapred-site.xml.template hadoop-2.9.2/etc/hadoop/mapred-site.xml
# 2.编辑 vim hadoop-2.9.2/etc/hadoop/mapred-site.xml添加配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
8.4.2 配置yarn-site.xml
# 1.编辑 添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop</value>
</property>
上述yarn.resourcemanager.hostname配置中的:
hadoop为当前机器的主机名
8.4.3 启动yarn
[root@hadoop hadoop]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop.out
hadoop: starting nodemanager, logging to /root/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop.out
8.4.4 是否启动成功
[root@hadoop hadoop]# jps
4897 Jps
4724 NodeManager
3542 SecondaryNameNode
3367 DataNode
4619 ResourceManager
3229 NameNode
如果出现
NodeManager和ResourceManager这两个进程说明配置成功
8.4.5 mapreduce的web监控页面
http://10.15.0.4:8088/cluster
8.5 Job 作业总体流程

8.6 World Count 第一个案例
8.6.1 什么是Word Count
说明: World Count 简单说也叫单词计数统计,就是在一个文件中统计出每个单词出现的次数 如图:

- 说明: 解决上述问题,实际上使用曾经的 Core Java就可以很快的计算出来,为什么需要Hadoop呢?注意:如果数据非常少我们可以很快计算,但是如果数据非常大有1TB或者10TB这样的大文件我们可能很难计算结果。这个使用我们如果借助Hadoop为我们提供的Map Reduce 我们就能很好解决这个问题!
8.6.2 使用Map Reduce 完成 Word Count 的思路分析

8.6.3 Map Reduce 的第一个程序
-
准备数据上传的HDFS中
chenyn xiaohei xiaowang chenyn zhaoliu wangwu zhangsan xiaoming xiaochen chenyn chenyn xiaozhang xiaohei xiaoliu xiaozi xiaosun xiaochen[root@hadoop5 ~]# touch data [root@hadoop5 ~]# vim data [root@hadoop5 ~]# hdfs dfs -mkdir -p /wordcount [root@hadoop5 ~]# hdfs dfs -put data /wordcount/data [root@hadoop5 ~]# hdfs dfs -cat /wordcount/data chenyn xiaohei xiaowang chenyn zhaoliu wangwu zhangsan xiaoming xiaochen chenyn chenyn xiaozhang xiaohei xiaoliu xiaozi xiaosun xiaochen


-
引入依赖
<properties> <hadoop.version>2.9.2</hadoop.version> </properties> <dependencies> <!--hadoop公共依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <!--hadoop client 依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <!--junit--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!--map reduce--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.9.2</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies> -
开发Job作业编码
//word count job作业开发 public class WordCountJob extends Configured implements Tool { public static void main(String[] args) throws Exception { ToolRunner.run(new WordCountJob(),args); } @Override public int run(String[] strings) throws Exception { //创建job作业 Configuration conf = getConf(); Job job = Job.getInstance(conf); job.setJarByClass(WordCountJob.class); //设置Input Format job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("/wordcount/data")); //设置map阶段 job.setMapperClass(WordCountMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置Shuffle 阶段 默认 //设置reduce 阶段 job.setReducerClass(WordCountReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置 Output Formate job.setOutputFormatClass(TextOutputFormat.class); //注意:要求结果目录不能存在 FileSystem fileSystem = FileSystem.get(conf); Path res = new Path("/wordcount/res"); if(fileSystem.exists(res)) { fileSystem.delete(res,true); } TextOutputFormat.setOutputPath(job, res); //提交job作业 boolean b = job.waitForCompletion(true); System.out.println("作业执行状态 = " + b); return 0; } //开发Map阶段 public static class WordCountMap extends Mapper<LongWritable, Text,Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //value 就是读入的一行数据 String[] keys = value.toString().split(" "); for (String word : keys) { context.write(new Text(word),new IntWritable(1)); } } } //开发Reduce阶段 public static class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum+=value.get(); } context.write(key,new IntWritable(sum)); } } }注意:在执行mapreduce作业过程中,一定涉及到数据数据的序列化,hadoop对原始基本数据类型进行了二次包装hadoop中包装类型 java原始数据类型 Text String LongWritable Long IntWritable Integer FloatWritable Float DoubleWritable Double -
将wordcount打成jar包

-
上传到hadoop集群并执行wordcount jar包
[root@hadoop5 ~]# hadoop jar hadoop_wrodcount-1.0-SNAPSHOT.jar com.baizhi.wordcount.WordCountJob


[root@hadoop5 ~]# hdfs dfs -text /wordcount/res/part-r-00000
chenyn 4
wangwu 1
xiaochen 2
xiaohei 2
xiaoliu 1
xiaoming 1
xiaosun 1
xiaowang 1
xiaozhang 1
xiaozi 1
zhangsan 1
zhaoliu 1

8.7 MapReduce 自动化运行配置
8.7.1 打包时指定main Class信息
默认直接通过maven插件打成jar包中没有指定main class 信息,因此在运行mapreduce的jar包时必须在指令后面明确指定main class 的信息是谁,这样日后在执行mapreduce作业时会加大执行的难度,因此我们需要在打jar包时指定main class信息,减少执行作业时的操作,如果需要在打包中指定main class 信息:只需要对打包插件进行配置即可:
<build>
<plugins>
<!-- 在打包插件中指定main class 信息 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<outputDirectory>${basedir}/target</outputDirectory>
<archive>
<manifest>
<mainClass>com.baizhi.wordcount.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
加入上述配置之后再打包,日后就可以直接执行jar包,不需要额外指定main class 信息:

执行命令: clean package
8.7.2 使用wagon插件实现自动上传至hadoop集群
<build>
<!--扩展maven的插件中加入ssh插件-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<fromFile>target/test.jar 或者 ${project.build.finalName}.jar</fromFile>
<url>scp://user:password@192.168.20.128/root</url>
</configuration>
</plugin>
</plugins>
</build>
打包后直接执行wagon uplod-single即可:


执行命令操作: clean package wagon:upload-single
8.7.3 使用wagon上传jar完成后远程执行job作业
wagon配置加入commands命令
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<fromFile>target/${project.build.finalName}.jar</fromFile>
<url>scp://root:1@10.15.0.5/root</url>
<commands>
<!-- 通过sh 执行shell脚本文件 -->
<command>nohup hadoop-2.9.2/bin/hadoop jar hadoop_wordcount-1.0-SNAPSHOT.jar > /root/mapreduce.out 2>&1 & </command>
</commands>
<displayCommandOutputs>true</displayCommandOutputs>
</configuration>
</plugin>
执行命令操作:clean package wagon:upload-single wagon:sshexec

任务执行成功:

8.8 配置历史服务器调试Map Reduce
8.8.1 配置mapped-site.xml 并同步集群配置
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop5:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop5:19888</value>
</property>
8.8.2 配置yarn-site.xml 并同步集群配置
<!--开启日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保存时间 单位秒 这里是7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
8.8.3 启动历史服务器
[root@hadoop6 ~]# mr-jobhistory-daemon.sh start historyserver
[root@hadoop6 ~]# mr-jobhistory-daemon.sh stop historyserver
8.8.4 使用日志

8.8.5 查看日志

九. MapReduce 案例
9.1 统计各个手机号的上传和下载流量总和
数据展示:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
数据解释:
# 每行数据的第二列数据是手机号,倒数第三列表示上行流量,倒数第二列表示下行流量
输出格式要求:
# 手机号 上行流量 下行流量 总流量
最终统计结果为:
13726230503 上传流量:4962 下载流量:49362 总数据流量: 54324
13826544101 上传流量:528 下载流量:0 总数据流量: 528
13926251106 上传流量:480 下载流量:0 总数据流量: 480
13926435656 上传流量:264 下载流量:3024 总数据流量: 3288
创建数据文件上传到HDFS文件系统中
[root@hadoop5 ~]# vim access.log
[root@hadoop5 ~]# cat access.log
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
[root@hadoop5 ~]# hdfs dfs -mkdir -p /accesslog
[root@hadoop5 ~]# hdfs dfs -put access.log /accesslog


编写mapreduce的job作业完成统计
//统计手机流量
public class AccessLogJob extends Configured implements Tool {
private static Logger logger = Logger.getLogger(AccessLogJob.class);
public static void main(String[] args) throws Exception {
ToolRunner.run(new AccessLogJob(),args);
}
@Override
public int run(String[] strings) throws Exception {
//创建job作业
Job job = Job.getInstance(getConf(), "access-log");
job.setJarByClass(AccessLogJob.class);
//设置InputFormate
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/accesslog/access.log"));
//设置map
job.setMapperClass(AccessLogMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//shuffle 无须设置 自动完成
//设置reduce
job.setReducerClass(AccessLogReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置Output Format
job.setOutputFormatClass(TextOutputFormat.class);
Path res = new Path("/accesslog/res");
FileSystem fileSystem = FileSystem.get(getConf());
if(fileSystem.exists(res)) {
fileSystem.delete(res,true);
}
TextOutputFormat.setOutputPath(job, res);
//提交job作业
boolean status = job.waitForCompletion(true);
System.out.println("本次作业执行状态 = " + status);
return 0;
}
public static class AccessLogMap extends Mapper<LongWritable, Text,Text,Text>{
@Override //参数1:行首字母偏移量 参数2:当前row数据 参数3:map输出上下文
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split("\t");
//输出key 为手机号 值为: 每个手机号"上传-下载流量"格式文本
context.write(new Text(values[1]),new Text(values[values.length-3]+"-"+values[values.length-2]));
logger.info("手机号: "+values[1]+" 流量格式:"+values[values.length-3]+"-"+values[values.length-2]);
}
}
//reduce
public static class AccessLogReduce extends Reducer<Text,Text,Text,Text>{
@Override //参数1:map的key 参数2:相当key的数组 参数3:Reduce输出的上下文
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int uploadData = 0; //保存上传流量
int downData = 0; //保存下载流量
for (Text value : values) {
String[] datas = value.toString().split("-");
uploadData+= Integer.valueOf(datas[0]);
downData+= Integer.valueOf(datas[1]);
}
int total = uploadData + downData;//保存总流量
//输出
context.write(key,new Text(" 上传流量:"+uploadData+" 下载流量:"+downData+" 总数据流量: "+total));
logger.info("手机号: "+key+" 上传流量:"+uploadData+" 下载流量:"+downData+" 总数据流量: "+total);
}
}
}
运行mapreduce

查看结果
[root@hadoop5 ~]# hdfs dfs -text /accesslog/res/part-r-00000
13726230503 上传流量:4962 下载流量:49362 总数据流量: 54324
13826544101 上传流量:528 下载流量:0 总数据流量: 528
13926251106 上传流量:480 下载流量:0 总数据流量: 480
13926435656 上传流量:264 下载流量:3024 总数据流量: 3288
9.2 自定义MapReduce中数据类型
MapReduce的执行过程,无论是map阶段还是Reduce阶段都会跨JVM,通过网络通信传递数据,索引对于传递数据必须实现序列化,为此Hadoop的MapReduce模型对现有的数据类型进行了近一步的包装,如之前用到的IntWriteable、LongWritable 、Text、 DoubleWritable、NullWritable。如果处理简单计算有这些基础类型就够了,但是如果需要复杂结果是这些数据类型远远是不够的,因此我们需要根据实际情况自定义数据类型!
9.2.1 查看提供已知数据类型类图

通过类图得知hadoop提供的数据类型都间接实现了:
Wirtable、Comparable。直接实现WritableComparable接口,因此我们自定义类型也需要实现相应的接口
9.2.2 查看WriteComparable接口

通过查看源码得知自定义的数据类型需要实现类中
wirte、readFiles、compareTo、hashCode和equals、toString等相关方法。
9.2.3 根据之前流量案例定义自定义类型
开发自定义Writable类型
//自定义Writable类型
public class AccessLogWritable implements WritableComparable<AccessLogWritable> {
private Integer upload;
private Integer down;
private Integer total;
@Override
public int compareTo(AccessLogWritable o) {
return this.total-o.getTotal();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upload);
out.writeInt(down);
out.writeInt(total);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upload = in.readInt();
this.down = in.readInt();
this.total = in.readInt();
}
@Override
public String toString() {
return "统计结果{" +
"上传流量=" + upload +
", 下载流量=" + down +
", 上传下载总流量=" + total +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
AccessLogWritable accessLogWritable = (AccessLogWritable) o;
return Objects.equals(upload, accessLogWritable.upload) &&
Objects.equals(down, accessLogWritable.down) &&
Objects.equals(total, accessLogWritable.total);
}
@Override
public int hashCode() {
return Objects.hash(upload, down, total);
}
public Integer getUpload() {
return upload;
}
public void setUpload(Integer upload) {
this.upload = upload;
}
public Integer getDown() {
return down;
}
public void setDown(Integer down) {
this.down = down;
}
public Integer getTotal() {
return total;
}
public void setTotal(Integer total) {
this.total = total;
}
public AccessLogWritable() {
}
public AccessLogWritable(Integer upload, Integer down, Integer total) {
this.upload = upload;
this.down = down;
this.total = total;
}
public AccessLogWritable(Integer upload, Integer down) {
this.upload = upload;
this.down = down;
}
}
注意:write的顺序和read的顺序必须严格一致,读的类型和写的类型也必须完全一致
开发Job作业
public class AccessLogCustomerTypeJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new AccessLogCustomerTypeJob(),args);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "customer-type-job");
job.setJarByClass(AccessLogCustomerTypeJob.class);
//设置input format
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/accesslog/access.log"));
//设置map
job.setMapperClass(AccessLogCustomerTypeMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(AccessLogWritable.class);
//shuffle 无须设置 自动处理
//设置reduce
job.setReducerClass(AccessLogCustomerTypeReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(AccessLogWritable.class);
//设置Output Format
job.setOutputFormatClass(TextOutputFormat.class);
Path res = new Path("/accesslog/res2");
FileSystem fileSystem = FileSystem.get(getConf());
if(fileSystem.exists(res)){
fileSystem.delete(res,true);
}
TextOutputFormat.setOutputPath(job, res);
//提交作业
boolean status = job.waitForCompletion(true);
System.out.println("作业执行状态:" + status);
return 0;
}
public static class AccessLogCustomerTypeMap extends Mapper<LongWritable, Text,Text, AccessLogWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split("\t");
int upload = Integer.valueOf(values[values.length-3]);
int down = Integer.valueOf(values[values.length-2]);
context.write(new Text(values[1]),new AccessLogWritable(upload,down,0));
}
}
public static class AccessLogCustomerTypeReduce extends Reducer<Text, AccessLogWritable,Text, AccessLogWritable>{
@Override
protected void reduce(Text key, Iterable<AccessLogWritable> values, Context context) throws IOException, InterruptedException {
int upload =0;
int down = 0;
for (AccessLogWritable value : values) {
upload += value.getUpload();
down += value.getDown();
}
context.write(key,new AccessLogWritable(upload,down,upload+down));
}
}
}
执行job作业
[root@hadoop5 ~]# yarn jar hadoop_wordcount-1.0-SNAPSHOT.jar
19/12/20 10:33:57 INFO client.RMProxy: Connecting to ResourceManager at hadoop6/10.15.0.6:8032
19/12/20 10:34:00 INFO input.FileInputFormat: Total input files to process : 1
19/12/20 10:34:00 INFO mapreduce.JobSubmitter: number of splits:1
19/12/20 10:34:01 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/12/20 10:34:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1576780523481_0013
19/12/20 10:34:03 INFO impl.YarnClientImpl: Submitted application application_1576780523481_0013
19/12/20 10:34:03 INFO mapreduce.Job: The url to track the job: http://hadoop6:8088/proxy/application_1576780523481_0013/
19/12/20 10:34:03 INFO mapreduce.Job: Running job: job_1576780523481_0013
19/12/20 10:34:27 INFO mapreduce.Job: Job job_1576780523481_0013 running in uber mode : false
19/12/20 10:34:27 INFO mapreduce.Job: map 0% reduce 0%
19/12/20 10:34:43 INFO mapreduce.Job: map 100% reduce 0%
19/12/20 10:35:00 INFO mapreduce.Job: map 100% reduce 100%
19/12/20 10:35:02 INFO mapreduce.Job: Job job_1576780523481_0013 completed successfully

查看结果
[root@hadoop5 ~]# hdfs dfs -text /accesslog/res2/part-r-00000
13726230503 统计结果{上传流量=4962, 下载流量=49362, 上传下载总流量=54324}
13826544101 统计结果{上传流量=528, 下载流量=0, 上传下载总流量=528}
13926251106 统计结果{上传流量=480, 下载流量=0, 上传下载总流量=480}
13926435656 统计结果{上传流量=264, 下载流量=3024, 上传下载总流量=3288}

十. MapReduce的高级特性
10.1 MapRedcuce的数据清洗
10.1.1 数据清洗
所谓数据清洗指的是在复杂的数据格式中获取我们需要的数据过程称之为数据清洗,整个过程仅仅是将复杂数据中我们需要的数据清洗出来,不涉及任何的统计计算工作,如下图展示过程就是数据清洗:

10.1.2 数据清洗编程思路分析

10.1.3 开发数据清洗
//开发数据清洗
public class DataCleanAccessLogJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new DataCleanAccessLogJob(),args);
}
@Override
public int run(String[] args) throws Exception {
//创建job作业
Job job = Job.getInstance(getConf(), "data-clean-access-log-job");
job.setJarByClass(DataCleanAccessLogJob.class);
//设置input format
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("/accesslog/access.log"));
//设置map
job.setMapperClass(DataCleanAccessLogMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//跳过shuffle 和 reduce
job.setNumReduceTasks(0);
//设置output format
job.setOutputFormatClass(TextOutputFormat.class);
Path res = new Path("/accesslog/cleandata");
FileSystem fileSystem = FileSystem.get(getConf());
if(fileSystem.exists(res)){
fileSystem.delete(res,true);
}
TextOutputFormat.setOutputPath(job,res);
//提交job
boolean status = job.waitForCompletion(true);
System.out.println("作业提交状态 = " + status);
return 0;
}
//map阶段
public static class DataCleanAccessLogMap extends Mapper<LongWritable, Text,Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split("\t");
Text keyout = new Text(values[1]+"\t"+values[6] + "\t" + values[7]);
context.write(keyout, NullWritable.get());
}
}
//没有reduce阶段
}
注意: 设置job.setNumReduceTasks(0);这句话本次的mapreduce就跳过了reduce阶段的执行
10.1.4 运行作业
[root@hadoop5 ~]# yarn jar hadoop_wordcount-1.0-SNAPSHOT.jar
19/12/20 13:22:03 INFO client.RMProxy: Connecting to ResourceManager at hadoop6/10.15.0.6:8032
19/12/20 13:22:07 INFO input.FileInputFormat: Total input files to process : 1
19/12/20 13:22:07 INFO mapreduce.JobSubmitter: number of splits:1
19/12/20 13:22:08 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
19/12/20 13:22:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1576780523481_0018
19/12/20 13:22:10 INFO impl.YarnClientImpl: Submitted application application_1576780523481_0018
19/12/20 13:22:10 INFO mapreduce.Job: The url to track the job: http://hadoop6:8088/proxy/application_1576780523481_0018/
19/12/20 13:22:10 INFO mapreduce.Job: Running job: job_1576780523481_0018
19/12/20 13:22:36 INFO mapreduce.Job: Job job_1576780523481_0018 running in uber mode : false
19/12/20 13:22:36 INFO mapreduce.Job: map 0% reduce 0%
19/12/20 13:22:51 INFO mapreduce.Job: map 100% reduce 0%
19/12/20 13:22:53 INFO mapreduce.Job: Job job_1576780523481_0018 completed successfully

10.1.5 查看运行结果

[root@hadoop5 ~]# hdfs dfs -text /accesslog/cleandata/part*
13726230503 2481 24681
13826544101 264 0
13926435656 132 1512
13926251106 240 0
13726230503 2481 24681
13826544101 264 0
13926435656 132 1512
13926251106 240 0

十一. MapReduce的高级特性
11.1 MapReduce中Map的数量
# MapReduce运行过程中Map的数量是由block所决定的:
也就是一个文件分为几个block就是几个map
注意:map的数量由block块决定,也就意味着一旦文件确定根据默认配置划分block也将确定,所以我们没有办法在程序中手动干预map的执行数量
11.2 MapReduce中Reduce的数量
# Reduce的数量是可以在程序中手动指定
默认数量为: 1个 Reduce
可以通过: job.setNumReduceTasks(0); 0 就是没有 数字是几就是几个
11.2.1 通过修改word count案例reduce数量比较不同
使用默认reduce数量也就是1的执行结果:


将reduce数量修改为多个这里修改为2个,运行查看结果
//省略............
//设置reduce 阶段
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置reduce数量
job.setNumReduceTasks(2);
//省略..........
运行job作业

查看结果


通过这里可以总结出:有几个reduce就会生成几个结果文件,多个reduce同时处理数据将原来一个reduce处理结果,分到了不同的reduce处理文件中,因此如果日后需要将所有结果数据汇总在一起之能设置一个reduce,如果想要将结果划分到多个文件中可以设置多个reduce数量
11.2.2 为什么要设置多个reduce数量?
# 1.提高MR的运行效率,从而快速统计计算工作
11.2.3 多个Reduce如何去分配map中数据?
一旦设置了多个reduce,如何让多个reduce均分map中统计的数据,这里面还有一个分区(Partition)概念,一个Reduce会形成一个分区,默认使用的是HashPartitioner会根据map输出key做hash运算去决定map中输出数据交给那个reduce处理
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ez3yOy3X-1681868327719)(Hadoop-new.assets/image-20191222130057898.png)]
11.2.4 如何自定义分区(Partitoner)
自定义分区:可以根据业务规则将统计结果划分到不同分区中
数据格式
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
要求
# 统计流量,并将不同省份数据的统计结果放在不同文件中
自定义分区
//自定义分区 输入数据map端结果
public class ProvincePartitioner extends Partitioner<Text,AccessLogWritable> {
//根据业务规则将不同省份结果划分到不同分区
private static HashMap<String,Integer> provincePartitioners = new HashMap<>();
static{
provincePartitioners.put("136",0);
provincePartitioners.put("137",1);
provincePartitioners.put("138",2);
provincePartitioners.put("139",3);
}
// 返回分区号给那个reduce
@Override
public int getPartition(Text key, AccessLogWritable accessLogWritable, int numPartitions) {
String keyPrefix = key.toString().substring(0, 3);
Integer partionId = provincePartitioners.get(keyPrefix);
return partionId ==null?4: partionId;
}
}
在job作业中指定分区
//设置分区
job.setPartitionerClass(ProvincePartitioner.class);
//设置reduce数量
job.setNumReduceTasks(5);
运行job作业

查看结果


11.3 计数器(Counter)
计数器:顾名思义就是用来对map运行数量和reduce运行数量进行统计的
11.3.1 在map中使用计数器
public static class AccessLogCustomerTypeMap extends Mapper<LongWritable, Text,Text, AccessLogWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//计数器
Counter access_map = context.getCounter("map-group", "access_map");
access_map.increment(1);
String[] values = value.toString().split("\t");
int upload = Integer.valueOf(values[values.length-3]);
int down = Integer.valueOf(values[values.length-2]);
context.write(new Text(values[1]),new AccessLogWritable(upload,down,0));
}
}
11.3.2 在reduce中使用计数器
public static class AccessLogCustomerTypeReduce extends Reducer<Text, AccessLogWritable,Text, AccessLogWritable>{
@Override
protected void reduce(Text key, Iterable<AccessLogWritable> values, Context context) throws IOException, InterruptedException {
//计数器
Counter access_map = context.getCounter("reduce-group", "access_reduce");
access_map.increment(1);
int upload =0;
int down = 0;
for (AccessLogWritable value : values) {
upload += value.getUpload();
down += value.getDown();
}
context.write(key,new AccessLogWritable(upload,down,upload+down));
}
}

11.4 Combiner 合并
Combiner合并:又称之为map端的reduce,主要是通过对map局部的数据先进行一次reduce,从而来减少map端输出数据频繁发送给Reduce处理时所带来的网络压力问题。通过这种提前对map输出做一次局部reduce,这样既可以减轻网络压力,又能提高效率。在mapreduce编程模型中默认是关闭的。
11.4.1 开启Combiner
.....................
//设置map
job.setMapperClass(AccessLogCustomerTypeMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(AccessLogWritable.class);
//shuffle 无须设置 自动处理
//设置Combiner
job.setCombinerClass(AccessLogCustomerTypeReduce.class);
//设置分区
job.setPartitionerClass(ProvincePartitioner.class);
...............
11.4.2 运行设置Combiner的job
没有设置Combiner时:

设置Combiner时:

十二. Job作业原理分析
12.1 Input Format 原理解析
12.1.1 类图和源码
查看Text InputFormat的类图

注意:通过类图发现最顶层父类为Input Format这个类
查看Input Formt 源码:

/**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
* @throws IOException
* @throws InterruptedException
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException;
getSplits方法:是用来根据block计算逻辑上的切片,每一个逻辑切片对应一个map操作createRecordReader方法:用来将切片数据封装成一行(LongWritable,Text)
12.1.2 Input Format切片的计算方式


说明:
1. 当一个文件小于128M时一定会被分成一个逻辑切片,Block块与Split(切片)一一对应。
2.当一个文件大于128M,剩余大小大于切片的1.1倍,Block块与Split(切片)一一对应。反之如果一个文件大于128M,剩余大小小于切片的1.1倍,此时将划分为一个切片。

12.1.3 将数据封装成key和value


12.2 Map源码原理分析
这里只给出了核心方法:
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}

12.3 Reduce源码分析
查看reduce的源码,这里只罗列核心代码:
**
* This method is called once for each key. Most applications will define
* their reduce class by overriding this method. The default implementation
* is an identity function.
*/
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Advanced application writers can use the
* {@link #run(org.apache.hadoop.mapreduce.Reducer.Context)} method to
* control how the reduce task works.
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
cleanup(context);
}
}
}

12.4 OutputFormat 源码分析
查看源类图的结构:

注意:和 InputFormat基本是类似的,最顶层父类为Output Format:
TextOutputFormat部分源码如下:
/** An {@link OutputFormat} that writes plain text files. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextOutputFormat<K, V> extends FileOutputFormat<K, V> {
public static String SEPERATOR = "mapreduce.output.textoutputformat.separator";
protected static class LineRecordWriter<K, V>
extends RecordWriter<K, V> {
private static final String utf8 = "UTF-8";
private static final byte[] newline;
static {
try {
newline = "\n".getBytes(utf8);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public LineRecordWriter(DataOutputStream out, String keyValueSeparator) {
this.out = out;
try {
this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
public LineRecordWriter(DataOutputStream out) {
this(out, "\t");
}
}

通过源码得知默认的key和value输出分割符为"tab键"也就是这里的"\t"
12.5 Shuffle的分析
shuffle阶段是一个整体叫法: 其实又分为
Map端的shuffle和Reduce端的Shuffle
12.5.1 Map端shuffle

12.5.2 Reduce端的shuffle

12.6 MapReduce整体运行原理

#1.计算切片
有几个切片就有几个map task
#2.环形缓存区
经过map函数的逻辑处理后的数据输出之后,会通过OutPutCollector收集器将数据收集到环形缓存区保存。
环形缓存区的大小默认为100M,当保存的数据达到80%时,就将缓存区的数据溢出到磁盘上保存。
#3.溢出
环形缓存区的数据达到其容量的80%时就会溢出到磁盘上进行保存,在此过程中,程序会对数据进行分区(默认HashPartition)和排序(默认根据key进行快排)
缓存区不断溢出的数据形成多个小文件
#4.合并
溢出的多个小文件各个区合并在一起(0区和0区合并成一个0区),形成大文件
通过归并排序保证区内的数据有序
#5.shuffle
从过程2到过程7之间,即map任务和reduce任务之间的数据流称为shuffle(混洗),而过程5最能体现出混洗这一概念。一般情况下,一个reduce任务的输入数据来自与多个map任务,多个reduce任务的情况下就会出现如过程5所示的,
每个reduce任务从map的输出数据中获取属于自己的那个分区的数据。
#6.合并
运行reducetask的节点通过过程5,将来自多个map任务的属于自己的分区数据下载到本地磁盘工作目录。这多个分区文件通过归并排序合并成大文件,并根据key值分好组(key值相同的,value值会以迭代器的形式组在一起)。
#7.reducetask
reducetask从本地工作目录获取已经分好组并且排好序的数据,将数据进行reduce函数中的逻辑处理。
#8.输出
每个reducetask输出一个结果文件。
十三. MapReduce与Yarn
13.1 Job作业提交过程

客户端的配置信息mapreduce.framework.name为yarn时,客户端会启动YarnRunner(yarn的客户端程序),并将mapreduce作业提交给yarn平台处理。
1.向ResourceManager请求运行一个mapreduce程序。
2.ResourceManager返回hdfs地址,告诉客户端将作业运行相关的资源文件上传到hdfs。
3.客户端提交mr程序运行所需的文件(包括作业的jar包,作业的配置文件,分片信息等)到hdfs上。
4.作业相关信息提交完成后,客户端用过调用ResourcrManager的submitApplication()方法提交作业。
5.ResourceManager将作业传递给调度器,调度器的默认调度策略是先进先出。
6.调度器寻找一台空闲的节点,并在该节点隔离出一个容器(container),容器中分配了cpu,内存等资源,并启动MRAppmaster进程。
7.MRAppmaster根据需要运行多少个map任务,多少个reduce任务向ResourceManager请求资源。
8.ResourceManager分配相应数量的容器,并告知MRAppmaster容器在哪。
9.MRAppmaster启动maptask。
10.maptask从HDFS获取分片数据执行map逻辑。
11.map逻辑执行结束后,MRAppmaster启动reducetask。
12.reducetask从maptask获取属于自己的分区数据执行reduce逻辑。
13.reduce逻辑结束后将结果数据保存到HDFS上。
14.mapreduce作业结束后,MRAppmaster通知ResourceManager结束自己,让ResourceManager回收所有资源。
十四. HA的hadoop集群搭建
14.1 集群规划
# 集群规划
10.15.0.20 zk zknodes 通过一个节点充当整个集群
10.15.0.22 hadoop22 NameNode (active) & ZKFC
10.15.0.23 hadoop23 NameNode (standby) & ZKFC
10.15.0.24 hadoop24 ResourceManager(active)
10.15.0.25 hadoop25 ResourceManager(standby)
10.15.0.26 hadoop26 DataNode & JournalNode & NodeManager
10.15.0.27 hadoop27 DataNode & JournalNode & NodeManager
10.15.0.28 hadoop28 DataNode & JournalNode & NodeManager
# 克隆机器做准备工作:
0.修改ip地址为上述ip
1.修改主机名/etc/hostsname为上述对应主机名 修改完必须重新启动
2.配置主机名ip地址映射/etc/hosts文件并同步所有节点
10.15.0.20 zk
10.15.0.22 hadoop22
10.15.0.23 hadoop23
10.15.0.24 hadoop24
10.15.0.25 hadoop25
10.15.0.26 hadoop26
10.15.0.27 hadoop27
10.15.0.28 hadoop28
3.所有节点安装jdk并配置环境变量
4.关闭所有机器的网络防火墙配置
systemctl stop firewalld
systemctl disable firewalld
5.所有节点安装centos7.x搭建集群的依赖
yum install psmisc -y
6.配置ssh免密登录
hadoop22 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop23 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop24 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
hadoop25 生成ssh-keygen 然后ssh-copy-id 到 hadoop22~~hadoop28 上每一个节点
14.2 搭建zk集群
# 1.安装zk安装包
[root@zk ~]# tar -zxvf zookeeper-3.4.12.tar.gz
# 2.准备zk的数据文件夹
[root@zk ~]# mkdir zkdata1 zkdata2 zkdata3
# 3.在每个数据文件夹中准备集群唯一标识文件myid
[root@zk ~]# echo "1" >> zkdata1/myid
[root@zk ~]# echo "2" >> zkdata2/myid
[root@zk ~]# echo "3" >> zkdata3/myid
# 4.在每个数据文件夹中准备zk的配置文件zoo.cfg
[root@zk ~]# vim /root/zkdata1/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata1
clientPort=3001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
[root@zk ~]# vim /root/zkdata2/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata2
clientPort=4001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
[root@zk ~]# vim /root/zkdata3/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata3
clientPort=5001
server.1=zk:3002:3003
server.2=zk:4002:4003
server.3=zk:5002:5003
# 5.进入zk安装目录bin目录执行如下命令启动zk集群:
[root@zk bin]# ./zkServer.sh start /root/zkdata1/zoo.cfg
[root@zk bin]# ./zkServer.sh start /root/zkdata2/zoo.cfg
[root@zk bin]# ./zkServer.sh start /root/zkdata3/zoo.cfg
# 6.进入zk安装目录bin目录执行如下命令查看集群状态
./zkServer.sh status /root/zkdata1/zoo.cfg
./zkServer.sh status /root/zkdata2/zoo.cfg
./zkServer.sh status /root/zkdata3/zoo.cfg
14.3 搭建hadoop的HA集群
# 1.在hadoop22--hadoop28上安装hadoop安装包
tar -zxf hadoop-2.9.2.tar.gz
# 2.在hadoop22--hadoop28机器上配置hadoop环境变量
# 3.在hadoop22节点上配置hadoop-env.sh文件
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
# 4.在hadoop22节点上配置core-site.xml文件
[root@hadoop22 ~]# vim hadoop-2.9.2/etc/hadoop/core-site.xml
<!--hdfs主要入口不再是一个具体机器而是一个虚拟的名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- hadoop临时目录位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
<!--zk集群的所有节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
# 5.在hadoop2节点上配置hdfs-site.xml文件
[root@hadoop22 ~]# vim hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop22:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop22:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop23:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop23:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop26:8485;hadoop27:8485;hadoop28:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
# 6.在hadoop2节点上配置yarn-site.xml文件
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop24</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop25</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop24:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop25:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk:3001,zk:4001,zk:5001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# 7.在hadoop2节点上配置mapred-site.xml文件,默认不存在需要复制
[root@hadoop22 ~]# cp hadoop-2.9.2/etc/hadoop/mapred-site.xml.template hadoop-2.9.2/etc/hadoop/mapred-site.xml
[root@hadoop22 ~]# vim hadoop-2.9.2/etc/hadoop/mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# 8.在hadoop2节点上配置slaves文件
[root@hadoop22 ~]# vim hadoop-2.9.2/etc/hadoop/slaves
hadoop26
hadoop27
hadoop28
# 9.同步集群配置文件
scp -r hadoop-2.9.2/etc/hadoop/ hadoop23:/root/hadoop-2.9.2/etc/
scp -r hadoop-2.9.2/etc/hadoop/ hadoop24:/root/hadoop-2.9.2/etc/
scp -r hadoop-2.9.2/etc/hadoop/ hadoop25:/root/hadoop-2.9.2/etc/
scp -r hadoop-2.9.2/etc/hadoop/ hadoop26:/root/hadoop-2.9.2/etc/
scp -r hadoop-2.9.2/etc/hadoop/ hadoop27:/root/hadoop-2.9.2/etc/
scp -r hadoop-2.9.2/etc/hadoop/ hadoop28:/root/hadoop-2.9.2/etc/
# 10.启动HDFS的高可用
1.在任意NameNode上格式化ZK
hdfs zkfc -formatZK
2.在hadoop26 hadoop27 hadoop28启动journal node
[root@hadoop26 ~]# hadoop-daemon.sh start journalnode
[root@hadoop27 ~]# hadoop-daemon.sh start journalnode
[root@hadoop28 ~]# hadoop-daemon.sh start journalnode
3.在活跃的NameNode节点上执行格式化
[root@hadoop22 ~]# hdfs namenode -format ns
4.在NameNode上启动hdfs集群
[root@hadoop22 ~]# start-dfs.sh
5.在standby的NameNode上执行
[root@hadoop23 ~]# hdfs namenode -bootstrapStandby
6.在standby的NameNode执行
[root@hadoop23 ~]# hadoop-daemon.sh start namenode
# 11.在活跃节点上启动yarn集群
1.在活跃的resourcemang节点上执行
[root@hadoop24 ~]# start-yarn.sh
2.在standby的节点上执行
[root@hadoop25 ~]# yarn-daemon.sh start resourcemanager
# 12.测试集群