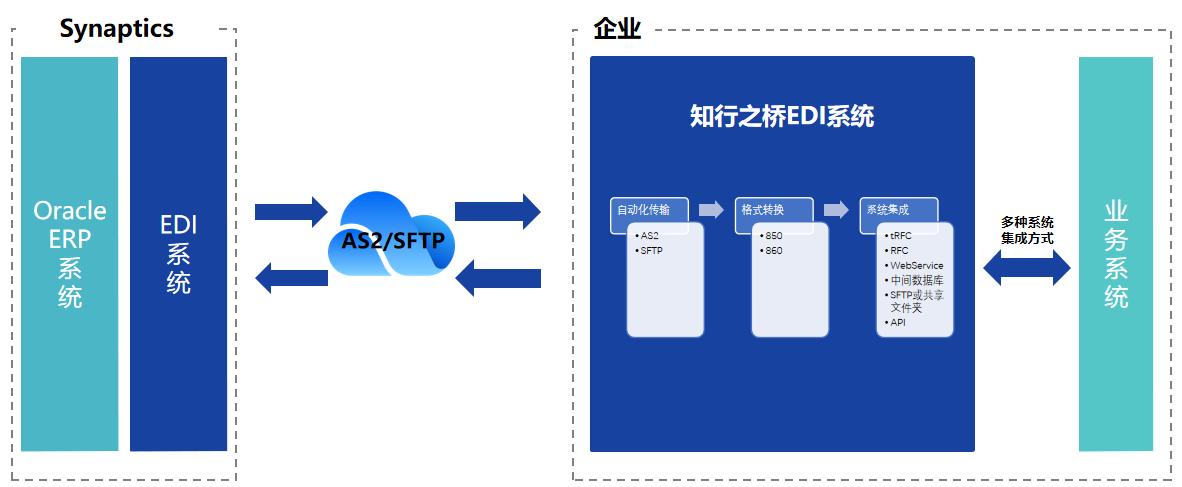
一、最长公共前缀

1.方法一:横向扫描
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
string prefix = strs[0];
int count = strs.size();
for (int i = 1; i < count; ++i) {
prefix = longestCommonPrefix(prefix, strs[i]);
if (!prefix.size()) {
break;
}
}
return prefix;
}
string longestCommonPrefix(const string& str1, const string& str2) {
int length = min(str1.size(), str2.size());
int index = 0;
while (index < length && str1[index] == str2[index]) {
++index;
}
return str1.substr(0, index);
}
};
解释
(1)return str1.substr(0, index)
使用了 substr() 方法从一个字符串中提取子字符串。
substr() 方法接受两个参数。第一个参数是子字符串的起始索引,第二个参数是子字符串的长度。这段代码从 str1 字符串的开头提取了一个子字符串,直到(但不包括)位于 index 位置的字符,并将该子字符串作为新字符串返回。
2.方法二:纵向扫描
方法一是横向扫描,依次遍历每个字符串,更新最长公共前缀。另一种方法是纵向扫描。纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
int length = strs[0].size();
int count = strs.size();
for (int i = 0; i < length; ++i) {
char c = strs[0][i];
for (int j = 1; j < count; ++j) {
if (i == strs[j].size() || strs[j][i] != c) {
return strs[0].substr(0, i);
}
}
}
return strs[0];
}
};
3.方法三:分治

class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
else {
return longestCommonPrefix(strs, 0, strs.size() - 1);
}
}
string longestCommonPrefix(const vector<string>& strs, int start, int end) {
if (start == end) {
return strs[start];
}
else {
int mid = (start + end) / 2;
string lcpLeft = longestCommonPrefix(strs, start, mid);
string lcpRight = longestCommonPrefix(strs, mid + 1, end);
return commonPrefix(lcpLeft, lcpRight);
}
}
string commonPrefix(const string& lcpLeft, const string& lcpRight) {
int minLength = min(lcpLeft.size(), lcpRight.size());
for (int i = 0; i < minLength; ++i) {
if (lcpLeft[i] != lcpRight[i]) {
return lcpLeft.substr(0, i);
}
}
return lcpLeft.substr(0, minLength);
}
};
4.方法四:二分查找

class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
int minLength = min_element(strs.begin(), strs.end(), [](const string& s, const string& t) {return s.size() < t.size();})->size();
int low = 0, high = minLength;
while (low < high) {
int mid = (high - low + 1) / 2 + low;
if (isCommonPrefix(strs, mid)) {
low = mid;
}
else {
high = mid - 1;
}
}
return strs[0].substr(0, low);
}
bool isCommonPrefix(const vector<string>& strs, int length) {
string str0 = strs[0].substr(0, length);
int count = strs.size();
for (int i = 1; i < count; ++i) {
string str = strs[i];
for (int j = 0; j < length; ++j) {
if (str0[j] != str[j]) {
return false;
}
}
}
return true;
}
};
解析:
(1)min_element(strs.begin(), strs.end(), [](const string& s, const string& t) {return s.size() < t.size();})->size();
min_element函数的参数是一个迭代器范围,由strs.begin()和strs.end()表示,这意味着要查找整个字符串向量中的最小元素。
第三个参数是一个函数对象,它是一个lambda表达式,用于指定如何比较两个字符串的大小。在这个lambda表达式中,const string& s和const string& t表示要比较的两个字符串,return s.size() < t.size()表示按照字符串长度从小到大进行比较。也就是说,这个lambda表达式将两个字符串的长度作为比较的关键字,返回值为两个字符串的长度比较结果。
最后,min_element函数返回一个迭代器,该迭代器指向字符串向量中的最小元素,即长度最短的字符串。因此,在这个代码中,->size()被用来获取长度最短的字符串的长度,并将其作为函数的返回值返回。
二、最长回文字串

方法一:动态规划
动态规划算法的实现通常分为四个步骤:定义状态、设计状态转移方程、初始化边界状态、计算最终状态。其中状态定义是最关键的一步,它需要将原问题转化为一个适合动态规划求解的子问题形式。状态转移方程则是核心步骤,它需要根据子问题之间的关系设计出一种递推公式,用来更新子问题的解。边界状态则是指最简单的子问题,通常需要先进行初始化。最终状态则是指原问题的解,通常可以通过已经求解过的子问题的解来计算得出。


#include <iostream>
#include <string>
#include <vector>
using namespace std;
class Solution {
public:
string longestPalindrome(string s) {
int n = s.size();
if (n < 2) {
return s;
}
int maxLen = 1;
int begin = 0;
// dp[i][j] 表示 s[i..j] 是否是回文串
vector<vector<int>> dp(n, vector<int>(n));
// 初始化:所有长度为 1 的子串都是回文串
for (int i = 0; i < n; i++) {
dp[i][i] = true;
}
// 递推开始
// 先枚举子串长度
for (int L = 2; L <= n; L++) {
// 枚举左边界,左边界的上限设置可以宽松一些
for (int i = 0; i < n; i++) {
// 由 L 和 i 可以确定右边界,即 j - i + 1 = L 得
int j = L + i - 1;
// 如果右边界越界,就可以退出当前循环
if (j >= n) {
break;
}
if (s[i] != s[j]) {
dp[i][j] = false;
} else {
if (j - i < 3) {
dp[i][j] = true;
} else {
dp[i][j] = dp[i + 1][j - 1];
}
}
// 只要 dp[i][L] == true 成立,就表示子串 s[i..L] 是回文,此时记录回文长度和起始位置
if (dp[i][j] && j - i + 1 > maxLen) {
maxLen = j - i + 1;
begin = i;
}
}
}
return s.substr(begin, maxLen);
}
};
方法二:中心扩展算法

class Solution {
public:
pair<int, int> expandAroundCenter(const string& s, int left, int right) {
while (left >= 0 && right < s.size() && s[left] == s[right]) {
--left;
++right;
}
return {left + 1, right - 1};
}
string longestPalindrome(string s) {
int start = 0, end = 0;
for (int i = 0; i < s.size(); ++i) {
auto [left1, right1] = expandAroundCenter(s, i, i);
auto [left2, right2] = expandAroundCenter(s, i, i + 1);
if (right1 - left1 > end - start) {
start = left1;
end = right1;
}
if (right2 - left2 > end - start) {
start = left2;
end = right2;
}
}
return s.substr(start, end - start + 1);
}
};
三、翻转字符串里的单词

方法一:自行编写对应的函数


class Solution {
public:
string reverseWords(string s) {
// 反转整个字符串
reverse(s.begin(), s.end());
int n = s.size();
int idx = 0;
for (int start = 0; start < n; ++start) {
if (s[start] != ' ') {
// 填一个空白字符然后将idx移动到下一个单词的开头位置
if (idx != 0) s[idx++] = ' ';
// 循环遍历至单词的末尾
int end = start;
while (end < n && s[end] != ' ') s[idx++] = s[end++];
// 反转整个单词
reverse(s.begin() + idx - (end - start), s.begin() + idx);
// 更新start,去找下一个单词
start = end;
}
}
//s.erase(s.begin() + idx, s.end()) 的含义是,删除从第一个多余空 //格到字符串末尾的所有元素,包括第一个多余空格。
s.erase(s.begin() + idx, s.end());
return s;
}
};
方法二:双端队列

class Solution {
public:
string reverseWords(string s) {
int left = 0, right = s.size() - 1;
// 去掉字符串开头的空白字符
while (left <= right && s[left] == ' ') ++left;
// 去掉字符串末尾的空白字符
while (left <= right && s[right] == ' ') --right;
//定义了一个名为 d 的双端队列(deque),其中存储的元素是字符串(string)类型。
deque<string> d;
string word;
while (left <= right) {
char c = s[left];
if (word.size() && c == ' ') {
// 将单词 push 到队列的头部
d.push_front(move(word));
word = "";
}
else if (c != ' ') {
word += c;
}
++left;
}
//将最后一个单词添加到双端队列 d 的头部
d.push_front(move(word));
string ans;
while (!d.empty()) {
ans += d.front();
d.pop_front();
if (!d.empty()) ans += ' ';
}
return ans;
}
};