- 魔王的介绍:😶🌫️一名双非本科大一小白。
- 魔王的目标:🤯努力赶上周围卷王的脚步。
- 魔王的主页:🔥🔥🔥大魔王.🔥🔥🔥
❤️🔥大魔王与你分享:“我不是害怕菲奥娜,我只是害怕满身破绽的自己。”

文章目录
- 前言
- 一、189. 轮转数组
- 思路
- 代码
- 二、面试题 17.04. 消失的数字
- 思路
- 代码
- 第一种
- 第二种
- 三、27. 移除元素
- 思路
- 代码
- 第一种:笨方法
- 第二种:正常解法
- 四、26. 删除有序数组中的重复项
- 思路
- 代码
- 五、88. 合并两个有序数组
- 思路
- 代码
- 第一种
- 第二种
- 六、20. 有效的括号
- 思路
- 代码
- 七、203. 移除链表元素
- 思路
- 代码
- 第一种
- 第二种
- 八、206. 反转链表
- 思路
- 代码
- 九、876. 链表的中间结点
- 思路
- 代码
- 十、链表中倒数第k个结点
- 思路
- 代码
- 十一、21. 合并两个有序链表
- 思路
- 代码
- 十二、总结
前言
一般都是接口型题型,所以并不是完整代码,只是关键代码。
一、189. 轮转数组
点我有惊喜!!!
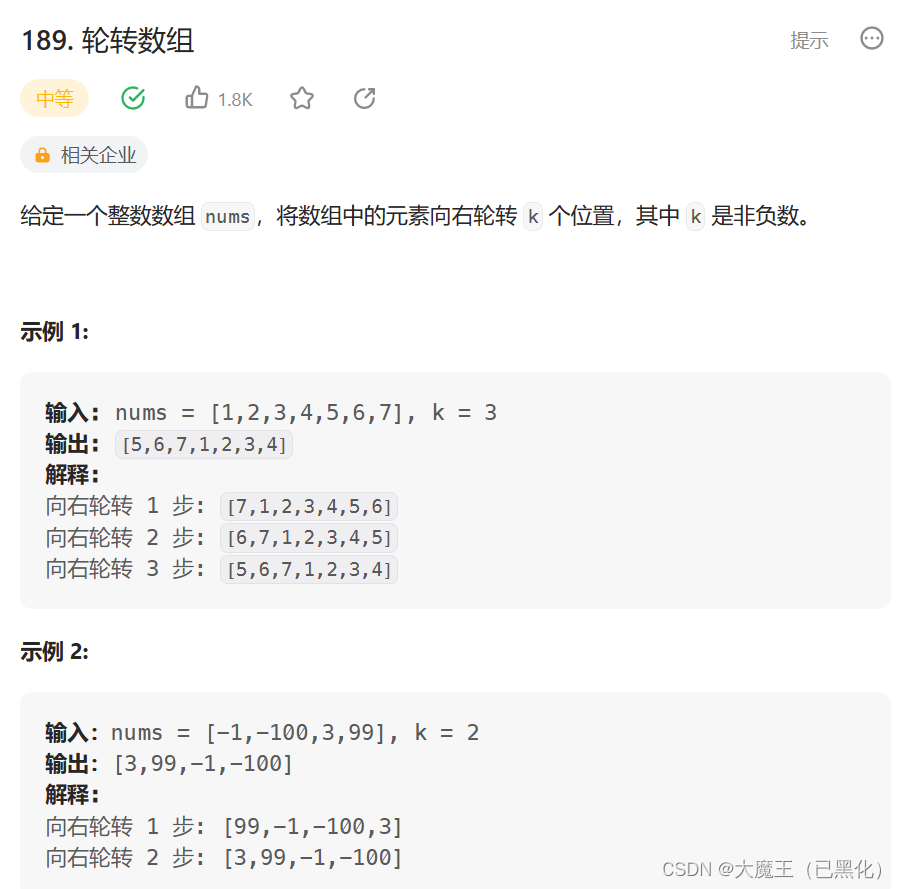
思路
前面有篇博客就是专门讲解这道题的:点我有惊喜!带你玩转字符串旋转问题所以这里就只写最优的方案,也就是空间复杂度为O(1),这个写法的思路需要知道一个技巧:如果是字符串左旋,那么规律就是,假设左旋n个元素,(eg:12345 左旋3个,那么就会变成45123)那么规律就是让前n个倒置,让剩下的倒置,然后再让改变后的字符串整体倒置,我们把这个方法用到上面这个例子:先让前三个倒置:123->321,剩下的倒置:45->54,那么这个字符串就变成了32154,然后我们让整体倒置就变成了45123,和上面的结果是一样的。
但是这一题是右旋,那么我们只需要略微改一下就OK了,假设一共num个数字,当右旋一个的时候,它其实就等价于左旋num-1个。
那么现在就剩下最后一个问题了,那就是倒置,我们用到了多次倒置,所以为了避免重复,复杂,我们把倒置封装成一个函数,每次用的时候直接传参。
实现方法:因为空间复杂度为O(1),所以我们用的是指针,我们每次用倒置函数时只需要传首位地址就好了,然后让它们进去对应交换,然后再调整指针指向另一个位置,具体如代码所示:
代码
void reverse(int* nums,int begin,int end)
{
while(begin<end)
{
int tep = 0;
tep = nums[begin];
nums[begin] = nums[end];
nums[end] = tep;
begin++;
end--;
}
}
void rotate(int* nums, int numsSize, int k){
k = k % numsSize;
k= numsSize - k;
reverse(nums,0,k-1);
reverse(nums,k,numsSize-1);
reverse(nums,0,numsSize-1);
}
二、面试题 17.04. 消失的数字
面试题 17.04. 消失的数字
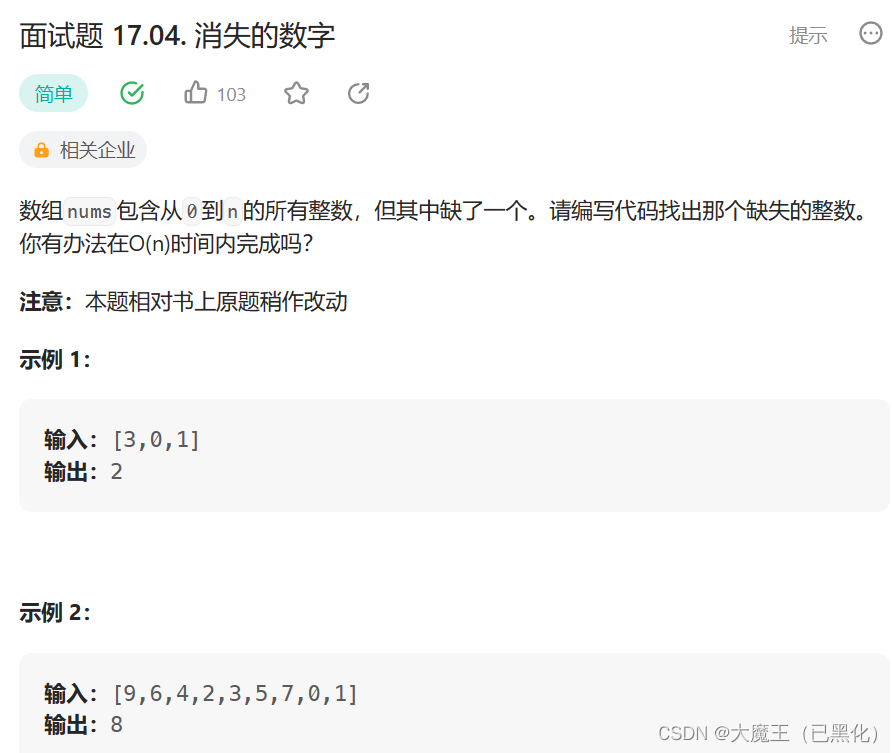
思路
两种方法:
第一种:
是这个题最简单的方法:让数组里的n个数全部相加,再让从0到n+1个自然数相加减去数组相加的值.。
第二种:
让数组里的每个元素都按位异或一次,然后再和0~n+1个自然数按位异或一下,那么结果的数就是缺的那个数。
补充:
按位异或相同的数后结果为0。
按位异或就是二进制位相同为0,不同为1。
代码
第一种
int missingNumber(int* nums, int numsSize){
int n = 0;
for(int i =0;i<numsSize+1;i++)
{
n += i;
}
for(int i = 0;i<numsSize;i++)
{
n -= nums[i];
}
return n;
}
第二种
int missingNumber(int* nums, int numsSize){
int n = 0;
for(int i =0;i<numsSize+1;i++)
{
n ^= i;
}
for(int i = 0;i<numsSize;i++)
{
n = n ^ nums[i];
}
return n;
}
三、27. 移除元素
移除元素

思路
注意题目:原地移除,所以我们不能用最容易想的方法:开辟一个新数组,让不等于val的数依次移过去。但是这样空间复杂度就是O(N),不符合要求。
笨方法:
遍历,每次遇到等于val的数,遍历一次,让这个位置后的都向前移动一次,这样时间复杂度就会是n^2了,效率很低,不过也能过。
正常解法:
这里我们引入双指针的方法:顾名思义,就是同时操纵两个指针,比如这个题,我们让两个指针同时指向然后让一个指针进行判断,如果不等于val,就把自己的指向赋给另一个指针,然后它和另一个指针都指向下一个结点,如果判断指针指向的是val,那么就只让判断指针指向下一个结点,另一个指针不管。实质就是覆盖,这样的结果就是让等于val的数组中的数被后面的覆盖了。具体实现如图:
代码
第一种:笨方法
void DelDate(int* nums, int begin, int end)
{
while(begin<end - 1)
{
nums[begin] = nums[begin + 1];
begin++;
}
}
int removeElement(int* nums, int numsSize, int val) {
int i = 0;
while (i < numsSize)
{
if (nums[i] == val)
{
DelDate(nums, i, numsSize);
numsSize--;
}
else
i++;
}
return numsSize;
}
第二种:正常解法
int removeElement(int* nums, int numsSize, int val) {
int dst = 0;
int front = 0;
while(numsSize--)
{
if(nums[front]!=val)
{
nums[dst] = nums[front];
front++;
dst++;
}
else
{
front++;
}
}
return dst;
}
四、26. 删除有序数组中的重复项
26. 删除有序数组中的重复项

思路
这道题和上面那题很相似,不能开辟额外空间,解法也很相似,也要使用双指针,题上说了给的是升序数组,所以我们的思路可以是这样的:同时创建两个指针,让一个先走,然后看它和第二个指针指向的值是否相等,如果不相等,同时都指向下一个元素,如果相等,就只让这个指针指向下一个元素,第二个指针不动。和上一个原理也是一样的:就是在这个数组中覆盖了不符合要求了(重复的数字)。代码如下:
代码
int removeDuplicates(int* nums, int numsSize){
int dst = 0;
int src = 1;
while(src<numsSize)
{
if(nums[dst]==nums[src])
{
src++;
}
else
{
dst++;
nums[dst] = nums[src];
src++;
}
}
return dst+1;
}
五、88. 合并两个有序数组
88. 合并两个有序数组

思路
非递减顺序:意思就是递增,只不过可能会出现重复项,所以不是完全意义的递增,所以说是非递减顺序。
题目分析:题目要求仍然要按顺序进行两个数组的合并排列,并且合并后是储存在第一个数组中的,第一个数组的大小是第一个数组元素的个数的字节数加第二个数组元素的个数的字节数,也就是如果数组1的元素个数为m,数组2的元素个数为n,那么数组1能存放的元素的个数就是m+n。
提供两种解法:
第一种:
开辟一个新数组空间,大小为数组1的大小,因为数组1的大小是两个数组元素的和,然后用双(三)指针(为什么是三:因为新数组的操纵也要用到一个指针)(和前面的那两题不同,前面那两题是双指针指向同一个数组,这里是分别指向一个数组),都从第一个元素开始,相比较,小的赋给第三个数组,然后第三个数组的指针和指向数小的那个指针都指向下一个元素,然后继续判断,直到有一个结束,那么剩下的操作就是把没有结束的那个数组剩下的元素赋给第三个数组,然后把第三个数组拷贝到第一个数组。
第二种:
因为数组1直接就是1、2数组元素个数整体的大小,那么我们不妨从后面(让两个数组都从最后开始比较大小,然后赋值也是从数组1的最后边开始)开始操纵,从大到小排序,让大的放到数组1的最后面,然后一直进行这样的操作(不会出现还没有判断大小就被覆盖的情况),直到把指针指向的第一个元素判断完,然后把剩下没判断完的那个数组中没判断的元素依次赋过去。当然,如果是数组2判断完了,数组1没判断完,那么就不用执行这一步骤了,因为数组1本来就是递增排序的,再怎么排序也还是这个顺序,但是如果数组2没判断完,数组1提前结束了,那就需要把数组2的覆盖到数组1前面的位置。
代码
第一种
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n){
int* nums3 = malloc(sizeof(int)*(m+n));
int n1 = 0;
int n2 = 0;
int n3 = 0;
while(n1 < m && n2 < n)
{
if(nums1[n1]<nums2[n2])
{
nums3[n3] = nums1[n1];
n1++;
n3++;
}
else
{
nums3[n3] = nums2[n2];
n2++;
n3++;
}
}
if(n1==m)
{
while(n2<n){
nums3[n3] = nums2[n2];
n2++;
n3++;
}
}
else
{
while(n1<m)
{
nums3[n3] = nums1[n1];
n1++;
n3++;
}
}
memcpy(nums1,nums3,sizeof(int)*(m+n));
}
第二种
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {
int dst = m + n - 1;
int src1 = m - 1;
int src2 = n - 1;
while (src1 >= 0 && src2 >= 0)
{
if (nums1[src1] > nums2[src2])
{
nums1[dst] = nums1[src1];
src1--;
dst--;
}
else
{
nums1[dst] = nums2[src2];
src2--;
dst--;
}
}
if (src1 == -1)
{
while (src2 >= 0)
{
nums1[dst--] = nums2[src2--];
}
}
}
六、20. 有效的括号
20. 有效的括号

思路
这个题就是栈的运用,你可以想到,当你理解这个题之后,其实就是栈区规则的实际运用。
思路:我们把字符串中左括号压栈进去,当出现右括号,我们就让栈去出栈一个,并判断出栈的这个和那个右括号是否匹配,括号的匹配就要遵守后进先出的思想,就是当出现右括号时,那么它要和最后一个进去的左括号想匹配,如果不匹配,直接结束,如果匹配,那么就进行之后的判断,直到字符串被遍历完(指向\0)。
代码
typedef char STDateType;
typedef struct Stack
{
STDateType* a;
int top;//如果初始化为0,可以理解为元素个数(也就是栈顶元素下标+1),如果初始化为-1,可以理解为栈顶元素的下标
int capacity;
}ST;
//初始化和最后销毁
void STInit(ST* ps)
{
assert(ps);
//ps->a = malloc(sizeof(ST) * 5); 1.没有强转
ps->a = (STDateType*)malloc(sizeof(STDateType) * 5);
2.开辟新空间后没有检查
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
ps->top = 0;
ps->capacity = 5;
}
void STDestory(ST* ps)
{
assert(ps);
free(ps->a);
ps->capacity = 0;
ps->a = NULL;
1.没有让top也就是栈顶位置重置。
ps->top = 0;
//最后在Test.c上让结构体指针指向空。
}
//判断是否为空
bool STEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
//入栈
void STPush(ST* ps, STDateType x)
{
assert(ps);
//if (ps->top == ps->capacity)
//{
// ST* str = realloc(ps->a, ps->capacity * sizeof(ST) * 2);
// if (str == NULL)
// {
// perror("realloc fail");
// return;
// }
//}
1.没有把扩容的时候创建的新指针赋给原指针
if (ps->top == ps->capacity) //判断是否满了
{
STDateType* temp = (STDateType*)realloc(ps->a, ps->capacity * sizeof(ST) * 2);
if (temp == NULL)
{
perror("realloc fail");
return;
}
else
{
ps->a = temp;
2.忘记让结构体内的容量*2
ps->capacity *= 2;
temp = NULL;
}
}
ps->a[ps->top] = x;
ps->top++;
}
//出栈
void STPop(ST* ps)
{
assert(ps);
assert(!STEmpty(ps));
ps->top--;
}
//元素个数
int STSize(ST* ps)
{
assert(ps);
return ps->top;
}
//栈顶元素
STDateType STTop(ST* ps)
{
assert(ps);
assert(!STEmpty(ps));
return ps->a[ps->top - 1];
}
bool isValid(char* s) {
//判不判断是否为奇数都行,因为就算判断为奇数直接结束返回false,下面那些特殊情况也要写。
//ST* st;//错误:创建的是结构体而不是结构体指针
ST st;
STInit(&st);
while (*s)
{
if (*s == '(' || *s == '{' || *s == '[')
{
STPush(&st, *s);
s++;
}
else
{
if (STEmpty(&st))
{
return false;
}
//自己定义的结构体里的数据类型为int,但是复制粘贴到这个题上时,应该改为char,但是没改。
STDateType top = STTop(&st);
if ((top == '(' && *s != ')') ||
(top == '[' && *s != ']') ||
(top == '{' && *s != '}'))
{
STDestory(&st);
return false;
}
if (st.top == 0)
return false;//如果栈区没有元素,但是却进入循环,说明不匹配。
STPop(&st);
s++;
}
}
//判断栈区是否为空,也就是栈区是否和字符串匹配完。
bool ret = STEmpty(&st);
STDestory(&st);
return ret;
}
前面一大段都是自己先实现的栈区,然后把栈区拷贝过来直接用,这样方便一些。
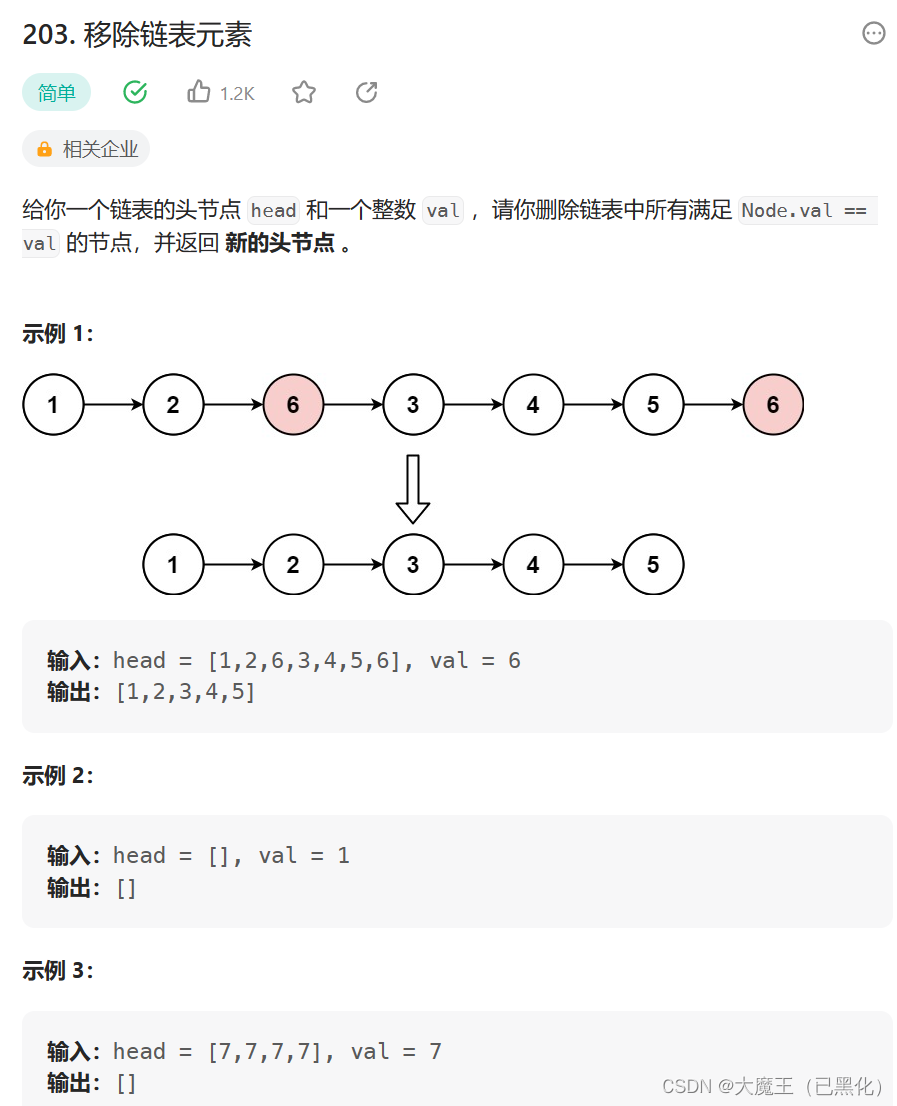
七、203. 移除链表元素
203. 移除链表元素
思路
第一种方法:在当前链表上修改,如果不符合题意,就把不符合题意的这个元素的前一个指向的地址变成这个不符合题意之后的元素,然后释放这个不符合题意的。如果符合题意,那就都指向自己指向的结构体的next,也就是不改变符合条件的结点,只跳过并释放不符合条件的结点。
第二种方法:新建一个链表指向单链表的head,然后在原指针上用一个指针依次判断,如果不符合就跳过,如果符合就让新链表指向的结构体指向的next赋上这个指针,然后新链表指向新赋上的指针,并且原指针也指向原指针指向的下一个结点。
代码
第一种
//解法1.双指针(跳过并释放不符合的结点)
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* cur = head;
struct ListNode* prev = NULL;
while(cur)
{
if(cur->val!=val)
{
prev = cur;
cur = cur->next;
}
else
{
if(prev==NULL)//如果第一个就相同,那么让head改变,不能改变prev,prev只是赋上了head的值,它的指向改变并不影响head的指向,后面不用这样是因为结构体指针可以改变结构体内部的内容。
{
head = head->next;
free(cur);
cur = head;//头指针变了,cur也要跟着变。
}
else
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
}
if(head!=NULL)//如果最后一个元素为val,那么释放后该链表最后指向的就会是被释放的空间,所以赋上NULL;
prev->next = NULL;
return head;
}
第二种
//解法2.创建一个新的链表(虽然还是指向这块链表,但是这次是让他们看作都没连接,让符合条件的重新串起来),然后将满足条件的尾插过去。其实可以看作第一种是两个指针在一个链表上操作,这个可以看作是两个指针都分别操纵一个链表,让符合条件的重新连接起来。
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* cur, * tail, * newhead;
cur = head;
tail = newhead = NULL;
while (cur)
{
if (cur->val != val)
{
if (newhead == NULL)
{
newhead = tail = cur;
cur = cur->next;
}
else
{
tail->next = cur;
tail = cur;
cur = tail->next;
}
}
else
{
struct ListNode* next = cur->next;
free(cur);
cur = next;
}
}
if(tail)
tail->next = NULL;
return newhead;
}
八、206. 反转链表
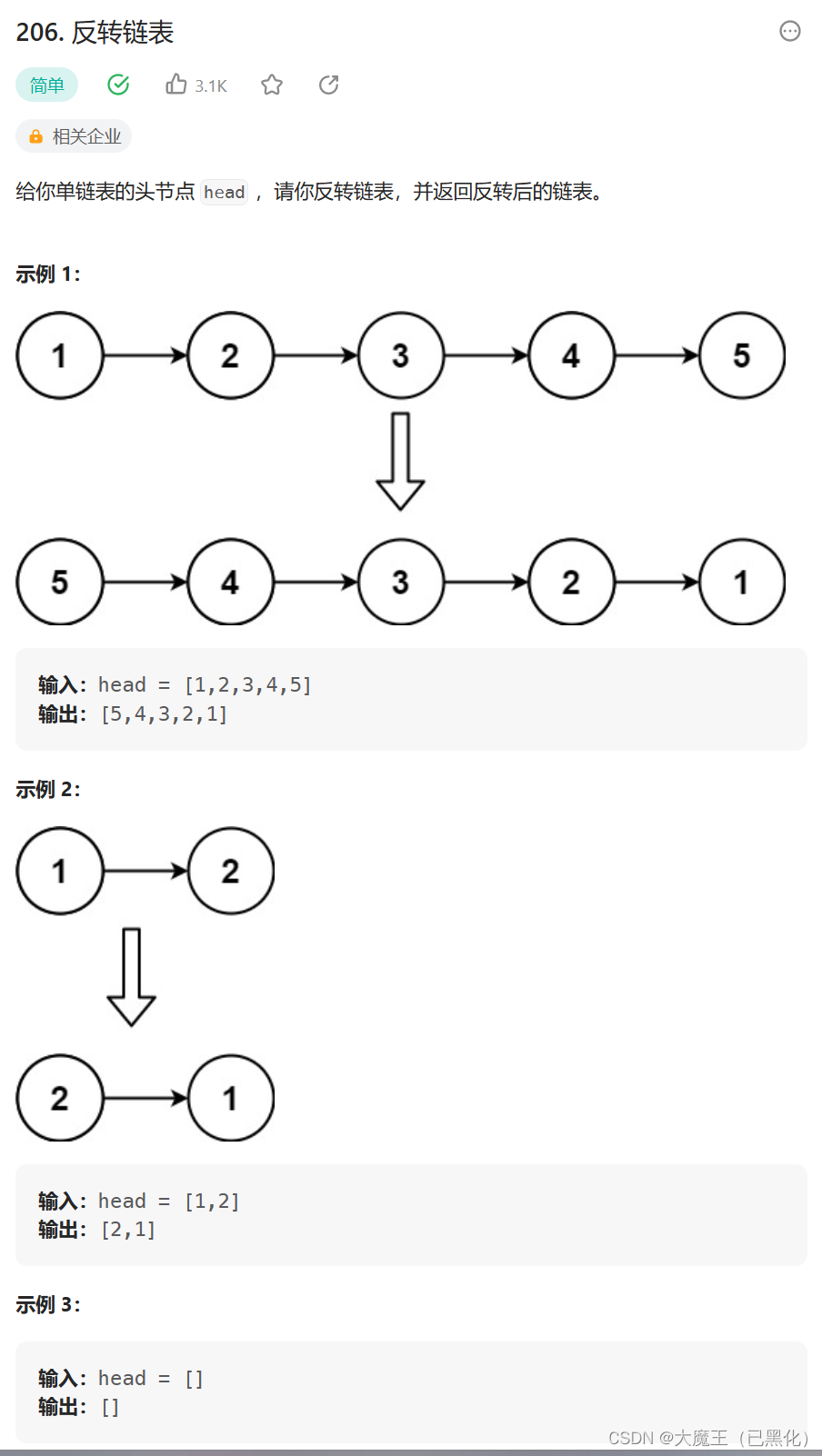
206. 反转链表
思路
思路:
这道题如果做不出来,其实主要的问题就是当我们让第二个结点的next指向的内容变成第一个结点时,那么第3个结点的位置就没了,所以只需要再多创建一个指针存储每次要用但是却要被覆盖的结点的地址就ok了(在被覆盖前把它赋给这个存储结点地址的指针1)。一共创建三个结构体指针,两个是相互操作的,每次操作完都把自己变为自己的下一个结点,第三个指针是存储的,当第二个位置被覆盖为前一个地址后,最前面的指针就找不到下一个结点的位置了,那么我们就需要让第三个指针的值赋给它。
特殊情况:
要记得让第一个结点也就是逆序之后的最后一个节点指向NULL,不然就会死循环了。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
if(head==NULL)
{
return head;
}
struct ListNode* cur = head->next;
struct ListNode* prev = head;
if(cur==NULL)
{
return head;
}
while(cur)
{
if(prev==head)
{
prev->next = NULL;
}
struct ListNode* next = cur->next;
cur->next = prev;
prev = cur;
cur = next;
}
return prev;
}
九、876. 链表的中间结点
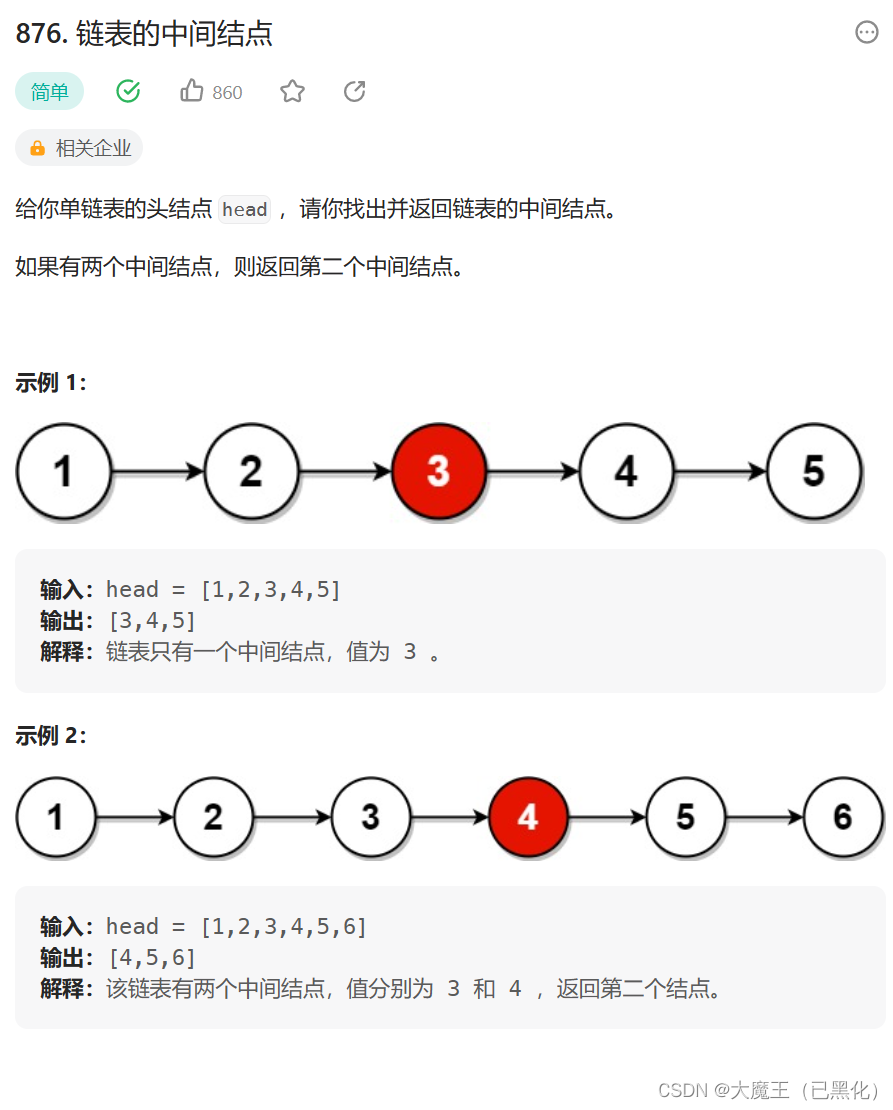
876. 链表的中间结点
思路
这道题用到一个新的方法:快慢指针,慢指针一次跳一个结点,快指针指向每次跳过两个结点。
如果是奇数个结点,那么就让快指针指向的是NULL的时候结束,返回慢指针。
如果是偶数个结点,那么就让快指针为NULL时结束,返回慢指针。
所以合起来就是当快指针是NULL或指向NULL的时候停止,返回慢指针。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* fast,* slow;
fast = slow = head;
while(fast!=NULL&&fast->next!=NULL)
{
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
十、链表中倒数第k个结点
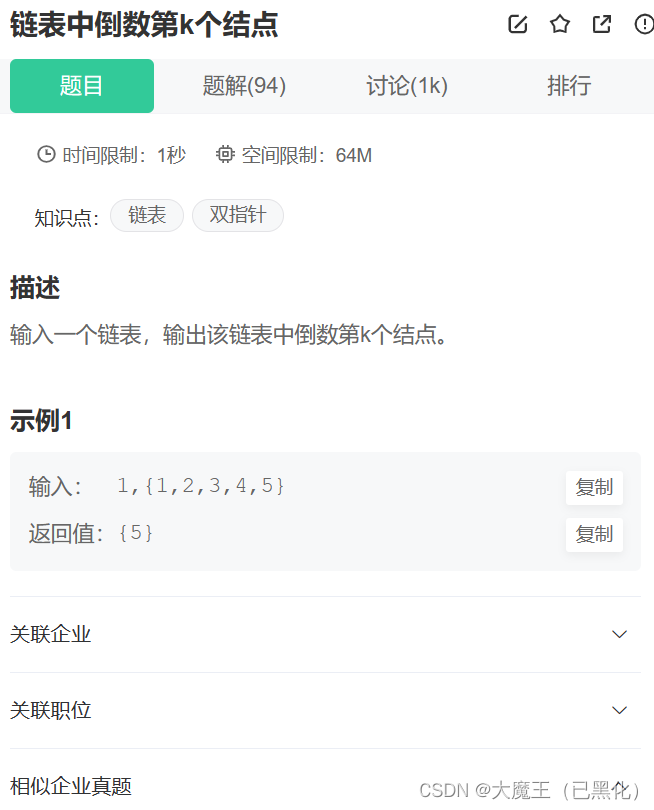
十、链表中倒数第k个结点
思路
这题和上一题相似,也是用的快慢指针的方法:让快指针先走k个,然后一起走,最后当快指针位NULL时,慢指针就是倒数第k个结点。
代码
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
struct ListNode* prev, *cur;
prev = cur = pListHead;
if (k <= 0) {
return NULL;
}
if (pListHead == NULL) {
return NULL;
}
while (k--) {
cur = cur->next;
if (cur == NULL && k >= 1) {
return NULL;
}
}
while (cur) {
cur = cur->next;
prev = prev->next;
}
return prev;
}
有的判断部分读题可能并不能直到,是根据输出样例来判断的,比如如果k大于链表结点的个数,要返回NULL;如果k小于等于0,也需要返回NULL。
十一、21. 合并两个有序链表
21. 合并两个有序链表
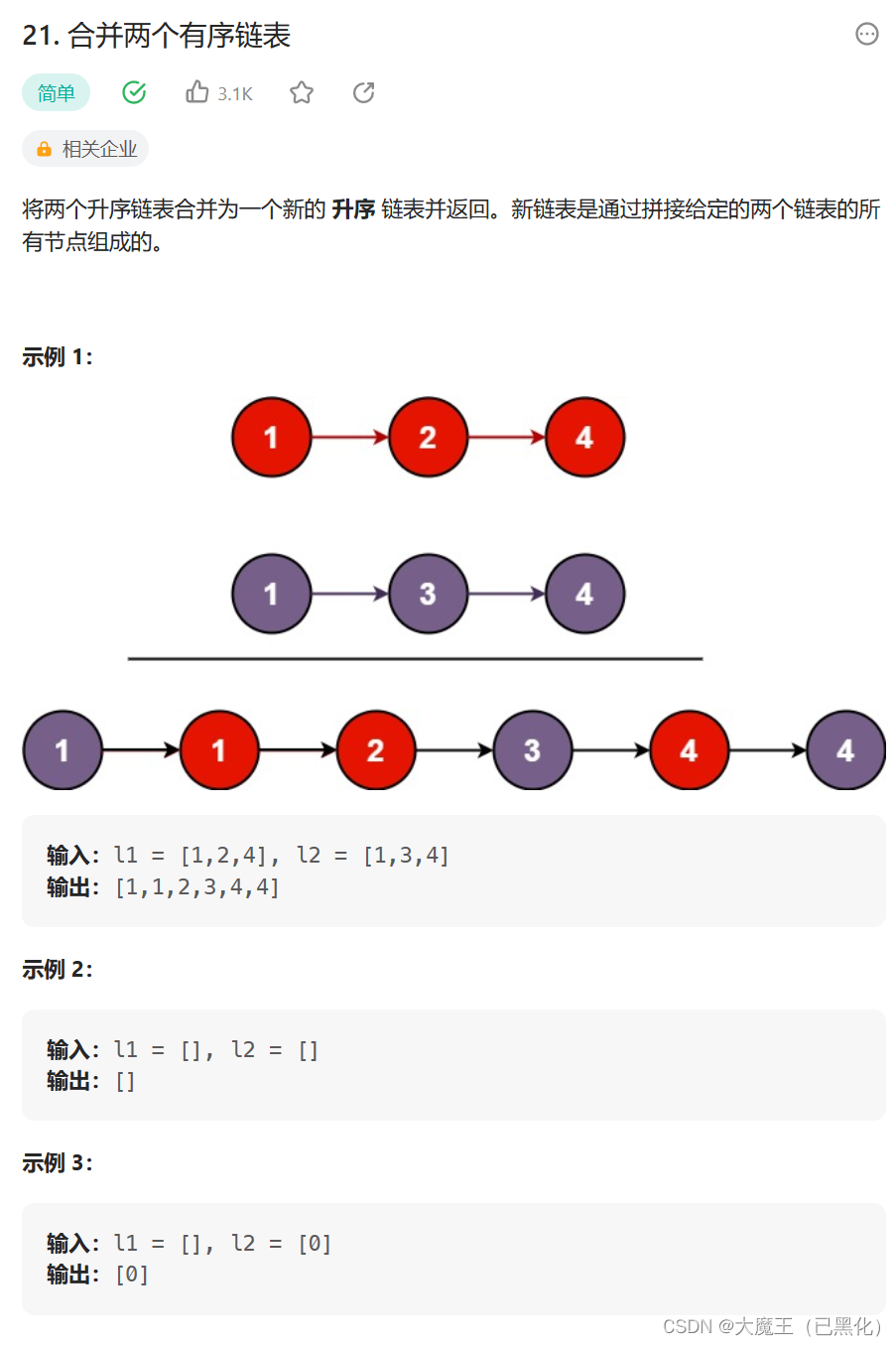
思路
创建三个指针,两个分别对象两个链表,另一个是进行重新连接的,也算是新链表,让链表里的元素这个判断大小,小的连接到新链表上,直到一个链表结束,然后让新链表最后有一个结点指向没结束的链表。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
struct ListNode* cur1, * cur2, * newhead, * newcur;
cur1 = list1;
cur2 = list2;
newhead = newcur = NULL;
if (cur1 == NULL && cur2 == NULL)
return NULL;
if (cur1 == NULL)
{
return cur2;
}
if (cur2 == NULL)
{
return cur1;
}
while (cur1 && cur2)
{
if (cur1->val < cur2->val)
{
if (newhead == NULL)
{
newhead = newcur = cur1;
cur1 = cur1->next;
}
else
{
newcur->next = cur1;
newcur = cur1;
cur1 = cur1->next;
}
}
else
{
if (newhead == NULL)
{
newhead = newcur = cur2;
cur2 = cur2->next;
}
else
{
newcur->next = cur2;
newcur = cur2;
cur2 = cur2->next;
}
}
}
if (cur1 == NULL)
{
newcur->next = cur2;
}
else
{
newcur->next = cur1;
}
return newhead;
}
十二、总结

✨请点击下面进入主页关注大魔王
如果感觉对你有用的话,就点我进入主页关注我吧!