文章目录
- 循环神经网络(RNN)入门教程
- 1. 循环神经网络的原理
- 2. 循环神经网络的应用
- 3. 使用keras框架实现循环神经网络
- 3.1导入对应的库及加载数据集
- 3.2.数据预处理
- 3.3定义RNN模型
- 3.4训练模型
- 3.5测试模型
- 4.使用PyTorch框架实现上述功能—注释详细
- 5.结论
循环神经网络(RNN)入门教程
循环神经网络(Recurrent Neural Networks,RNN)是一类具有记忆功能的神经网络,主要应用于序列数据的建模和处理,例如自然语言文本和音频、视频。与前馈神经网络不同,RNN网络中的神经元可以接受自身过去的输出作为输入,从而实现对序列数据的记忆和预测。常见的RNN模型包括基本循环神经网络、长短期记忆网络(LSTM)和门控循环单元(GRU)等。
在本教程中,我们将介绍循环神经网络的基本原理和应用,以及如何使用keras框架和pytorch框架实现一个简单的循环神经网络模型。
1. 循环神经网络的原理
循环神经网络的主要特点是它可以处理具有时间序列结构的数据。它的神经元之间存在循环连接,使得当前时刻的输入和前一时刻的输出可以共同影响当前时刻的输出。这种结构使得循环神经网络可以处理变长的时间序列数据,而且不需要预先确定时间序列的长度。
给出简单的循环神经网络结构图,包括5个时间步长和一个输入序列 ( x 1 , x 2 , . . . , x 5 ) (x1, x2, ..., x5) (x1,x2,...,x5),以及对应的隐藏状态 ( h 0 , h 1 , . . . , h 5 ) (h0, h1, ..., h5) (h0,h1,...,h5) 和输出序列 ( y 1 , y 2 , . . . , y 5 ) (y1, y2, ..., y5) (y1,y2,...,y5) ,循环神经网络的基本结构如下图所示:
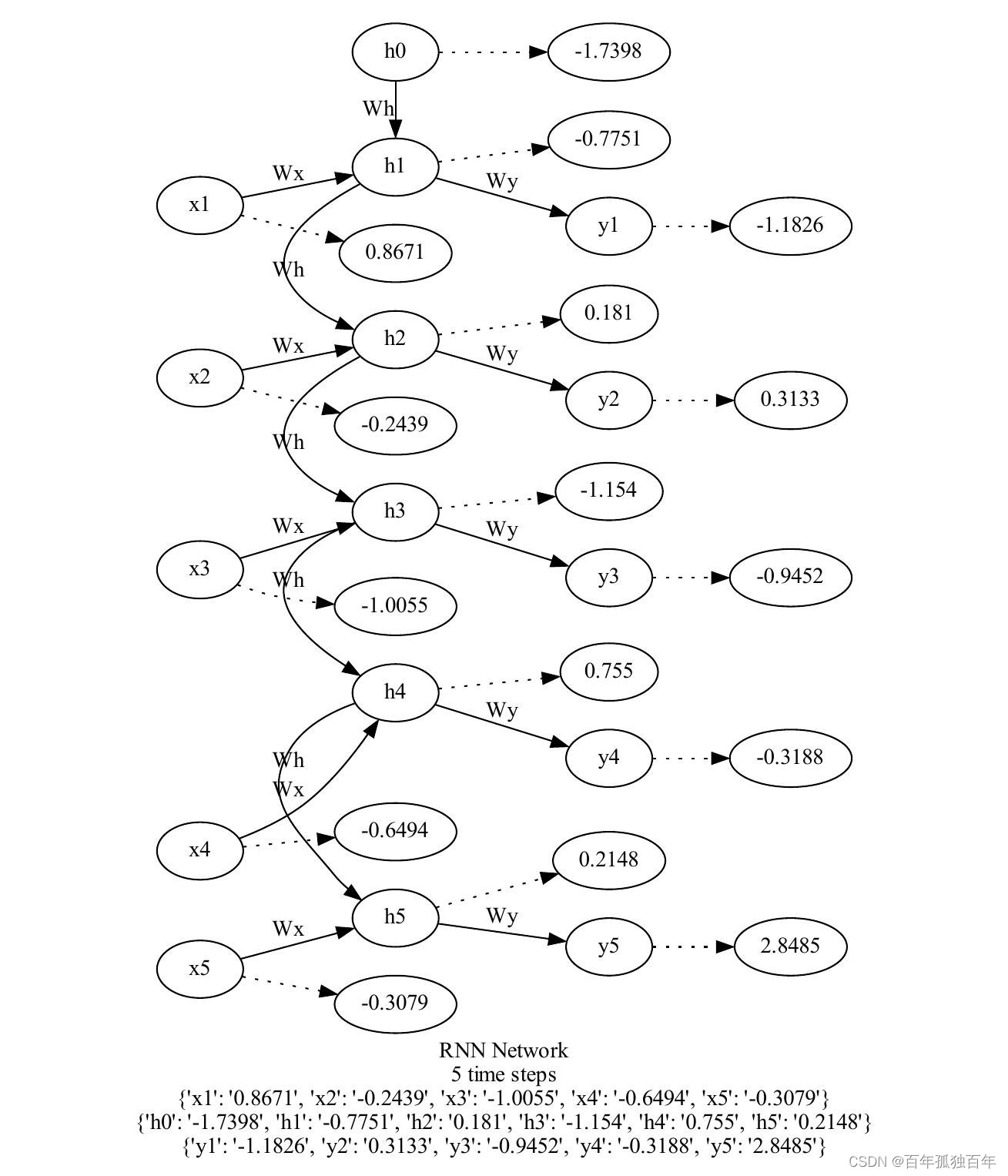
循环神经网络(RNN)是一种通过逐个处理序列中的元素来处理序列的神经网络。在每个时间步长t,RNN都会根据当前的输入
x
t
x_{t}
xt和先前的隐藏状态
h
t
−
1
h_{t-1}
ht−1计算出新的隐藏状态
h
t
h_{t}
ht和输出
y
t
y_{t}
yt。我们可以使用以下公式来表示RNN的计算过程:
h
t
=
f
h
(
W
x
x
t
+
W
h
h
t
−
1
+
b
h
)
h_t = f_{h}(W_{x}x_{t} + W_{h}h_{t-1} + b_h)
ht=fh(Wxxt+Whht−1+bh)
y t = f y ( W y h t + b y ) y_t = f_{y}(W_{y}h_t + b_y) yt=fy(Wyht+by)
其中, W x W_{x} Wx和 W h W_{h} Wh是输入和隐藏状态之间的权重矩阵, W y W_{y} Wy是隐藏状态和输出之间的权重矩阵, b h b_h bh和 b y b_y by是偏置项, f h f_{h} fh和 f y f_{y} fy是激活函数,通常是tanh或ReLU。
这个公式表示了RNN在一个时间步长t如何计算新的隐藏状态 h t h_{t} ht和输出 y t y_{t} yt。在这个公式中,我们首先将输入 x t x_{t} xt和先前的隐藏状态 h t − 1 h_{t-1} ht−1合并起来,使用权重矩阵相乘,然后加上偏置项 b h b_{h} bh。接下来我们通过激活函数 f h f_{h} fh来对这个合并后的向量进行非线性变换,从而得到新的隐藏状态 h t h_{t} ht。最后,我们使用新的隐藏状态 h t h_{t} ht和权重矩阵 W y W_{y} Wy来计算输出 y t y_{t} yt,并通过激活函数 f y f_{y} fy对其进行非线性变换。
通过重复使用这个公式来处理序列中的每个元素,我们可以构建一个循环神经网络,并使用它来预测具有时序特征的数据。
当用于多分类问题时,其中
f
y
f_y
fy就会变成softmax的激活函数,如下:
y
t
=
s
o
f
t
m
a
x
(
W
y
h
t
+
b
y
)
y_t = softmax(W_{y}h_t + b_y)
yt=softmax(Wyht+by)
2. 循环神经网络的应用
循环神经网络可以应用于多种任务,包括:
- 语言模型:预测下一个单词或字符
- 机器翻译:将一种语言翻译成另一种语言
- 语音识别:将语音转换成文本
- 图像描述生成:根据图像生成相应的文字描述
- 情感分析:根据文本判断情感是积极还是消极
3. 使用keras框架实现循环神经网络
我们使用Python和Keras框架来实现一个简单的循环神经网络模型。我们将使用MNIST数据集来演示模型的训练和测试。
3.1导入对应的库及加载数据集
首先,我们需要导入所需的库:
from keras.datasets import mnist # 从keras.datasets中导入MNIST数据集
from keras.models import Sequential # 导入Sequential模型
from keras.layers import SimpleRNN, Dense # 导入SimpleRNN层和Dense层
from keras.utils import to_categorical # 导入to_categorical函数
接下来,我们需要加载MNIST数据集并进行预处理:
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
3.2.数据预处理
# 数据预处理,将每个像素点的值归一化到0到1之间,并将标签进行独热编码
x_train = x_train.reshape(-1, 28, 28) / 255.0
x_test = x_test.reshape(-1, 28, 28) / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
在上面的代码中,我们使用mnist.load_data()函数加载MNIST数据集,并对数据进行预处理,将每个像素点的值归一化到0到1之间,并将标签进行独热编码。
3.3定义RNN模型
接下来,我们定义一个简单的循环神经网络模型:
# 定义一个简单的循环神经网络模型
model = Sequential() # 定义顺序模型
model.add(SimpleRNN(units=32, input_shape=(28, 28))) # 添加SimpleRNN层
model.add(Dense(units=10, activation='softmax')) # 添加全连接层
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 编译模型,指定损失函数、优化器和评价指标
在上面的代码中,我们使用Sequential类定义一个顺序模型,并添加一个SimpleRNN层和一个全连接层。SimpleRNN层有32个神经元,输入维度为(28,28),表示输入是28个时间步长,每个时间步长的输入维度为28。全连接层有10个神经元,使用softmax作为激活函数,表示输出的概率分布。我们使用categorical_crossentropy作为损失函数,adam作为优化器,并将准确率作为评价指标。
3.4训练模型
接下来,我们训练模型:
# 训练模型
model.fit(x_train, y_train, batch_size=64, epochs=10, validation_data=(x_test, y_test))
在上面的代码中,我们使用fit方法对模型进行训练,将训练数据集和标签作为输入,设置批量大小为64,迭代次数为10次,并将测试数据集作为验证集。训练过程中,模型会输出每个epoch的损失和准确率。
3.5测试模型
最后,我们使用测试数据集对模型进行测试:
# 使用测试数据集对模型进行测试
loss, accuracy = model.evaluate(x_test, y_test)
print('Test loss:', loss)
print('Test accuracy:', accuracy)
在上面的代码中,我们使用evaluate方法对模型进行测试,并输出测试集的损失和准确率。
4.使用PyTorch框架实现上述功能—注释详细
import torch # 导入PyTorch
import torch.nn as nn # 导入PyTorch的神经网络模块
import torchvision.datasets as dsets # 导入PyTorch的数据集模块
import torchvision.transforms as transforms # 导入PyTorch的数据预处理模块
# 定义超参数
input_size = 28 # 输入层大小,图片大小为28x28
sequence_length = 28 # 序列长度,每个序列表示一行像素
num_layers = 1 # 网络层数
hidden_size = 32 # 隐藏层大小
num_classes = 10 # 输出类别数量
batch_size = 64 # 每个小批次大小
num_epochs = 10 # 迭代次数
learning_rate = 0.001 # 学习率
# 加载MNIST数据集
train_dataset = dsets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) # 加载训练集
test_dataset = dsets.MNIST(root='./data', train=False, transform=transforms.ToTensor()) # 加载测试集
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) # 创建训练数据加载器
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) # 创建测试数据加载器
# 定义一个简单的循环神经网络模型
class RNN(nn.Module): # 定义RNN类,继承自nn.Module
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__() # 调用父类的构造函数
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # 定义RNN层
self.fc = nn.Linear(hidden_size, num_classes) # 定义全连接层
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) # 初始化隐藏状态h0
out, _ = self.rnn(x, h0) # 前向传播,输出out和最终隐藏状态
out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出,传入全连接层
return out
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 判断是否支持GPU加速
model = RNN(input_size, hidden_size, num_layers, num_classes).to(device) # 定义模型,并将其移动到GPU上
criterion = nn.CrossEntropyLoss() # 定义损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # 定义优化器
# 训练模型
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.reshape(-1, sequence_length, input_size).to(device) # 将图片数据reshape成[batch_size, sequence_length, input_size]大小,并移动到GPU上
labels = labels.to(device) # 将标签数据移动到GPU上
outputs = model(images) # 前向传播,计算模型输出
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新权重和偏置
if (i+1) % 100 == 0: # 每训练100个小批次,输出一次信息
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))
# 测试模型
with torch.no_grad(): # 禁用梯度计算,加速推理过程
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, sequence_length, input_size).to(device) # 将图片数据reshape成[batch_size, sequence_length, input_size]大小,并移动到GPU上
labels = labels.to(device) # 将标签数据移动到GPU上
outputs = model(images) # 前向传播,计算模型输出
_, predicted = torch.max(outputs.data, 1) # 取最大值作为预测结果
total += labels.size(0) # 累加样本数量
correct += (predicted == labels).sum().item() # 累加正确预测的样本数量
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total)) # 输出模型测试精度
5.结论
在本教程中,我们介绍了循环神经网络的基本原理和应用,以及如何使用Python和Keras框架实现一个简单的循环神经网络模型。循环神经网络是一种强大的神经网络结构,可以处理具有时间序列结构的数据,并且在自然语言处理、语音识别、图像处理等领域具有广泛的应用。