CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
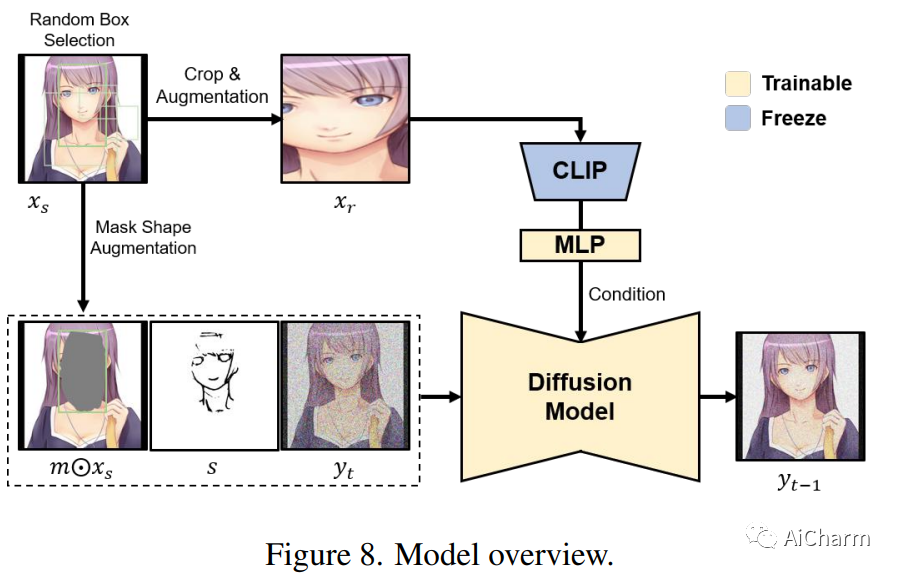
1.Reference-based Image Composition with Sketch via Structure-aware Diffusion Model

标题:通过结构感知扩散模型与草图进行基于参考的图像合成
作者:Kangyeol Kim, Sunghyun Park, Junsoo Lee, Jaegul Choo
文章链接:https://arxiv.org/abs/2304.09748
项目代码:https://github.com/kangyeolk/Paint-by-Sketch


摘要:
最近大规模文本到图像生成模型的显着改进在生成高保真图像方面显示出有希望的结果。为了进一步增强可编辑性并实现细粒度生成,我们引入了一种多输入条件图像合成模型,该模型将草图作为一种新颖的模态与参考图像结合在一起。由于使用草图的边缘级可控性,我们的方法使用户能够编辑或完成具有所需结构(即草图)和内容(即参考图像)的图像子部分。我们的框架微调预训练扩散模型以使用参考图像完成缺失区域,同时保持草图引导。尽管简单,但这会带来广泛的机会来满足用户获取所需图像的需求。通过广泛的实验,我们证明我们提出的方法为图像处理提供了独特的用例,支持用户驱动的任意场景修改。
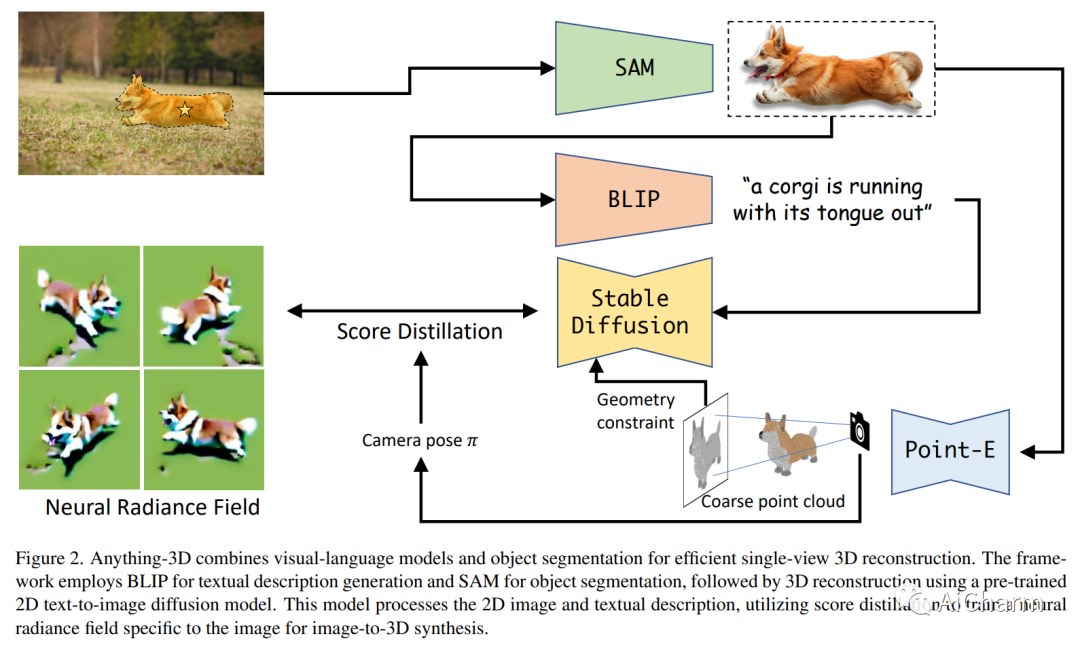
2.Anything-3D: Towards Single-view Anything Reconstruction in the Wild

标题:Anything-3D:迈向野外的单视图任何重建
作者:Qiuhong Shen, Xingyi Yang, Xinchao Wang
文章链接:https://arxiv.org/abs/2304.06018
项目代码:https://github.com/Anything-of-anything/Anything-3D
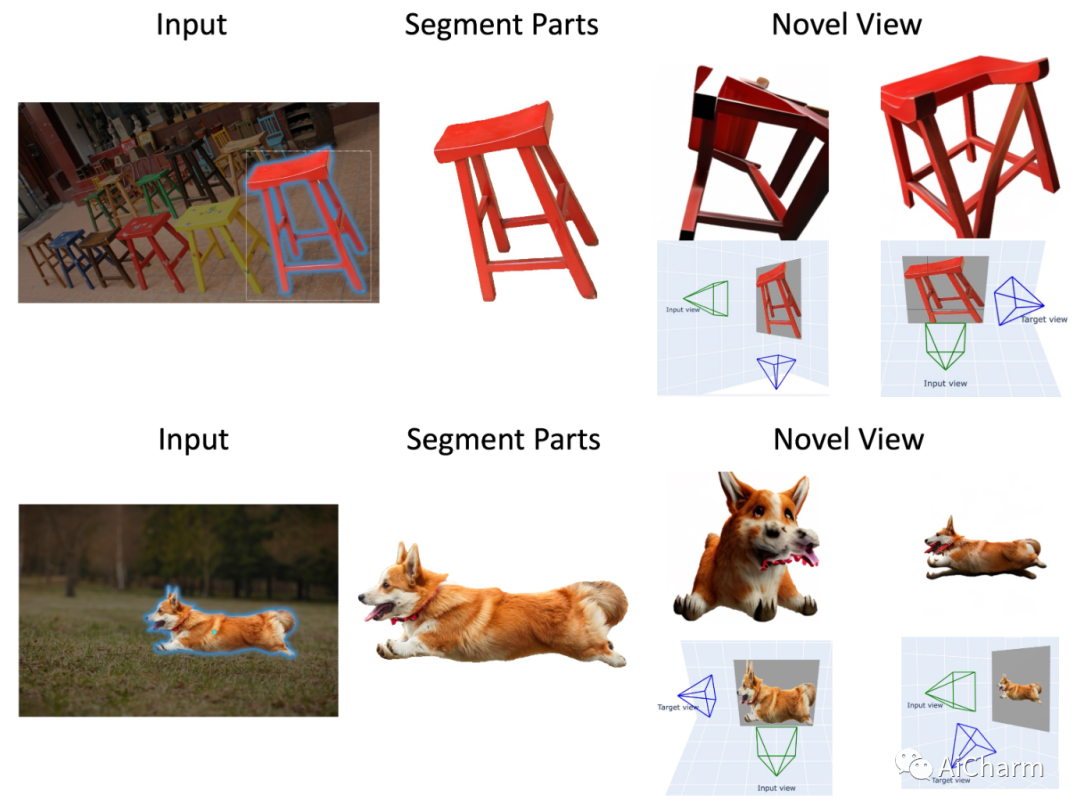
摘要:
由于物体和环境固有的多样性和复杂性,在不受约束的现实世界场景中从单 RGB 图像进行 3D 重建提出了许多挑战。在本文中,我们介绍了 Anything-3D,这是一个巧妙地结合了一系列视觉语言模型和 Segment-Anything 对象分割模型以将对象提升为 3D 的系统框架,从而为单视图条件 3D 重建提供了可靠且通用的系统任务。我们的方法采用 BLIP 模型生成纹理描述,利用 Segment-Anything 模型有效提取感兴趣的对象,并利用文本到图像扩散模型将对象提升到神经辐射场。\emph{Anything-3D\footnotemark[2]} 展示了其为各种对象生成准确和详细的 3D 重建的能力,显示了解决现有方法局限性的希望。通过对各种数据集的综合实验和评估,我们展示了我们方法的优点,强调了它在 3D 重建领域做出有意义贡献的潜力。
3.ReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects

标题:ReLight My NeRF:用于现实世界对象的新颖视图合成和重新照明的数据集
作者:Marco Toschi, Riccardo De Matteo, Riccardo Spezialetti, Daniele De Gregorio, Luigi Di Stefano, Samuele Salti
文章链接:https://arxiv.org/abs/2304.10448
项目代码:https://eyecan-ai.github.io/rene/
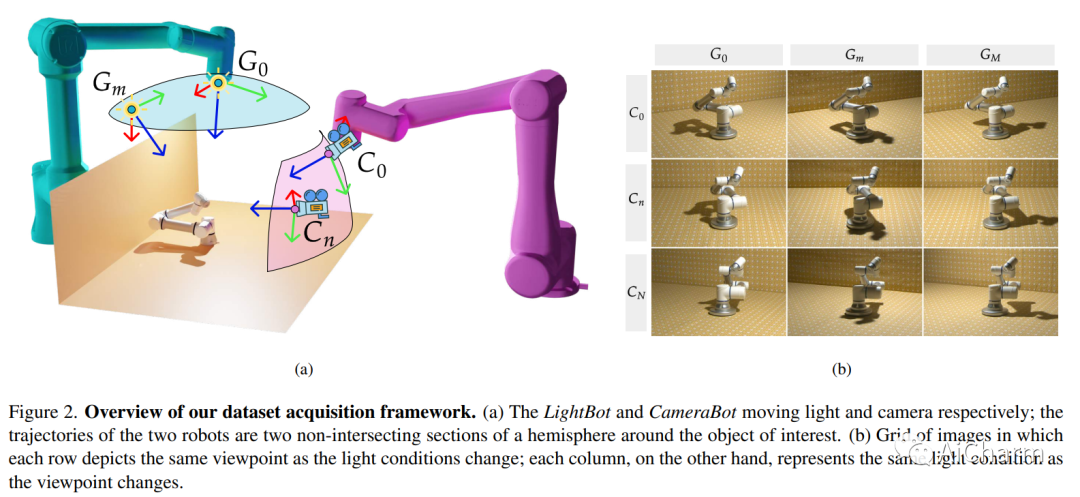
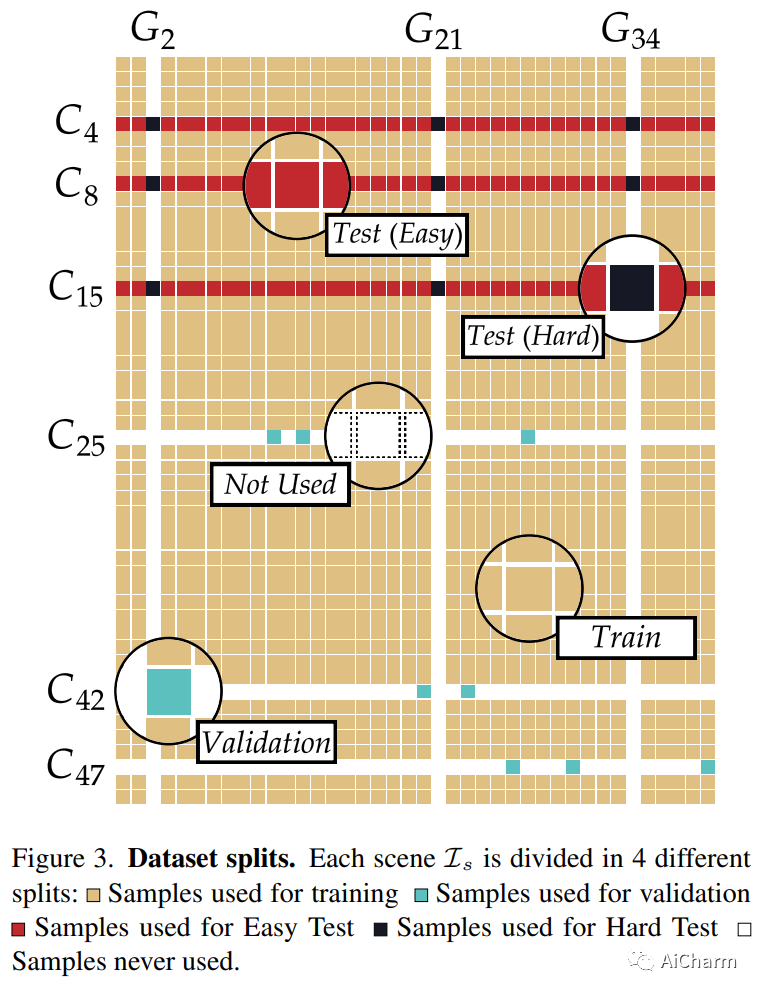
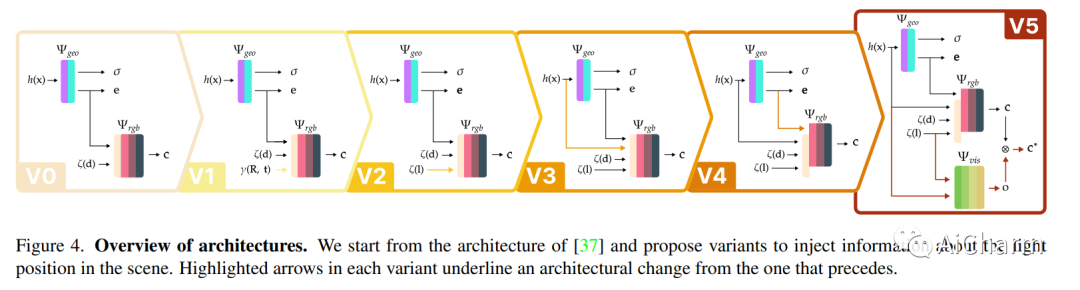


摘要:
在本文中,我们关注在未观察到的光照条件下从神经辐射场 (NeRF) 渲染新视图的问题。为此,我们引入了一个新的数据集,称为 ReNe (Relighting NeRF),在一次一光 (OLAT) 条件下构建真实世界的对象,并用准确的地面实况相机和光姿态进行注释。我们的采集管道利用两个机械臂,分别拿着一个相机和一个全向点光源。我们总共发布了 20 个场景,描绘了具有复杂几何形状和具有挑战性材料的各种物体。每个场景包括 2000 张图像,这些图像是在 40 种不同的 OLAT 条件下从 50 个不同的视角获取的。通过利用数据集,我们对普通 NeRF 架构变体的重新照明能力进行了消融研究,并确定了一种轻量级架构,该架构可以在新颖的光照条件下呈现物体的新颖视图,我们使用它来建立一个重要的基线数据集。
更多Ai资讯:公主号AiCharm