文章目录
- 1. 前言
- 2. 性能分析概述
- 3. 性能分析方法论一览
- 3.1 TSA 和 USE
- 3.1.1 TSA
- 3.1.1.1 TSA 概述
- 3.1.1.2 TSA 状态转换
- 3.1.1.3 延迟类状态
- 3.1.1.3 TSA 总结
- 3.1.2 USE
- 3.1.2.1 USE 简介
- 3.1.2.2 低利用率是否意味着没有饱和?
- 3.1.2.3 使用 USE
- 3.1.2.3 常见资源列表 和 它们的测量指标
- 3.1.2.4 USE 总结
- 3.2 Intel TMA
- 3.3 其它
- 4. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 性能分析概述
通常,我们是通过理论指导实践,而实践又反哺完善理论,二者缺一不可。
总的来说,性能优化是从 时间 和 空间 两方面做出优化,然后取得一个可接受的平衡点。记住,无论怎么优化,也无法超出物理硬件的极限,假设 CPU 的最高频率是 1.5GHz ,就不可能优化出 1.6GHz 的效果。
在现在复杂的系统中,包含很多软硬件资源,硬件资源如 CPU、内存、磁盘、网络、GPU 、音视频Codec等等等等,软件资源包括各个软件模块、第三方库等等等,每一个都有可能成为我们优化的目标;从全局考虑(考虑所有软硬件资源),或者从某个局部考虑(只考虑某个或某几个软硬件资源),需要采用的优化方法可能又不一样。
当我们遇到一个性能问题,该当如何下手?通盘考虑全局所有资源,让每个部分达到最佳,当然是我们最想要的。但是,有时候这并不现实,譬如程序使用了一个第三方库,而它又不开源,那很可能你无法优化它;又或者,我们只需要将程序某个功能点的执行速度提高5%,这时候可能不需要考虑全局优化,仅仅针对某个点就可以了。所以,对于优化,我认为第一步要做的,就是要确定优化的目标。同时,我们也应该考虑可行性,最高频 1.5GHz 的 CPU 永远也无法跑出 1.6GHz 的效果。当然,可行性有时候不是那么一目了然,那就只能试试看了。
3. 性能分析方法论一览
对于 Linux 下的性能分析,可能我们通常的做法是:用 top 或类似工具,对程序做基本观察,确定程序是 CPU 密集型(也称 计算密集型) 还是 IO 密集型,然后来进行优化。但世界哪有那么简单,一个程序,可能有时候是 CPU 密集型 ,有时候又呈现为 IO 密集型 ;有的线程是 CPU 密集型 ,有的线程又是 IO 密集型 。多进程系统通常不可能只有一个程序在运行,程序相互之间也可能对彼此的性能造成妨害。程序当前可能运行在用户空间,也可能运行于内核空间系统调用,有时候瓶颈在于内核,有时候瓶颈又在用户空间……总之各种情形都有,不一而足。为应对各种情形,我们应该有一些方法论,作为一般性的指导,告诉我们该怎样一步步来定位分析性能问题。
3.1 TSA 和 USE
TSA 和 USE 是性能分析大佬 Brendan Gregg 提出的性能分析方法论。
3.1.1 TSA
3.1.1.1 TSA 概述
TSA 是 Thread State Analysis 的缩写,直译过来就是 线程状态分析 。该方法总结为:
1. 对每个观测线程,测试线程在各个不同状态下的总时间;
2. 使用合适的工具,根据观测到的线程在不同状态的总时间,按总时间由长到短对线程的各状态进行观测.
上面用术语“线程”来指代系统中的可运行实体,它们可能是线程、任务、进程。
线程消耗的总时间,可划分到各个不同线程状态。下面划分了6种线程状态,作为关键信息源,用来标识分析性能相关问题:
. Executing: 在CPU上执行。
在CPU上执行的时间,又细分为系统时间和用户时间。
对于系统时间,观测CPU时间以及系统调用频率;对于用户时间,观测CPU时间。
注意,CPU时间可能包含在自旋锁上自旋的时间。
. Runnable: 等待调度到CPU行执行。
等待调度的时间,可以观察CPU的利用率和饱和率、施加的各种资源限制(如cgroup
等)、进程CPU绑定。
. Anonymous Paging: 类似于Runnable,但是在等待进行页换出处理。
检查系统内存的使用状况、资源限制状态检查(如memcg等)。
. Sleeping: 等待I/O状态, 包括网络、磁盘 等I/O操作。
检查系统调用的时间和相关资源、mmap()引发的I/O;检查资源忙碌状态;
通过off-cpu分析工具检查线程阻塞。
. Lock: 等待获取同步锁。
观察线程等待的锁、造成锁等待的原因,以及锁机制分析。
. Idle: 空闲状态,无事可干,等待分配工作。
这个状态列表,在不同的操作系统下,可能要做些调整,取决于用来测量评估工具报告的状态。观察这些线程状态的工具,如 Linux 下的 top, mpstat, prstat 等等。有些监视程序,可能将时间消耗归结到某个程序组件,如时间消耗在 MySQL,PHP 等线程,这种方法称为 面向请求(request-oriented) 的方法,这种方法可能造成误导,这时可以通过 TSA 方法来搞清楚真正的原因,通过调查发现,MySQL 线程的大部分 Runnable 状态,即等待被调度到 CPU 执行,这也就意味着,实际上是别的线程占用了 CPU 时间,而不是 MySQL 线程,所以 面向请求(request-oriented) 方法的结论造成了误导,但通过 TSA 可以修正它,这样引导我们可以将注意力转移到真正消耗 CPU 时间的线程上去。
3.1.1.2 TSA 状态转换
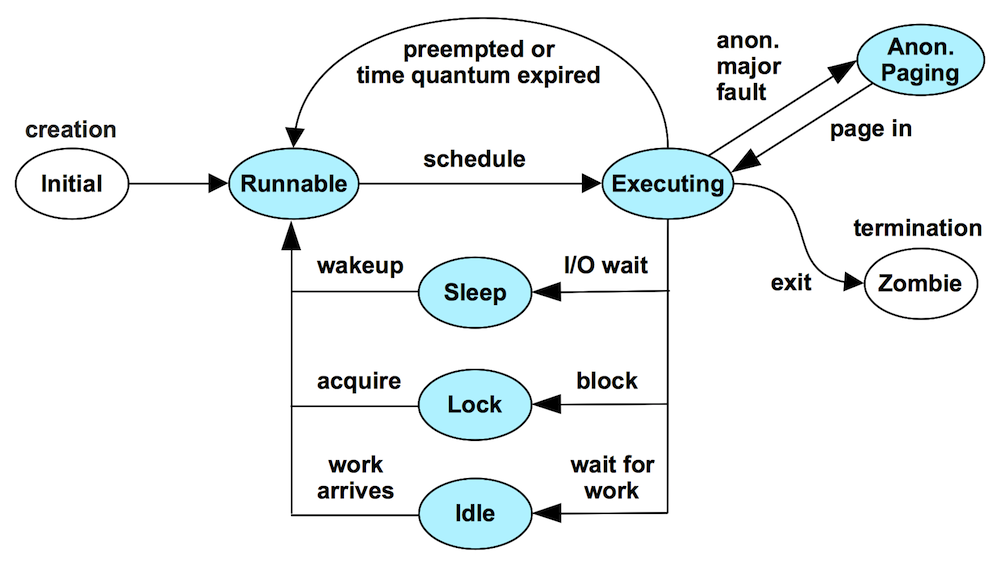
3.1.1.3 延迟类状态
将 Runnable, Anonymous Paging, Sleeping, Lock 这4个状态统称为 延迟类状态,一旦发现这类状态的时间超过了 10% ,通常可以转为检查其它状态的时间消耗,这可以简化分析过程。
3.1.1.3 TSA 总结
TSA 方法是一个简单的、用来分析每线程性能的方法,它为性能分析提供一个起点和方向。在分析的早期,可以使用个方法,和后述的 USE 方法一起,对性能问题起到基本的了解。
3.1.2 USE
3.1.2.1 USE 简介
USE 是 Utilization Saturation and Errors 的缩写,是一种用列举的 检查清单 来分析性能问题的方法。该方法从提出问题开始,然后寻求问题的答案;而不是从给定的测量结果,然后逆向寻求答案。针对不同的操作系统,USE 方法使用的 检查清单 各不相同。USE 方法可以总结为:
对每个资源,检查 利用率、饱和度、错误状态。
USE 方法旨在用于性能分析的早期,以确定系统瓶颈。为方便后面的阐述,先给出几个术语定义:
资源: CPU, 磁盘, 网络, mutex, ...
利用率: 【资源】处于忙碌状态的平均时间。也可以说成资源已使用的比例,譬如100%表示不能接收更多的工作。
饱和度: 【资源】不能处理的额外工作的程度。如【资源】上等待队列的长度。可以描述【资源】竞争的激烈程度。
错误状态: 【资源】错误事件计数。
这 3 个指标可能以如下形式描述:
利用率: 一段时间内的百分比,如一个磁盘以 90% 的利用率在运行。
饱和度: 队列长度。如 CPU 的平均运行队列长度为 4 。
错误状态:如网络接口发生50次冲突错误。
对错误状态应该引起重视,因为它们会降低性能。这在它们可恢复时,可能不会被注意到。
CPU 缓存 和 其它未列出的资源,可以在 USE 方法之后检查 - 在排除系统瓶颈之后。如果不确定是否要添加上述列表之外的资源到检查清单,请包含该资源,然后查看运行中资源指标的情况。
3.1.2.2 低利用率是否意味着没有饱和?
即使长时间平均利用率低,突发的高利用率也可能导致饱和性能问题。
3.1.2.3 使用 USE
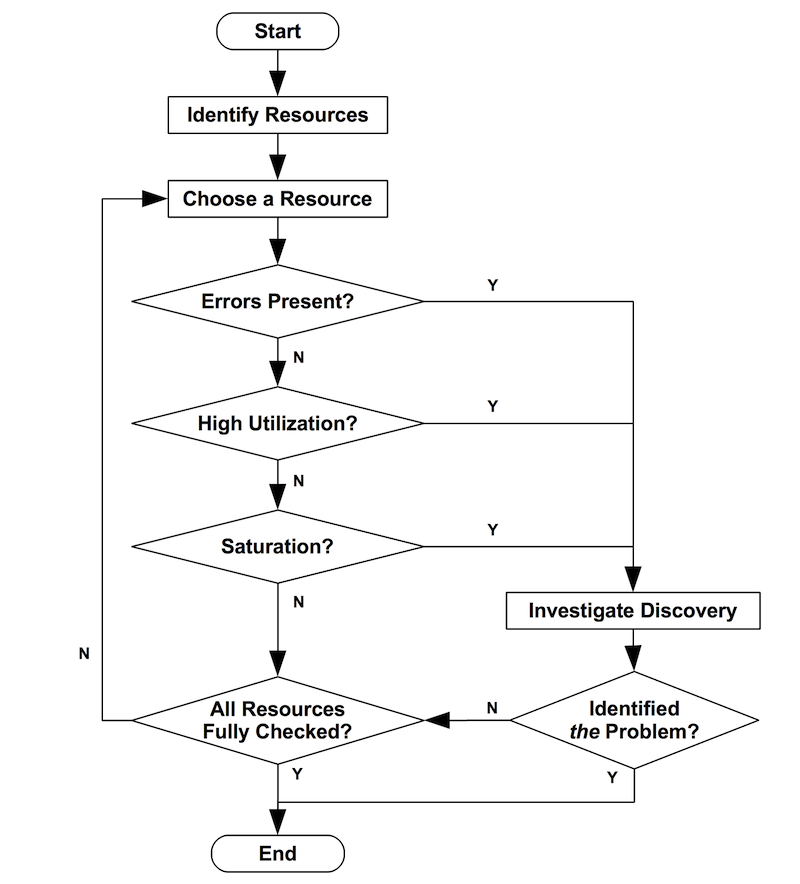
使用 USE 方法,第一步是列出系统中可能造成性能瓶颈的资源列表;接着测试单个资源的能够达到的上限性能;最后是顺着资源清单列表,以合适的工具来查看资源当前的指标:利用率、饱和度、错误状态。操作步骤,一如下面的流程图:
3.1.2.3 常见资源列表 和 它们的测量指标
资源包括 硬件资源 和 软件资源 两大类。
常见 硬件资源 列表 和 测量指标:
资源 | 测量指标
---------|----------------------------------
CPU | 利用率
| 饱和度:运行队列长度 或 调度延迟
---------|----------------------------------
内存 | 利用率:系统可用内存
| 饱和度:页面换出
| 错误:内存分配失败次数
---------|----------------------------------
存储设备 | 利用率:设备忙碌状态比例
| 饱和度:等待队列长度
| 错误状态:hard, soft, ...
---------|----------------------------------
......
可能的 软件资源 和 可能的 测量指标:
资源 | 测量指标
---------------------|--------------------------------
锁(mutex,...) | 利用率:锁持有的时长
| 饱和度:等待锁的队列长度
---------------------|--------------------------------
线程池 | 利用率:线程忙于处理工作的时间
| 饱和度:等待线程池处理的请求数
---------------------|--------------------------------
系统最大线程数 | ......
---------------------|--------------------------------
系统最大文件描述符数 | ......
---------------------|--------------------------------
......
这些没有一定的规范,可以按实际情况来定义。
3.1.2.4 USE 总结
USE 方法是一种简单的策略,可用于执行完整的系统运行状况检查,识别常见的瓶颈和错误。它可以在调查的早期部署,并快速识别问题区域,然后如果需要,可以更详细地研究其他方法。USE 的优势在于它的速度和可见性:通过考虑所有资源,你不太可能忽略任何问题。但是,它只会发现某些类型的问题 - 瓶颈和错误 - 并且应该被视为更大工具箱中的一员。
3.2 Intel TMA
Intel 在 CPU 微架构层面,提供对性能分析的支持。使用自顶向下的分析方法,具有固定的套路和模式。对这个不熟悉,提到 VTune 估计不少人就明了了。
更多细节可参考 vtune-profiler 。
3.3 其它
其它我所不知道的方法论,将在未来添加。
4. 参考资料
https://brendangregg.com/usemethod.html
https://brendangregg.com/tsamethod.html