提示学习中常见的Prompt方法
- 硬模板方法
- 1. PET(Pattern Exploiting Training)
- 2. LM-BFF
- 软模板方法
- 1. P-tuning
- 2. Prefix tuning
- 3. Soft Prompt Tuning
- 总结
- 参考资料
提示学习中常见的Prompt方法可以大概分为硬模板方法和软模板方法。
硬模板方法
主要介绍PET方法和LM-BFF方法。
1. PET(Pattern Exploiting Training)
硬模板-PET(Pattern Exploiting Training),它是一种较为经典的提示学习方法,即将问题建模成一个完形填空问题,然后优化最终的输出词。虽然 PET 也是在优化整个模型的参数,但是相比于传统的 Fine-tuning 方法,对数据量需求更少。建模方式如下(以往模型只要对
P
(
l
∣
x
)
P(l|x)
P(l∣x)建模就好了(
l
l
l是label),但现在加入了Prompt
P
P
P以及标签映射(称为verbalizer),所以这个问题就可以更新为):
s
p
(
l
∣
x
)
=
M
(
v
(
l
)
∣
P
(
x
)
)
s_p(l|x)=M(v(l)|P(x))
sp(l∣x)=M(v(l)∣P(x))其中
M
M
M表示模型,
s
s
s相当于某个prompt下生成对应word的
l
o
g
i
t
s
logits
logits。再通过softmax,就可以得到概率:
q
p
(
l
∣
x
)
=
e
s
p
(
l
∣
x
)
∑
l
′
∈
L
e
s
p
(
l
′
∣
x
)
q_p(l|x)=\frac{e^{s_p(l|x)}}{\sum_{l'\in L}e^{s_p(l'|x)}}
qp(l∣x)=∑l′∈Lesp(l′∣x)esp(l∣x)

通过提供具有自然语言“任务描述”的预训练语言模型,可以以完全无监督的方式解决一些NLP任务(例如,Radford等人,2019)。虽然这种方法的表现不如监督方法,但我们在这项工作中表明,这两种想法可以结合起来:我们引入了模式开发训练(PET),这是一种半监督训练程序,将输入示例重新表述为完形填空式短语,以帮助语言模型理解给定的任务。然后,这些短语被用来为一大组未标记的例子分配软标签。最后,对生成的训练集执行标准监督训练。对于几种任务和语言,PET在低资源环境中大大优于监督训练和强半监督方法。
论文地址:https://arxiv.org/abs/2001.07676v3
作者在训练时又加上了MLM loss,进行联合训练:
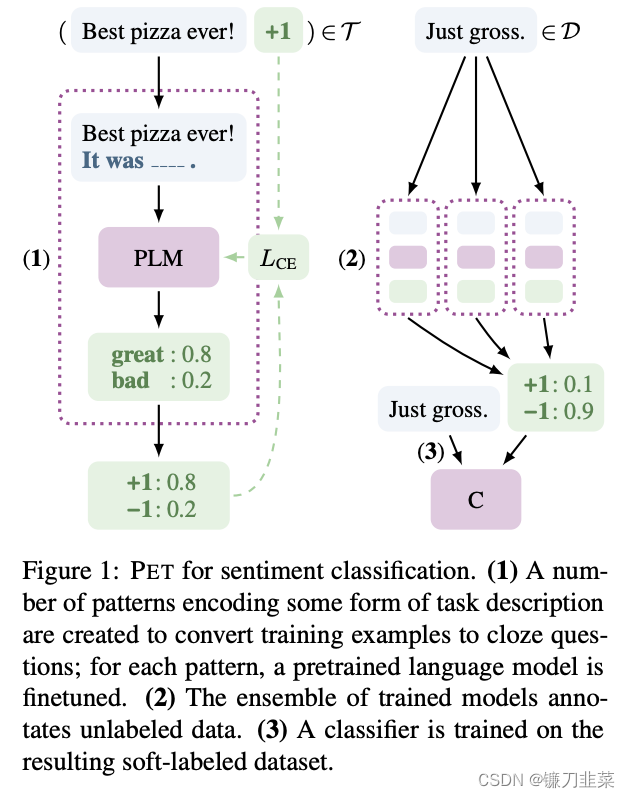
在用于情感分类的 PET 中,首先创建一些编码某种形式的任务描述的模式,以将训练示例转换为完型填空问题; 对于每个模式,预先训练的语言模型被微调。其次,训练后的模型集成对未标记数据进行注释。最后,对得到的软标记数据集进行分类器训练。
具体过程为:
- 在少量监督数据上,给每个Prompt训练一个模型;
- 对于无监督数据,将同一个样本的多个prompt预测结果进行集成,采用平均或加权(根据acc分配权重)的方式,再归一化得到概率分布,作为无监督数据的soft label;
- 在得到的soft label上 finetune 一个最终模型。
2. LM-BFF
基于规则的方法构建的模板虽然简单,但是这些模板都是“ 一个模子刻出来的 ”,在语义上其实挺难做到与句子贴合。因此一种策略就是 直接让模型来生成合适的模板 ,因为文本生成本质上就是去理解原始文本的语义,并获得在语义上较为相关的文本。这样不论给定什么句子,我们可以得到在语义层面上更加贴合的模板。

论文地址:https://aclanthology.org/2021.acl-long.295.pdf
LM-BFF是陈丹琦团队的工作,其出自于《Making Pre-trained Language Models Better Few-shot Learners》(ACL2021)。在Prompt Tuning基础上,提出了Prompt Tuning with demonstration & Auto Prompt Generation。
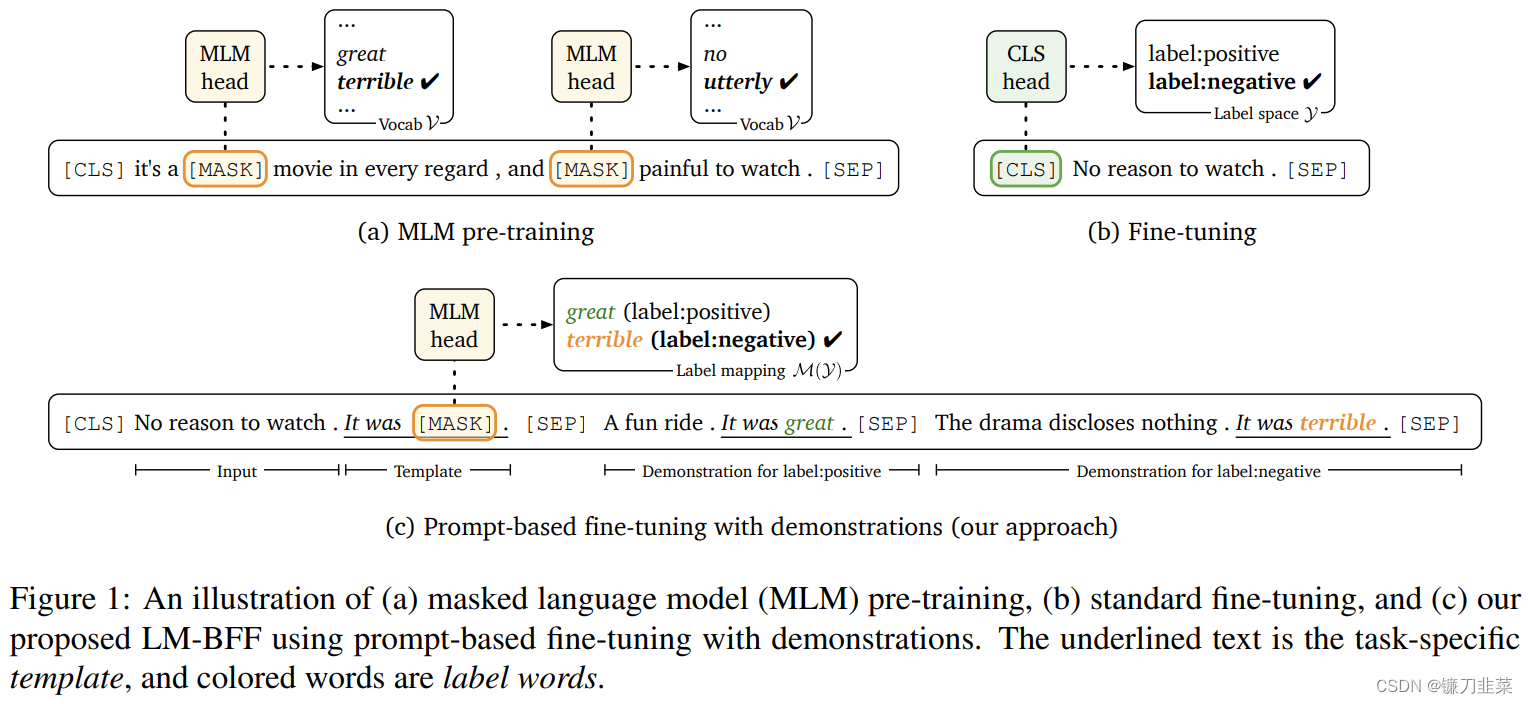
LM-BFF提出了基于生成的方法来构建Pattern,而给定相应的Pattern之后,再通过搜索的方法得到相应的Verbalizer。如下图所示:
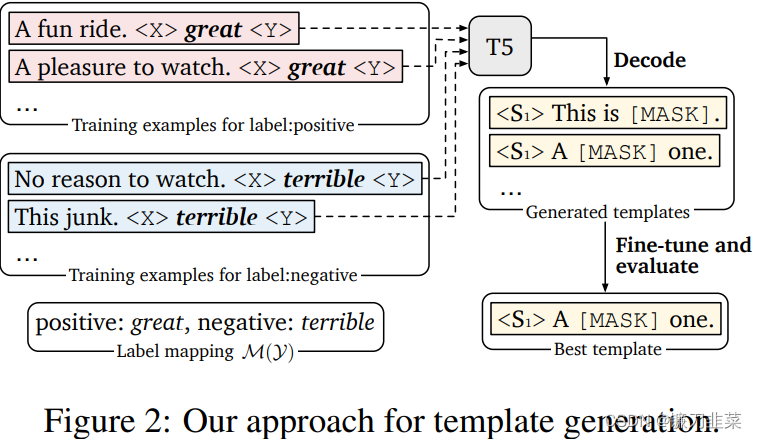
首先定义一个Template的母版(有点类似于PTR中的含有占位符的子模板),将这些母版与原始文本拼接后喂入T5模型(T5模型属于自回归式的生成模型)后在
<
X
>
<X>
<X>和
<
Y
>
<Y>
<Y>占位符部分生成相应的字符,最终形成对应的Template。然后再基于生成的Template和label word进行训练。
硬模板方法的缺陷:硬模板产生依赖两种方式:根据经验的人工设计 & 自动化搜索。但是,人工设计的不一定比自动搜索的好,自动搜索的可读性和可解释性也不强。
软模板方法
1. P-tuning
P-tuning不再设计/搜索硬模板,而是在输入端直接插入若干可被优化的Pseudo Prompt Tokens,自动化地寻找连续空间中的知识模板:

论文地址:https://arxiv.org/pdf/2103.10385.pdf
所谓PET,主要的思想是借助由自然语言构成的模版(英文常称Pattern或Prompt),将下游任务也转化为一个完形填空任务,这样就可以用BERT的MLM模型来进行预测了。
某种意义上来说,这些模版属于语言模型的“探针”,我们可以通过模版来抽取语言模型的特定知识,从而做到不错的零样本效果,而配合少量标注样本,可以进一步提升效果。
然而,前面已经说了,对于某些任务而言,人工构建模版并不是那么容易的事情,模型的优劣我们也不好把握,而不同模型之间的效果差别可能很大,在这种情况下,人工标注一些样本可能比构建模版还要轻松得多。所以,如何根据已有的标注样本来自动构建模版,便成了一个值得研究的问题了。
P-tuning重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效。
- 不依赖人工设计
- 要优化的参数极少,避免了过拟合(也可全量微调,退化成传统 finetuning)
- 传统离散prompt直接将模板T的每个token映射为对应的embedding,而 P-Tuning 将模板 T 中的Pi(Pseudo Prompt)映射为一个可训练的参数 hi 。
![An example of prompt search for “The capital of Britain is [MASK]”](https://img-blog.csdnimg.cn/ddc84149d7fe4f31babef6fda86769e0.png)
优化关键点在于,自然语言的hard prompt,替换为可训练的soft prompt;使用双向LSTM 对模板 T 中的 pseudo token 序列进行表征;引入少量自然语言提示的锚字符(Anchor)提升效率,如上图的“capital” ,可见 p-tuning是hard+soft的形式,并不是完全的soft形式。具体的做法:
- 初始化一个模板:The capital of [X] is [mask]
- 替换输入:[X] 处替换为输入 “Britian”,即预测 Britain 的首都
- 挑选模板中的一个或多个token作为soft prompt
- 将所有soft prompt送入LSTM,获得每个soft prompt的隐状态向量h。
- 将初始模板送入BERT的 Embedding Layer,所有soft prompt的token embedding用h代替,然后预测mask。
核心结论:基于全量数据,大模型:仅微调 prompt 相关的参数,媲美 fine-tuning 的表现。
2. Prefix tuning
P-tuning更新prompt token embedding的方法,能够优化的参数较少。Prefix tuning 希望能够优化更多的参数,提升效果,但是又不带来过大的负担。虽然prefix tuning是在生成任务上被提出来的,但是它对soft prompt后续发展有着启发性的影响。

微调是利用大型语言模型来执行下游任务的事实上的方法。但是,它修改了所有语言模型参数,因此需要为每个任务存储完整的副本。在本文中,我们提出了Prefix-Tuning,这是用于自然语言生成任务进行微调的轻量级替代品,它可以使语言模型参数冻结,但优化了一个小的连续特定任务特定的矢量(称为前缀)。前缀调整可以从prompt中汲取灵感,从而使后续token可以参加此前缀,就好像它是“虚拟令牌”。我们将前缀调整应用于gpt-2,以生成表 - 文本,并将其用于摘要。我们发现,通过仅学习0.1%的参数,前缀调整可以在完整的数据设置中获得可比的性能,在低数据设置中的表现优于微调,并且可以更好地推断出在训练过程中看不见的主题的示例。
论文地址:https://arxiv.org/abs/2101.00190
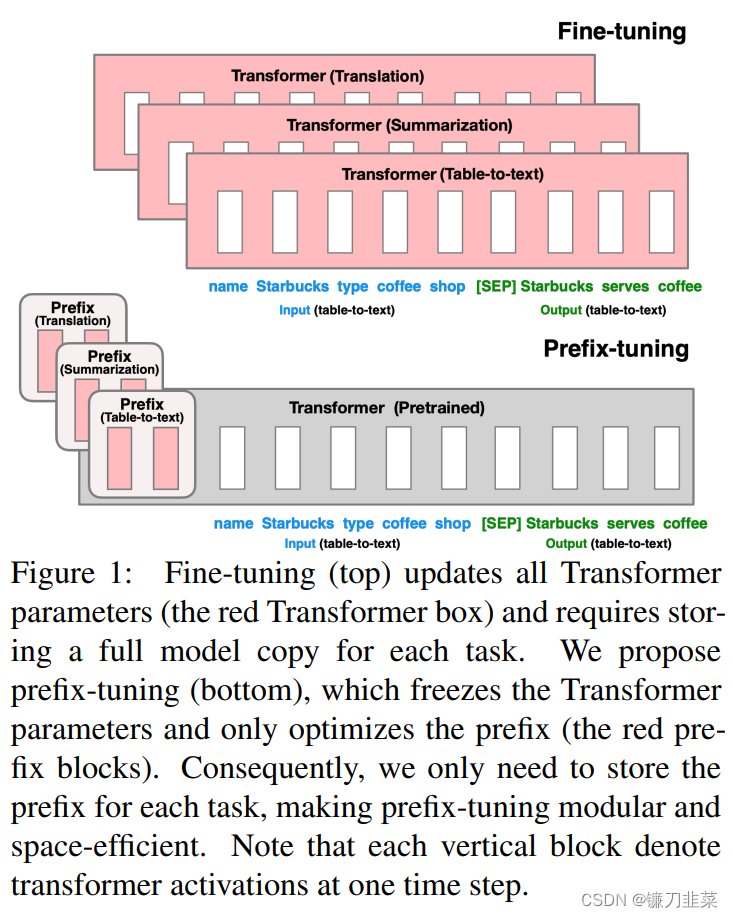
由上图可见,模型上在每层 transformer 之前加入 prefix。特点是 prefix 不是真实的 token,而是连续向量(soft prompt),Prefix-tuning 训练期间冻结 transformer 的参数,只更新 Prefix 的参数。只需要存储大型 transformer 的一个副本和学习到的特定于任务的前缀即可,为每个附加任务产生非常小的开销。
Prefix-tunning考虑两个生成任务:table-to-text 和摘要任务。
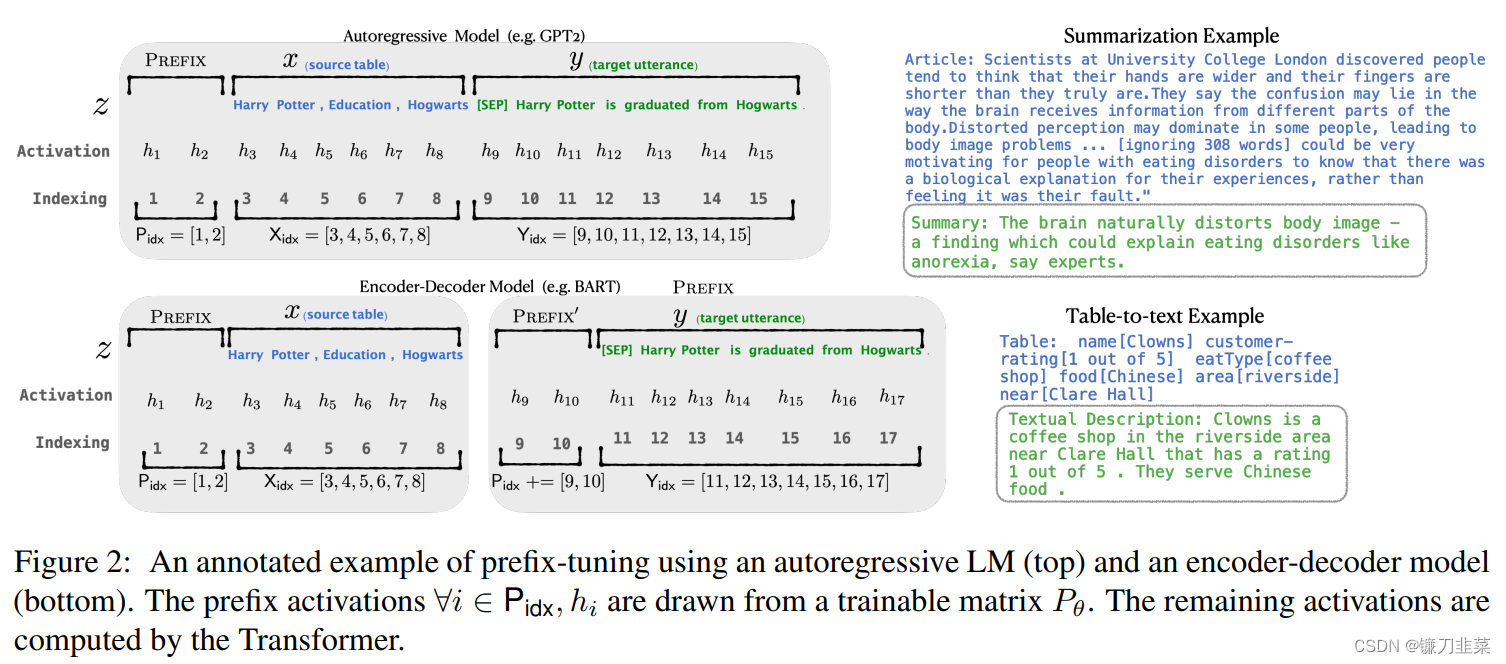
对于table-to-text任务,本文使用自回归语言模型GPT-2,输入为source(
x
x
x)和target(
y
y
y)的拼接,模型自回归地生成
y
~
\tilde{y}
y~ :
p
ϕ
(
z
i
+
1
∣
h
≤
i
)
=
s
o
f
t
m
a
x
(
W
ϕ
h
i
(
n
)
)
p_\phi(z_{i+1}|h_{\le i})=softmax (W_\phi h_i^{(n)})
pϕ(zi+1∣h≤i)=softmax(Wϕhi(n))
对于摘要任务,使用BART模型,编码器输入source文本 x x x,解码器输入target 黄金摘要( y y y),模型预测摘要文本 y ~ \tilde{y} y~。
在传统微调方法中,模型使用预训练参数进行初始化,然后用对数似然函数进行参数更新。
max
ϕ
log
p
ϕ
(
y
∣
x
)
=
∑
i
∈
Y
i
d
x
log
p
ϕ
(
z
i
∣
h
<
i
)
\max_{\phi} \log p_\phi (y|x)=\sum_{i\in Y_{idx}} \log p_\phi (z_i|h_{<i})
ϕmaxlogpϕ(y∣x)=i∈Yidx∑logpϕ(zi∣h<i)
本文将指令优化为连续的单词嵌入,而不是通过离散的token进行优化,其效果将向上传播到所有Transformer激活层,并向右传播到后续的token。严格来说,这比离散提示符更具表达性,后者需要匹配嵌入的真实单词。
上图2为回归模型为例的做法:
- 加入前缀后模型输入表示为 Z = [ P R E F I X ; x ; y ] Z = [ PREFIX ; x ; y ] Z=[PREFIX;x;y]
- Prefix-tuning 初始化一个训练的矩阵 P P P,用于存储prefix parameters
- 前缀部分 token,参数选择设计的训练矩阵,而其他部分的token,参数则固定 且为预训练语言模型的参数
结论:Prefix-tuning 在生成任务上,全量数据、大模型:仅微调 prompt 相关的参数,媲美 fine-tuning 的表现。
3. Soft Prompt Tuning
它验证了软模板方法的有效性,并提出:固定基础模型,有效利用任务特定的 Soft Prompt Token,可以大幅减少资源占用,达到大模型的通用性。

文章地址:https://ai.googleblog.com/2022/02/guiding-frozen-language-models-with.html
soft prompts相比于比离散的文本prompt,可以蕴含更质密的信息 (成千上万个examples)。对Prefix-tuning的简化,固定预训练模型,只对下游任务的输入添加额外的 k个可学习的 token。这种方式在大规模预训练模型的前提下,能够媲美传统的 fine-tuning 表现。
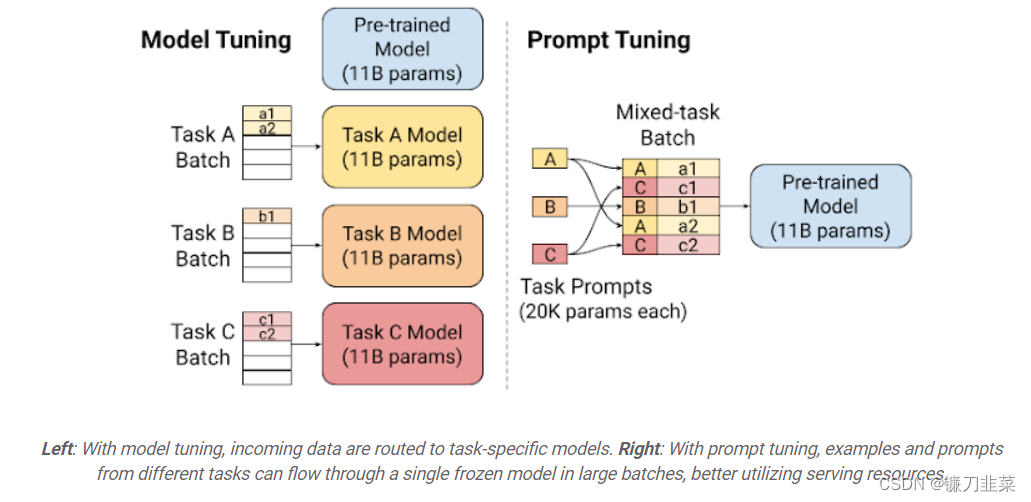
左图:通过模型调优,传入数据被路由到特定于任务的模型。右:通过即时调优,来自不同任务的示例和提示可以大批量地在单个冻结模型中流动,从而更好地利用服务资源。
总结
Prompt Learning的组成部分:
- 提示模板:根据使用预训练模型,构建 完形填空 or 基于前缀生成 两种类型的模板。
- 类别映射/Verbalizer:根据经验选择合适的类别映射词。
- 预训练语言模型。
典型的Prompt Learning方法总结:
- 硬模板方法:人工设计/自动构建基于离散 token 的模板,例如
PET、LM-BFF。 - 软模板方法:不再追求模板的直观可解释性,而是直接优化Prompt Token Embedding,是向量/可学习的参数,例如
P-tuning、Prefix Tuning、Soft Prompt Tuning。
参考资料
- 深入浅出提示学习思想要旨 及 常用Prompt方法
- Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
- P-tuning:自动构建模版,释放语言模型潜能
- 《Prefix-Tuning: Optimizing Continuous Prompts for Generation》阅读笔记
- 谷歌 Soft Prompt Learning