传统机器学习(五)决策树算法(一)
1.1 决策树算法手动实现
可以参考:机器学习实战(二)决策树-分类树(海洋生物数据集案例)
1.2 sklearn决策树参数详解
1.2.1 入参参数详解
class sklearn.tree.DecisionTreeClassifier(*,
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0
)
分类树参数如下

回归树DecisionTreeRegressor的入参与分类树基本相同,不同之处在于:
criterion可选值:mse:默认,均方差,mae:平均绝对差,friedman_mse
没有class_weight
1.2.2 属性和方法
-- 1、训练
clf.fit(X,y) :模型训练
-- 2、预测
clf.predict(X) :预测X的类别
clf.predict_proba(X) :预测X属于各类的概率
clf.predict_log_proba(X) :相当于 np.log(clf.predict_proba())
clf.apply(X) :返回样本预测节点的索引
clf.score(X,y) :返回准确率,即模型预测值与y不同的个数占比
支持样本权重:clf.score(X,y,sample_weight=sample_weight)
-- 3、剪枝
clf.cost_complexity_pruning_path(X, y) :返回 CCP(Cost Complexity Pruning代价复杂度剪枝)法的剪枝路径。
-- 4、树信息
clf.get_depth() :返回树的深度
clf.get_n_leaves() :叶子节点个数
clf.tree_.node_count :总节点个数
-- 4、树明细数据
左节点编号 : clf.tree_.children_left
右节点编号 : clf.tree_.children_right
分割的变量 : clf.tree_.feature
分割的阈值 : clf.tree_.threshold
不纯度(gini) : clf.tree_.impurity
样本个数 : clf.tree_.n_node_samples
样本分布 : clf.tree_.value
-- 5、其他
clf.feature_importances_ :各个特征的权重。
clf.get_params() :查看模型的入参设置
如果想获取节点上样本的数据,sklearn不直接提供,但可以借用 clf.apply(X) ,把原数据作为输入,间接获得。
1.2.3 提取决策树数据
用sklearn建好决策树后,可以打印出树的结构,还可以画图进行展示。但往往我们需要提取图中的数据(例如用于将决策树转化成规则代码),那图中的数据究竟在哪呢?
决策树模型信息分为树结构信息和节点信息,它们可以从模型对象clf中提取。
-- 树结构信息
左节点编号 : clf.tree_.children_left
右节点编号 : clf.tree_.children_right
-- 节点信息
分割的变量 : clf.tree_.feature
分割的阈值 : clf.tree_.threshold
不纯度(gini) : clf.tree_.impurity
样本个数 : clf.tree_.n_node_samples
样本分布 : clf.tree_.value
sklearn并没有直接存决策树的类别(概率)预测值,我们需要借助 样本分布 clf.tree_.value,
节点预测类别:样本最多的一类就是节点的预测类别
节点预测类别的概率:样本占比则是预测概率
from sklearn import tree
from sklearn.datasets import load_iris
import graphviz
#----------------数据准备----------------------------
iris = load_iris()
#---------------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(random_state=0,max_depth=3)
clf = clf.fit(iris.data,iris.target)
#---------------树结构可视化-----------------------------
dot_data = tree.export_graphviz(clf)
graph = graphviz.Source(dot_data)
graph

#---------------提取模型结构数据--------------------------
# 左节点编号
children_left = clf.tree_.children_left
# 右节点编号
children_right = clf.tree_.children_right
# 分割的特征
feature = clf.tree_.feature
# 分割的阈值
threshold= clf.tree_.threshold
# 不纯度
impurity = clf.tree_.impurity
# 样本个数
n_node_samples = clf.tree_.n_node_samples
# 样本的分布
value = clf.tree_.value
#-------------打印------------------------------
print("children_left:",children_left)
print("children_right:",children_right)
print("feature:",feature)
print("threshold:",threshold)
print("impurity:",impurity)
print("n_node_samples:",n_node_samples)
print("value:",value)
children_left : [ 1 -1 3 4 -1 -1 7 -1 -1]
children_right: [ 2 -1 6 5 -1 -1 8 -1 -1]
feature : [ 3 -2 3 2 -2 -2 2 -2 -2]
threshold : [ 0.80000001 -2. 1.75 4.95000005 -2. -2. 4.85000014 -2. -2.]
impurity : [ 0.66666667 0. 0.5 0.16803841 0.04079861 0.44444444 0.04253308 0.44444444 0. ]
n_node_samples: [150 50 100 54 48 6 46 3 43]
value : [[[50. 50. 50.]][[50. 0. 0.]] [[ 0. 50. 50.]] [[ 0. 49. 5.]] [[ 0. 47. 1.]] [[ 0. 2. 4.]]
[[ 0. 1. 45.]] [[ 0. 1. 2.]] [[ 0. 0. 43.]]]
-- 提取树结构信息
children_left : [ 1 -1 3 4 -1 -1 7 -1 -1]
children_right: [ 2 -1 6 5 -1 -1 8 -1 -1]
树结构信息存在children_left和children_right ,它们记录了左右节点编号
children_left[0] = 1 代表 第0(根节点)个节点左节点编号为1
children_right[0] = 2 代表 第0(根节点)个节点右节点编号为2
由上可知,根节点的左节点编号为1,右节点编号为2,左节点1和节点2的子节点,继续代入 children_left和 children_right即可。
-- 左节点1的子节点编号:
左子节点 children_left[1] = -1,
右子节点 children_right[1] =-1,
-1 代表没有子节点(即说明左节点1是叶子节点)。
-- 右节点2的子节点编号:
左子节点 children_left[2] = 3
右子节点 children_right[2] = 6
....
如此类推,即知树结构。
-- 提取节点信息
-- 第0个节点的信息:
分割特征 : feature[0] = 3
分割阈值 : threshold[0] = 0.8
不纯度(gini系数) : impurity[0] = 0.66666667
样本个数 : n_node_samples[0] = 150
样本分布 : value[0] = [50 50 50]
-- 第1个节点的信息:
分割变量 :feature[1] = -2 (-2代表是叶子节点,该值没意义)
分割阈值 :threshold[1] = -2 (-2代表是叶子节点,该值没意义)
不纯度(gini系数) :impurity[1]= 0
样本个数 :n_node_samples[1] = 50
样本分布 :value[1]= [50 0 0]
......
如此类推即可
1.2.4 决策树模型的布署样例
在sklearn中将决策树模型建好之后,要提取决策树规则布署到生产。一般是采用数据与代码分离的方案,只提取数据,在生产环境写出通用预测代码, 需要布署新的模型只需替换数据即可。
1.2.4.1 python测试代码
import numpy as np
"""
将sklearn训练好的决策树模型传入get_tree函数,get_tree函数将其中的决策树模型信息单独提取出来,返回字典对象。
根据生产上的使用语言需要,转成对应的数据文件,之后在生产上把数据文件加载成生产语言的数据对象。
"""
def get_tree(sk_tree):
#--------------拷贝sklearn树模型关键信息--------------------
children_left = sk_tree.tree_.children_left.copy() # 左节点编号
children_right = sk_tree.tree_.children_right.copy() # 右节点编号
feature = sk_tree.tree_.feature.copy() # 分割的变量
threshold = sk_tree.tree_.threshold.copy() # 分割阈值
impurity = sk_tree.tree_.impurity.copy() # 不纯度(gini)
n_node_samples = sk_tree.tree_.n_node_samples.copy() # 样本个数
value = sk_tree.tree_.value.copy() # 样本分布
n_sample = value[0].sum() # 总样本个数
node_num = len(children_left) # 节点个数
depth = sk_tree.get_depth()
# ------------补充节点父节点信息---------------------------
parent = np.zeros(node_num).astype(int)
parent[0] = -1
branch_idx = np.where(children_left != -1)[0]
for i in branch_idx:
parent[children_left[i]] = i
parent[children_right[i]]= i
#-------------存成字典-----------------------------------------
tree = {
'children_left':children_left
,'children_right':children_right
,'feature':feature
,'threshold':threshold
,'impurity':impurity
,'n_node_samples':n_node_samples
,'value':value
,'depth':depth
,'n_sample':n_sample
,'node_num':node_num
,'parent':parent
}
return tree
"""
在生产上编写一个tree_predict 函数,需要预测时就调用tree_predict进行预测
以下是python的样例
"""
def tree_predict(tree,x):
node_idx = 0
t = 0
while(t < tree['depth']):
# 在特征集合中找到比较的特征索引,与该特征的阈值进行比较,决定下一步分割到左子节点,还是右子节点
if(x[tree['feature'][node_idx]] <= tree['threshold'][node_idx]):
node_idx = tree['children_left'][node_idx]
else:
node_idx = tree['children_right'][node_idx]
# 如果该子节点没有左子节点,说明该子节点为叶子节点,用该子节点的样本分布预测其分类以及概率,并且退出循环
if( tree['children_left'][node_idx] == -1 ):
value = tree['value'][node_idx][0]
pred_class = np.argmax(value)
pred_prob = value / value.sum()
return pred_class,pred_prob
t = t + 1
from sklearn.datasets import load_iris
from sklearn import tree
if __name__ == '__main__':
# ----------------1、数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
# ---------------2、模型训练----------------------------------
clf = tree.DecisionTreeClassifier(random_state=41,max_depth=3) # sk-learn的决策树模型
clf = clf.fit(X, y) # 用数据训练树模型构建()
# --------------3、将树提取成简单的字典--------------------------------
tree = get_tree(clf)
# -------------------------
# 将tree持久化到服务器,服务器中用tree_predict进行预测即可
# -------------------------
# ------------4、测试函数的准确性-----------------------------
self_pred_y = np.zeros(len(y))
self_pred_prob = np.zeros((len(y), len(tree['value'][0][0])))
# 用函数进行预测,
# 节点预测类别:样本最多的一类就是节点的预测类别
# 节点预测类别的概率:样本占比则是预测概率`
for i in range(X.shape[0]):
pred_class, pred_prob = tree_predict(tree, X[i])
self_pred_y[i] = pred_class
self_pred_prob[i] = pred_prob
# 用sklearn进行预测
pred_y = clf.predict(X)
pred_prob = clf.predict_proba(X)
print("与sklearn预测结果差异个数(类别):", np.sum(pred_y != self_pred_y))
print("与sklearn预测结果差异个数(概率):", np.sum(pred_prob != self_pred_prob))
与sklearn预测结果差异个数(类别): 0
与sklearn预测结果差异个数(概率): 0
1.2.4.2 python和java测试代码
先用python语言把树模型准换为json输出
import numpy as np
"""
将sklearn训练好的决策树模型传入get_tree函数,get_tree函数将其中的决策树模型信息单独提取出来,返回字典对象。
根据生产上的使用语言需要,转成对应的数据文件,之后在生产上把数据文件加载成生产语言的数据对象。
"""
def get_tree(sk_tree):
#--------------拷贝sklearn树模型关键信息--------------------
children_left = sk_tree.tree_.children_left.copy() # 左节点编号
children_right = sk_tree.tree_.children_right.copy() # 右节点编号
feature = sk_tree.tree_.feature.copy() # 分割的变量
threshold = sk_tree.tree_.threshold.copy() # 分割阈值
impurity = sk_tree.tree_.impurity.copy() # 不纯度(gini)
n_node_samples = sk_tree.tree_.n_node_samples.copy() # 样本个数
value = sk_tree.tree_.value.copy() # 样本分布
n_sample = value[0].sum() # 总样本个数
node_num = len(children_left) # 节点个数
depth = sk_tree.get_depth()
# ------------补充节点父节点信息---------------------------
parent = np.zeros(node_num).astype(int)
parent[0] = -1
branch_idx = np.where(children_left != -1)[0]
for i in branch_idx:
parent[children_left[i]] = i
parent[children_right[i]]= i
#-------------存成字典-----------------------------------------
tree = {
'children_left':children_left.tolist()
,'children_right':children_right.tolist()
,'feature':feature.tolist()
,'threshold':threshold.tolist()
,'impurity':impurity.tolist()
,'n_node_samples':n_node_samples.tolist()
,'value':value.tolist()
,'depth':depth
,'n_sample':n_sample.tolist()
,'node_num':node_num
,'parent':parent.tolist()
}
return tree
from sklearn.datasets import load_iris
from sklearn import tree
import json
if __name__ == '__main__':
# ----------------1、数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
# ---------------2、模型训练----------------------------------
clf = tree.DecisionTreeClassifier(random_state=41,max_depth=3) # sk-learn的决策树模型
clf = clf.fit(X, y) # 用数据训练树模型构建()
# --------------3、将树提取成简单的字典--------------------------------
tree = get_tree(clf)
# -------------------------
# 将tree持久化到服务器,服务器中用tree_predict进行预测即可
# -------------------------
res_json = json.dumps(tree,ensure_ascii=False, indent=4)
print(res_json)
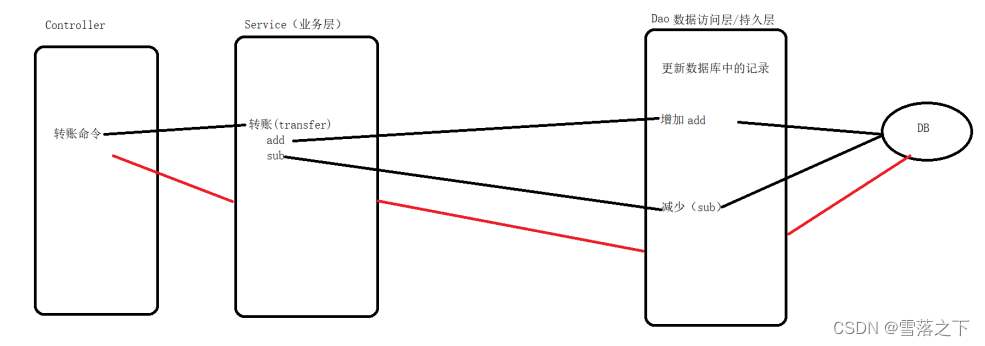
然后部署为接口
controller层
package com.yyds.controller;
import com.yyds.domain.Book;
import com.yyds.domain.IrisRequestBean;
import com.yyds.service.DecisionTreeService;
import io.swagger.annotations.Api;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@Slf4j
@RestController
@RequestMapping("/tree")
@Api(tags = "DecisionTreeController", description = "测试决策树的Rest API")
public class DecisionTreeController {
@Autowired
private DecisionTreeService decisionTreeService;
// 测试数据:5.10,3.50,1.40,0.20(鸢尾花数据集第1条数据,类别为山鸢尾)
@PostMapping("/predict")
public String getById(@RequestBody IrisRequestBean iris){
String predict = decisionTreeService.treePredict(iris);
return predict;
}
}
service层
package com.yyds.service.impl;
import com.alibaba.fastjson.JSON;
import com.yyds.domain.DBTreeBean;
import com.yyds.domain.IrisRequestBean;
import com.yyds.service.DecisionTreeService;
import io.swagger.models.auth.In;
import org.springframework.stereotype.Service;
import java.util.*;
@Service
public class DecisionTreeServiceImpl implements DecisionTreeService {
// 从决策树模型得到json字符串
String json = "......";
@Override
public String treePredict(IrisRequestBean iris) {
// 山鸢尾:0,杂色鸢尾:1,弗吉尼亚鸢尾:2
Map<Integer,String> resMap = new HashMap<>();
resMap.put(0,"山鸢尾");
resMap.put(1,"杂色鸢尾");
resMap.put(2,"弗吉尼亚鸢尾");
DBTreeBean treeBean = JSON.parseObject(json, DBTreeBean.class);
List<Integer> features = iris.getFeatures();
int node_idx = 0;
int t = 0;
while (t < treeBean.getDepth()){
int currentFeature = treeBean.getFeature().get(node_idx);
double currentThreshold = treeBean.getThreshold().get(node_idx);
if(features.get(currentFeature) <= currentThreshold){
node_idx = treeBean.getChildren_left().get(node_idx);
}else {
node_idx = treeBean.getChildren_right().get(node_idx);
}
if(treeBean.getChildren_left().get(node_idx) == -1){
// 类别
List<Integer> list = treeBean.getValue().get(node_idx).get(0);
// 找出预测类别最多的索引
int[] arr = list.stream().mapToInt(Integer::intValue).toArray();
int index = index(arr);
return resMap.get(index);
}
t += 1;
}
return null;
}
/**
* 找出一个整型数组中,出现次数最多的值
* @param arr
* @return
*/
public Integer index(int[] arr){
Map<Integer, Integer> map = new HashMap<Integer,Integer>();
for (int i = 0; i < arr.length; i++) {
if (map.containsKey(arr[i])) {
map.put(arr[i], map.get(arr[i]) + 1);
} else {
map.put(arr[i], 0);
}
}
int count = -1;
int max = Integer.MIN_VALUE;
Iterator<Map.Entry<Integer, Integer>> iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<Integer,Integer> entry = iter.next();
if (entry.getValue()>count||(entry.getValue()==count&&entry.getKey()>max)) {
max=entry.getKey();
count=entry.getValue();
}
}
return max;
}
}
beans
package com.yyds.domain;
import lombok.Data;
import java.util.List;
@Data
public class DBTreeBean {
private List<Integer> children_left;
private List<Integer> children_right;
private List<Integer> feature;
private List<Double> threshold;
private List<Double> impurity;
private List<Integer> n_node_samples;
private List<List<List<Integer>>> value;
private Integer depth;
private Integer n_sample;
private Integer node_num;
private List<Integer> parent;
}
package com.yyds.domain;
import lombok.Data;
import java.util.List;
@Data
public class IrisRequestBean {
private List<Integer> features;
}
swagger测试


1.2.5 决策树剪枝
剪枝是决策树预防模型过拟合的措施,剪枝分为预剪枝和后剪枝方法
1. 预剪枝:树构建过程,达到一定条件就停止生长
2. 后剪枝是等树完全构建后,再剪掉一些节点。
1.2.5.1 决策树预剪枝
预剪枝是树构建过程,达到一定条件就停止生长。在sklearn中,实际就是调参,通过设置树的生长参数,来达到预剪枝的效果。
-- 相关参数如下
min_samples_leaf :叶子节点最小样本数
min_samples_split :节点分枝最小样本个数
max_depth :树分枝的最大深度
min_weight_fraction_leaf :叶子节点最小权重和
min_impurity_decrease :节点分枝最小纯度增长量
max_leaf_nodes :最大叶子节点数
一般来说,只调这三个:max_depth,min_samples_leaf,min_samples_split
(1) 先用默认值预观察完整生长的树
'''
(1) 先用默认值预观察完整生长的树
'''
from sklearn.datasets import load_iris
from sklearn import tree
import numpy as np
import pandas as pd
#--------数据加载-----------------------------------
iris = load_iris() # 加载数据
X = iris.data
y = iris.target
#--------默认值训练模型-----------------------------------
clf = tree.DecisionTreeClassifier(random_state=0)
clf.fit(X,y)
depth = clf.get_depth()
leaf_node = clf.apply(X)

#-----观察各个叶子节点上的样本个数--------
df = pd.DataFrame(
{
"leaf_node":leaf_node,
"num":np.ones(len(leaf_node)).astype(int)
}
)
df = df.groupby(["leaf_node"]).sum().reset_index(drop=True)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
print(df)

(2) 通过参数限制节点过分生长
默认值得到的决策树,有很多叶子节点只有一两个样本,这样很容易过拟合,因此我们把min_samples_leaf 调为10。
'''
(2) 通过参数限制节点过分生长
'''
#--------调正参数进行模型-----------------------------------
clf = tree.DecisionTreeClassifier(random_state=0,max_depth=4,min_samples_leaf=10)
clf.fit(X,y)
depth = clf.get_depth()
leaf_node = clf.apply(X)
#-----观察各个叶子节点上的样本个数--------
df = pd.DataFrame(
{
"leaf_node":leaf_node,
"num":np.ones(len(leaf_node)).astype(int)
}
)
df = df.groupby(["leaf_node"]).sum().reset_index(drop=True)
df = df.sort_values(by='num').reset_index(drop=True)
print("\n==== 树深度:",depth," ============")
print("==各个叶子节点上的样本个数:==")
# 可以看到,最少的一个叶子,也有11个样本了,这样的决策树泛化能力更加好。
# 这只是预剪枝的基本操作,在实际中,需要更灵活的思路
print(df)

1.2.5.2 决策树后剪枝

在sklearn中,如果criterion设为GINI,Li 则是每个叶子节点的GINI系数,如果设为entropy,则是熵。
'''
计算CCP路径,查看alpha与树质量的关系:
构建好树后,我们可以通过clf.cost_complexity_pruning_path(X, y) 查看树的CCP路径
'''
#---------------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(min_samples_split=10,ccp_alpha=0)
clf = clf.fit(X, y)
#-------计算ccp路径-----------------------
pruning_path = clf.cost_complexity_pruning_path(X, y)
#-------打印结果---------------------------
print("\n====CCP路径=================")
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
====CCP路径=================
ccp_alphas: [0. 0.00415459 0.01305556 0.02966049 0.25979603 0.33333333]
impurities: [0.02666667 0.03082126 0.04387681 0.07353731 0.33333333 0.66666667]
# 意义如下
0<α<0.00415时,树的不纯度为 0.02666,
0.00415< α <0.013050时,树的不纯度为 0.03082,
0.01305< α <0.029660时,树的不纯度为 0.04387
......
其中,树的不纯度指的是损失函数的前部分,也即所有叶子的不纯度(gini或者熵)加权和.
'''
根据树的质量,选定alpha进行剪树我们选择一个可以接受的树不纯度,找到对应的alpha
例如,我们可接受的树不纯度为0.0735,则alpha可设为0.1(在0.02966与0.25979之间)
对模型重新以参数ccp_alpha=0.1进行训练,即可得到剪枝后的决策树。
'''
#------设置alpha对树后剪枝-----------------------
clf = tree.DecisionTreeClassifier(min_samples_split=10,random_state=0,ccp_alpha=0.1)
clf = clf.fit(X, y)
#------自行计算树纯度以验证-----------------------
is_leaf =clf.tree_.children_left ==-1 # 叶子节点
tree_impurities = (clf.tree_.impurity[is_leaf] * clf.tree_.n_node_samples[is_leaf]/len(y)).sum()
#-------打印结果---------------------------
print("\n==设置alpha=0.1剪枝后的树纯度:=========\n",tree_impurities)
==设置alpha=0.1剪枝后的树纯度:=========
0.0735373054213634
1.2.6 决策树的特征权重
clf.feature_importances是各个特征的重要性指标,即各个特征对模型的贡献性占比。
例如, feature_importances=[0 , 0, 0.05, 0.95],则代表第1、2个对象对模型的贡献为0,第3个特征贡献度为5% ,第4个特征贡献度为95%。
计算公式如下

1.3 鸢尾花决策树案例详解
在决策树的实际应用中,我们并不是简单地调用一下sklearn构建一棵决策树,是需要一套完整的建模流程,包括数据处理、参数调优、剪枝等操作。
1.3.1 数据预处理
-- 1.缺失值填充
决策树(CART)是不支持缺失值的,我们要把缺失数据按业务逻辑处理成非缺失值。
-- 2.枚举变量转成数值变量
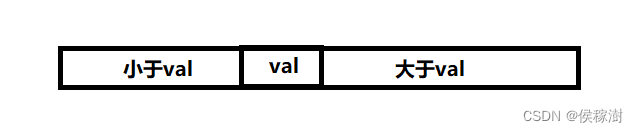
CART树的每个节点都是判断 变量在阈值的 左边还是右边,因此,它是不支持枚举变量的,需要处理成数值变量
-- 3.决策树是一个易于过拟合的模型,因此,需要数据分割为两份:训练数据集(80%)、测试数据集(20%)。
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import numpy as np
import pandas as pd
import graphviz
import datetime
'''
1、数据预处理
'''
#--------数据加载-----------------------------------
iris = load_iris() # 加载数据
all_X = iris.data
all_y = iris.target
#--------数据预处理-----------------------------------
train_X, test_X, train_y, test_y = train_test_split(all_X, all_y, test_size=0.2, random_state=0)
1.3.2 试探建模极限
我们建模结果并不总是一直顺利如意,模型的结果可能不理想,可能是数据问题,也可能是模型参数问题。
所以,我们要先试探一下用这批数据建模的极限在哪里。如果很差,那就没必要在模型参数上太纠结了,应往数据上找问题。
'''
2、模型极限试探
'''
clf = tree.DecisionTreeClassifier(max_depth=3,min_samples_leaf=8,random_state=20)
clf = clf.fit(all_X, all_y)
total_socre = clf.score(all_X,all_y)
clf = clf.fit(train_X, train_y)
train_socre = clf.score(train_X,train_y)
print("\n========模型试探============")
print("全量数据建模准确率:",total_socre)
print("训练数据建模准确率:",train_socre)
========模型试探============
全量数据建模准确率: 0.96
训练数据建模准确率: 0.9583333333333334
1.3.3 参数调优(预剪枝)
参数网格扫描
例如,我们要确定参数max_depth和min_samples_leaf,可预设max_depth的扫描值为 [3,5,7,9,11,13,15] 这7个值,min_samples_leaf 的扫描值为[1,3,5,7,9]这5个值。那它们的组合为5*7=35种,然后对每组参数进行评估,最后选出最优的参数组。
参数评估效果
评估方法采用:《K折交叉验证评估方法》。
-- K折交叉验证评估方法思想如下:
例如5折交叉验证,就是把数据分为5份,训练5轮,每轮训练用一份数据验证,其余4份训练。
这样最终每个样本都有预测值,最后把预测值的准确率(或其它指标)作为评估指标。
由于评估指标用的都是检验数据,所以评估的是泛化能力。通过网络扫描后,即可得到最优的参数组合。
-- 决策树调整主要参数
min_samples_leaf :叶子节点最小样本数。
max_depth :树分枝的最大深度
random_state :随机种子
'''
3、网格扫描最优训练参数
'''
clf = tree.DecisionTreeClassifier(random_state=0)
param_test = {
'max_depth':range(3,15,3) #最大深度
,'min_samples_leaf':range(5,20,3)
,'random_state':range(0,100,10)
# ,'min_samples_split':range(5,20,3)
# ,'splitter':('best','random') #
# ,'criterion':('gini','entropy') #基尼 信息熵
}
gsearch= GridSearchCV(estimator=clf, # 对应模型
param_grid=param_test, # 要找最优的参数
scoring=None, # 准确度评估标准
n_jobs=-1, # 并行数个数,-1:跟CPU核数一致
cv = 5, # 交叉验证 5折
verbose=0 # 输出训练过程
)
gsearch.fit(train_X,train_y)
print("\n========最优参数扫描结果============")
print("模型最佳评分:",gsearch.best_score_)
print("模型最佳参数:",gsearch.best_params_)
========最优参数扫描结果============
模型最佳评分: 0.95
模型最佳参数: {'max_depth': 3, 'min_samples_leaf': 8, 'random_state': 20}
1.3.4 最优参数进行训练
'''
4、用最优参数训练模型
'''
#-----------错误样本在叶子节点的分布-----------------
def cal_err_node(clf,X,y):
# 计算错误样本在叶子节点上的分布
leaf_node = clf.apply(X)
predict_y = clf.predict(X)
is_err = predict_y!=y
df = pd.DataFrame(
{
"leaf_node":leaf_node,
"num":np.ones(len(leaf_node)).astype(int),
"is_err":is_err
}
)
df = df.groupby(["leaf_node"]).sum().reset_index(drop=False)
df["err_rate"] = df["is_err"] / df["num"]
df = df[df['err_rate']>0].reset_index(drop=True)
df = df.sort_values(by='err_rate', ascending=False)
return df
clf = tree.DecisionTreeClassifier(**gsearch.best_params_)
clf = clf.fit(train_X, train_y)
pruning_path = clf.cost_complexity_pruning_path(train_X, train_y)
test_score = clf.score(test_X,test_y) # 统计得分(错误占比)
err_node_df = cal_err_node(clf, test_X, test_y)
print("\n========最优参数训练结果============")
print("\n---------决策树信息--------------")
print("叶子个数:",clf.get_n_leaves())
print("树的深度:",clf.get_depth())
print("特征权重:",clf.feature_importances_)
print("\n--------测试样本准确率:----------:\n",test_score)
print("\n----错误样本在叶子节点的分布--------:")
print(err_node_df)
print("\n------CCP路径---------------")
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
dot_data = tree.export_graphviz(
clf,
out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,
rounded=True,
special_characters=True
)
graph = graphviz.Source(dot_data)
graph
========最优参数训练结果============
---------决策树信息--------------
叶子个数: 5
树的深度: 3
特征权重: [0.00277564 0. 0.54604969 0.45117467]
--------测试样本准确率:----------:
0.9666666666666667
----错误样本在叶子节点的分布--------:
leaf_node num is_err err_rate
0 4 9 1 0.111111
------CCP路径---------------
ccp_alphas: [0. 0.00167683 0.01384615 0.25871926 0.32988169]
impurities: [0.06073718 0.06241401 0.07626016 0.33497942 0.66486111]

1.3.5 后剪枝
参考CCP路径,我们选择一个可以接受的树不纯度,找到对应的alpha,使用新的alpha重新训练模型,达到后剪枝效果。
'''
5、后剪枝
'''
clf = tree.DecisionTreeClassifier(max_depth=3,min_samples_leaf=8,random_state=20,ccp_alpha=0.1)
clf = clf.fit(train_X, train_y)
test_score = clf.score(test_X,test_y)
print("\n==============后剪枝=====================:\n")
print("测试样本准确率:",test_score)
print("叶子节点个数",clf.get_n_leaves())
==============后剪枝=====================:
测试样本准确率: 0.9666666666666667
叶子节点个数 3
1.3.6 模型提取与部署
模型建好后,需要布署到生产,生产环境可能是JAVA环境,PYTHON环境等,往往不能直接调用sklearn的模型对象。
需要我们把决策树模型规则纯粹的提取出来。提取决策树模型,只需要将描述模型的树结构、节点信息提取出来即可(即模型描述数据),具体提取方法可参考上面《决策树模型的布署样例》。
将模型描述数据发布到生产,在生产环境上,加载模型描述数据,再使用决策树的通用预测代码对新样本预测即可。