上次简单写了一篇对ChatGPT的一些看法,最近想深入研究一下。
极客时间上有个课程《AI大模型之美》,看了一下还可以。当做入门是不错的,但还是有很多细节可以打磨,不过毕竟是在风口上的课,也能接受。
本次演示如何调用OpenAPI的函数。
人工智能分类
要了解GPT,大体总得知道一下GPT在人工智能分类里属于哪部分吧!
GPT模型是一种基于深度学习的神经网络模型,是一种自然语言处理技术。GPT模型使用了一个称为“自回归语言模型”的方法来训练。在训练过程中,模型会接收到一个输入序列,并预测下一个单词或句子。这个预测过程会不断重复,直到生成完整的文本。在预测过程中,GPT模型会根据已经生成的文本和上下文信息来预测下一个单词或句子。这种无监督学习方法可以让模型从大量的文本数据中学习语言的模式和规律,从而生成高质量的自然语言文本。
GPT4回答的分类:
机器学习
│
├── 监督学习
│ ├── 线性回归
│ ├── 逻辑回归
│ ├── 支持向量机 (SVM)
│ ├── 决策树
│ │ └── 随机森林
│ ├── K-近邻
│ └── 神经网络
│ ├── 深度学习
│ │ ├── 卷积神经网络 (CNN)
│ │ ├── 循环神经网络 (RNN)
│ │ │ └── 长短时记忆网络 (LSTM)
│ │ └── 生成对抗网络 (GAN)
│ ├── TensorFlow
│ │ └── Keras
│ ├── PyTorch
│ └── MXNet
│
├── 无监督学习
│ ├── 聚类
│ │ ├── K-均值
│ │ ├── 层次聚类
│ │ └── DBSCAN
│ ├── 降维
│ │ ├── 主成分分析 (PCA)
│ │ ├── t-分布邻域嵌入算法 (t-SNE)
│ │ └── 自编码器
│ └── 关联规则学习
│ └── Apriori算法
│
├── 半监督学习
│ └── 标签传播算法
│
└── 强化学习
├── Q-learning
├── SARSA
├── 深度Q网络 (DQN)
├── 策略梯度 (PG)
├── 代理者演员-评论家 (DDPG)
└── 深度确定性策略梯度 (PPO)
Sage回答的分类:
机器学习
├── 监督学习
│ ├── 线性回归(Linear Regression)
│ ├── 逻辑回归(Logistic Regression)
│ ├── 决策树(Decision Tree)
│ ├── 随机森林(Random Forest)
│ ├── 支持向量机(Support Vector Machines)
│ ├── 朴素贝叶斯(Naive Bayes)
│ ├── K最近邻(K-Nearest Neighbors)
│ └── 神经网络(Neural Networks)
│ ├── 前馈神经网络(Feedforward Neural Networks)
│ ├── 卷积神经网络(Convolutional Neural Networks)
│ ├── 循环神经网络(Recurrent Neural Networks)
│ ├── 长短时记忆网络(Long Short-Term Memory Networks)
│ ├── 生成对抗网络(Generative Adversarial Networks)
│ └── 转移学习(Transfer Learning)
├── 无监督学习
│ ├── 聚类(Clustering)
│ │ ├── K均值聚类(K-Means Clustering)
│ │ ├── 层次聚类(Hierarchical Clustering)
│ │ ├── 密度聚类(Density-Based Clustering)
│ │ └── 高斯混合模型(Gaussian Mixture Model)
│ ├── 关联规则学习(Association Rule Learning)
│ │ ├── Apriori算法
│ │ └── FP-growth算法
│ ├── 异常检测(Anomaly Detection)
│ ├── 主成分分析(Principal Component Analysis)
│ ├── 特征选择(Feature Selection)
│ └── 降维(Dimensionality Reduction)
│ ├── 主成分分析(Principal Component Analysis)
│ ├── 独立成分分析(Independent Component Analysis)
│ ├── t-SNE
│ └── UMAP
├── 强化学习
│ ├── Q-learning
│ ├── Sarsa
│ ├── 深度Q网络(Deep Q-Network)
│ ├── 策略梯度(Policy Gradient)
│ ├── Actor-Critic
│ └── 强化学习应用
├── 半监督学习(Semi-Supervised Learning)
├── 迁移学习(Transfer Learning)
├── 元学习(Meta Learning)
├── 神经架构搜索(Neural Architecture Search)
├── 自然语言处理(Natural Language Processing)
│ ├── 词袋模型(Bag of Words)
│ ├── 词嵌入(Word Embedding)
│ ├── 递归神经网络(Recursive Neural Networks)
│ ├── 长短时记忆网络(Long Short-Term Memory Networks)
│ ├── 注意力机制(Attention Mechanism)
│ ├── 预训练模型(Pretrained Models)
│ │ ├── BERT
│ │ ├── GPT
│ │ ├── GPT-2
│ │ ├── GPT-3
│ │ ├── RoBERTa
│ │ ├── T5
│ │ └── XLNet
│ └── 序列到序列模型(Sequence-to-Sequence Models)
│ ├── 编码器-解码器(Encoder-Decoder)模型
│ ├── 注意力机制(Attention Mechanism)模型
│ ├── 递归神经网络(Recursive Neural Networks)模型
│ ├── 门控循环单元(Gated Recurrent Unit)模型
│ ├── 长短时记忆网络(Long Short-Term Memory Networks)模型
│ └── 转移学习(Transfer Learning)模型
├── 计算机视觉(Computer Vision)
│ ├── 卷积神经网络(Convolutional Neural Networks)
│ ├── 残差网络(Residual Networks)
│ ├──目标检测(Object Detection)
│ │ ├── R-CNN
│ │ ├── Fast R-CNN
│ │ ├── Faster R-CNN
│ │ ├── YOLO
│ │ ├── SSD
│ │ └── RetinaNet
│ ├── 语义分割(Semantic Segmentation)
│ ├── 实例分割(Instance Segmentation)
│ ├── 图像分类(Image Classification)
│ ├── 图像生成(Image Generation)
│ │ ├── 生成对抗网络(Generative Adversarial Networks)
│ │ ├── 变分自编码器(Variational Autoencoders)
│ │ └── 流模型(Flow Models)
│ ├── 姿态估计(Pose Estimation)
│ ├── 光流估计(Optical Flow Estimation)
│ ├── 图像超分辨(Image Super-Resolution)
│ └── 图像风格转换(Image Style Transfer)
├── 常用框架和产品
│ ├── TensorFlow
│ ├── PyTorch
│ ├── Keras
│ ├── Scikit-Learn
│ ├── XGBoost
│ ├── LightGBM
│ ├── CatBoost
│ ├── Caffe
│ ├── MXNet
│ ├── Theano
│ ├── Microsoft Cognitive Toolkit
│ ├── Amazon SageMaker
│ ├── Google Cloud AI Platform
│ ├── IBM Watson Studio
│ ├── Hugging Face Transformers
│ └── OpenAI GPT
└── 其他应用领域
├── 推荐系统(Recommendation Systems)
├── 时间序列分析(Time Series Analysis)
├── 异常检测(Anomaly Detection)
├── 信用风险评估(Credit Risk Assessment)
├── 医学诊断(Medical Diagnosis)
├── 股票市场预测(Stock Market Prediction)
├── 自动驾驶(Autonomous Driving)
├── 语音识别(Speech Recognition)
├── 人脸识别(Face Recognition)
├── 自然语言生成(Natural Language Generation)
├── 机器翻译(Machine Translation)
├── 游戏AI(Game AI)
└── 机器人控制(Robot Control)
名词解释
这里列出一些常用的名次,方便大家理解
| 名词 | 全称 | 解释 |
|---|---|---|
| GPT | 生成式预训练 Transformer(Generative Pre-trained Transformer) | GPT模型的训练是一种无监督学习方法,它不需要人工标注的标签或答案来指导模型的学习。相反,它使用大量的文本数据来预测下一个单词或句子,从而让模型学习语言的模式和规律。GPT模型不属于聚类或者降维等传统机器学习算法,它是一种基于深度学习的神经网络模型。具体来说,GPT模型是基于Transformer架构的神经网络模型,它使用了多层的自注意力机制来对输入序列进行编码,并通过解码器生成新的自然语言文本。 |
| NLP | Natural Language Processing | NLP代表自然语言处理(Natural Language Processing),是一种计算机科学和人工智能领域的交叉学科,旨在使计算机能够理解、解释和操作人类语言。自然语言处理涉及使用计算机算法和统计模型来分析、处理、理解和生成人类语言,包括文本和语音。自然语言处理技术已经广泛应用于许多领域,例如语音识别、机器翻译、情感分析、文本分类、信息检索、自然语言生成、问答系统等等。这些应用领域涵盖了许多实际场景,例如智能客服、语音助手、社交媒体分析、金融分析、医疗诊断等等。 |
| LLM | large language model | 大语言模型 |
| 召回率(Recall) | 在人工智能领域中,召回率(Recall)是指模型正确识别出的正样本数占总正样本数的比例,通常用以下公式表示:Recall = TP / (TP + FN) 其中,TP表示真正例(True Positive),即模型正确识别出的正样本数;FN表示假反例(False Negative),即模型未能识别出的正样本数。召回率衡量了模型识别正样本的能力,即模型能够正确地找到多少个正样本。召回率越高,表示模型能够正确地识别出更多的正样本,但同时可能会导致误识别负样本的数量增加。召回率,代表模型判定属于这个分类的标题占实际这个分类下所有标题的比例,也就是没有漏掉的比例。比如,模型判断 100 个都是农业新闻,这 100 个的确都是农业新闻。准确率已经 100% 了。但是,实际我们一共有 200 条农业新闻。那么有 100 条其实被放到别的类目里面去了。那么在农业新闻这个类目,我们的召回率,就只有 100/200 = 50%。所以模型效果的好坏,既要考虑准确率,又要考虑召回率,综合考虑这两项得出的结果,就是 F1 分数(F1 Score)。 | |
| 准确率(Precision) | 准确率是指模型正确识别出的正样本数占总样本数的比例,通常用以下公式表示:Precision = TP / (TP + FP) 其中,FP表示假正例(False Positive),即模型错误地识别出的正样本数。准确率衡量的是模型识别出的正样本占总样本数的比例,即模型能够正确地找到多少个被识别为正样本的样本。准确率越高,表示模型能够更准确地识别正样本,但同时可能会导致未能识别出的正样本数量增加。准确率,代表模型判定属于这个分类的标题里面判断正确的有多少,有多少真的是属于这个分类的。比如,模型判断里面有 100 个都是农业新闻,但是这 100 个里面其实只有 83 个是农业新闻,那么准确率就是 0.83。准确率自然是越高越好,但是并不是准确率达到 100% 就代表模型全对了。因为模型可能会漏,所以我们还要考虑召回率。 | |
| F1 分数 | F1 分数,是准确率和召回率的调和平均数,也就是 F1 Score = 2/ (1/Precision + 1/Recall)。当准确率和召回率都是 100% 的时候,F1 分数也是 1。如果准确率是 100%,召回率是 80%,那么算下来 F1 分数就是 0.88。F1 分数也是越高越好。 | |
| 支持的样本量 | 是指数据里面,实际是这个分类的数据条数有多少。一般来说,数据条数越多,这个分类的训练就会越准确。 | |
| 预训练模型(Pre-trained Model) |
创建API Key
OpenAI 还没有向中国大陆和香港地区开放,所以要注册的话,至少需要VPN和短信接收平台。这里默认大家已经有办法注册账号了。
我们首先需要获取API Key,需要用这个值作为请求API的token。这个Key一定要自己记录下来,否则再也查不到了。另外千万不要泄露出去。
地址:https://platform.openai.com/overview

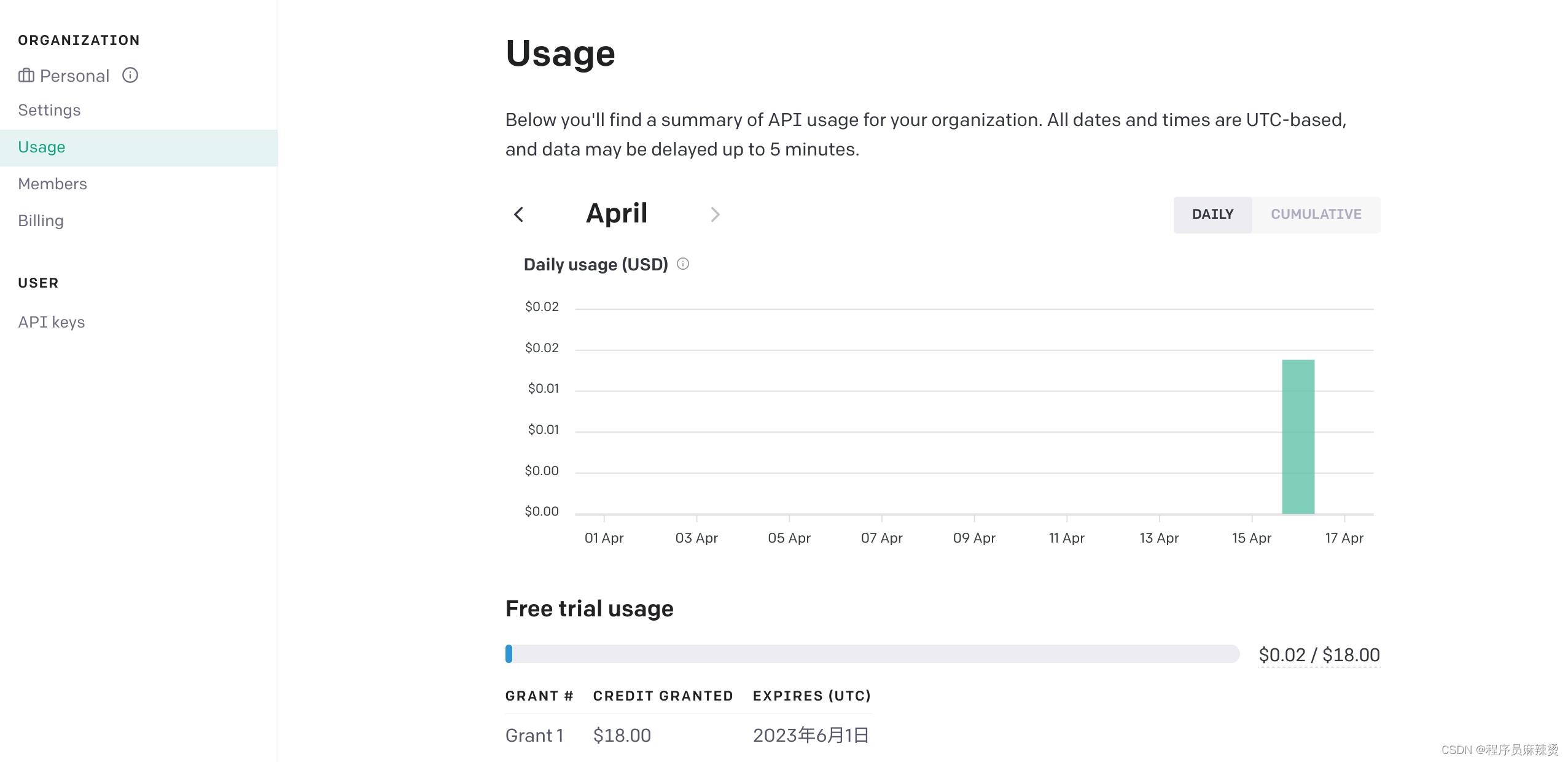
我的账号注册的比较早,所以有18美元的试用额度
搭建Jupyter Labs开发环境
大家可以参考我的Jupyterhub安装教程,我是用npm方式安装
mkdir jupyter
cd jupyter
sudo npm install -g configurable-http-proxy
sudo apt install python3-pip
sudo pip3 install jupyterhub
sudo pip3 install notebook
sudo pip3 install jupyterlab
# 生成配置文件
jupyterhub --generate-config
# 启动
nohup jupyterhub -f jupyterhub_config.py &
# 默认8000端口,访问链接,查看安装情况
#http://127.0.0.1:8000/hub/login?next=%2Fhub%2F
测试
操作
简单找个例子测试一下
代码
import openai
import os
openai.api_key = os.environ.get("OPENAI_API_KEY")
COMPLETION_MODEL = "text-davinci-003"
prompt = """
Consideration product : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具
1. Compose human readable product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
def get_response(prompt):
completions = openai.Completion.create (
engine=COMPLETION_MODEL,
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.0,
)
message = completions.choices[0].text
return message
print(get_response(prompt))
返回
{
"title": "PVC Inflatable Glow-in-the-Dark Frog Water Toy for Kids Night Market Stall",
"selling_points": [
"Made of durable PVC material",
"Inflatable design for easy storage and transport",
"Glow-in-the-dark feature for night time fun",
"Perfect for water play and pool parties",
"Great for kids of all ages"
],
"price_range": "$10 - $20"
}
参数
第一个参数是 engine,也就是我们使用的是 Open AI 的哪一个引擎,这里我们使用的是 text-davinci-003,也就是现在可以使用到的最擅长根据你的指令输出内容的模型。当然,也是调用成本最高的模型。
第二个参数是 prompt,自然就是我们输入的提示语。
第三个参数是 max_tokens,也就是调用生成的内容允许的最大 token 数量。你可以简单地把 token 理解成一个单词。实际上,token 是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个 token。比如,icecream 是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个 token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。一般来说,750 个英语单词就需要 1000 个 token。我们这里用的 text-davinci-003 模型,允许最多有 4096 个 token。需要注意,这个数量既包括你输入的提示语,也包括 AI 产出的回答,两个加起来不能超过 4096 个 token。比如,你的输入有 1000 个 token,那么你这里设置的 max_tokens 就不能超过 3096。不然调用就会报错。
第四个参数 n,代表你希望 AI 给你生成几条内容供你选择。在这样自动生成客服内容的场景里,我们当然设置成 1。但是如果在一些辅助写作的场景里,你可以设置成 3 或者更多,供用户在多个结果里面自己选择自己想要的。
第五个参数 stop,代表你希望模型输出的内容在遇到什么内容的时候就停下来。这个参数我们常常会选用 "\n\n"这样的连续换行,因为这通常意味着文章已经要另起一个新的段落了,既会消耗大量的 token 数量,又可能没有必要。
第六个参数temperature,参数的输入范围是 0-2 之间的浮点数,代表输出结果的随机性或者说多样性。可以把这个参数设置为 0,这样,每次输出的结果的随机性就会比较小。
总结
https://platform.openai.com/docs/api-reference/introduction
函数不是很多,大家有兴趣可以自己看一下,使用起来也是很方便的。
链接:http://gk.link/a/121Tn
资料
- 官方文档
- monica