1.group by的作用
根据一定的规则将一个数据集划分成若干个小区域,然后针对每个区域进行数据处理。即分组查询,一般是和聚合函数配合使用。
重点说明(重要):
如果用Select选择某个字段,那么这个字段要么在Group By子句中,作为分组的依据;要么就要在聚合函数中。
正确例子:
//正确例子
//这个例子是允许的,不会报错
//按部门分类,查找每个部门的编号、人数和最高的工资数
select d.dept_no, count(*) as emp_no, max(s.salary)
from dept_emp as d join salaries as s
on d.emp_no = s.emp_no
group by d.dept_no;
错误例子:
//错误例子
//按部门分类,查找每个部门的编号、最高工资的员工编号和最高的工资数
select d.dept_no, d.emp_no, max(s.salary) //d.emp_no既不是分组条件也不是聚合结果
from dept_emp as d join salaries as s
on d.emp_no = s.emp_no
group by d.dept_no;
group by的错误用法,上面代码报错的
原因是:d.emp_no既不是分组条件也不是聚合结果。
2.group by 与 over(partition by)的区别
以例子说明:
计算每个部门的总薪水
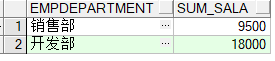
2.1group by
SELECT EmpDepartment,SUM(EmpSalary) sum_sala FROM Employee GROUP BY EmpDepartment
2.2over(partition by)
SELECT EmpSalary,EmpDepartment,SUM(EmpSalary) OVER(PARTITION BY EmpDepartment) sum_sala FROM Employee
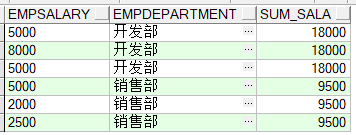
小结:group by 和 partition by 都有分组统计的功能,但是partition by并不具有group by的汇总功能。partition by统计的每一条记录都存在,而group by将所有的记录汇总成一条记录(类似于distinct EmpDepartment 去重)。partition by可以和聚合函数结合使用,同时具有其他高级功能。
2.3补充:在partition by 后在加上order by
SELECT EmpSalary,EmpDepartment,SUM(EmpSalary) OVER(PARTITION BY EmpDepartment ORDER BY EmpSalary) sum_sala FROM Employee
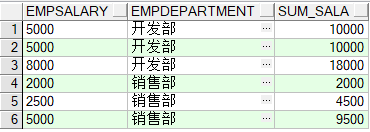
小结:加上order by 后,类似于累加功能(sum_sala += EmpSalary),先观察销售部的结果,从第4条记录开始,其sum(EmpSalary)即sum_sala=2000,第5条记录,sum(EmpSalary)=sum_sala+2500=4500,即第4条sum_sala与第5条EmpSalary的和,依次类推;开发部,由于2个5000是并列的,所以计算的时候是几个并列数据之和即5000+5000=10000。
参考文章:
1.https://www.jianshu.com/p/82f2c3e1c3f8
2.https://blog.csdn.net/WuLex/article/details/115037696