文章目录
- 1、kafka是什么
- 2、docker上部署kafka
- 3、在kafka容器内部署python,并跑通生产者-消费者简单代码
- 4、最新接口
- 4.1、kafka_config.py
- 4.2、kafka_interface.py
- 4.3、run.py
- 4、测试
1、kafka是什么

- Producer:即生产者,消息的产生者,是消息的入口;
- Consumer:消费者,即消息的消费方,是消息的出口;
- Broker:中间代理,即一个broker就是一个server。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
- Topic(主题):可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic,也可以类比为电脑的文件夹;
- Event(事件):也称为记录、消息(Message),可以类比为文件。示例事件包括支付交易、来自手机的地理位置更新、运输订单、来自物联网设备或医疗设备的传感器测量等等。这些事件被组织并存储在 Topic 中;
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器) 上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给 consumer ,不保证一个 topic 的整体(多个 partition 间)的顺序;
- Consumer Group(CG):尚硅谷讲的,因为Topic被分为了Partition,同样Consumer一样可以分组。各个consumer可以组成一个组,同一个消费者组的消费者可以消费同一个topic的不同分区(partition)的数据,这也是为了提高kafka的吞吐量!
- Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
参考连接《kafka基本原理详解》,里面有具体的流程。
下面是我自己看了很多资料理解的:
kafka 有很多 broker (因为一个 boker 相当于一个云服务器,即一台大型电脑),每个 broker 里有很多topic(相当于一个电脑有很多文件夹),而有时可能一个 topic 太大,一个 broker 无法存下一个 topic ,因此分为topicA-partition0 、 topicA-partition1 存在 broker1 、 broker2上(相当于分布式存储了,将一个大文件夹拆成很多小文件夹,当然为了防范风险,还有存其很多副本),而每一个 partition 下存的是event(相当于文件夹存的文档)。
2、docker上部署kafka
-
拉取zookeeper和kafka的镜像
docker pull wurstmeister/zookeeper docker pull wurstmeister/kafka -
创建并运行容器。
注意创建运行顺序,一定要先zookeeper,再kafka,否则报错!
2.1 创建并运行zookeeper
docker run --name zookeeper \ -d -t wurstmeister/zookeeper \ -p 2181:2181参数说明(具体可查看《docker示例,菜鸟教程》):
- –name zookeeper:此容器别名叫zookeeper
- -d:后台运行
- -t: 在新容器内指定一个伪终端或终端
- wurstmeister/zookeeper:指定要运行的镜像,Docker 首先从本地主机上查找镜像是否存在,如果不存在,Docker 就会从镜像仓库 Docker Hub 下载公共镜像。
- -p :端口号(映射到宿主机的端口:zookeeper端口号)。容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P 或 -p 参数来指定端口映射(具体查看《docker容器互联之端口互联,菜鸟教程》)。例如这里我在ubuntu虚拟机上部署的docker,那么在unbuntu虚拟机上访问 localhost:2181 就能访问docker中的zookeeper。
执行完毕后,会返回一个容器ID。
2.2 创建并运行kafka
docker run --name kafka \ -t wurstmeister/kafka\ -p 9092:9092 \ --link zookeeper:zk\ -e HOST_IP=localhost \ -e KAFKA_BROKER_ID=1 \ -e KAFKA_ZOOKEEPER_CONNECT=zk:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \ -e KAFKA_LISTENERS=PLAINTEXT://localhost:9092参数说明:
- –name kafka:此容器别名叫kafka。
- -d:后台运行。
- -t: 在新容器内指定一个伪终端或终端。
- wurstmeister/kafka:指定要运行的镜像,Docker 首先从本地主机上查找镜像是否存在,如果不存在,Docker 就会从镜像仓库 Docker Hub 下载公共镜像。
- -p 端口号(映射到宿主机的端口:kafka端口号)。容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P 或 -p 参数来指定端口映射(具体查看《docker容器互联之端口映射,菜鸟教程》)。例如这里我在ubuntu虚拟机上部署的docker,那么在unbuntu虚拟机上访问 localhost:9092 就能访问docker中的kafka。
–link=[]: 添加链接到另一个容器。这里代表链接到zookeeper这个容器,同时取别名为zk - -e : 设置环境变量:
HOST_IP: 宿主主机的IP;
KAFKA_BROKER_ID: 该ID是集群的唯一标识,因为在kafka集群中,每个kafka都有一个BROKER_ID来区分自己;
KAFKA_ZOOKEEPER_CONNECT==<这里换成你的zookeeper地址和端口>: 配置zookeeper管理kafka的路径;
KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<这里换成你的kafka地址和端口>: kafka发布到zookeeper供客户端使用的服务地址;
KAFKA_LISTENERS: 配置kafka的监听端口,代表允许使用PLAINTEXT侦听器。网上有的教程将-e KAFKA_LISTENERS=PLAINTEXT://localhost:9092换成了-e ALLOW_PLAINTEXT_LISTENER=yes是一个意思。
2.3 使用如下命令,可查看容器是否创建成功:
docker ps -a下图可以看到均处于up状态,代表创建运行成功。

-
测试发送消息
3.1 进入容器内部
docker exec -it kafka /bin/bash # 注意,这里kafka是之前创建的容器名。参数说明:
- -i:允许你对容器内的标准输入 (STDIN) 进行交互。
- -t:在新容器内指定一个伪终端或终端。
- kafka:这里是之前run一个容器时,创建的容器名。
- /bin/bash:通俗点讲,#!/bin/bash: 是指此脚本使用/bin/bash来解释执行。其中,#!是一个特殊的表示符,后面紧跟着解释此脚本的shell路径。bash只是shell的一种,还有很多其它shell,比如:sh,csh,ksh,tcsh等等。shell脚本通常第一句是#!/bin/bash,在很多情况中,如果没有设置好这一行,那么该程序很可能无法执行,因为系统无法判断该程序需要使用什么shell来执行
下图显示成功进入容器内部,@后面跟“63d8a927b72c”的就是容器id。

3.2 切换至该容器下的/opt/kafka/bin目录。此目录下存放的全是官方编写好的 .sh 文件。这些.sh文件全是脚本文件,不同脚本文件集合了不同的命令行命令,一个脚本文件实现一个功能,用户只用执行这个.sh文件+参数,就能实现很多命令,方便很多。
例如创建topic、producer、consumer就需要执行对应的 .sh 文件。切换到此目录下的好处是,可以省略前面的路径了。
可以照着下图依次切换(建议这样做,才能熟悉kafka容器默认文件夹下都有什么文件)。当然也可以一步到位:
cd /opt/kafka/bin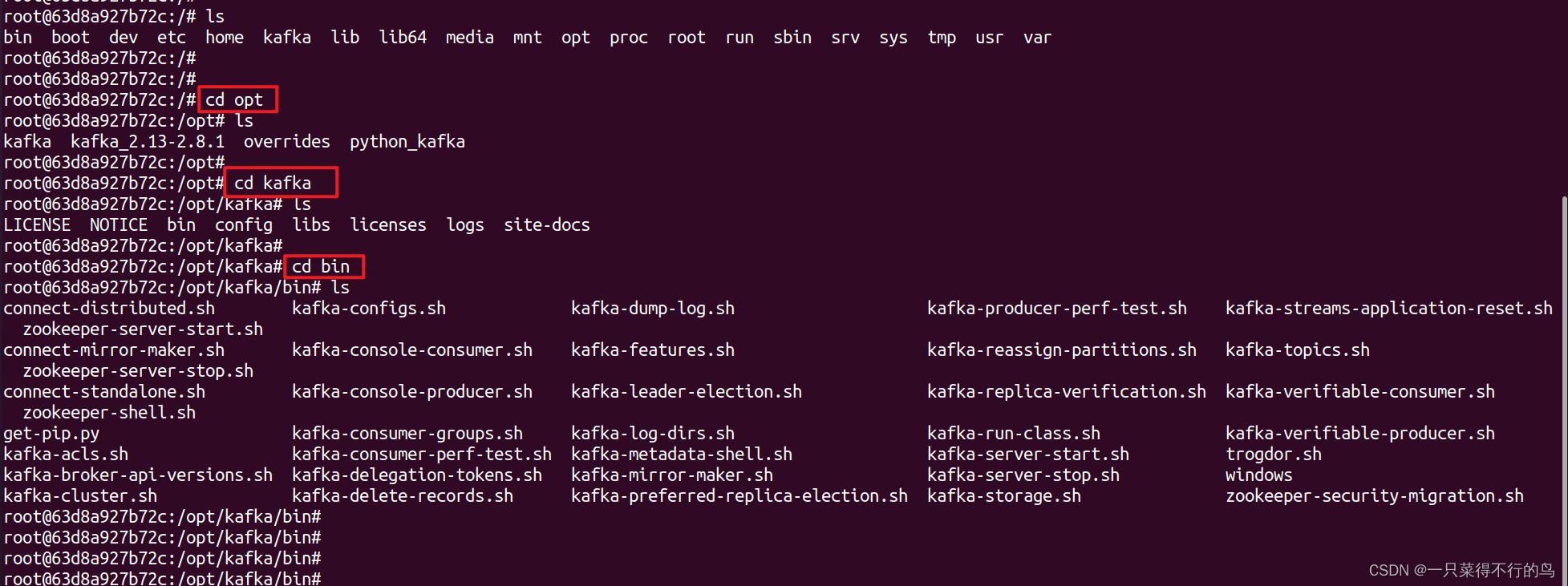
3.3 创建一个主题kafka-topics.sh --create \ --zookeeper zookeeper:2181 \ --replication-factor 1 \ --partitions 1 \ --topic mykafka参数说明(具体参数可参考《kafka-topics.sh脚本详解》):
- create:创建Topic。
- zookerrper:指定连接的zk的地址。
- replication-factor:创建主题时指定副本数
- partitons:创建主题或增加分区时指定的分区数
- topic:指定主题名称
使用如下命令可查看已创建的Topic,下图可见之前创建的mykafka的Topic。
kafka-topics.sh --zookeeper zookeeper:2181 --list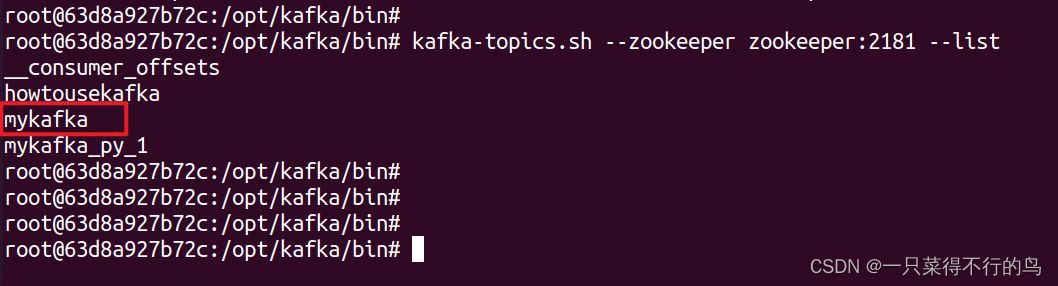
3.4 运行一个消息生产者,指定topic为刚刚创建的topic。
kafka-console-producer.sh --broker-list localhost:9092 \ --topic mykafka参数说明(具体参数可参考《kafka-console-producer.sh脚本详解》):
- broker-list:要连接的服务器,也可用bootstrap-server代替。
- topic:接收消息的主题名称。
3.5 新开一个终端,进入相同目录,运行一个消费者,指定同样的主题:
docker exec -it kafka /bin/bash cd opt/kafka/bin kafka-console-consumer.sh --bootstrap-server localhost:9092 \ --topic mykafka \ --from-beginning下图为生产者发送消息,消费者消费消息。
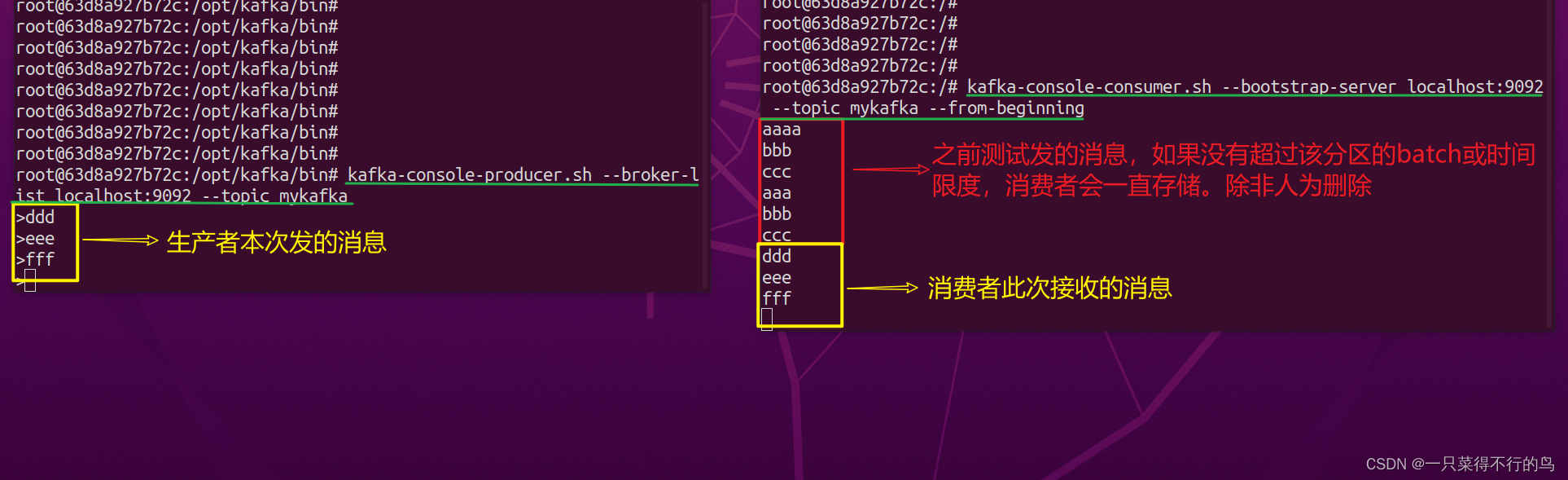
有人肯定有疑问,为什么consumer会接收之前发送的消息?因为配置消费者时加了参数
--from-beginning,代表consumer从存在的最早消息开始消费,而不是从最新消息开始。下图是去掉--from-beginning参数的相同topic的consumer,可以看到则从最新消息开始消费。
3、在kafka容器内部署python,并跑通生产者-消费者简单代码
前提:
默认部署了zookeeper容器和kafka容器,且处于up状态。如果不是up状态,记得先restart zookeeper,再restart kafka。
使用sudo docker ps -a可查看所有容器加状态,如果不含参数-a就只能查看正在运行的容器。由于我之前关闭了虚拟机,因此查看之前部署的两个容器,可以看到下图均处于非up状态。

restart了以后可以看到下图部署了zookeeper容器和kafka容器,别名就是zookeeper和kafka。

下面开始部署python环境
-
先进容器内部:
docker exec -it kafka /bin/bash #(这里kafka为你的容器id或别名)可以看到,成功进入容器内部,自动当前用户切换到root,@后面跟的是容器id:

-
更新apt指令。不更新第3步可能报错:
apt update -
安装pip指令。安装pip时就自动安装python3环境了:
apt install pippython命令执行,发现安装环境成功。再输入exit()退出。
-
安装第三方库:kafka-python。
python代码中from kafka import KafkaConsumer, KafkaProducer就是导自这个库。
pip install kafka-python
-
切换至opt目录,并创建文件夹保存python文档,这里我叫python_kafka.

-
切换至python_kafka目录后,开始创建三个文件:config1.py为参数初始化文件,consumer1.py为消费者进程,produer.py为生产者进程。三个文件参考自《如何使用Python读写Kafka?》
下面为具体步骤:
6.1. config1.py
在python_kafka目录下使用vim命令,创建并编辑config1.py文件。注意,第一次使用需要使用命令apt install vim,安装vim。
vim config1.py下面代码是config1.py具体内容。我是在windows下vscode写好的,直接复制粘贴过去的。windows下复制了,vim下在insert模式下按住shift再鼠标右键,便能粘贴(具体参考《Windows中的文本与Linux中CentOS的vim编辑器相互复制粘贴方法》)
# config1.py # 参数初始化 SERVER = 'localhost:9092' TOPIC = 'mykafka_py_1'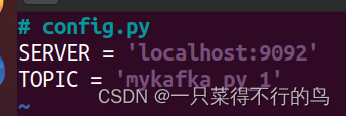
写完了记得保存退出。 -
producer1.py
创建生产者。同样在python_kafka目录下,使用命令vim,创建并编辑producer1.py文件。
vim producer1.py下面代码是producer1.py具体内容:
import json import time import datetime import config1 from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers=config1.SERVER, value_serializer=lambda m: json.dumps(m).encode()) for i in range(100): data = {'num': i, 'ts': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')} producer.send(config1.TOPIC, data) time.sleep(1)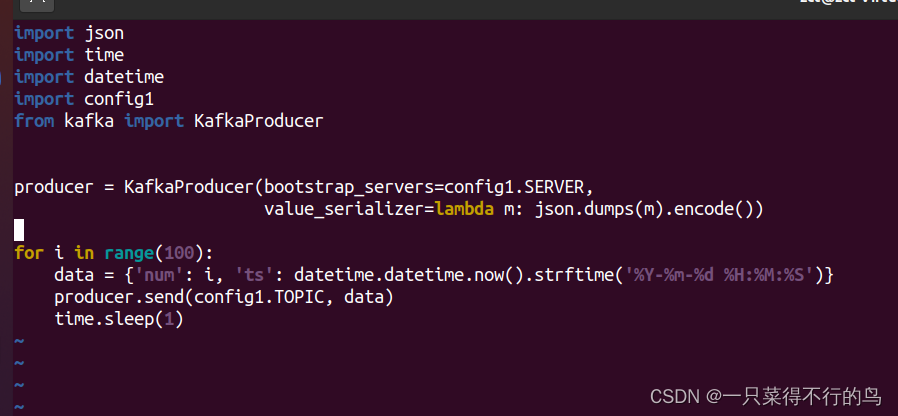
-
consumer1.py
创建消费者。同样在python_kafka目录下,使用命令vim consumer1.py,创建并编辑consumer1.py文件。
vim consumer1.py下面代码是consumer1.py具体内容:
import config1 from kafka import KafkaConsumer consumer = KafkaConsumer(config1.TOPIC, bootstrap_servers=config1.SERVER, group_id='test', auto_offset_reset='earliest') for msg in consumer: print(msg.value) -
一个生产者,一个消费者。可以看到互通消息了。
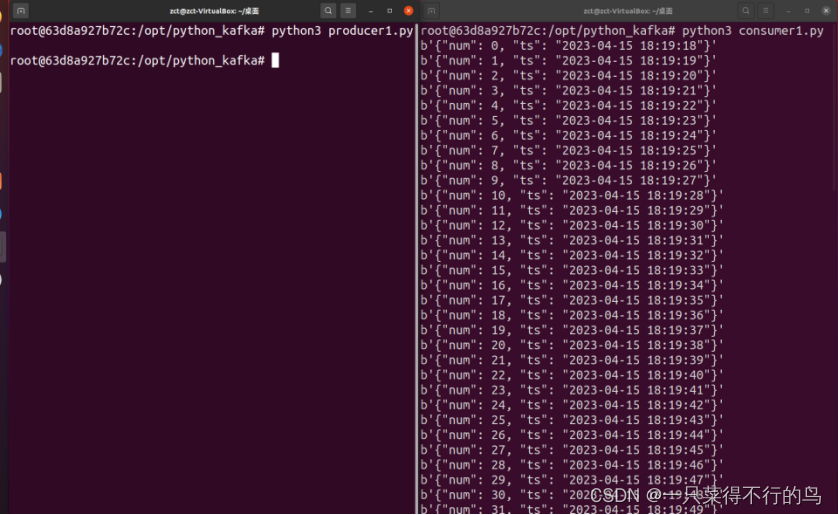
说明:关于上方简单代码的具体函数和参数,可以看下方最新接口中的kafka_interface.py文件中注释。已将producer中的三种发送消息方式总结了。
4、最新接口
贡献:
1、对于第3部分简单代码进行改写,抽象成三个文件;
2、kafka_interface.py对于producer中三种方式进行了总结并代码复现,具体见其注释;
3、对于cosumer消费方式也进行了总结,具体见其注释。
参考:
《python kafka订阅之producer三种模式》
《学会使用Kafka(十一)Python生产者和消费者API使用 》
《《Apache Kafka系列》Kafka生产者(Producer)发送消息的几种方式,以及生产者相关配置》
《Python kafka操作实例(kafka-python)》
《Python之kafka消息队列操作入门》
《Python 操作 Kafka — kafka-python》
《Apache Kafka的3个核心Python客户端库》
4.1、kafka_config.py
# -*- coding: utf-8 -*-
# kafka_config.py
SERVER = 'localhost:9092'
TOPIC = 'howtousekafka'
group_id = 'test'
auto_offset_reset = 'earliest'
4.2、kafka_interface.py
# -*- coding: utf-8 -*-
# kafka_interface.py
from kafka import KafkaConsumer, KafkaProducer
import logging
import traceback
import kafka_config
log = logging.getLogger(__name__)
class KafkaInterface:
def __init__(self):
self.producer = KafkaProducer(bootstrap_servers=kafka_config.SERVER)
# self.consumer = KafkaConsumer(kafka_config.TOPIC,
# bootstrap_servers=kafka_config.SERVER,
# group_id=kafka_config.group_id,
# auto_offset_reset=kafka_config.auto_offset_reset)
'''
因为消费者消费数据时可以才从subscribe方法订阅相应的主题或assign订阅相应的分区,
故初始化时不必指定topic,故采用下面此种写法。
再高级点的用法是在subscribe基础上,搭配poll函数。有时候,我们并不需要实时获取数据,
因为这样可能会造成性能瓶颈,我们只需要定时去获取队列里的数据然后批量处理就可以,
这种情况,我们可以选择主动拉取数据。
'''
self.consumer = KafkaConsumer(bootstrap_servers=kafka_config.SERVER,
group_id=kafka_config.group_id,
auto_offset_reset=kafka_config.auto_offset_reset)
'''
Kafka发送消息主要有三种方式:
1.发送并忘记
2.同步发送
3.异步发送+回调函数
下面以单节点的方式分别用三种方法发送消息
'''
def send_message_asyn_producer(self, message):
"""
方式一:
发送并忘记(把消息发送给服务器,不关心消息是否正常到达,对返回结果不做任何判断处理)
说明:
1、发送并忘记的方式本质上也是一种异步的方式,消息先存储在缓冲区中,达到设定条件后批量发送,
只是它不会获取消息发送的返回结果,这种方式的吞吐量是最高的,但是无法保证消息的可靠性。
2、由于测试数据太少,异步看着像同步。当发送例如1w条消息时,可以通过对比执行完成时间可以看出:
异步发送时间是低于同步发送时间的。
"""
while True:
counter = 0 # 记录一共发了多少条消息
try:
for item in message.split(","):
counter += 1 # 发一条消息就增加一条
self.producer.send(kafka_config.TOPIC,
item.encode('utf-8'))
self.producer.flush() # 批量提交
print("您使用方法一简单异步发送消息,此次一共发送了{}条消息".format(counter))
self.producer.close()
break
except Exception as e:
log.error("Kafka asyn send fail, {}.".format(e))
traceback.format_exc()
def send_message_sync_producer(self, message):
"""
方式二:
同步发送数据(通过get方法等待Kafka的响应,判断消息是否发送成功)
说明:
1、以同步的方式发送消息时,一条一条的发送,对每条消息返回的结果判断,可以明确地知道每条消息的发送情况,
但是由于同步的方式会阻塞,只有当消息通过get返回future对象时,才会继续下一条消息的发送。
2、如果业务要求消息必须是按顺序发送的,那么可以使用同步的方式,并且只能在一个partation上,
结合参数设置retries的值让发送失败时重试,因为在同一个分区上是FIFO,不同分区上不能保证顺序读取,
故只有指定同一个分区才能保证顺序读取。
3、send函数是有返回值的是RecordMetadata,也就是记录的元数据,包括主题、分区、偏移量
"""
while True:
counter = 0 # 记录一共发了多少条消息
try:
for item in message.split(","):
counter += 1 # 发一条消息就增加一条
# 同步确认消费,即监控是否发送成功。future.get函数等待单条消息发送完成或超时,或用time.sleep代替
future = self.producer.send(
kafka_config.TOPIC, item.encode('utf-8'))
# time.sleep(10) # 等价于future.get(timeout=10)
# future.get会返回一个类ConsumerRecord, 内容格式如下:
# ConsumerRecord{topic=xxx, partition=xxx, offset=xxx, timestamp=xxx, timestamp_type=xxx, ...}
record_metadata = future.get(timeout=10)
partition = record_metadata.partition # 数据所在的分区
offset = record_metadata.offset # 数据所在分区的位置
log.debug("save success, partition: {}, offset: {}".format(
partition, offset)) # 输出到日志
print("您使用方法二同步发送消息,此次一共发送了{}条消息".format(counter))
break
except Exception as e:
log.error("Kafka sync send fail, {}.".format(e))
traceback.format_exc()
def send_message_asyn_producer_callback(self, message):
"""
方法三:
异步发送+回调函数(消息以异步的方式发送,通过回调函数返回消息发送成功/失败)
说明:
1、在调用send方法发送消息的同时,指定一个回调函数,服务器在返回响应时会调用该回调函数,通过回调函数
能够对异常情况进行处理,当调用了回调函数时,只有回调函数执行完毕生产者才会结束,否则一直会阻塞。
2、如果业务上需要知道消息发送是否成功,并且对消息的顺序不关心,那么可以用异步+回调的方式来发送消息,
配合参数retries=0,并将发送失败的消息记录到日志文件中。
"""
while True:
counter = 0 # 记录一共发了多少条消息
try:
for item in message.split(","):
counter += 1 # 发一条消息就增加一条
self.producer.send(kafka_config.TOPIC, item.encode('utf-8')).add_callback(
self.send_success).add_errback(self.send_error)
# 注册回调也可以这样写,上面的写法就是为了简化
# future.add_callback(self._onSendSucess)
# future.add_errback(self._onSendFailed)
# self.producer.send(self.topic, data).add_callback(self.send_success).add_errback(self.send_error)
self.producer.flush() # 批量提交
print("您使用方法三异步+回调发送消息,此次一共发送了{}条消息".format(counter))
self.producer.close()
break
except Exception as e:
log.error("Kafka asyn send fail, {}.".format(e))
traceback.format_exc()
def send_success(self, record_metadata):
"""
异步发送成功回调函数,也就是真正发送到kafka集群且成功才会执行。发送到缓冲区不会执行回调方法。
"""
print("发送成功")
print("被发往的主题:", record_metadata.topic)
print("被发往的分区:", record_metadata.partition)
# 这个偏移量是相对偏移量,也就是相对起止位置,也就是队列偏移量。
print("队列位置:", record_metadata.offset)
log.debug("save success")
def send_error(self):
print("发送失败")
log.debug("save error")
# def send_message(self, message):
# producer = self.producer.send(
# kafka_config.TOPIC, message.encode('utf-8'))
# producer.flush()
def receive_message(self):
print("消费者开始消费来自生产者的消息:")
self.consumer.subscribe([kafka_config.TOPIC])
for k, v in enumerate(self.consumer, start=1): # 这里将list转换为enumerate类型
print("收到第{}条消息为:{}".format(k, v.value.decode('utf-8')))
# 消费,这里具体为打印,到时候具体什么逻辑操作,再定
'''
不足:
1、单机,没有实现分布式。尝试搭建一个boker集群,并指定不同分区试一试分布式;
2、配置文件很简单,应像之前那样修改,例如读一个json文件来返回;
3、代码是否有些变量和方法需要改成私有?
4、此代码并不是最终抽象的接口,例如回调函数那里,可以利用@abc.abstractmethod,变成抽象方法。
好处是不同实例可能回调函数编写不同,例如UAV实例和environment实例;
5、message那里,有待商榷。目前初步想法是用户实例产生的:环境状态信息、智能体信息、错误信息,
这些统一格式例如json格式,然后用户实例调用时可以将json里的message统一发送。统一格式的好处是
就算message很复杂,但是统一后可以对message进行统一处理,例如切片处理等。
'''
4.3、run.py
# -*- coding: utf-8 -*-
import kafka_interface
import time
usermessage = input('请输入你要发的消息,每条消息间用英文逗号隔开: ')
kafka_interface = kafka_interface.KafkaInterface()
start_time = time.time()
'''
测试时记得修改,测试3种方案
'''
kafka_interface.send_message_asyn_producer(usermessage) # 简单异步,即发送并忘记
# kafka_interface.send_message_sync_producer(usermessage) # 同步
# kafka_interface.send_message_asyn_producer_callback(usermessage) # 同步加回调
end_time = time.time()
print("time: {}".format(end_time-start_time))
kafka_interface.receive_message()
4、测试
测试一:修改run.py文件,使用简单异步发送


测试二:修改run.py文件,使用同步发送


测试三:修改run.py文件,使用异步+回调发送。


分析:
- 可以看出同步发送消息的时间会比异步的时间更长
- 异步+回调的一般用得会更多
注意:
ctrl+z退出run.py时,一定要run.py显示完毕后等5秒以后再退出,否则会出现下方重复消费的情况。
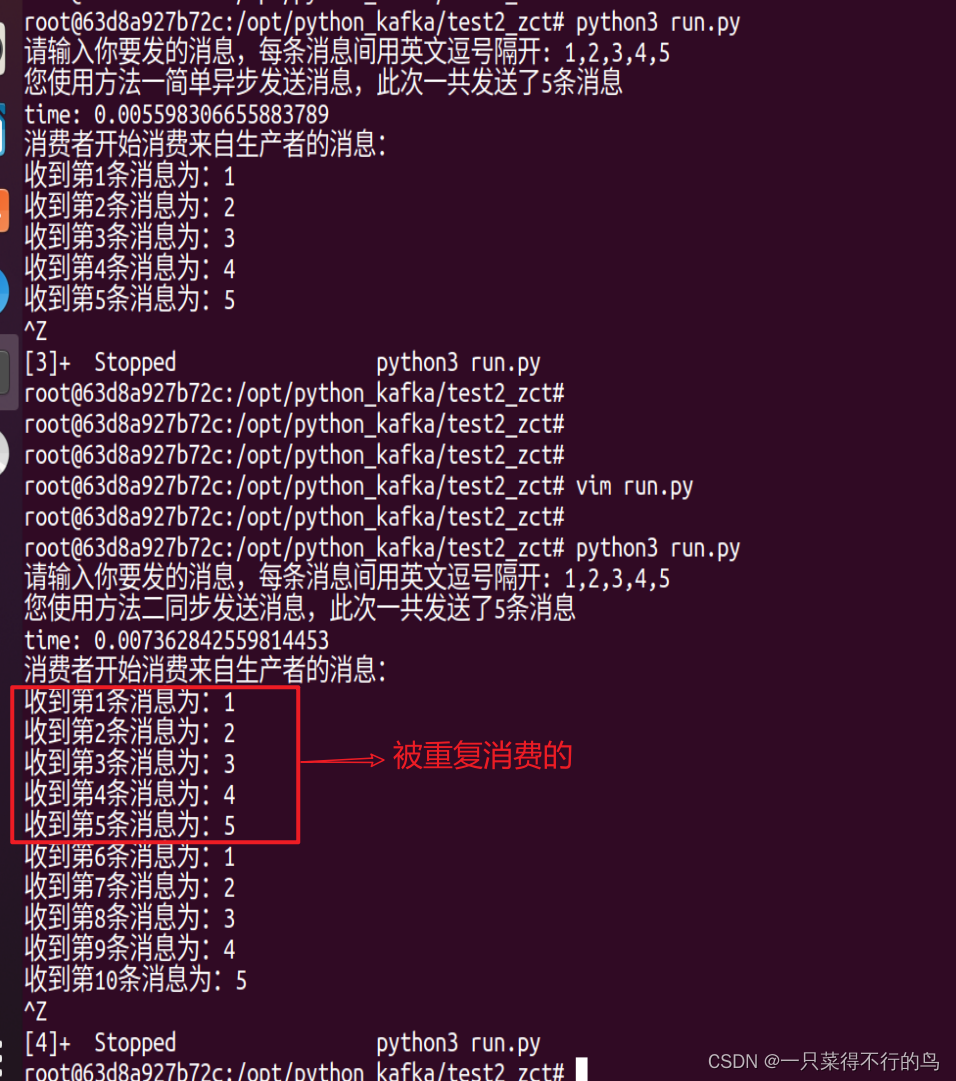
原因:
重复消费出现的常见场景主要分为两种,一种是 Consumer在消费过程中,应用进程被强制kill掉或者发生异常退出(挂掉…),另一种则是Consumer消费的时间过长。
-
Consumer消费过程中,进程挂掉/异常退出
在Kafka消费端的使用中,位移(Offset)的提交有两种方式,自动提交和手动提交。自动提交情况下,当消费者拉取一批消息进行消费后,需要进行Offset的提交,在消费端提交Offset之前,Consumer挂掉了,当Consumer重启后再次拉取Offset,这时候拉取的依然是挂掉之前消费的Offset,因此造成重复消费的问题。在手动提交模式下,在提交代码调用之前,Consumer挂掉也会造成重复消费。
-
消费者消费时间过长
Kafka消费端的参数max.poll.interval.ms定义了两次poll的最大间隔,它的默认值是 5 分钟,表示 Consumer 如果在 5 分钟之内无法消费完 poll方法返回的消息,那么Consumer 会主动发起“离开组”的请求。
在离开消费组后,开始Rebalance,因此提交Offset失败。之后重新Rebalance,消费者再次分配Partition后,再次poll拉取消息依然从之前消费过的消息处开始消费,这样就造成重复消费。而且若不解决消费单次消费时间过长的问题,这部分消息可能会一直重复消费。
整体上来说,如果我们在消费中将消息数据处理入库,但是在执行Offset提交时,Kafka宕机或者网络原因等无法提交Offset,当我们重启服务或者Rebalance过程触发,Consumer将再次消费此消息数据。
总结:这里重复消费的原因是原因1。这里设置的是默认自动提交offset,自动提交是发生在消费者消费完后每隔5秒(由auto.commit.interval.ms指定)提交一次位移。而这里杀进程过快了,都没来得及提交,自然而然要重复消费了。