这两个也不是新面孔了。
那么OODS和HCPR到底他俩怎么用?既然大家都是虚拟的,不占地方。那这俩infoprovider到底有啥区别?
首先就是目的不同。
HCPR是可以用Union和Join。也就是老的Multiprovider和InfoSet。Union就是说两个数据集的行能被互相添加到彼此身上,然后你有我有大家有。Join就是把一个表的列加到另一个表上,但前提是两个表的相同列中有相同值做过滤。
HCPR这么牛哄哄的,那OODS是来干啥的?
OODS的能力就是它能连外部的表。比如你有外围系统的数据存在Oracle数据库上,毕竟咱现在BW都在HANA上了。那么我既想去拿它的数据,又不想多存一份在我BW这里。那咱就可以用SDA连接到Oracle数据库,然后创建一个虚拟表。(这个是Basis帮忙建连接)
基于这个虚拟表,我们就可以建一个OODS ,至此你也就有了一个到Oracle表的虚拟连接。在这个OODS上建的query在运行时就会去直接访问外部表。当然如果你想保存数据,那就接着建ADSO就好了。不保存的好处就是省空间,等于省钱。但是如果数据量很大,显然性能不会太好。
HCPR
先到HCPR瞅一瞅,你新建的时候就能发现,它能添加两种part provider:
Infoprovider或者HANA view,也就是说calculation view能用来混合建模。你想用的前提是得把你的HANA attach到这个BW project里面。
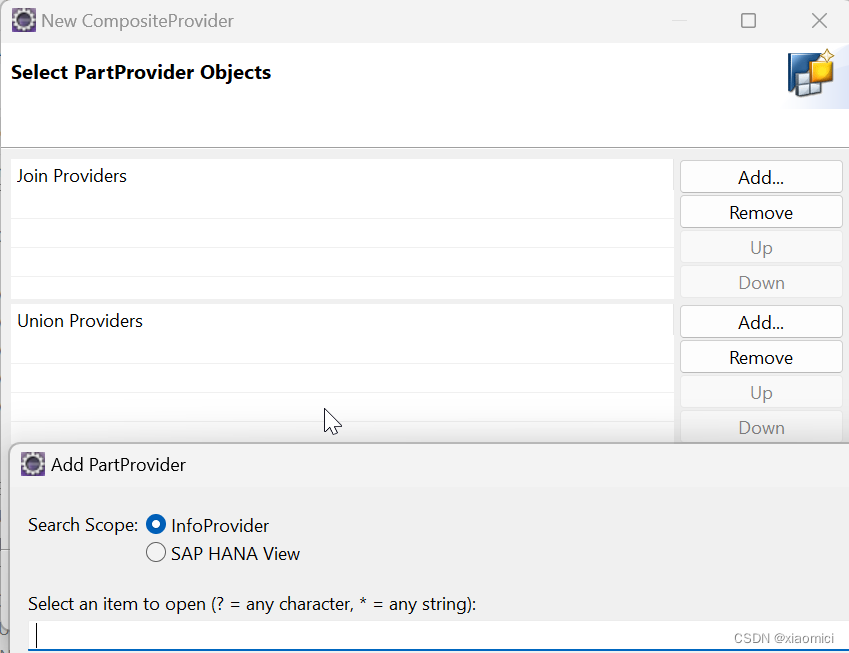
选择union或者join,这些part provider都会在跑query的时候被关联起来。
Union的话,你想加多少个part provider都行,但是前提是,第一个part provider得是交易数据,此后你能union很多次。
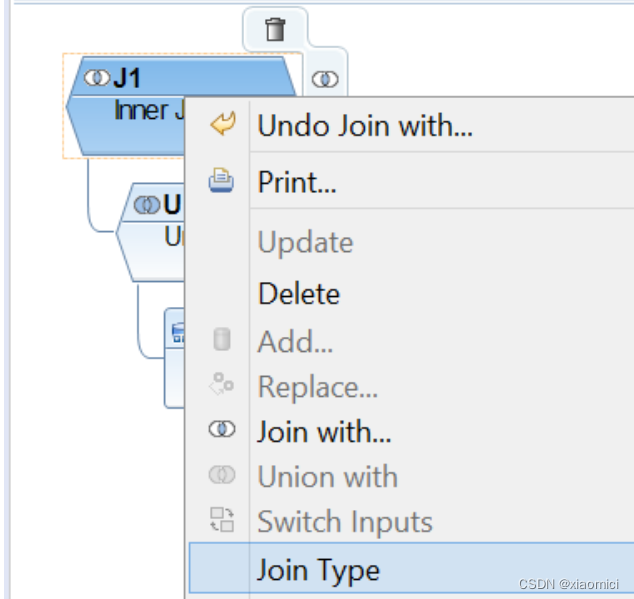
Union里面是把相似的数据源的字段映射到相同的一个字段里。这些字段得是相同数据类型,长度,技术名的。描述不一定要一样。描述会从第一个映射的数据源的字段读取。
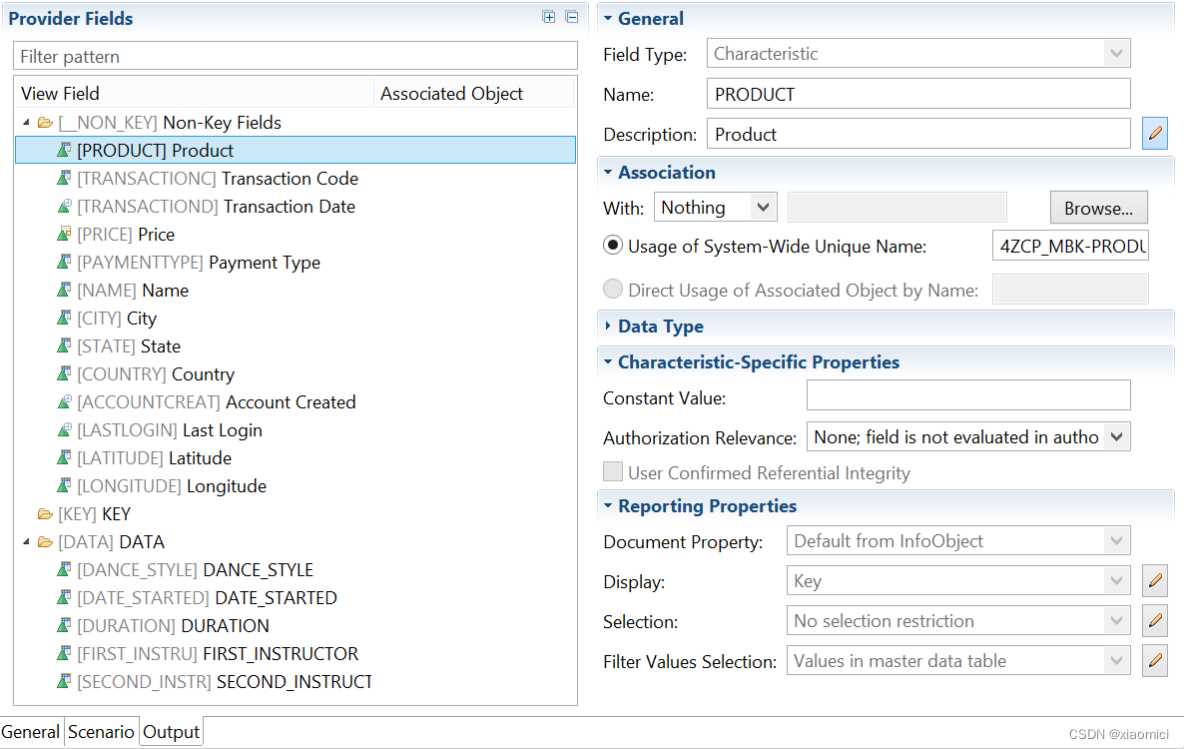
建好的HCPR看output里能看到所有字段的属性,这些字段按逻辑组分类。这个组可以自己修改的。
OODS
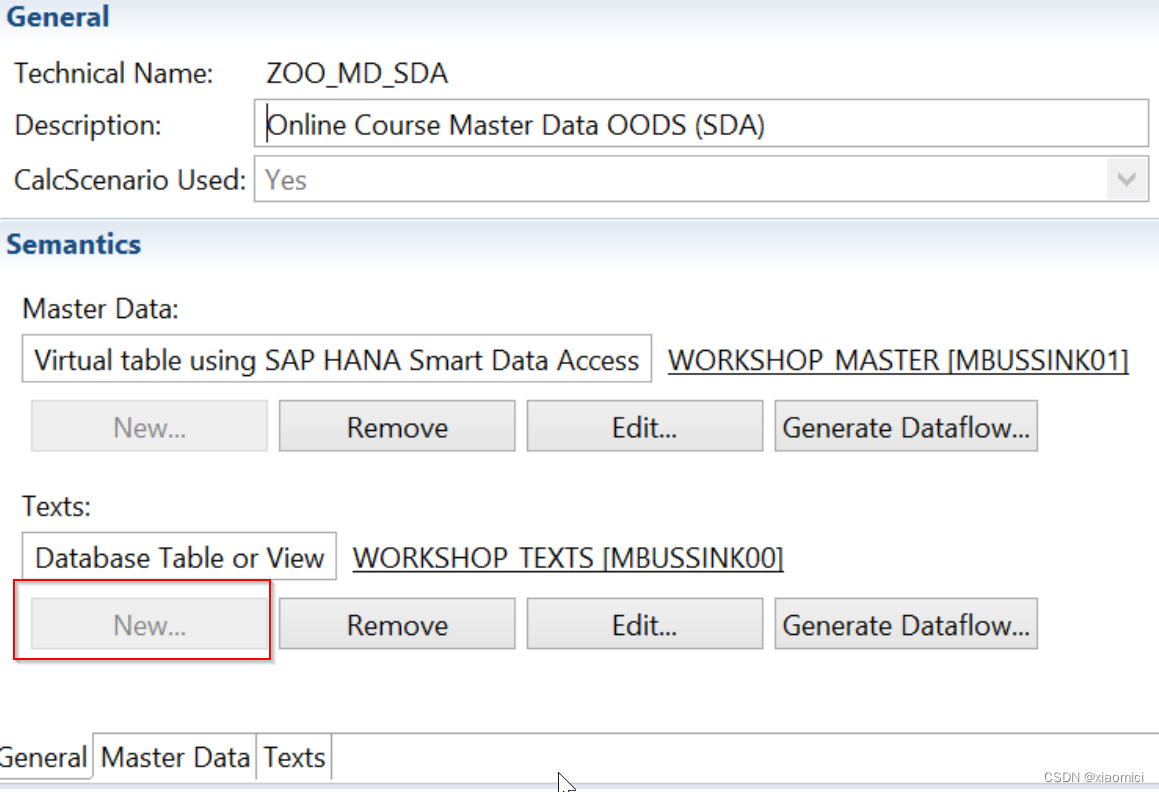
OODS的主要功能是连接外部数据,可以是以fact表或者主数据或者文本。
也就是说你有在外部数据库的数据想要在BW里面用,但是又不想冗余保存一遍在BW里面,那么你就设置一个SDA连接到外部数据库,创建一个Virtual Table。
建好了一个Virtual Table之后,也就是你对外部数据库的表有了一个虚拟连接,然后就可以去建一个OODS了。如果在这个OODS上直接建query,那就会在query执行的时候直接访问外部数据库表。这样就是剩下HANA空间了,不用保存一遍,但是数据量大的话会耗时。但是如果你想保存一遍到BW上,比如保存历史数据的话,那就在OODS上建一个CP,然后在CP和ADSO间建转换和DTP,把数据拉到ADSO里面。
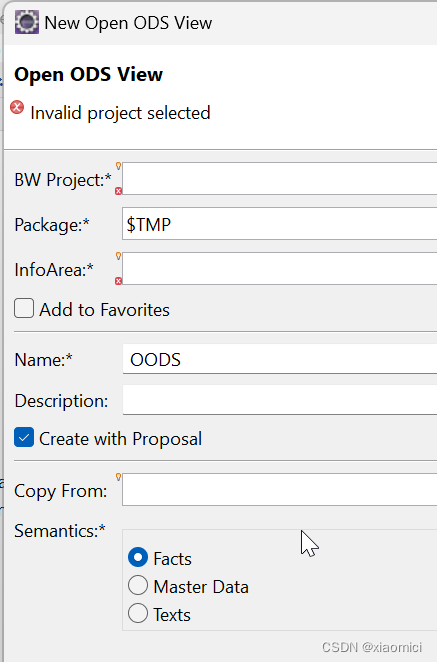
建一个OODS,可以选择很多数据源类型。
DataSource(BW)
的话,就是得有个数据源,可以是ECC的数据源,也可以是你自己建在BW里面的一些数据源。
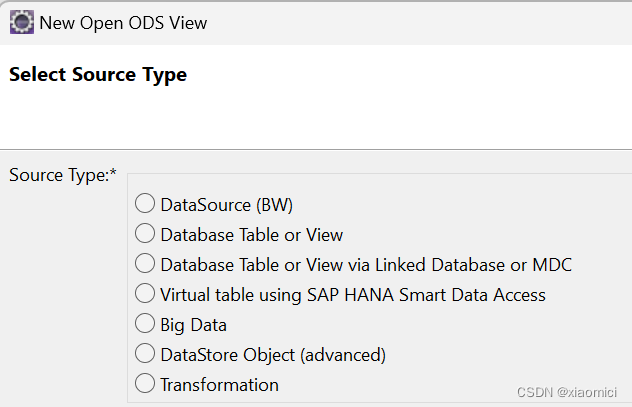
Database Table or View就是在HANA数据库里的表,选这个会把你带到下一层:

如果选了
existing BW Source System
呢,就是你的BW对应的HANA系统了。接下来是到你的BW对应的HANA系统去选Schema了。建好了之后呢,就可以
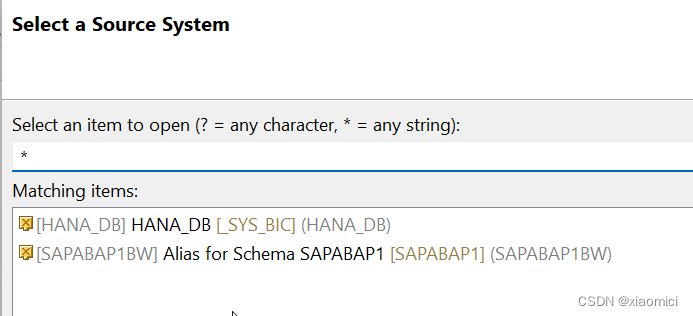 这个HANA Source System 其实是早就建好了的。你自己可以RSA1看到的,在eclipse里面也能看到的:
这个HANA Source System 其实是早就建好了的。你自己可以RSA1看到的,在eclipse里面也能看到的:
看不到就自己建一个。
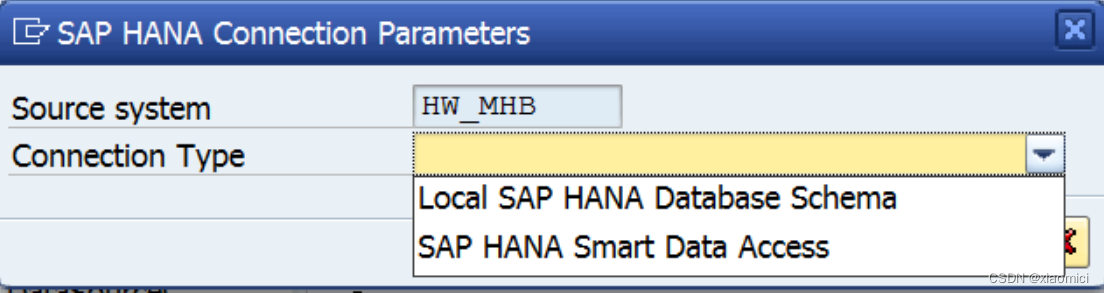

建好了之后就可以从HANA系统进去选择Schema下面的表来建OODS了。
如果选的是
Owner/Schema
就是直接去HANA下面的所有Schema去找表了。那么这两个有啥不同呢?
如果你选现存的BW源系统,它其实是指向保存BW的表的HANA数据库Schema,然后可以去这些Schema下面去选表。
如果选Owner/Schema,也就是你会先选一个Schema,然后选表。但是之后,你还得选一个源系统。没有源系统BW没办法搞数据。
那么这个源系统要么是选一个这个Schema已经在的源系统,要么就是新建一个。
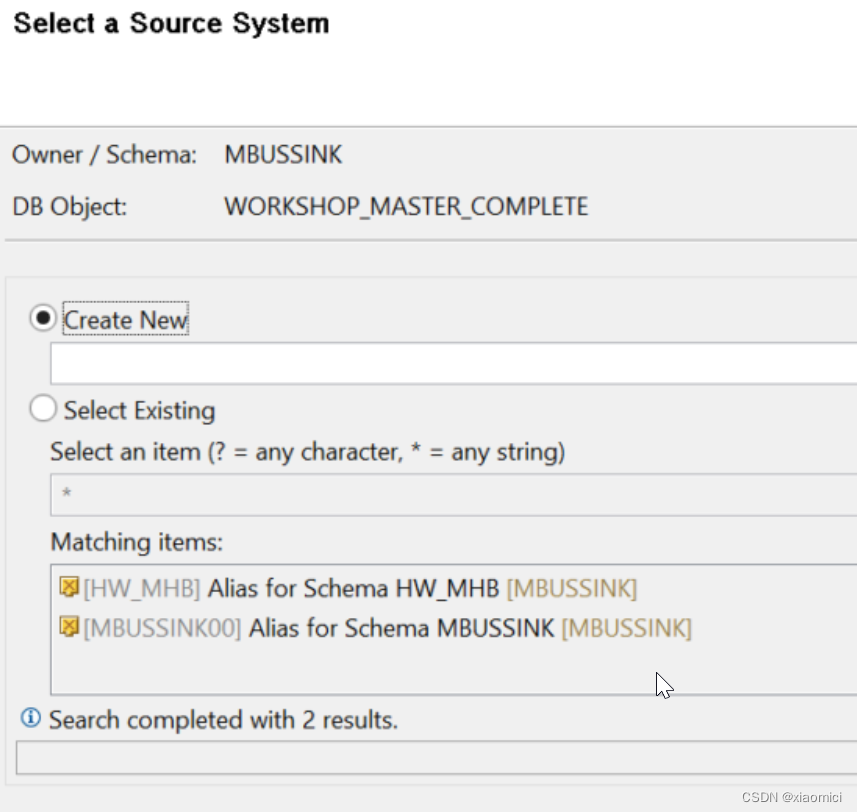
这些都搞好了之后,就能建一个OODS了,如果你建好了,激活出现错误:
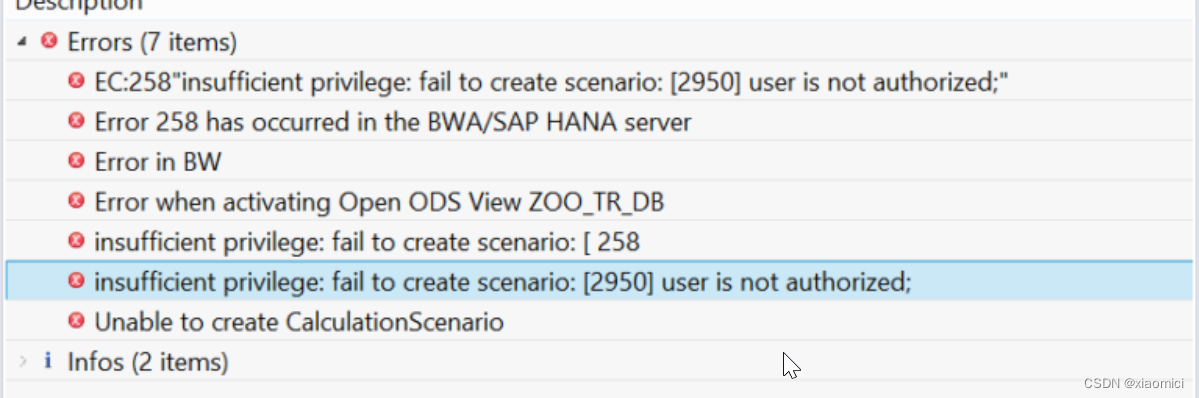
那么可能你的用户没有在这个Schema上建OODS的权限。
让你的HANA管理员给你GRANT Select on Schema 'Schema_name' to 'user_name'.
如果选了
Virtual Table Using SAP HANA SDA
那就是连接到外部表。不需要数据源了。提前建好SDA数据源,然后就和从HANA的表建OODS一样的步骤。这个让有CREATE REMOTE SOURCE权限的Basis做。作为BW只要有CREATE VIRTUAL TABLE的权限就行。
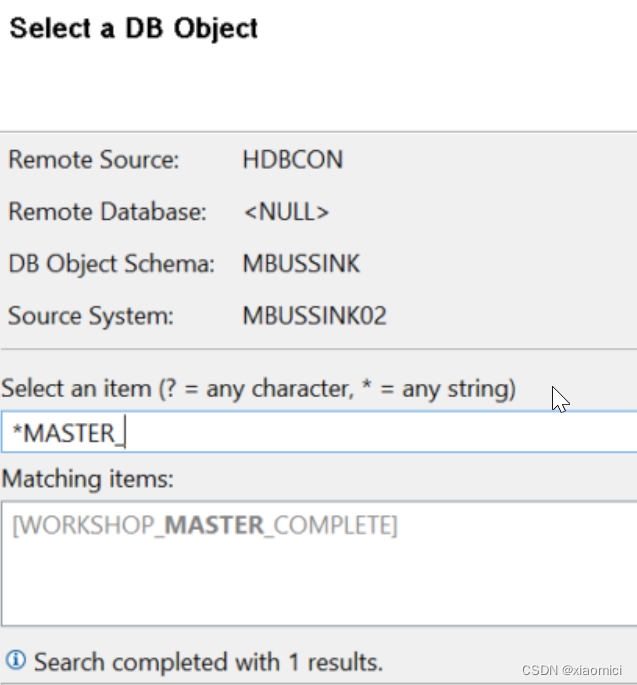
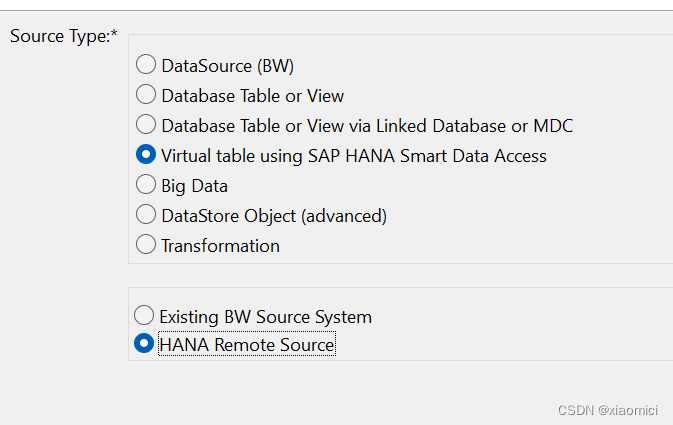
如果选了远程数据源,那就是远程连接。最后也需要建一个源系统。这个咱没搞过。
ADSO
选了Data Store Object的,意义何在呢?
不是说去拿外部数据的么。
有个用处就是把底层基于字段的ADSO的一些数据类型给转换掉,咋转换呢,就用和infoobject关联来转换。这是一个用法吧。
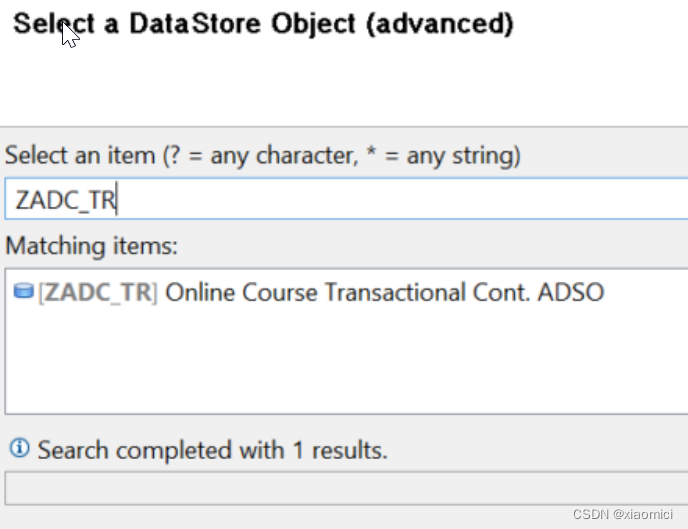
Transformation
接下来,要建基于转换的OODS。首先这个OODS不能被用做转换的源或目标。那么我们需要建一个数据源。数据源之上要有一个infosource,在数据源和信息源之间建一个转换:

接下来要建的OODS就是基于这个数据源和信息源之间的转换了。

不过这种做法有什么用处?就是用来传输virtual table的数据?我觉得还不如直接建一个OODS来的快。具体用法还有待考究。
接下来看一个OODS的不同语义。
如果一开始你选的是Fact表,也就是你要把它当做交易数据来用。那你建好之后可以把source fields拖到view fields里面的不同的folder下面。特性关键值和单位等等。你也可以关联特性字段到一些infoobject。这样在跑query的时候能用到信息对象的导航属性和主数据啥的。也可以设置Key,最后用成ADSO的主键。
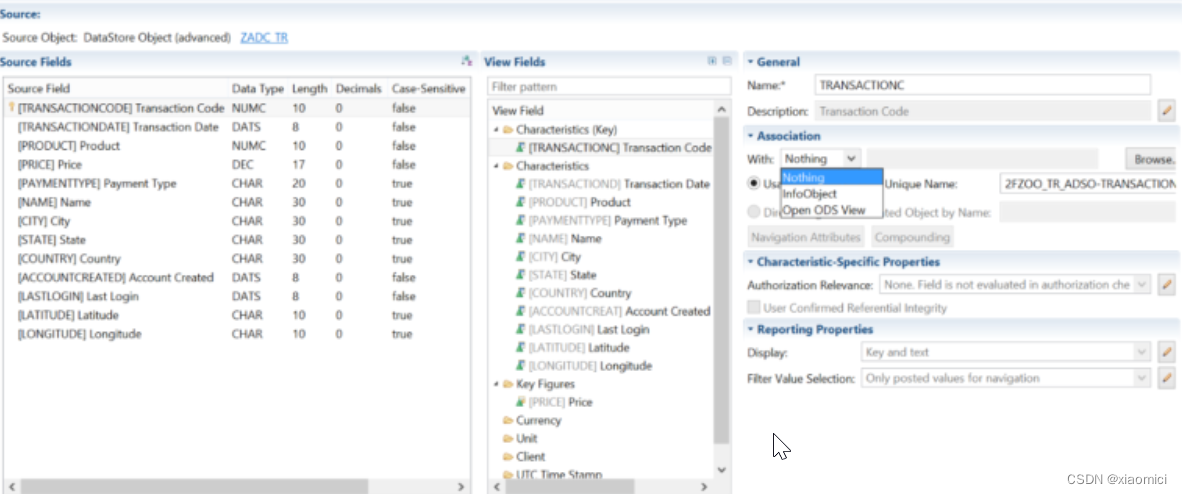
如果选的是主数据表,那就是说它的功能是个主数据表,在HCPR里面你就可以把它关联到一些信息对象上,这个信息对象能够用你建的主数据OODS的属性了。
那么在这个主数据OODS里面,有个Representative Key Field是用来和HCPR做关联的。除了这个Key Field之外的其他字段你都能用作导航属性。
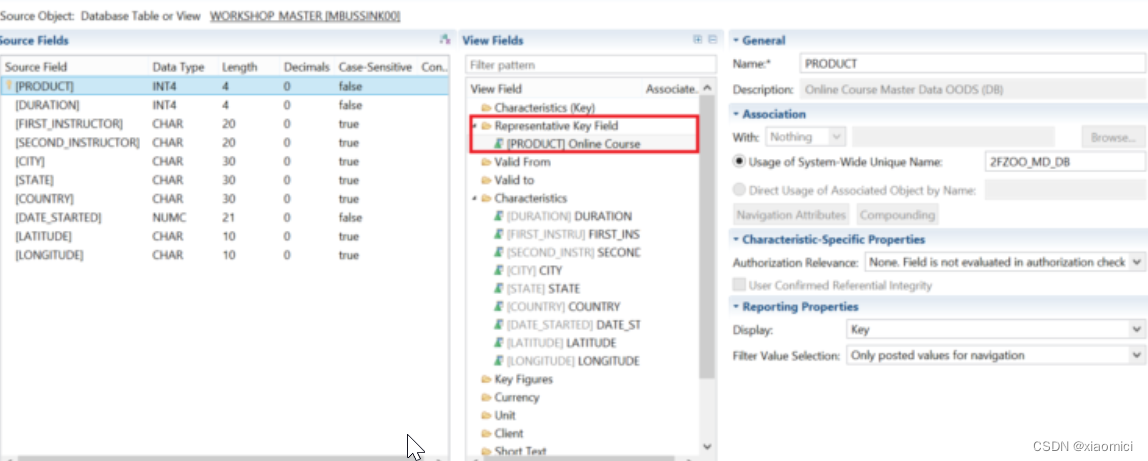
这个主数据OODS的folder就和主数据表有点像了,你可以把对应的source字段放到时间相关的folder下面,或者是单位,文本folder下面。同时,还有除了Represetative Key Field之外的Charecteristic Key是用来做联合主键的。compounding的意思。
如果是选了Text的呢,那就是跟主数据的OODS有一点不一样了,Text的会包含Language这个folder。
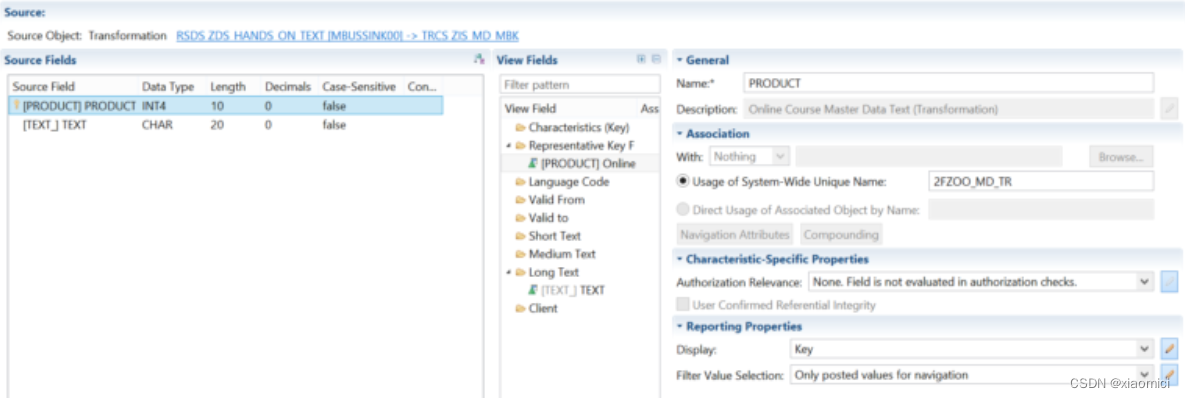
也就是他能设置语言相关。
但是Text的OODS就只能在HCPR的信息对象关联里面用到。这个里面也要用到关联字段:Representative key Field.用来和HCPR的字段做关联。
而且Text字段要放到Short Text或者Medium Text等的folder下面。
Text的OODS还可以被添加到主数据的OODS下面去。在General下面New就能把Text加到主数据里,或者把主数据加到Text里。