目录
一、概要
二、深入扩展
2.1 预训练任务
2.2 模型精调
一、概要
如果将基于Transformer的双向语言模型(如BERT模型中的掩码语言模型)与单向的自回归语言模型(如BART模型的解码器)进行对比,可以发现,两者的区别主要在于模型能够使用序列中的哪部分信息进行每一时刻隐含层表示的计算。对于双向 Transformer,每一时刻隐含层的计算可以利用序列中的任意单词;而对于单向Transformer,只能使用当前时刻以及“历史”中的单词信息。基于这一思想,研究人员提出了单向Transformer结构的
统一语言模型
(Unified LanguageModel,UniLM)。
不同于BART模型的编码器--解码器结构,UniLM只需要使用一个Transformer网络,便可以同时完成语言表示以及文本生成的预训练,进而通过模型精调应用于语言理解任务与文本生成任务。它的核心思想是通过使用不同的自注意力掩码矩阵控制每个词的注意力范围,从而实现不同语言模型对于信息流的控制。
二、深入扩展
2.1 预训练任务
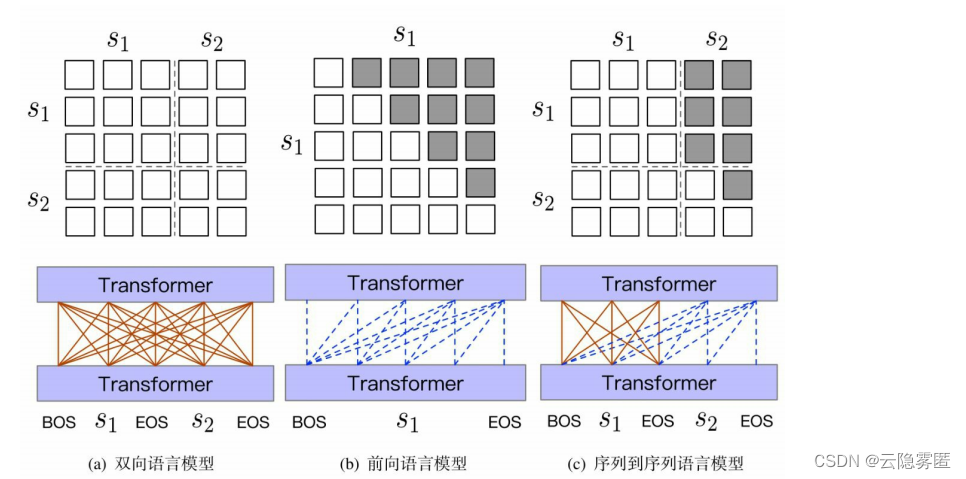
UniLM 模型提供了一个统一的框架,可以利用双向语言模型、单向语言模型和序列到序列语言模型进行预训练。其中,基于双向语言模型的预训练使模型具有语言表示的能力,适用于语言理解类下游任务;而基于单向语言模型以及序列到序列语言模型的预训练任务使模型具有文本生成的能力。下图展示了不同的预训练任务对应的自注意力掩码模式。
假设第 L 层 Transformer 的自注意力矩阵为AL,在UniLM中,AL可由下式计算
:
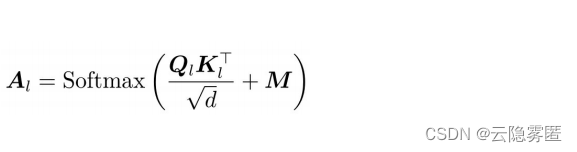
式中,QL、KL分别为第L层上下文表示经线性映射后得到的查询、键分别对应的向量:d是向量的维度。UniLM在原始自注意力计算公式的基础上增加了掩码矩阵M ∈ R(维度:n x n) ,n是输入序列的长度,M 是一个常数矩阵,定义如下
:

通过控制M,便可以实现不同的预训练任务。
(1)双向语言模型。输入序列由两个文本片段组成,由特殊标记 [EOS] 相隔。与 BERT 模型类似,在输入文本中随机采样部分单词,并以一定概率替换为[MASK]标记,最后在输出层的相应位置对正确词进行预测。在该任务中,序列中的任意两个词都是相互“可见”的,因此在前向传播过程中都能够被“注意”到。反映在Transformer模型中,则是一个全连接的自注意力计算过程,如图(a)所示。此时,对原始自注意力掩码矩阵不作任何变化,即M=0。
(2)单向语言模型。包括前向(自左向右)与后向(自右向左)的自回归语言模型。以前向语言模型(图(b))为例,对于某一时刻隐含层表示的计算,只能利用当前时刻及其左侧(前一层)的上下文表示。相应的自注意力分布是一个三角矩阵,灰色代表注意力值为0。相应的,掩码矩阵M在灰色区域处的值为负无穷(−∞)。
(3)序列到序列语言模型。利用掩码矩阵,还可以方便地实现序列到序列语言模型,进而应用于条件式生成任务。此时,输入序列由分别作为条件以及目标文本(待生成)的两个文本片段构成。条件文本片段内的词相互“可见” ,因此使用全连接的自注意力;对于目标文本片段,则采用自回归的方式逐词生成,在每一时刻,可以利用条件文本中的所有上下文表示,以及部分已生成的左侧上下文表示,如图(c)所示。在有关文献中,也将该结构称为前缀语言模型(PrefixLM)
。
与BART模型的编码器--解码器框架不同,这里的编码与解码部分共享同一套参数,而且在自回归生成的过程中,与条件文本之间的跨越注意力机制也有所区别。
2.2 模型精调
(1)分类任务。对于分类任务,UniLM的精调方式与BERT类似。这里使用双向Transformer编码器(M=0),并以输入序列的第一个标记[BOS]处的最后一层隐含层表示作为文本的表示,输入至目标分类器,再利用目标任务的标注数据精调模型参数。
(2)生成任务。对于生成任务,随机采样目标文本片段中的单词并替换为[MASK]标记,精调过程的学习目标是恢复这些被替换的词。值得注意的是,输入序列尾部的[EOS]标记也会被随机替换,从而让模型学习什么时候停止生成。