重磅推荐专栏: 《Transformers自然语言处理系列教程》
手把手带你深入实践Transformers,轻松构建属于自己的NLP智能应用!
可不可以先 点击下方链接,求赞 点击 like ❥(^_-) 一下我的 Model 和 Space,再看后面的正文~~:
Model 、 Space
………………………………………………………………
近年来,图像生成技术发展迅速,越来越多的人开始关注和探索各种图像生成模型。而 Diffusion Model 作为其中的一种,其在生成高质量图像方面具有重要意义。在本次分享中,我们将探讨 Diffusion Model 的原理和实现方式。希望本次分享能够帮助大家更深入地了解这一领域的技术和方法,以及启发您进一步探索和研究。
1. 什么是 Diffusion Model,它是如何生成图像的?
在介绍 Diffusion Model 之前,我们先来了解一下生成模型。通俗来说,生成模型是一种人工智能算法,其基本思想是让计算机自动学习一些数据的统计规律,并利用这些规律生成新的数据,比如图像、音频等。这种技术的应用非常广泛,比如可以用于文本生成、图像生成、视频生成等领域。
而 Diffusion Model 是一种比较新的图像生成模型,其最大的特点就是可以生成高质量的图像。它的生成原理非常有趣,实际上,Diffusion Model 是一种基于去噪技术的图像生成 Denoise Model。这就意味着,在生成图像的过程中,它实际上是在不断地去除噪声和随机性的影响,从而逐渐得到一个越来越真实、越来越精细的图像。
1.1 Diffusion Model 原理

- 首先,Denoise Model 需要一个起始的噪声图像作为输入。这个噪声图像可以是完全随机的,也可以是一些特定的模式(如 高斯分布)或者形状。
- 接下来,随着 denoise 的不断进行,图像的细节信息会逐渐浮现出来。这个过程有点像冲洗照片,每次冲洗都会逐渐浮现出照片中的细节和色彩。denoise 的次数越多,生成的图像就越清晰、越细腻。
- 最后,Denoise Model 会根据用户的需求输出最终的图像。

Denoise 过程中,用的都是同一个 Denoise Model。为了让 Diffusion Model 知道当前是在哪个 Step 输入的图片,实际操作过程中会把 Step 数字作为输入传递给模型。这样,模型就能够根据当前的 Step 来判断图像的噪声程度,从而进行更加精细的去噪操作。
1.2 Denoise Model 的内部

实际上,Denoise Model 内部做了一些非常有趣的事情来生成高质量的图像。
首先,由于让模型直接预测出去噪后的图片是比较困难的事情,所以 Denoise Model 做了两件事情:
- 首先,它会把噪音图片和当前的 Step 一起输入到一个叫做 Noise Predicter 的模块中,这个模块会预测出当前图片的噪音。
- 接下来,模型会对初步的去噪图片进行修正,以达到去噪效果。具体来说,模型会通过像素值减去噪音的方式来进一步去除噪音。
1.3 如何训练 Noise Predictor?

要训练 Noise Predictor,我们需要有 Ground truth 的噪音作为 label 进行有监督的学习。那么,各个 Step 的 Ground truth 从哪里来呢?

我们可以通过随机产生噪音的方式来模拟扩散过程(Diffusion Process)。具体来说,我们从原始图像开始,不断地加入随机噪音,得到一系列加噪后的图像。这些加噪后的图像和当前的 Step 就是 Denoise Model 的输入,而加入的噪音则是 Ground truth。我们可以用这些 Ground truth 数据来训练 Noise Predictor,以便它能够更好地预测出当前图像的噪音。
1.4 Text-to-Image
有些同学问了:我见到的 Diffusion Model是Text-to-image Generator,基于文本生成图片。为什么你这个没有文本的输入呢?

确实,有些 Diffusion Model 是基于文本生成图片的,这意味着我们可以将文本作为输入来生成图片。

每一个 step,文本都可以作为 Denoise Model 的输入,这样可以让模型知道当前应该生成什么样的图片。


具体来说,我们可以将文本输入到 Noise Predictor 中,以便预测出噪音来去噪。
2. Stable Diffusion、DALL-E、Imagen 背后共同的套路是什么?

Stable Diffusion、DALL-E、Imagen 这些模型的共同之处在于它们都使用了三个模块来生成图像:
- 首先,通过 Text Encoder 模块,将输入的文本编码成为一个表征向量。
- 然后, Generation Model 模块会利用这个表征向量生成一个图像表征向量,可以把它看作是图像的压缩版本。
- 最后,通过 Decoder 模块,将这个图像表征向量解码为一张清晰的图像。
2.1 Stable Diffusion

Stable Diffusion 是一个比较热门的开源 Diffusion Model,它的架构如上图所示。
- 它的 Encoder 输入可以不仅仅是文本,还可以是图像等条件。
- 它的 Generation Model 使用的是 Denoising U-Net,引入了交叉注意力机制(cross attention),以加入多模态的条件。
- 同时,它还使用了预训练的通用 VAE,将输入的图片压缩到潜空间(latent space),然后再进行扩散过程。
2.2 DALL-E

DALL-E是由OpenAI发布的一种Diffusion Model,它的架构如上图所示。
它利用CLIP方法得到文本和图像的表征向量。CLIP objective是一种对比学习方法,通过训练模型使其同时理解文本和图像,以便将文本描述和对应的图像紧密联系起来。在训练过程中,模型会从数据集中随机选择一个文本描述和对应的图片作为正样本,随机选择另一个文本描述和不属于该文本描述的图片作为负样本。模型的目标是使正样本的相似度高于负样本的相似度。
DALL-E利用CLIP objective实现了文本和图像之间的交互,即给定一个文本描述,DALL-E可以生成与该描述相符合的图像。具体而言,DALL-E的生成过程如下:
- 首先将给定的文本描述编码成文本表征向量
- 然后将该向量输入到DALL-E的生成模型(prior 模块)中,生成一个图像表征向量。
- 最后,将该图像表征向量输入到DALL-E的解码器中,生成最终的图像。
DALL-E的生成模型有两种实现方式:
- 第一种是利用Autoregressive模型(例如GPT),输入文本表征,生成图像表征向量降维(如PCA)后的表征
- 第二种是利用Diffusion,输入文本表征,生成大小一致的图像表征向量。
2.3 Imagen

Imagen是Google发布的一种文本到图像生成的Diffusion Model,它可以根据给定的文本描述生成一张高清晰度的图片。整个生成过程包含三个主要模块:Frozen Text Encoder、Text-to-Image Diffusion Model和Super-Resolution Model。
- 首先,Frozen Text Encoder将输入的文本描述编码成一个Text Embedding
- 然后Text-to-Image Diffusion Model根据Text Embedding从随机噪声图开始,不断迭代产生一张与输入描述匹配的64x64小图
- 再由Super-Resolution模块根据Text Embedding放大到256x256的中等尺寸图像,最终通过另一个Super-Resolution模块根据Text Embedding产生1024x1024的高清晰度图像。
为了实现更好的生成效果,Imagen采用了一些优化措施。
-
其中,text encoder采用T5模型的encoder,测试结果表明T5-XXL效果最佳,其对应参数量为4.6B。
-
Text-to-Image Diffusion Model使用U-Net结构,并插入一些注意力层,以更好地利用文本信息。

-
而Super-Resolution模块同样使用U-Net结构,为减少显存占用、加速收敛、提升推理速度,Imagen对其进行了优化,称为Efficient U-Net。具体来说,
- Efficient U-Net采用了更多的ResNetBlock在低分辨率部分,使得模型参数量分布偏向低分辨率部分
- 同时将skip connections缩放一个系数1/sqrt(2),有助于模型更快收敛
- 并且采用了先降采样再卷积的DBlock模块和先卷积再上采样的UBlock模块,以提升模型的推理速度
3. Dreambooth 和 LoRA 是什么?它们如何教授模型新的概念?如何生成小鹏P7的图像?
现在我们有了Diffusion Model(如 开源的Stable Diffusion),可以生成与文字描述匹配的图像。那该如何教授模型新的概念,让它生成我们自己领域内的图像呢?比如我们可以输入“小鹏汽车P7”相关的文字描述,它就能生成一张符合这个描述的图片。
当然,我们可以 finetue 模型,喂给模型“小鹏汽车P7”的<image,text> pair 训练数据。但是直接微调大模型可能有两个问题:
- 过度拟合。因为我们的训练数据集非常小,直接用这个模型可能会过于专注于输入图像的主体上下文和外观,而且可能会将训练图像的一些特定姿势或背景等特征过度拟合到生成的图像中,导致生成的图像看起来不自然、失去多样性。如下图第二行,狗的姿势被固定了,趴在一个东西上。

- 语言漂移。因为Diffusion模型是基于大量语料库训练的,但在生成具体领域的图像时需要特定的领域知识,如果直接微调大模型可能会导致模型失去特定于领域的先验知识。具体来说,由于文本提示同时包含 [identifier](如“小鹏汽车P7”) 和 [class noun](“汽车”),当扩散模型在进行微调时,我们观察到它会慢慢忘记如何生成同一类的主题并逐渐忘记特定于class的先验知识,并且不能生成相关类的不同实例(即 所有的“汽车” 可能都变成了 “小鹏汽车P7”)。

如上图第二行显示了在特定的“XX狗” 图像上对模型进行微调后生成的“狗”图像的一些示例。结果清楚地表明,这个模型由于这次的微调失去了生成一般的狗图像的能力
3.1 Dreambooth:学了新的,不忘了旧的

我们有了一种文本到图像的扩散模型,可以根据输入的文本生成相应的图像。但是,如果我们只有三到五张特定对象的图片,我们可以通过给模型输入这些图片的同时,加上一个包含特定对象的名称和类别的文本提示来微调模型,例如“一只[V]狗”。同时,我们还可以应用一种特定于类别的先验保护损失(a class-specific prior preservation loss),它利用模型对该类别的语义先验,并鼓励模型生成多样的属于该类别的实例,例如在文本提示中输入“一只狗”。这样可以让模型更好地生成与特定对象相似的图像。
3.2 LoRA:不想训练大模型?加个旁路
如果我们不想给大模型做 “大手术”—— finetue 训练大模型(成本太高了 ==),毕竟我们只是仅仅想教授模型一个新的概念,其他预训练的先验知识都不用变动。那应该如何做到呢?
可以尝试LoRA(Low-Rank Adaptation)!LoRA是一种低秩适应方法,可以用于神经网络的微调和适应。其主要原理是,在微调神经网络时,只优化低秩分解矩阵,而保持预训练的权重不变。具体来说,LoRA 允许我们通过优化自适应期间密集层(dense layers)变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预训练的权重冻结:

如上图所示,我们只训练A和B部分的参数,其中,r 远小于 d。A 部分参数初始化符合高斯分布。为了让训练最初输出的 h 的值 和 预训练大模型输出相同,B部分 参数的初始化为0。
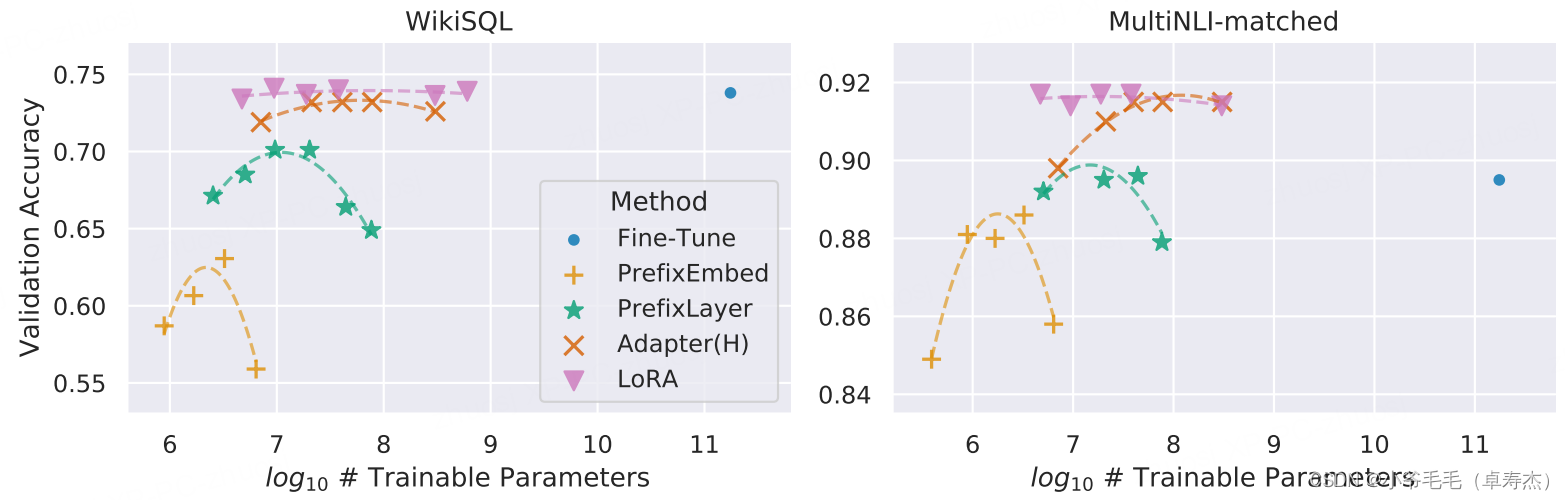
上图为GPT-3 175B 验证精度与 WikiSQL 和 MNLI 匹配上的几种自适应方法的可训练参数数量的关系。 LoRA 表现出更好的可扩展性和任务性能。使用LoRA,175B 的 GPT-3 只需 18M Trainable Parameters就能有很好的表现了。
总的来说,LoRA具有以下优点:
- 可以共享预训练模型并用于构建许多不同任务的小型LoRA模块。通过冻结共享模型,我们可以通过替换上图中的矩阵A和B来高效地切换任务,从而大大降低存储要求和任务切换开销。
- LoRA使得训练更加高效,并且可以降低硬件要求,使得使用自适应优化器时,计算梯度或维护优化器状态的大部分参数不再需要。相反,LoRA仅优化注入的、更小的低秩矩阵,从而使得训练更加高效。
- LoRA的简单的**“旁路”线性设计使得我们可以在部署时将可训练的矩阵与冻结的权重合并**,(相比“串联”的添加额外模块)不会引入推理延迟。
- LoRA与许多先前的模型训练方法无缝对接,如prefix-tuning等。
3.3 小 Demo
3.3.1 小鹏P7
我们尝试利用十几张 “小鹏P7汽车” 相关的图像样本,基于开源的中文Stable-Diffusion(IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese) 基础上进行了(Dreambooth + LoRA)微调,Trainable 模型文件大小只有 3M。
我们把 prompt 设置为:小鹏P7汽车,蓝天,草地,4K照片,高清
来分别看下开源的中文Stable-Diffusion 以及其经过训练后的效果:
- IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese:

- IDEA-CCNL/Taiyi-Stable-Diffusion-Chinese + Dreambooth + LoRA:

可以对比发现:
- 经过微调的模型,基本上能够学到 “小鹏P7汽车” 的车身外形,虽然看起来有点变形 ==
- 由于prompt没有明确车身颜色,模型泛化出了 “小鹏P7汽车” 实际上不存在的颜色,如微调后生成的第3、第4张图。
- 在细节方面,模型学习的了小鹏汽车的车标“X”,但是车牌上的数字学不到,如微调后生成的第3张图。可能的原因是:
- 训练数据的每张图片车牌内容不一样,模型比较难学
- 看到微调前生成图像车牌也是模糊的,所以才可能是隐私的缘故,预训练大模型的训练数据中的车牌可能就已经做了去隐私处理了。
3.3.2 宝可梦
最后再安利一下最开始的可爱的宝可梦demo:
Model 、 Space
求赞:
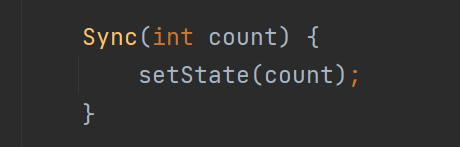
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1", torch_dtype=torch.float16)
model_path = "souljoy/sd-pokemon-model-lora-zh"
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
pipe.safety_checker = lambda images, clip_input: (images, False)
prompt = "粉色的蝴蝶,小精灵,卡通"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image
prompt = "可爱的狗,小精灵,卡通"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image
prompt = "漂亮的猫,小精灵,卡通"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image



![深度学习基础入门篇[七]:常用归一化算法、层次归一化算法、归一化和标准化区别于联系、应用案例场景分析。](https://img-blog.csdnimg.cn/img_convert/1a5a92c378832c41ea3aefb989a5247e.png)