项目完整地址:
可以先看一下Bert的介绍。
Bert简单介绍
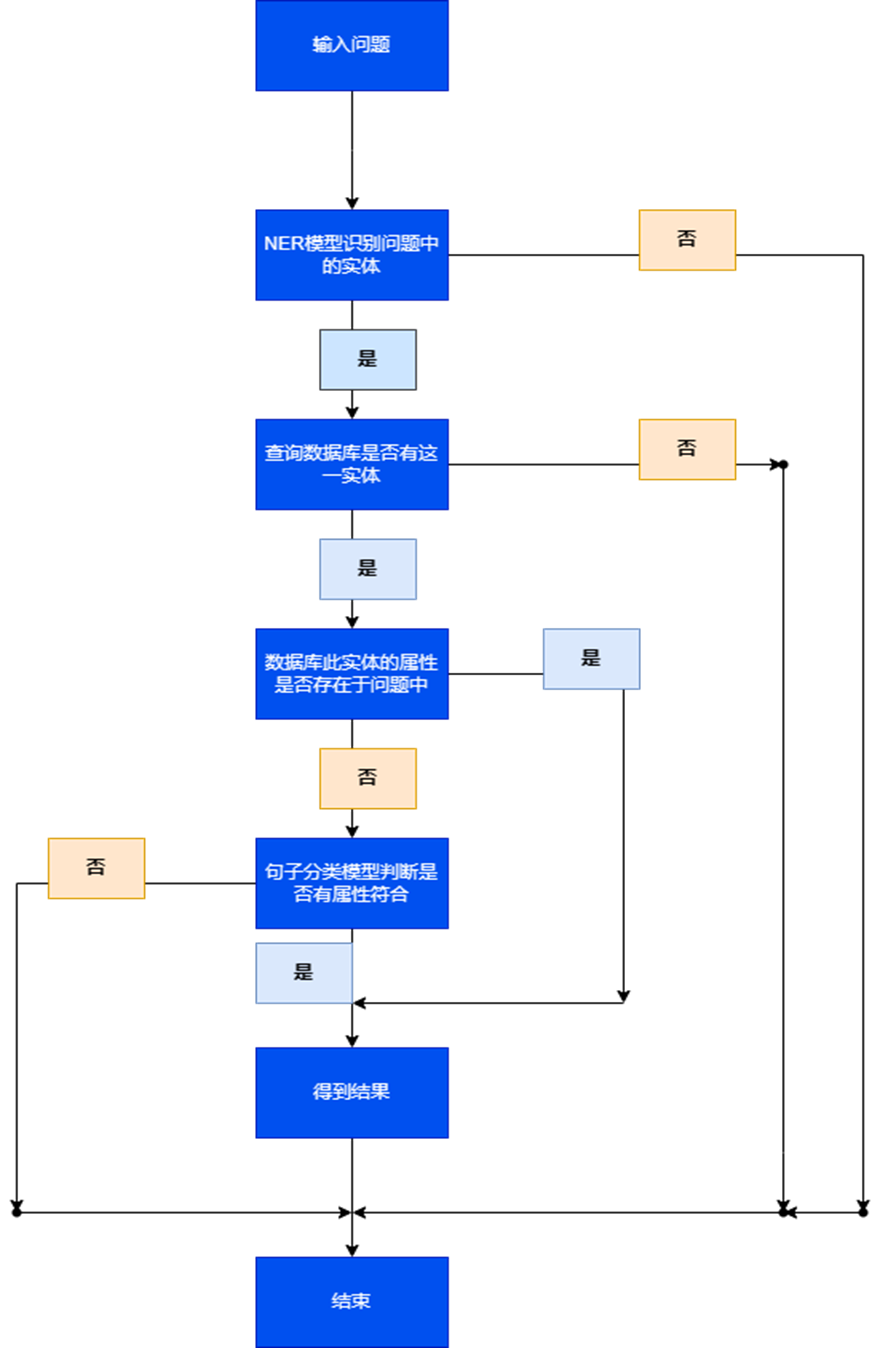
一.系统流程介绍。
-
知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说都具有三元组,例如“苏琳的性别是男”。在这个句子中,第一个实体是苏琳,第二个实体是男,实体关系(属性)就是性别。在这样的系统中,知识库起到了至关重要的作用。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在此基于知识库的智能问答系统中,对于一个问题,需要提取出来的有两部分内容,一是实体,二是实体关系。确定实体和实体关系之后,系统才能够通过知识库找到对应的答案。因此,在构建这样的系统时,首先需要搭建知识库数据库,将数据中的每一个知识点分别归纳出实体、实体关系和答案。一个知识点对应一行数据,接着将这些数据存储进mysql数据库中,如图:

-
接下来是训练模型,一共需要训练两个,一个是Bert-Crf模型,用于识别问题中的第一个实体。。在问答系统中,识别问题中的实体是非常关键的一步,因为它是回答问题所必须的基本信息。举例来说,对于“苏琳的性别是男”这个问题,Bert-Crf模型可以识别出“苏琳”这个实体。
-
一般来说,回答一个问题需要三个要素:实体、实体关系和答案。但为了更快速地找到答案,在这里可以直接使用实体进行数据库查询。如果数据库中有关于这个实体的信息,就可以判断数据库中对应的属性是否存在于问题中。如果存在,就可以直接返回数据库中的答案,以此来简化整个问题回答的过程。
-
以“苏琳”这个实体为例,如果在数据库中有对应的属性“性别”,并且问题中也提到了“性别”一词,那么就可以直接返回数据库中“性别”对应的答案“男”。这样,通过Bert-Crf模型和数据库的配合使用,可以快速准确地回答问题,提高问答系统的效率和精度。
-
然而,实际上问题的复杂性可能不止于此。如果问题中涉及到多个实体,或者实体之间存在复杂的关系,这种简单的查询方法就不能满足需求了。此时,需要更加复杂的问答系统来处理这些问题。例如数据库中关于实体的数据的实体关系并不存在于问题中,这时候我们就需要利用第二个模型,即BertForSequenceClassification模型。
-
利用预训练的 BERT模型来实现自然语言理解和问答,同时将知识库和问答系统进行整合,从而能够对用户提出的问题进行准确、高效的回答。该系统通过将问题和知识库中的实体和关系进行匹配,从而找到最佳答案。具体来说,本系统先将三个属性:实体(问题),实体关系(实体属性),实体(答案)存储进 mysql 数据库。当提出问题时,用 BertCrf模型来识别出问题中所包含的实体,识别出实体之后就可以进行数据库的查询;识别出实体后就需要进行实体与属性的连接,利用BertForSequenceClassification模型进行连接,连接完成后查询数据库得到答案并将结果返回。
流程图如下:
结果展示如下:

二.处理数据。
1.数据集介绍。
NLPCC(Natural Language Processing and Chinese Computing)是中国计算机学会主办的一个自然语言处理和中文计算会议,旨在促进中文自然语言处理领域的交流和发展。该会议自2002年开始举办,每年一届,通常在中国境内的某个城市举行。NLPCC已成为中国自然语言处理领域的重要学术盛会之一,吸引了众多国内外专家学者参与。该会议每年还会颁发最佳论文奖、最佳学生论文奖等奖项,以鼓励和表彰优秀的研究成果和研究人员。源数据集所在网址如下 :
源数据集
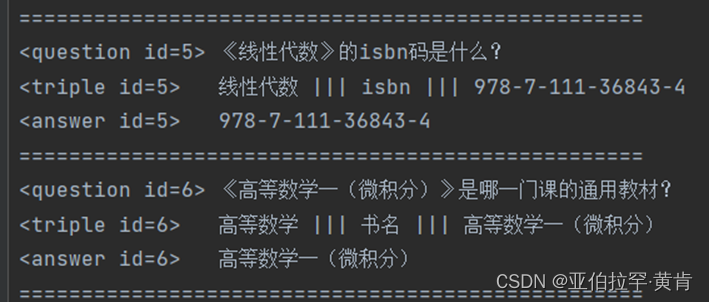
在本项目中,所使用的数据集是经过预处理的三元组数据。这些三元组数据包含了实体之间的关系和属性信息:
预处理过的数据集
其中包含了两个文件:一个是nlpcc-iccpol-2016.kbqa.training-data,另一个是nlpcc-iccpol-2016.kbqa.testing-data。分别是训练数据和测试数据。
内容如下:
2.切分数据。
- training-data样本数量为14609,testing-data样本数量为9870 。将文件重新切分一下,划分为train.txt,test.txt,dev.txt三个文件。划分如下:(运行 1_split_data.py )
- 将nlpcc-iccpol-2016.kbqa.testing-data 中的对半分,一半变成验证集(dev.text),一半变成测试集(test.txt)。
- nlpcc-iccpol-2016.kbqa.training-data 保持不变,直接复制成为训练集 train.txt。
3.构造命名实体识别(NER)数据集 (运行2-ner-data.py)
- 常见的命名实体识别的数据集实体类型包括国籍(CONT)、教育背景(EDU)、地名(LOC)、人名(NAME)、组织名(ORG)、专业(PRO)、民族(RACE)、职称(TITLE)。因为本系统只针对nlpcc的数据集做智能问答系统,故只定义一种数据类型LOC,并且以nlqcc的数据集作为训练数据。所以需要对nlqcc的数据做进一步处理。
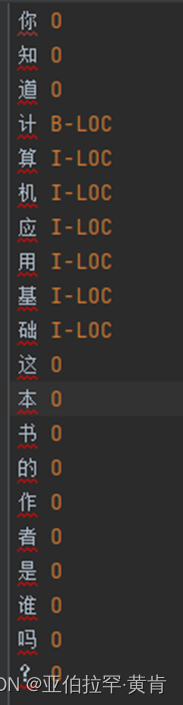
处理流程如下:首先,先检查每一行中是否包含 question 和 triple 两个字符串。虽然此系统只需要nlqcc数据集中的问题,但也需要得到问题中的实体作为标注的依据。如果发现包含这两个字符串中的一个,就将该行去除开头和结尾的空格并存储在 q_str 或 t_str 变量中。 - 当遇到 ==== 这个分隔符时,说明已经是新的一个样本了。就可以将 q_str 和 t_str 进一步处理,提取出t_str 中的所有实体,将它们存储在 entities 变量中。
- 接下来,代码将检查 entities 是否在 q_str 中出现,并将 q_str 拆分成一个字符列表 q_list,将其用空格分隔开并附加到 ner_list 后面,最后在 ner_tag_list 中附加相应的标记序列。
具体地说,代码会将实体标记为 “B-LOC”(实体的开始)和 “I-LOC”(实体的中间或结尾),并将相应的标记附加到 ner_tag_list 中。完成后,代码会将 ner_list 和 ner_tag_list 中的所有标记和字符以及空格都合并成一个字符串列表。
结果如下:
4.制作知识库。
先需要将数据的问题,实体关系,答案制作成一个csv(运行3-q-t-a-data.py)。结果如下:

接着运行4-load_dbdata.py,将数据更新到数据库上面。
5.构建属性相似度的数据
- 前文提到,如果我们输入的问题是“苏琳是男的吗?”,识别出“苏琳”这一实体后,当在数据库中查询到关于“苏琳”的数据后,因为数据库中关于“苏琳”这一数据的实体关系(属性)并不存在于问题当中,所以无法给出准确的答案,这个时候就需要利用到我们训练的第二个模型,BertForSequenceClassification模型。BertForSequenceClassification模型的作用简而言之就是判断我们提问的问题和知识库中存在的实体关系(属性)之间的关联,以此来找到准确的答案。所以数据集应该包含问题,属性,标签。
结果如下:

三.训练模型。
1. BertCrf模型(运行NER_main.py)
BertCrf模型是一个结合了BertForTokenClassification和条件随机场(CRF)的模型,用于从问题中识别实体。
调用transformers下的BertForTokenClassification来创建MLM模型,然后在模型后面再接一个crf模型。
模型训练时的数据(模仿谷歌官网Bert模型对数据的处理方式处理):
可以这么理解:
Input_ids:将输入到的词映射到模型当中的字典ID。
Attention_mask:要拿来mask的位置。在此处可以认为是判断是否有训练意义的标志。
Token_type_ids:在此处可以认为是segment_ids,因为是一个句子一个句子训练,所以都是第一个句子,都为0。
Labels_ids:文字对应的标签索引。(CRF_LABELS = [“O”, “B-LOC”, “I-LOC”])
评估结果如下:

2.BertForSequenceClassification模型(运行SIM_main.py)

模型训练时的数据(模仿谷歌官网Bert模型对数据的处理方式处理):

Input_ids:将输入到的词映射到模型当中的字典ID。
Attention_mask:要拿来mask的位置。在此处可以认为是判断是否有训练意义的标志。
Token_type_ids:在此处可以认为是属性词所在的位置,即segment_ids。
Labels:属性是否对应问题的标签。
评估结果如下:

四.搭建系统。(运行test_pro.py)
- 现在我们已经有了训练好的BertCrf模型和BertForSequenceClassification模型,分别保存为best_ner.bin和best_sim.bin,一个用于识别出问题中的实体,一个用于问题和属性相关性的判断。

参考文章:
Bert谷歌地址:https://github.com/google-research/bert
基于BERT模型的知识库问答(KBQA)系统
Pytorch: 命名实体识别: BertForTokenClassification/pytorch-crf
TensorFlow:NLP自然语言处理,通用框架BERT项目实战,唐博士带你快速入门!