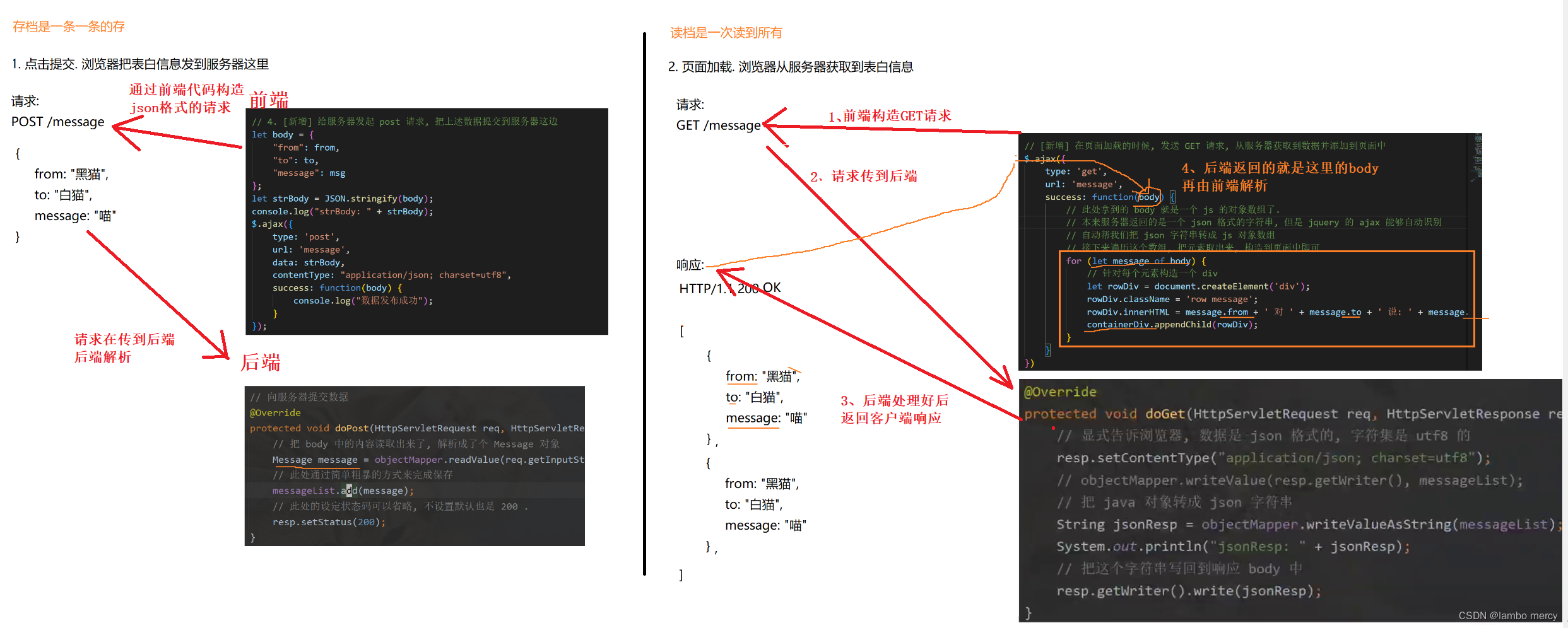
线性模型概述
模型是对现实的一种数学近似,其中给定输入变量集的某个函数旨在重建一个输出变量。以fMRI范式为例,在这个范式中,给受试者呈现面孔和房屋的图像。该模型的目标是利用体素对面孔和房屋反应时的预期时间进程,并产生与测量体素对面孔/房屋反应信号密切匹配的输出(见图1)。设Y为长度为N的向量,其中包含一个体素的时间序列数据,设X1和X2分别为面孔和房屋激活的预期时间过程。由于测量和模型并不完美,因此有一个额外的误差项向量,用来描述剩余项的可变性:
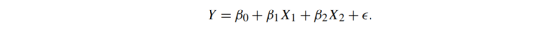
参数β0描述的是被试在没有看到面孔或房屋时(X1和X2为零)fMRI信号的基线值,而β1和β2分别描述的是面孔或房屋的激活量。最后,包含来自数据噪声的可变性以及模型未捕获到的任何未知结构可变性。图1底部图显示了拟合模型与原始数据和参数估计的匹配程度。
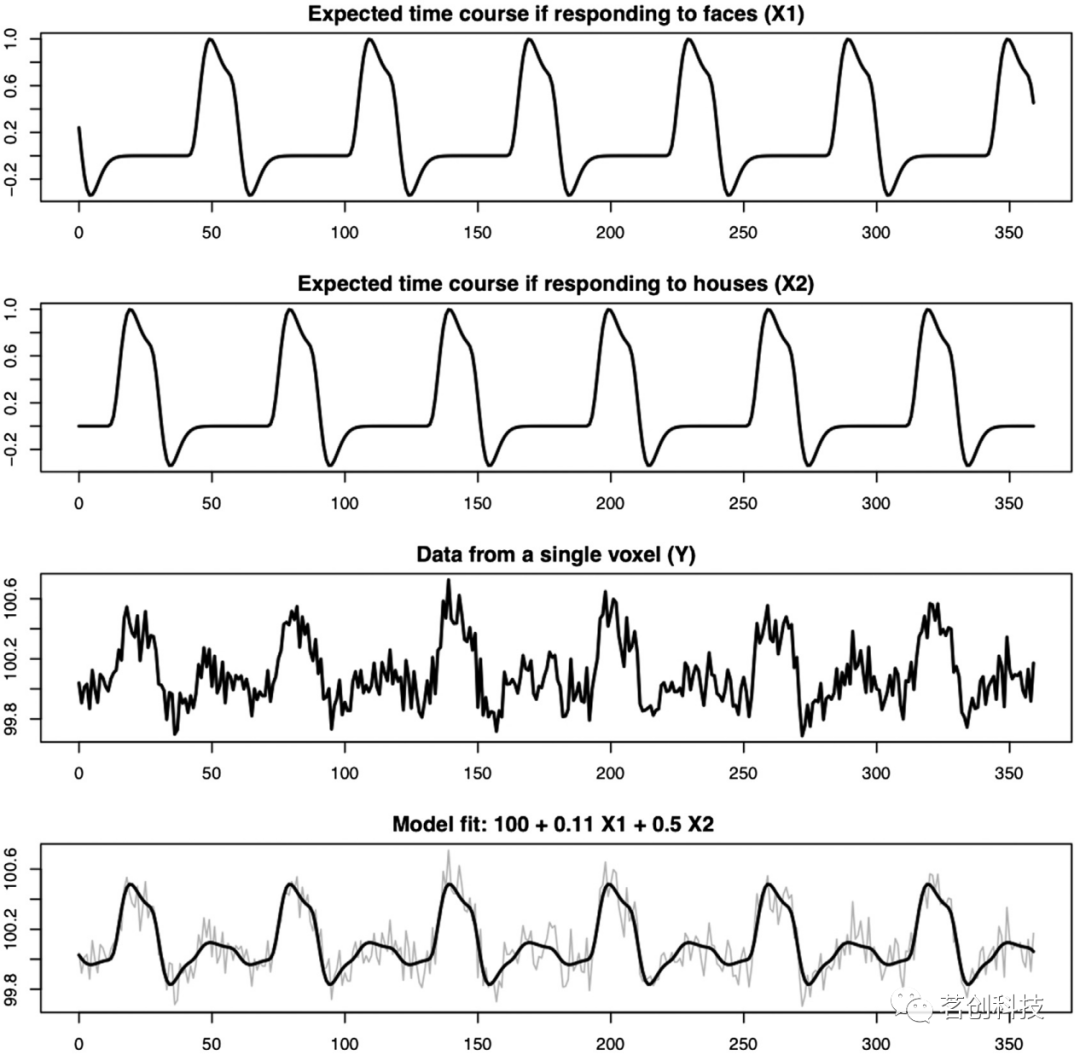
图1.BOLD建模示例。
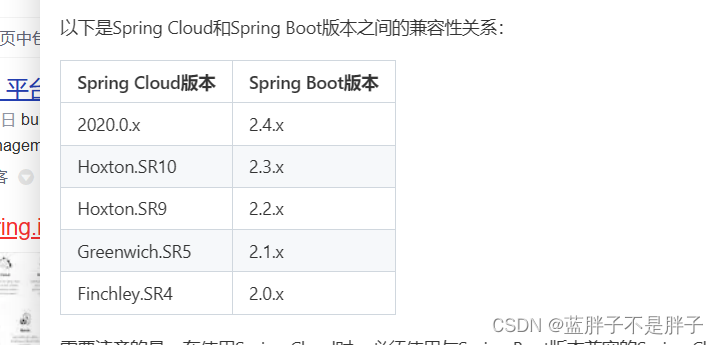
模型可以用矩阵形式表示,其中所有回归量在一个矩阵中,所有βi在一个列向量中,表示为Y=Xβ+∈,其中Y是一个长度为N的向量,X是一个维数N×p的矩阵,p是回归量的数量,β是一个长度为p的列向量,同时也是一个长度为N的向量。图2展示了fMRI任务的这些矩阵(左),以及研究分数各向异性(FA)组间差异的模型(右)。线性模型被广泛应用于神经成像分析,用于将各种大脑测量指标与不同变量关联起来,并在组间进行比较。该方法还可用于静息态fMRI数据的预处理步骤,以去除伪影。它可以直接用于预测分析,也可以扩展用于构建更高级的机器学习算法,如神经网络。接下来将讨论该模型在用于预测和解释方面的广泛差异。
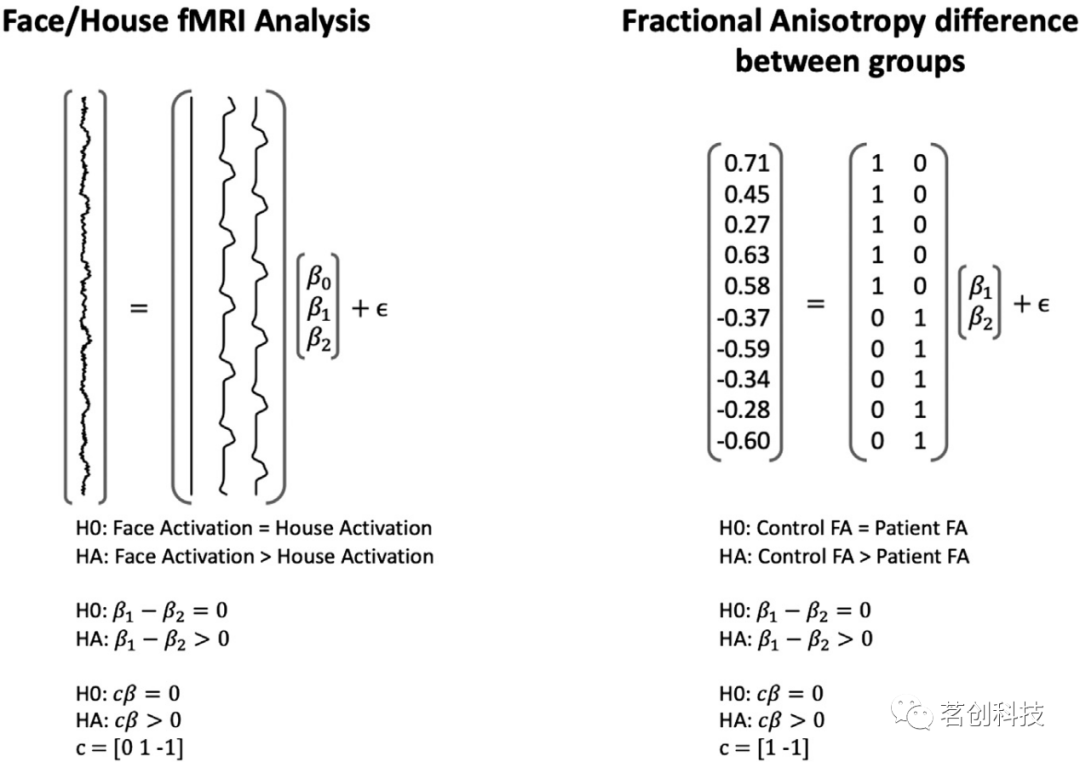
图2.两种矩阵形式的模型示例。
线性模型:预测与解释的比较
在预测模型中,X的列通常被称为特征,而模型中的回归器主要用于解释。在预测的情况下中,β内的值通常称为特征权重,在解释的情况下被称为参数估计。除了这些命名上的差异外,模型Y=Xβ+∈在预测和解释上的泛化目标也略有不同。
在进行预测时,重点在于向量β(表示为
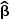
)的估计对其他数据集的泛化能力。具体来说,如果一个数据集用于估计
,那么当X和Y来自一个新的、独立的数据集时,X
与Y的实际值的匹配程度如何?重要的是,在许多情况下,特征的权重不能用来理解底层机制。例如,两个特征可能几乎相同,但特征权重的符号相反,或者一个特征的权重为0,而另一个特征的权重为非0,这并不意味着一个特征比另一个“更好”。
在解释的情况下,我们通常会对底层机制进行更详细的介绍,目的是使模型能够很好地泛化到其他数据集。但换言之,这种解释是一个可靠框架吗?β估计值可能会改变,但我们希望该模型仍然拟合良好。当为模型选择回归器时,用于估计β的方法通常会产生推断统计量,可用于评估β内的每个参数以及参数的线性组合。回归器的选择在避免所谓的共线性时起作用,共线性将在下文进行讨论。共线性可能会使解释变得困难,但并不妨碍预测。
线性模型的参数估计
无论目标是预测还是解释,都需要对向量β进行估计。首先,假设β的长度p比观测值数量N要小得多。一般来说,这是需要解释的,尽管预测通常使用正则化估计方法,可以处理p>N的情况。对β的估计,用
表示,目的是用于求出Y的估计值,=X,即接近Y的实际值。如何定义“接近”?最典型的方法是最小二乘估计,通过实际值与其估计值之间的差的平方和来衡量接近程度,(Y−)T (Y−),其中T是矩阵转置,也可以不用矩阵来表示。假设β的长度为2,将有:

假设N<p,且X的其他列不能通过线性组合重建出X的单个列,那么可以表明该估计由,
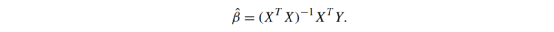
向量

的估计协方差为
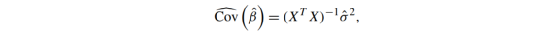
其中

2是残差向量的估计方差,由下式得到

偏差与方差
最小二乘估计是无偏的,这意味着如果你重复许多研究并在每个研究中估计β,那么均值将等于真实值。此外,该估计在所有无偏估计中具有最小的方差,这是指在重复研究中估计值的变异性。可能是不同的估计器产生了方差更小的有偏估计,但为什么要使估计有偏差呢?这是解释和预测之间的另一个区别。方差会影响预测效果,因此某些特征权重会产生偏差,通常将其缩小或设置为0来提高预测效果。另一方面,有偏的参数估计可能会干扰解释。一般来说,解释模型坚持在无偏估计的范畴内,通过避免共线性和需要比参数更多的样本(N>p)来避免解释中的潜在问题。预测模型通常具有N<P和平衡偏差和方差,以改进使用正则化估计器而不是最小二乘法的样本外预测。
共线性
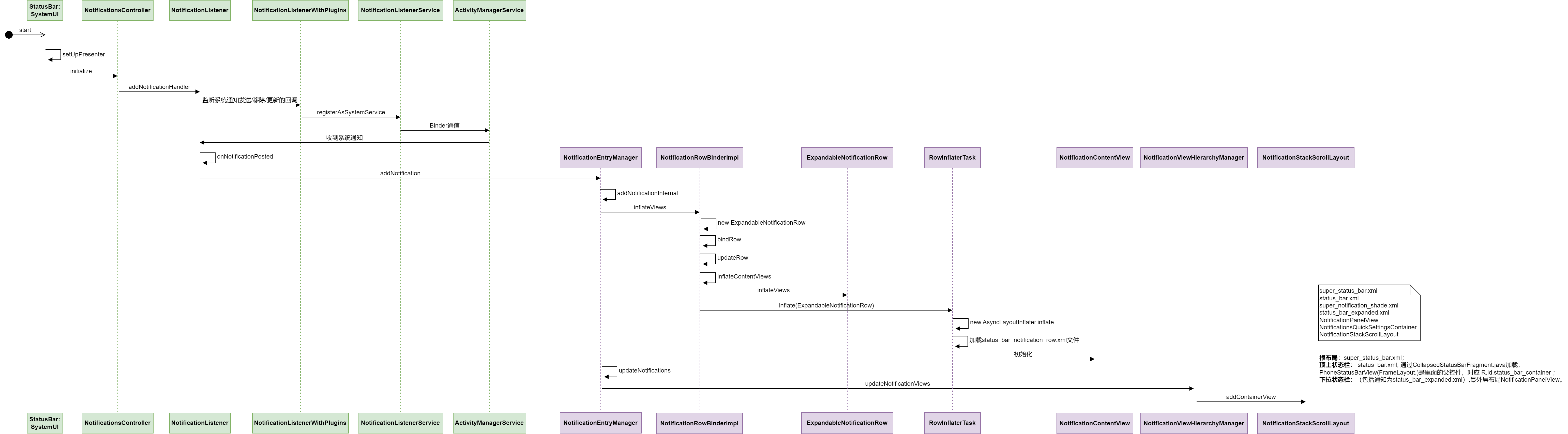
当回归量高度相关时,估计参数的方差会相当大,这在解释模型中尤其成问题,需要避免,而在预测模型中的问题较小。接下来将通过一个简单的例子来说明。假设我们有10个受试者,并且有两个高度相关的体素和年龄的灰质密度测量值。在解释情况下,目标是了解这些体素与年龄之间的关系,而对于预测,我们想测试是否可以通过这些体素的灰质密度准确地预测年龄。在这两种情况下,感兴趣的模型为:Age=β0+β1GM1+β2GM2+∈(图3)。使用最小二乘估计,得到各参数的估计值为
0=−36.59,1=−5.82和2=7.59,均与0有统计学差异。这些体素几乎完全相同(相关性=0.98),那么它们与年龄的真实关系怎么会如此不同呢(符号相反)?高度共线性导致了估计参数的高度变异性,而这些对解释几乎没有用处。由于共线性存在时缺乏可解释性,因此在解释模型设置中应该避免共线性。在这种情况下,研究人员应该选择一个体素,或创建两个体素的汇总度量以在模型中使用。
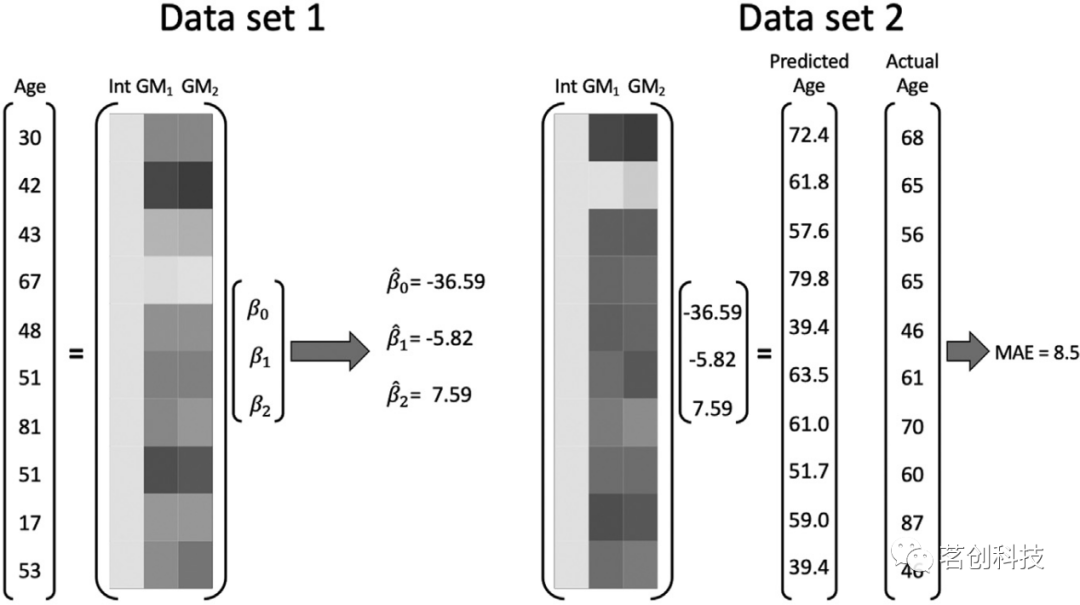
图3.共线性对解释和预测的影响。
与解释相关的主题
解释性分析通常用于检验涉及模型参数的统计假设。假设检验有两部分:①零假设或H0;②备择假设或HA。图2列出了两个模型和每个模型的假设。第二个模型的目标是发现对照组是否比患者有更大的FA,使HA:β1>β2和H0:β1=β2。可以使用以下推论步骤来检验这一假设。
对比度估计
 推断
推断

此外,p值经常被误解。我们假设零假设为真,然后计算在零分布下观测到统计量的概率或者比它更极端的概率。注意,“更极端”指的是备择假设的方向。最常用的阈值是p=0.05。这个阈值的含义是,如果我们的数据中没有任何真正的信号,那么做出这一结论犯错误的概率为5%(假阳性)。
在神经影像学中,大多数假设检验都是单侧的。在所有标准统计软件中,默认p值反映的是双侧检验,用于检验效应是与0存在显著差异。双侧p值通常是前者的两倍大,因此,单侧检验应该在有强有力的证据表明效应是在某个方向上的情况下使用。用两个单侧检验代替一个双侧检验是一种不好的做法,因为这会增加假阳性率,稍后将讨论这个问题。尽管在神经影像学中经常会忽视这一问题,但有必要改变这种做法,要么默认运行双侧检验,要么在运行两个单侧检验时进行适当调整。
多重比较
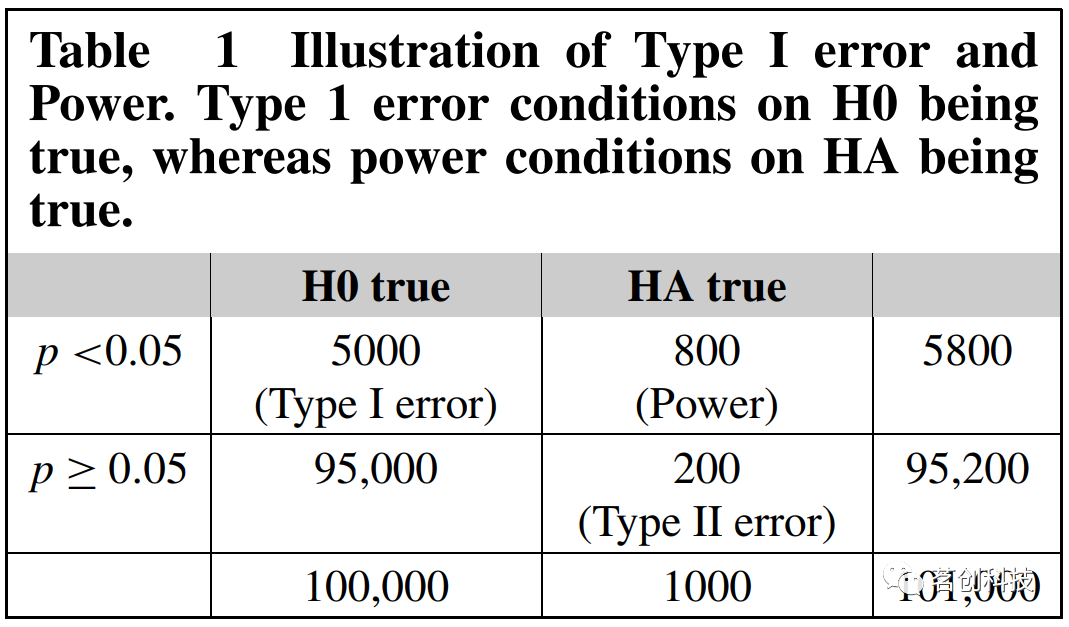
假设你要分析101000个体素,其中100000个体素不包含信号,而1000个体素包含信号(表1)。假设体素是独立的,p值临界值为0.05意味着将有5000个假阳性或I类错误。而事实上,我们的体素并不是独立的,所以这种假阳性通常很容易被解释为真实的效应。为了解决这个问题,可以采用控制错误率的方法。虽然Bonferroni校正是一种控制I类错误的著名方法;但它假设所有检验都是独立的,这对于成像数据来说过于保守。相反,我们通常专注于基于聚类的统计数据,并校正这些统计数据的错误率。
表1
功效

有效性
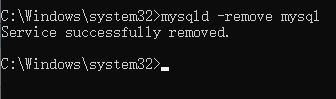
如前所述,由于参数估计的高变异性,共线性会干扰解释模型的解释。在fMRI分析中,大多数时间进程数据的回归量在数据收集之前就已经知道了,因为它们主要依赖于任务设计的参数,例如刺激的时间和顺序。在fMRI研究中测量的BOLD信号与实际的神经信号相比是延迟的,因为我们测量的是血氧变化。如果刺激不随时间间隔开来,这通常会导致模型中的共线性。例如,在一个项目识别任务中,首先向被试呈现一组字母,例如{a,T,E,M} (目标刺激),然后在短暂的停顿后向其呈现一个字母,例如T,并且要求他们判断这个字母是否包含在前面的集合中(探测刺激),以“是”或“否”来回答。在这个示例中,“是”/“否”响应和正确性将被忽略。为了分别研究目标刺激和探测刺激诱发的大脑过程,需要为任务的每个目标和探测部分分别使用单独的回归器。如图4所示,如果目标和探测之间的时间很短,回归量的相关性越强。t统计量分母(公式6)的倒数c(XTX)-1cT称为有效性,可用于对设计进行排名。在图4的两种设计中,第二种设计的目标或探测的对比度估计效率是第一种设计的1.97倍,这表明使用第一种设计的对比度的方差估计将增大1.97倍!有效性并没有一个特定的阈值,因为它只是一个相对的衡量标准,可以用来对一组研究设计进行排名。此外,在fMRI研究前进行行为试验是很重要的,以确保任何发现的行为效应不会因为刺激间隔而受到影响。
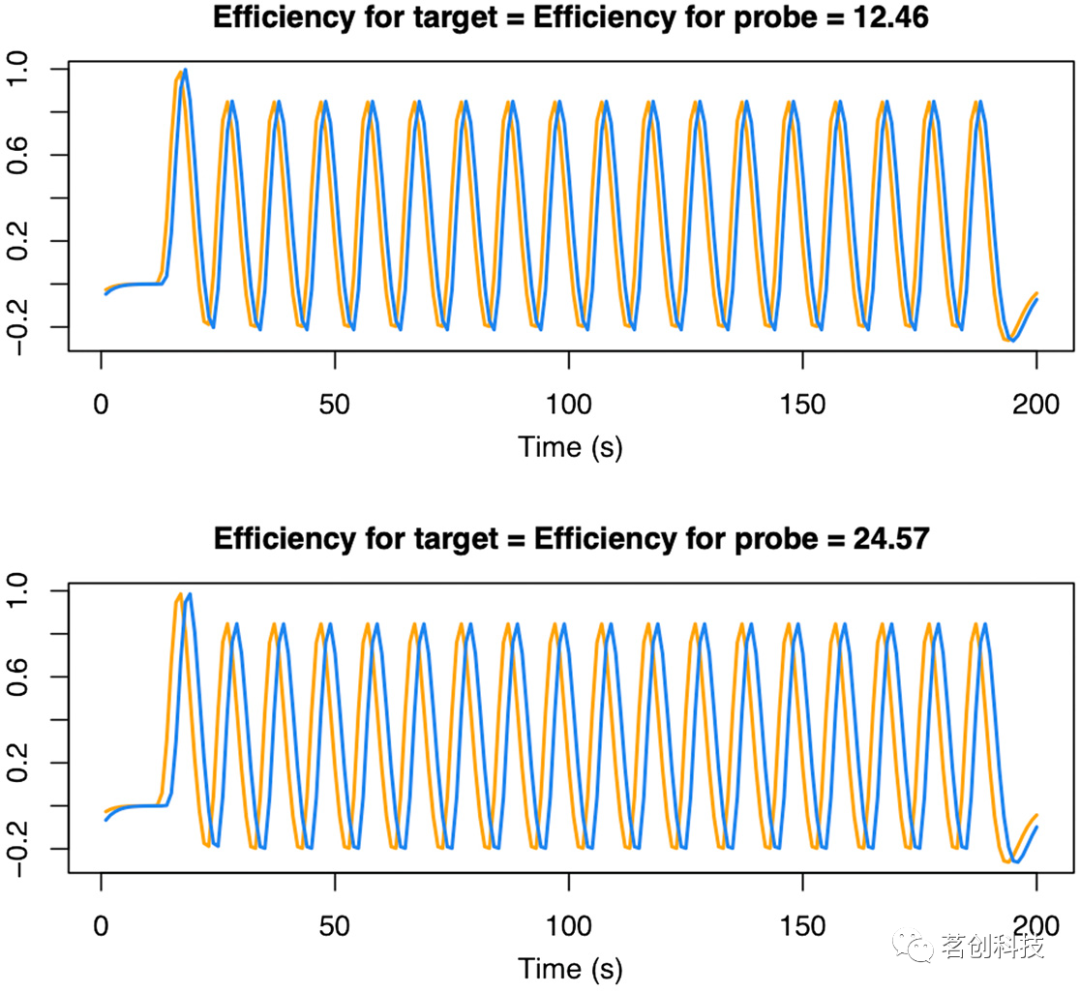
图4.项目识别fMRI任务的回归量,由目标(橙色)和探测(蓝色)组成。
避免共线性的一种方法是使用共线性评估工具——方差膨胀因子(VIF)。它为模型中的每个参数提供了一个VIF,目标是所有VIF都小于5。图4中两种设计的参数VIFs均小于5(顶部模型的各参数VIF为2.28,底部模型的VIF为1.56)。VIF可以确保避免共线性,有效性可以进一步细化模型选择,从而进一步降低方差。
与预测相关的主题
虽然很少直接使用线性回归模型进行预测分析,但大多数预测模型都可以看作是该模型的扩展。此外,必须结合交叉验证来估计预测性能。
交叉验证
预测的目标是测试
估计对新数据的泛化能力。具体来说,如果使用数据集Ytrain、Xtrain来估计train,那么在数据集Ytest、Xtest上,Ytest与Xtesttrain的接近程度如何?图3对此进行了说明。相反,如果将Ytrain与Xtraintrain进行比较,则预测能力将被高估。这是因为模型总是会在一定程度上拟合数据中的噪声,因此Ytrain与Xtraintrain的比较将反映重建信号和噪声的能力,而独立的数据集将反映重建信号的能力。例如,如果使用数据集1(图3)来估计β和检验预测能力,则MAE为3.95,远小于样本外预测的MAE(8.5)。
仍然可以使用交叉验证来获得单个样本中所有观测值的预测。它首先将数据分成10个大小相同的块。这将用于10折交叉验证。如果数据集有200个被试,可以将数据随机分成10组,每组20个,执行如下步骤:
①将第一组20名被试作为测试数据,其他180名被试作为训练数据。
②将模型对180个训练样本进行拟合,得到
train。
③使用Xtest
train对测试数据进行预测,并存储这些值以供后续使用。
④将其他组的20名被试作为测试数据,重复步骤①-③九次以上。
⑤将所有200个预测值与真实值进行比较,以评估准确性。
测试数据和训练数据必须是独立的,否则准确性将会被夸大。通常选择5折或10折交叉验证,但最佳选择取决于数据中的样本数量,因为更大的训练集应该产生更好的参数估计。
正则化
通常,人们不会使用标准的线性回归进行预测,因为特征通常比观测值更多。这通常被称为“宽数据”,因为设计矩阵X的宽度大于其高度。正则化的思想可以追溯到之前提到的偏差-方差权衡。尽管无偏参数估计听起来很有吸引力,但它们可能导致高度可变的预测。正则化分别关注偏差和方差,允许两者达到某种平衡,与最小二乘估计相比,最终减少了总体预测误差。Lasso回归是一种常用的L1正则化回归模型。另一种常用的正则化策略称为“L2”,L2是逐渐地缩小所有特征权重,而不是严格地缩小到0。岭回归是该策略中最著名的一种方法。此时参数估计的可解释性更强,但赋予不同特征重要性仍然是有风险的。即使使用最小二乘回归,回归量也会协同变化。
更高级的预测模型
最简单的机器学习方法依赖于人工干预,输入可以很好预测的、有意义的特征。例如,如果试图将视网膜图像分类为健康或疾病,可能需要首先对图像进行处理,以开发有意义的特征,如病变数量。深度学习方法的不同之处在于,算法接管了创建更有意义的特征以改善预测工作。尽管这些方法似乎与线性回归相去甚远,但线性回归和简单的神经网络之间存在联系,这可以与更现代的深度学习方法联系起来。
假设一名墙面专家、水管工和电工一起装修房屋,一般的想法是将每个工人在房屋上花费的时间与装修质量(RQ)联系起来。在这种情况下,模型为RQ=β1tdw+β2telec+β3tplumb+∈。图5左图给出了该模型的描述,反映了一个标准的线性回归模型。实际上,这些工人在房屋上花费的时间和最终的装修质量取决于他们在不同类型的房间上共同工作的时间,然后,整体的装修质量可以更好地解释为每个房间类型的集体努力的函数。假设,对于每一所房子,电工的时间将以相同的方式分配到所有房子的不同房间类型上,还假设所有房子在每种类型的房间数量方面都是相似的。那么,花费的时间和装修质量之间的真实关系可能更接近图5的右图。这是一个简单的、具有一个隐藏层的线性前馈神经网络。这个单一的隐藏层包含两个节点或神经元,它们实际上是新的和改进的特征。虽然其中指定了节点和层的数量,但没有指定节点代表什么。它们将在评估过程中确定,可能没有直观的含义,例如房间类型。无论哪种方式,这一层中的每个节点都由每个工人的部分时间的加权和组成。例如,l1=β11tdw+β12telec+β13tplumb,这看起来很像一个更大的线性模型中的线性模型。这种线性关系之外的一个复杂层次是允许每个节点都存在非线性。例如,l1=f1(β11tdw+β12telec+β13tplumb),其中f1是某个非线性函数,其取值范围在0和1之间。通常还包括偏差项,通过添加一个常数来进一步控制每个节点的贡献,即l1=f1(β11tdw+β12telec+β13tplumb+β10)。该模型涉及的参数数量非常多,模型估计比最小二乘回归更复杂。
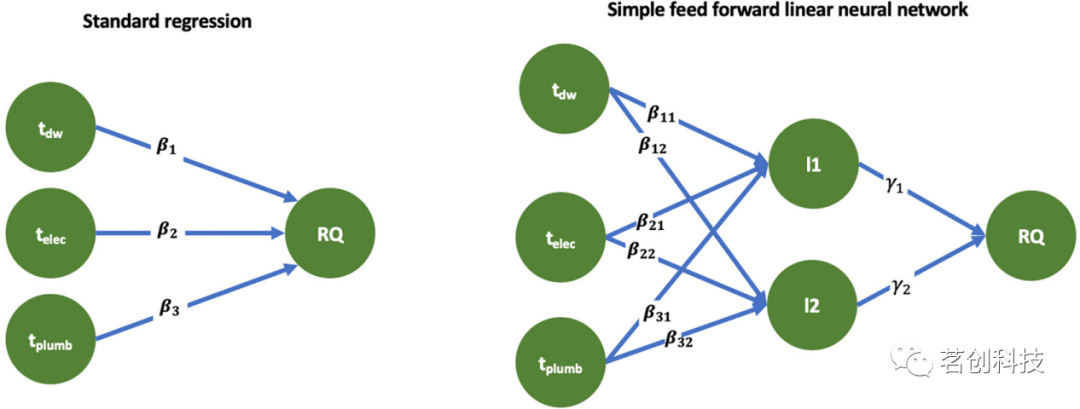
图5.左图以图形的形式说明了一个简单的线性回归模型。右图是一个简单的前馈线性神经网络,其中一层由两个节点组成。
参考文献(上下滑动查看):
Bausell, R., Li, Y.F., 2002. Power Analysis for Experimental Research: A Practical Guide for the Biological, Medical and Social Sciences. Cambridge University Press.
Eklund, A., Nichols, T., Knutsson, H., 2016. Cluster failure: why fmri inferences for spatial extent have inflated false-positive rates. Proceedings of the National Academy of Sciences 114, E4929. https://doi.org/10.1073/pnas.1602413113.
Hastie, T., Tibshirani, R., Friedman, J., 2001. The Elements of Statistical Learning: Data Mining, Inference and Prediction. Springer Series in Statistics.
Kao, M.H., Mandal, A., Lazar, N., Stufken, J., 2009. Multi-objective optimal experimental designs for event-related fmri studies. NeuroImage 44, 849–856. https://doi.org/10.1016/j.neuroimage.2008.09.025.
Lindquist, M., Mejia, A., 2015. Zen and the art of multiple comparisons. Psychosomatic Medicine 77, 114–125. https://doi.org/10.1097/PSY.0000000000000148.
Liu, T., Frank, L., Buxton, R., 2001. Detection power, estimation efficiency, and predictability in event-related fmri. NeuroImage 13, 759–773. https://doi.org/10.1006/nimg.2000.0728.
Mumford, J., 2011. A power calculation guide for fmri studies. Social Cognitive and Affective Neuroscience 7, 738–742. https://doi.org/10.1093/scan/nss059.
Nielsen, M., 2015. Neural Networks and Deep Learning. Determination Press.
Poldrack, R., Mumford, J., Nichols, T., 2011. Handbook of Functional MRI Data Analysis. Cambridge University Press.
Rawlings, J., Pantula, S.G., Dickey, D.A., 1998. Applied Regression Analysis: A Research Tool. Springer Texts in Statistics.