前面我们完成了一些基本概念,如果你对深度学习的基本原理还不了解,你可以通过这里获得更多信息,由于深度学习的教程汗牛充栋,因此我在这里不会重复,而是集中精力到chatgpt模型原理的分析,实现和实践上。ChatGPT基于一种叫transformer的深度学习模型,它又由一系列组件组合而成,对称我们将逐个剖析。首先我们看看transformer模型的基本结构:
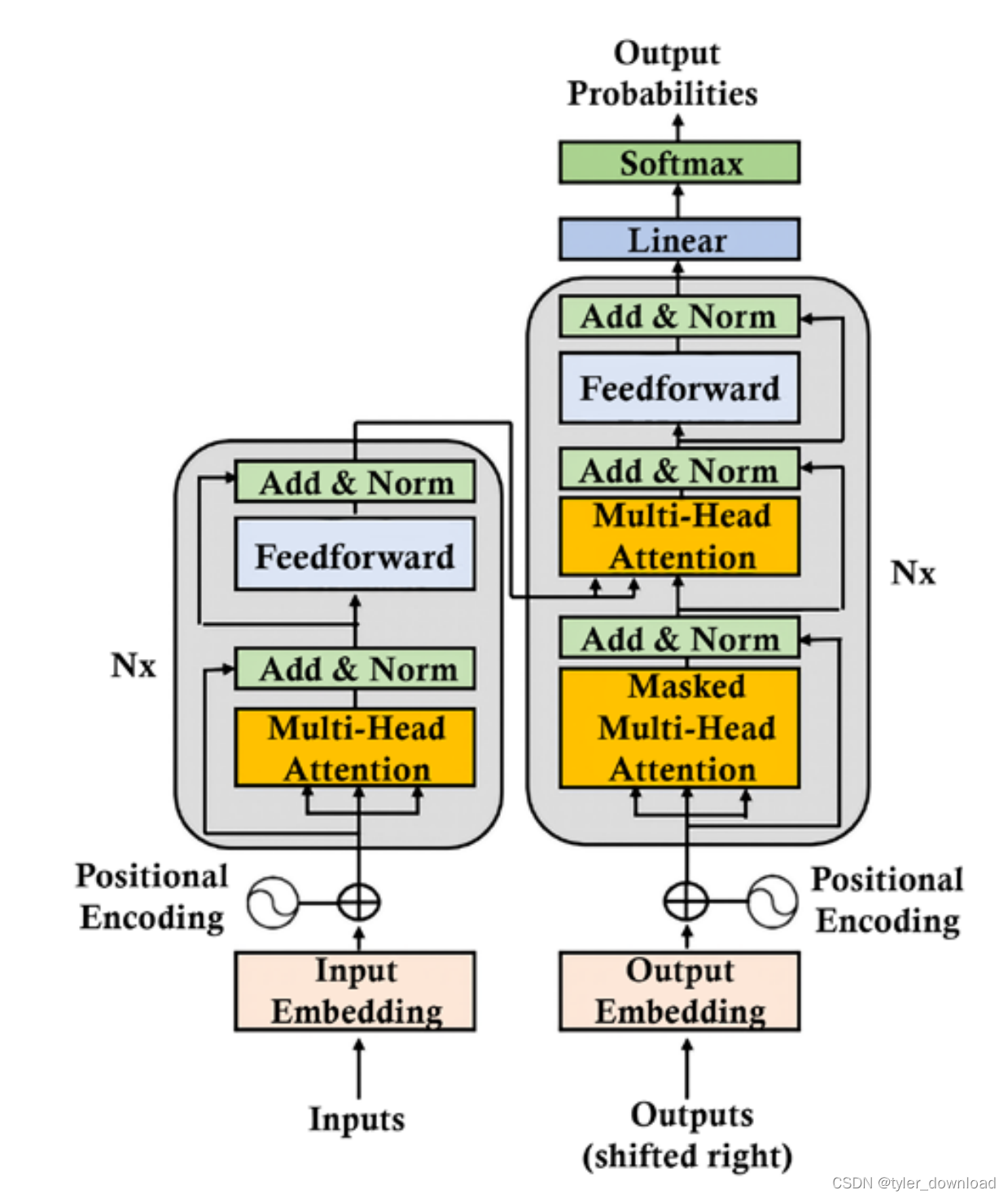
不知你是否感觉这个图有种赛博朋克的科幻感。两个大方块左边那个叫encoder,也叫编码器,在深度学习中一种很常见的模式是,将输入数据经过一系列运算后转换成一种特定向量,用术语说叫lantent vector,这个向量往往记录了输入数据的特定属性,右边方块叫decoder,它的作用是解析encoder生成的中间向量,然后生成某种特定的输出。举个具体例子,警察在侦查案件时,往往会让目击者描述嫌疑人的长相特征,此时目击者就相当于encoder,他描述的特征比如“圆脸,卷发,高额头”等就相当于上面encoder的输出向量,然后公安部分有特定的刑侦人员通过这些特征把嫌疑人的相貌绘制出来,通常绘制的画像跟真实嫌疑人相貌有不小差距,但是由于它能捕捉特定特征,因此这种画像对警方追查嫌疑人也有很大帮助。
首先我们看第一步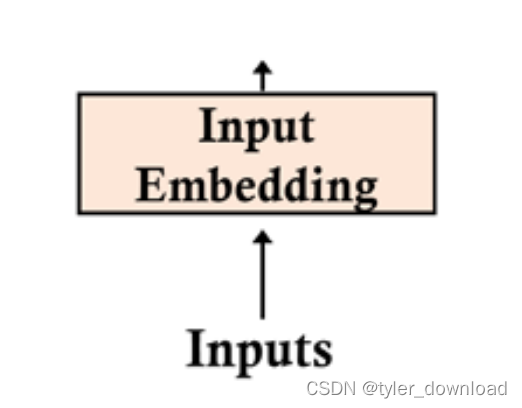
inputs是模型的输入数据,对chatgpt来说输入就是一个单词或者句子,input embedding是对输入的一种预处理,它把输入的单词或句子转换成一个向量,这一步是NLP算法中一个重要的课题,前面我们描述过任何难以用传统数据结构描述的对象都可以用向量来表示,当一个词被转换成多维空间的向量时,我们就能通过研究向量在空间中的分布来了解它在语言中的特性,同时如果两个单词分别转换成向量后,如果他们对应的向量在空间上距离越接近,我们就认为他们之间的关系越紧密。
首先我们看看如何将单词转换为向量,这里我们使用BERT模型,它是谷歌大脑早期基础模型之一,通过它我们就能够直接将单词转换为向量。首先我们看一个句子:
The man is king and he loves dog, the woman is queen and she loves cat
在句子中有几个关键词,(man,woman), (king, queen), (dog, cat),可以看到每一组的两个词,它们在含义上互相接近,因此有理由预计如果将他们转换为向量,那么括号对里单词对应的向量在空间上的距离会相互接近,我们用代码检验一下:
from transformers import AutoTokenizer, AutoModel
import torch
from sklearn.metrics.pairwise import cosine_similarity
# Load the BERT tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased')
words = ["man", "woman", "king", "queen", "cat", "dog"]
#embeddings = np.array([word2Vector(word).detach().numpy().reshape(1, -1).flatten() for word in words])
sentence = "The man is king and he loves dog, the woman is queen and she loves cat"
word1 = "man"
word2 = "woman"
word3 = "king"
word4 = "queen"
word5 = "cat"
word6 = "dog"
# Tokenize the sentence and words
tokens = tokenizer(sentence, return_tensors='pt')
word1_tokens = tokenizer(word1, return_tensors='pt')
word2_tokens = tokenizer(word2, return_tensors='pt')
word3_tokens = tokenizer(word3, return_tensors='pt')
word4_tokens = tokenizer(word4, return_tensors='pt')
word5_tokens = tokenizer(word5, return_tensors='pt')
word6_tokens = tokenizer(word6, return_tensors='pt')
# Get the embeddings for the sentence and words
sentence_embedding = model(**tokens).last_hidden_state.mean(dim=1).squeeze()
word1_embedding = model(**word1_tokens).last_hidden_state.mean(dim=1).squeeze()
word2_embedding = model(**word2_tokens).last_hidden_state.mean(dim=1).squeeze()
word3_embedding = model(**word3_tokens).last_hidden_state.mean(dim=1).squeeze()
word4_embedding = model(**word4_tokens).last_hidden_state.mean(dim=1).squeeze()
word5_embedding = model(**word5_tokens).last_hidden_state.mean(dim=1).squeeze()
word6_embedding = model(**word6_tokens).last_hidden_state.mean(dim=1).squeeze()
embeddings = [word1_embedding.detach().numpy().reshape(1, -1).flatten(), word2_embedding.detach().numpy().reshape(1, -1).flatten(),
word3_embedding.detach().numpy().reshape(1, -1).flatten(), word4_embedding.detach().numpy().reshape(1, -1).flatten(),
word5_embedding.detach().numpy().reshape(1, -1).flatten(), word6_embedding.detach().numpy().reshape(1, -1).flatten()]
上面代码通过下载已经训练好的BERT模型,然后将给定句子进行分词,每个单词在模型训练的语料中都有对应编号,我们找到其编号也就是上面对应的word1_tokens等输入到模型中获得其对应向量word1_embedding,我们不用关心上面代码的逻辑,只需要知道代码把单词转换为向量即可,然后我们把向量打印出来看看:
import numpy as np
print(np.shape(word1_embedding.detach().numpy().reshape(1, -1).flatten()))
print(f"word embedding : {word1_embedding}")
上面代码运行后所得结果如下:
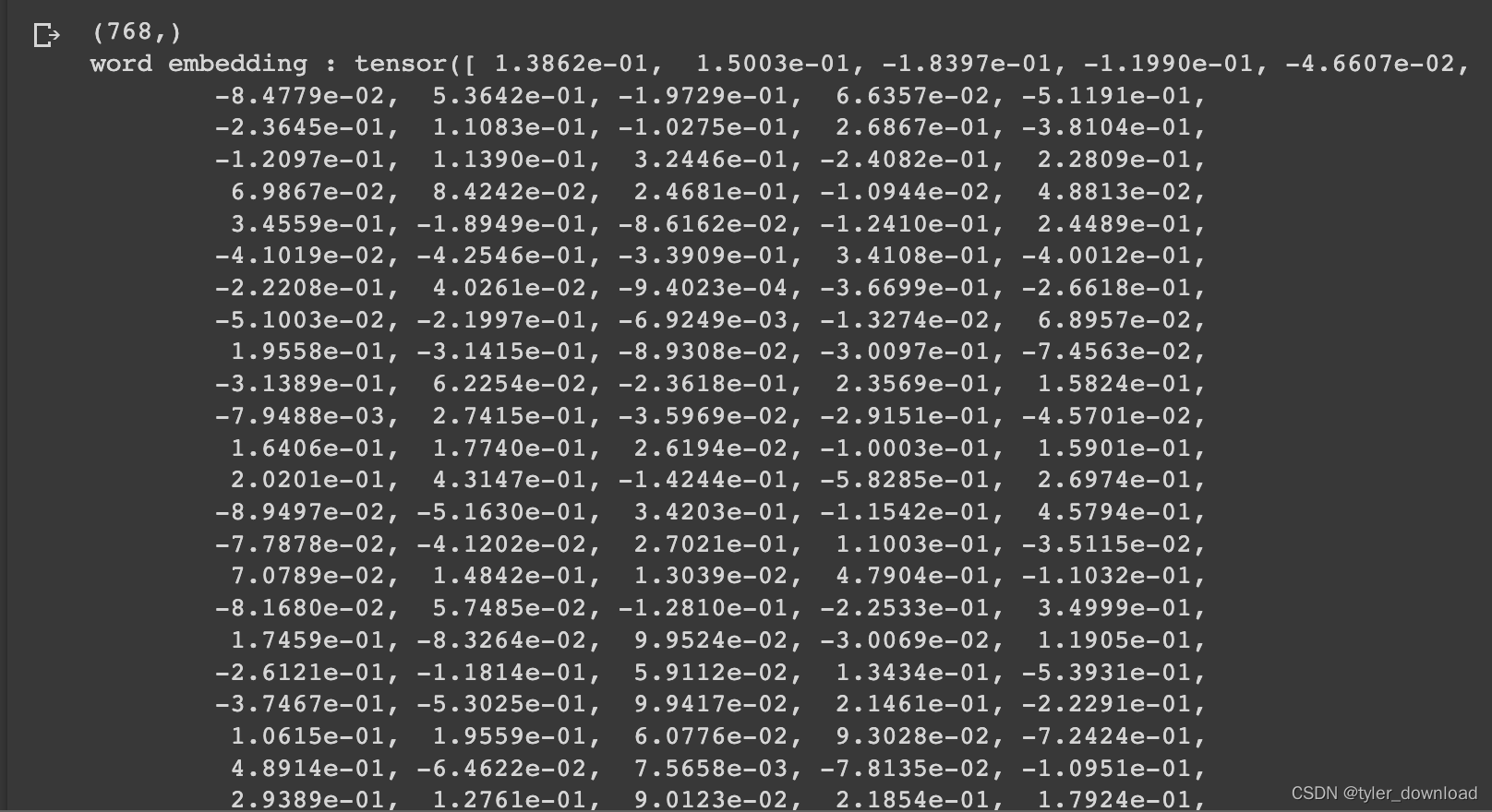
可以看到单词转换为向量后,对应的是一个包含有768个元素的一维向量,接下来我们把六个单词向量绘制出来看看其对应关系:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings)
fig, ax = plt.subplots()
ax.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1])
for i, word in enumerate(words):
ax.annotate(word, (embeddings_2d[i, 0], embeddings_2d[i, 1]))
plt.show()
上面代码运行后所得结果如下:
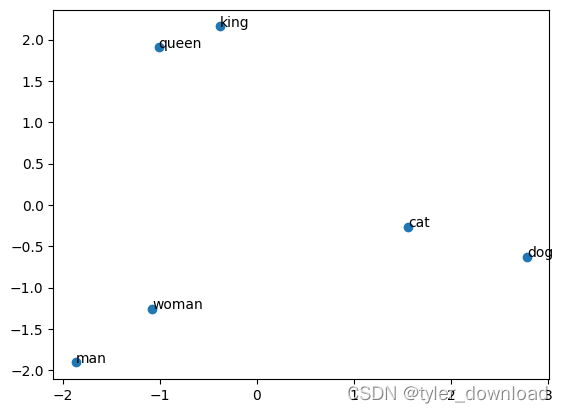
可以看到上面提到的每个括号里面的单词,相互之间距离接近,也就是说这些单词在语义上相互之间的关联性比较强,此外单词向量化后我们还能计算他们在语义上的相似性,从上图也可以看到,(man, women)在语义上相近,(queen, king)在语义上相近,(cat,dog)在语义上相近,在算法上我们通过计算两个向量夹角的余弦值来判断两个向量指向对象的相似度,我们看看相应代码实现:
man_king_sim = torch.cosine_similarity(word1_embedding, word3_embedding, dim=0)
print(f"sim for man and king: {man_king_sim}")
上面代码输出结果为:
sim for man and king: 0.861815869808197
woman_queen_sim = torch.cosine_similarity(word2_embedding, word4_embedding, dim=0)
print(f'sim for woman and queen: {woman_queen_sim}')
代码输出结果为:
sim for woman and queen: 0.8941507935523987
man_woman_sim = torch.cosine_similarity(word1_embedding, word2_embedding, dim=0)
print(f'sim for man and woman: {man_woman_sim}')
输出结果为:
im for man and woman: 0.9260298013687134
man_dog_sim = torch.cosine_similarity(word1_embedding, word6_embedding, dim=0)
print(f'sim for man and dog: {man_dog_sim}')
woman_dog_sim = torch.cosine_similarity(word2_embedding, word5_embedding, dim=0)
print(f'sim for woman and cat : {woman_dog_sim}')
dog_cat_sim = torch.cosine_similarity(word6_embedding, word5_embedding, dim=0)
print(f'sim for dog and cat: {dog_cat_sim}')
上面代码输出结果为:
sim for man and dog: 0.8304506540298462
sim for woman and cat : 0.876427948474884
sim for dog and cat: 0.900851309299469
从输出结果我们看到,dog和cat在语义上接近,man和woman在语义上接近。在具体的文本中,影响两个词意思相近性的因素还有他们在文本中的距离,假设man和women在一个句子中距离很近,那么就有可能他们指向的是一对夫妇或者情侣,但如果距离很远,那有可能文章的意思就是在说两个不相干的人,因此单词在文本中的距离也会影响他们在语义上的成分,因此chatgpt在识别文本时,也会把单词的距离纳入考量。
回到上面架构图,我们会看到在输入部分还有一个叫positional encoding的东西,如下图所示:
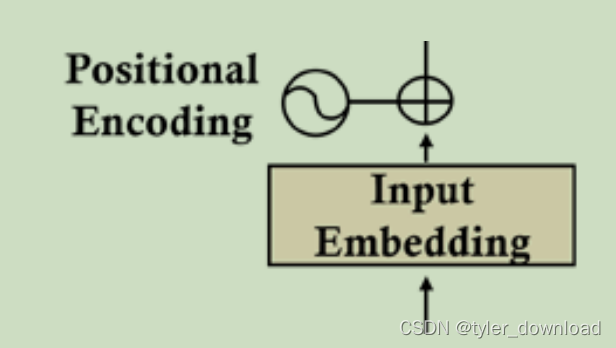
这个positional encoding 本质就是对单词在句子中的距离进行编码,这里位置的编码结果也是一维向量,而且向量的长度跟单词对应向量要一致,因为他们要进行加法运算后,其结果才能输入给chatgpt进行下一步处理,那么chatgpt是怎么去”编码“单词位置的呢,它用了如下方式进行计算:
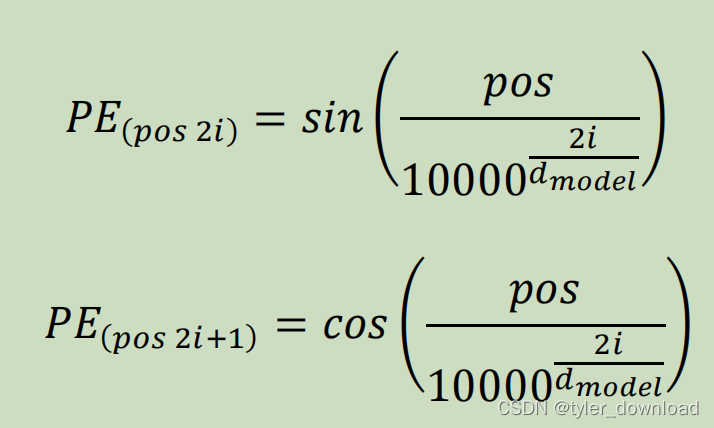
公式中pos表示单词在句子中的位置,i表示向量中分量的下标,当i=0时PE(pos, 0)就是第0个分量的取值,PE(pos, 2*0+1) 就是第1个分量的取值,d_model表示的是向量的长度,由于上面我们对单词的编码向量长度是768,因此它这里的取值也是768,我们看看实现代码:
import numpy as np
def positional_encoding(max_len, d_model):
"""
Generates positional encoding for a given sequence length and model dimension.
Args:
max_len (int): Maximum sequence length.
d_model (int): Model dimension.
Returns:
np.array: Positional encoding matrix of shape (max_len, d_model).
"""
pos_enc = np.zeros((max_len, d_model))
for pos in range(max_len):
for i in range(0, d_model, 2):
# Compute positional encoding values
div_term = np.power(10000, (2 * i) / d_model)
pos_enc[pos, i] = np.sin(pos / div_term)
pos_enc[pos, i + 1] = np.cos(pos / div_term)
return pos_enc
max_len = len(sentence)
d_model = 768
pos_enc = positional_encoding(max_len, d_model)
print("Positional Encoding:\n", pos_enc)
上面代码执行后输出如下:
Positional Encoding:
[[ 0.00000000e+00 1.00000000e+00 0.00000000e+00 ... 1.00000000e+00
0.00000000e+00 1.00000000e+00]
[ 8.41470985e-01 5.40302306e-01 8.15250650e-01 ... 1.00000000e+00
1.04913973e-08 1.00000000e+00]
[ 9.09297427e-01 -4.16146837e-01 9.44236772e-01 ... 1.00000000e+00
2.09827946e-08 1.00000000e+00]
...
[-8.55519979e-01 -5.17769800e-01 8.57295439e-01 ... 1.00000000e+00
7.02923619e-07 1.00000000e+00]
[-8.97927681e-01 4.40143022e-01 9.16178088e-01 ... 1.00000000e+00
7.13415016e-07 1.00000000e+00]
[-1.14784814e-01 9.93390380e-01 2.03837160e-01 ... 1.00000000e+00
7.23906413e-07 1.00000000e+00]]
接下来我们按照上图把位置编码对应的向量跟单词向量相加:
pe_tensor = []
for tensor in pos_enc:
pe_tensor.append(torch.from_numpy(tensor))
man_index = sentence.index("man")
man_pe_tensor = word1_embedding + pe_tensor[man_index]
woman_index = sentence.index("woman")
woman_pe_tensor = word2_embedding + pe_tensor[woman_index]
dog_index = sentence.index("dog")
dog_pe_tensor = word6_embedding + pe_tensor[dog_index]
cat_index = sentence.index("cat")
cat_pe_tensor = word5_embedding + pe_tensor[cat_index]
现在所得的最终向量不但包含了单词的语义,同时还包含了单词在句子中的位置信息,于是chatgpt就得综合这两种信息来对单词进行识别,那么单词向量加上位置信息后会有什么影响呢,一个可见的影响是,如果两个单词在位置中的距离越远,那么他们的语义相似度就会降低,也就是单词向量加上它对应的位置向量后,所得结果进行余弦计算时其对应的结果应该会有相应的降低,我们实验看看:
man_woman_pe = torch.cosine_similarity(man_pe_tensor, woman_pe_tensor, dim = 0)
print(f'man woman sim with pe: {man_woman_pe}') #0.9260298013687134
man_dog_pe = torch.cosine_similarity(man_pe_tensor, dog_pe_tensor, dim = 0)
print(f'man dog sim with pe: {man_dog_pe}') #0.8304506540298462
woman_cat_pe = torch.cosine_similarity(woman_pe_tensor, cat_pe_tensor, dim = 0)
print(f'woman cat sim with pe: {woman_cat_pe}') #0.876427948474884
dog_cat_pe = torch.cosine_similarity(dog_pe_tensor, cat_pe_tensor, dim = 0)
print(f'dog cat sim with pe: {dog_cat_pe}') #0.900851309299469
上面代码运行结果如下;
man woman sim with pe: 0.8062191669897198
man dog sim with pe: 0.8047418505220771
woman cat sim with pe: 0.7858729168616464
dog cat sim with pe: 0.7830654688550558
通过结果我们能看到,在考虑到距离因素后,对应两个词在语义上的相似度确实有相应的降低。至此我们就完成了chatgpt模型输入处理部分的分析,想一节我们分析开启大模型算法的理论基石:multi-attention,正是因为这个机制或算法的引进,chatgpt这种基于transfomer架构的语言生成能力才会如此强悍。