目录
- 环境配置
- 取得数据名 datas.keys()
- 取得pandas的DataFrame类型数据
- 一些数据分析例程供入门同学学习
- 转化为csv excel格式
- 所有数据 转化为csv
- 取前面100行数据 快速测试能否转化csv
- 取前面100行数据 快速测试能否转化xlsx
- 完整例程
- 总结
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
近期有不少数学专业的同学做统计方向的毕设有咨询,特此整理本文,所以讲的比较细,计算机专业的直接看文末的代码即可。
环境配置
虽然核心是pyreadr库,但是它有不少的前置库,最好是建议你通过我导出的requirement.txt安装所有库
pip install pyreadr
在项目目录下新建一个requirement.txt文件,内容如下:
et-xmlfile==1.1.0
numpy==1.24.2
openpyxl==3.1.2
pandas==2.0.0
pyreadr==0.4.7
python-dateutil==2.8.2
pytz==2023.3
six==1.16.0
tzdata==2023.3
在你的项目下打开cmd(输入cmd后按下回车键即可)
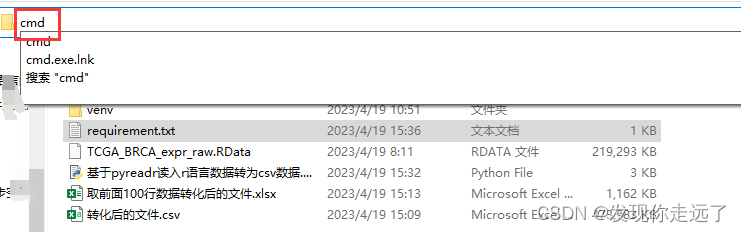
快速批量安装所有库包,并且版本和我一致(当然最好装在venv虚拟环境中 有需求可以参看我关于venv的博文,无伤大雅)
pip install -r requirements.txt

## 从文件中读取数据pyreadr.read_r() ```python in_file_path="TCGA_BRCA_expr_raw.RData"#输入文件名 datas = pyreadr.read_r(in_file_path) ```
- 参数 in_file_path 是你的rdata文件路径,如果和py文件在同一文件夹下,就填写rdata文件名就行了
- 返回值:<class ‘collections.OrderedDict’>类型数据
取得数据名 datas.keys()
print(datas.keys()) #输出数据名
- 输出内容:odict_keys([‘BRCA.expr’])
这里面是一个列表可以存放很多数据,但是我们这个列表恰好只有一个'BRCA.expr'
取得pandas的DataFrame类型数据
df = datas["BRCA.expr"] # 根据数据名得到数据,数据类型是 <class 'pandas.core.frame.DataFrame'>
print(type(df))# <class 'pandas.core.frame.DataFrame'>
print(df) #打印数据展示
- 这里要根据前面得到的数据名获取df
一些数据分析例程供入门同学学习
df是前文代码得到的数据
col_names = df.columns
print("展示列名\n",col_names)
#展示行名
index_names = df.index
print("展示行名\n",index_names)
# 取前面X行数据
test_df=df.head(10)#取前面10行数据
print("取前面10行数据\n",test_df)#取前面10行数据
# df.iloc方法按照切片取指定X行数据
# 注意:pandas的1.0.0版本后,已经对ix函数进行了升级和重构。 老版本这里不是df.iloc而是df.ix
# 现在都是新版本了,如果你看到 df.ix这种操作也不要惊讶
test_df=df.iloc[0:5, :] # 使用 iloc 函数 ,切片类似matlab 取得第0-4行,所有列数据
print("df.iloc方法按照切片取指定X行数据\n",test_df)#取指定X行数据 [5 rows x 1222 columns]
# df.loc方法,按照行和列的标签取数据
test_df=df.loc[df.index[0:5], "TCGA.E9.A1N3.01A.12R.A157.07"] # 取得第0-4行,"TCGA.E9.A1N3.01A.12R.A157.07"这一列的数据,其实就是第一列
print("df.loc方法,按照行和列的标签取数据\n",test_df)
转化为csv excel格式
我的rdata源文件有200+MB大小
导出的csv文件有 400MB+
excel肯定会更大·····
为什么不推荐导出excel呢?转化时间很慢,比csv慢50倍,而且对内存要求大。而且csv文件也一样能用excel办公软件打开。
所有数据 转化为csv
out_file_path="转化后的文件.csv"
print("开始转化")
df.to_csv(out_file_path)
print("转化完成")#这个转化过程比较久,没有出现输出转化完成之前不要动文件,可能因为文件的只读导致文件损坏!!
取前面100行数据 快速测试能否转化csv
#取前面100行数据 快速测试能否转化
out_file_path="转化后的文件.csv"
print("开始转化")
test_df=df.head(100)#取前面100行数据 快速测试能否转化
test_df.to_csv(out_file_path)#如果需要,取前面100行数据 快速测试能否转化
print("转化完成")
取前面100行数据 快速测试能否转化xlsx
# 如果你一定要抓excel,也有解决方案
out_file_path="取前面100行数据转化后的文件.xlsx"
print("开始转化")
test_df=df.head(100)#取前面100行数据 快速测试能否转化
test_df.to_excel(out_file_path)#如果需要,取前面100行数据 快速测试能否转化
print("转化完成")
完整例程
# @Time : 2023/4/19 8:19
# @Author : 南黎
# @FileName: 基于pyreadr读入r语言数据转为csv数据.py
import pyreadr
import pandas as pd
in_file_path="TCGA_BRCA_expr_raw.RData"#输入文件名
datas = pyreadr.read_r(in_file_path)
#print(type(datas))# <class 'collections.OrderedDict'>
# print(datas.keys()) #输出数据名 odict_keys(['BRCA.expr']) 本文的数据只有 BRCA.expr 有些文件可能是一个列表 有多个数据项
df = datas["BRCA.expr"] # 根据数据名得到数据,数据类型是 <class 'pandas.core.frame.DataFrame'>
# print(type(df))# <class 'pandas.core.frame.DataFrame'>
# print(df) #打印数据展示
#展示列名
col_names = df.columns
print("展示列名\n",col_names)
#展示行名
index_names = df.index
print("展示行名\n",index_names)
# # 取前面X行数据
# test_df=df.head(10)#取前面10行数据
# print("取前面10行数据\n",test_df)#取前面10行数据
# # df.iloc方法按照切片取指定X行数据
# # 注意:pandas的1.0.0版本后,已经对ix函数进行了升级和重构。 老版本这里不是df.iloc而是df.ix
# # 现在都是新版本了,如果你看到 df.ix这种操作也不要惊讶
# test_df=df.iloc[0:5, :] # 使用 iloc 函数 ,切片类似matlab 取得第0-4行,所有列数据
# print("df.iloc方法按照切片取指定X行数据\n",test_df)#取指定X行数据 [5 rows x 1222 columns]
#
# # df.loc方法,按照行和列的标签取数据
# test_df=df.loc[df.index[0:5], "TCGA.E9.A1N3.01A.12R.A157.07"] # 取得第0-4行,"TCGA.E9.A1N3.01A.12R.A157.07"这一列的数据,其实就是第一列
# print("df.loc方法,按照行和列的标签取数据\n",test_df)
# 导出csv文件的流程(为什么不选择excel呢? csv处理数据更快,csv比excel快50倍,数据量太大了这里)
out_file_path="转化后的文件.csv"
print("开始转化")
df.to_csv(out_file_path)
print("转化完成")#这个转化过程比较久,没有出现输出转化完成之前不要动文件,可能因为文件的只读导致文件损坏!!
# #取前面100行数据 快速测试能否转化
# out_file_path="转化后的文件.csv"
# print("开始转化")
# test_df=df.head(100)#取前面100行数据 快速测试能否转化
# test_df.to_csv(out_file_path)#如果需要,取前面100行数据 快速测试能否转化
# print("转化完成")
# # 如果你一定要抓excel,也有解决方案
# out_file_path="取前面100行数据转化后的文件.xlsx"
# print("开始转化")
# test_df=df.head(100)#取前面100行数据 快速测试能否转化
# test_df.to_excel(out_file_path)#如果需要,取前面100行数据 快速测试能否转化
# print("转化完成")
总结
大家喜欢的话,给个👍,点个关注!继续跟大家分享敲代码过程中遇到的问题!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2022 mzh
Crated:2022-1-10
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
【Python安装第三方库一行命令永久提高速度】
【使用PyInstaller打包Python文件】
【更多内容敬请期待】