引言
- 当前LLM模型火出天际,但是做事还是需要脚踏实地。
- 此文只是日常学习LLM,顺手整理所得。
- 本篇博文更多侧重对话、问答类LLM上,其他方向(代码生成)这里暂不涉及,可以去看综述来了解。
之前LLM模型梳理
- 图来源: A Survey of Large Language Models | Github Repo

BLOOM (BigScience)
- BLOOM是一个自回归的大模型,可根据prompt来生成连续的文本。包括46种语言和13个编程语言。
- 参数量为1760亿个参数。和GPT一样,使用的是
decoder-only架构。 - 训练所用数据集基本是手搓出来的。
- 但是要想推理起来这个模型,起码需要8个A800 80G的显卡才能推理起来。小编前不久有幸推理了一下,模型将近就有328G,真是够大的。
- 这个模型要想落地,可就需要很长一段时间了。
后BLOOM模型梳理
LLaMA (Meta)
- 缺乏指令微调
后LLaMA模型梳理
Alpaca (斯坦福)
- 由Meta的LLaMA 7B微调而来,52k数据,性能约等于GPT-3.5
- 由Self-Instruct: Aligning Language Model with Self Generated Instructions论文启发,使用现有强语言模型自动生成指令数据
- 衍生项目:
- Alpaca-LoRA: 开启了LLaMA模型上LoRA微调
- Chinese-LLaMA-Alpaca
- Chinese-alpaca-lora
- japanese-alpaca-lora
- Wombat
- 提出无需强化学习的对齐方法训练语言模型
Vicuna (UC伯克利、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校)
- 与GPT-4性能相匹配的LLaMA微调版本, 130亿参数
- 通过在ShareGPT收集用户共享对话对LLaMA进行微调而来,在超过90%的情况下,实现了与Bard和ChatGPT相匹配的能力
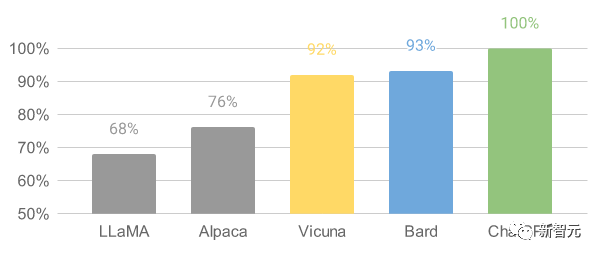
- 训练流程:
三者之间汇总对比

Koala (UC伯克利 AI Research Institute(BAIR))
- 使用网络获取的高质量数据进行训练,可以有效地回答各种用户的查询,比Alpaca更受欢迎,至少在一半的情况下与ChatGPT的效果不相上下
- 得出有效结论:正确的数据可以显著改善规模更小的开源模型
- 研究人员专注于收集一个小型的高质量数据集,包括ChatGPT蒸馏数据、开源数据等
ChatLLaMA (Nebuly)
- 一个可以使用自己的数据和尽可能少的计算量,来创建个性化的类似ChatGPT的对话助手
- 库的目的是通过抽象计算优化和收集大量数据所需的工作,让开发人员高枕无忧
- ChatLLaMA旨在帮助开发人员处理各种用例,所有用例都与RLHF训练和优化推理有关。以下是一些用例参考:
- 为垂直特定任务(法律、医疗、游戏、学术研究等)创建类似ChatGPT的个性化助手;
- 想在本地硬件基础设施上使用有限的数据,训练一个高效的类似ChatGPT的助手;
- 想创建自己的个性化版本类ChatGPT助手,同时避免成本失控;
- 想了解哪种模型架构(LLaMA、OPT、GPTJ等)最符合我在硬件、计算预算和性能方面的要求;
- 想让助理与我的个人/公司价值观、文化、品牌和宣言保持一致。
Chinese-ChatLLaMA(ydli-ai)
- 中文对话模型ChatLLaMA、中文基础模型LLaMA-zh。
-ChatLLaMA 支持简繁体中文、英文、日文等多语言。 - LLaMA 在预训练阶段主要使用英文,为了将其语言能力迁移到中文上,首先进行中文增量预训练,
- 使用的语料包括中英平行语料、中文维基、社区互动、新闻数据、科学文献等。再通过 Alpaca 指令微调得到 Chinese-ChatLLaMA。
- 项目特点
- 通过 Full-tuning (全参数训练)获得中文模型权重,提供 TencentPretrain 与 HuggingFace 版本
- 模型细节公开可复现,提供数据准备、模型训练和模型评估完整流程代码
- 提供目前最大的中文 LLaMA 模型
- 多种量化方案,支持 CUDA 和边缘设备部署推理
FreedomGPT (Age of AI)
- 建立在Alpaca之上,回答问题没有偏见或偏袒,并且会毫不犹豫第回答有争议或争论性的话题
- 克服了审查限制,在没有任何保障的情况下迎合有争议性的话题。标志是自由女神像,象征自由。
ColossalChat (UC伯克利)
- 基于LLaMA模型,只需不到100亿个参数就能达到中英文双语能力,效果与ChatGPT和GPT3.5相当。
- 复刻了完整的RLHF过程,是目前最接近ChatGPT原始技术路线的开源项目
- 使用了InstrutionWild中英双语训练数据集,其中包含大约100,000个中英文问答对。
- 该数据集是从社交媒体平台上的真实问题场景中收集和清理的,作为种子数据集,使用self-instruct进行扩展,标注成本约为900美元。
- 与其他self-instruct方法生成的数据集相比,该数据集包含更真实和多样化的种子数据,涵盖更广泛的主题。该数据集适用于微调和RLHF训练。
- 在提供优质数据的情况下,ColossalChat可以实现更好的对话交互,同时也支持中文。
- 完整的RLHF管线,共有三个阶段:
- RLHF-Stage1: 使用上述双语数据集进行监督指令微调模型
- RLHF-Stage2: 通过对同一提示的不同输出手动排序来训练奖励模型,分配相应的分数,然后监督奖励模型的训练
- RLHF-Stage3: 使用强化学习算法,这是训练过程中最复杂的部分。
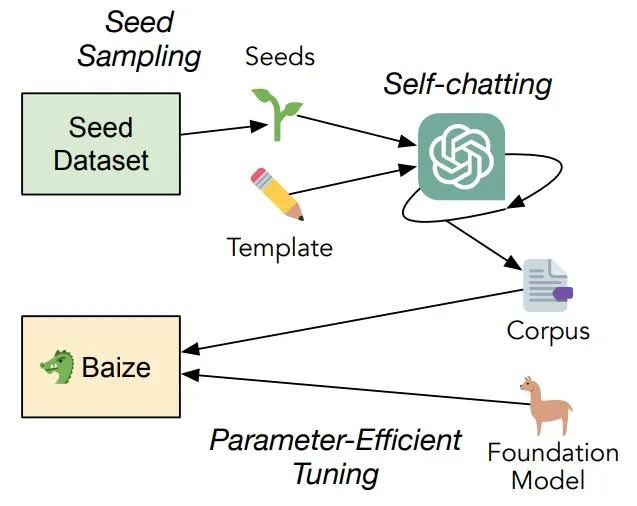
Baize (加州大学圣迭戈分校、中山大学和微软亚研)
-
包括四种英文模型(白泽-7B、13B、30B)和一个垂直领域的白泽医疗模型,计划未来发布中文的白泽模型。
-
值得注意的是,该方法的数据处理、训练模型、Demo等全部代码均已开源,真是良心,由衷点赞。
-
作者提出一种自动收集ChatGPT对话的流水线,通过从特定数据集中采样[种子]的方式,让ChatGPT自我对话,批量生成高质量多轮对话数据集。如果使用特定领域数据集,比如医学问答数据集,就可以生成高质量垂直领域语料。
gpt4all(Nomic AI)
- 基于GPT-3.5-Turbo的800k条数据进行训练,包括文字问题、故事描述、多轮对话和代码。
- 该方案提供了完整的技术报告,包括收集数据、整理数据、训练代码和模型权重。
Huatuo-Llama-Med-Chinese(哈工大)
ChatYuan-large-v2 (元语智能)
- 这个模型的商业气息较浓一些。不过,这也是无奈之举。
- ChatYuan-large-v2是一个支持中英双语的功能型对话语言大模型。ChatYuan-large-v2使用了和 v1版本相同的技术方案,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
- ChatYuan-large-v2是ChatYuan系列中以轻量化实现高质量效果的模型之一,用户可以在消费级显卡、 PC甚至手机上进行推理(INT4 最低只需 400M )。
Firefly(yangjianxin1)
- Firefly(流萤) 是一个开源的中文对话式大语言模型,基于BLOOM模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。同时使用了词表裁剪、ZeRO、张量并行等技术,有效降低显存消耗和提高训练效率。 在训练中,使用了更小的模型参数量,以及更少的计算资源。构造了许多与中华文化相关的数据,以提升模型这方面的表现,如对联、作诗、文言文翻译、散文、金庸小说等。
- 因为该项目首先采用LLMPrunner对原始BLOOM模型进行此表裁剪,所以效果有限,优势在于小,缺点也在这里。
BELLE (链家)
-
本项目重点关注在开源预训练大语言模型的基础上,如何得到一个尽可能效果好的具有指令表现能力的语言模型,降低大家研究此方面工作的门槛,重点在于中文大语言模型。
-
针对中文做了优化,模型调优仅使用了由ChatGPT生产的数据(不包含任何其他数据)
-
调优BLOOMZ-7B1-mt模型,开放了四个不同大小规模的指令学习数据集训练模型
Datasize 200,000 600,000 1,000,000 2,000,000 Finetuned Model BELLE-7B-0.2M BELLE-7B-0.6M BELLE-7B-1M BELLE-7B-2M
- 基于Meta LLaMA实现调优的模型:BELLE-LLaMA-7B-0.6M-enc
, BELLE-LLaMA-7B-2M-enc
, BELLE-LLaMA-7B-2M-gptq-enc
, BELLE-LLaMA-13B-2M-enc。请参考Meta LLaMA的License
- 值得说明的是,该项目开源了一批由ChatGPT生成的中文数据集,具体如下:
- 1.5M中文数据集:包含不同指令类型、不同领域的子集。
- 10M中文数据集,包括25w条中文数学题数据、80w条用户与助手对话数据、40w条给定角色的多轮对话数据、200w条多样化指令任务数据。
- ⚠️ 数据集开源协议均为GPL3.0,使用请注意。
ChatGLM-6B (清华)
GLM-130B(清华)
后ChatGLM梳理
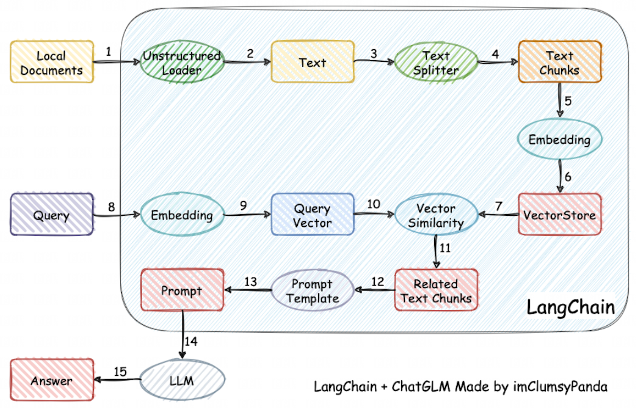
langchain-ChatGLM (imClumsyPanda)
-
该项目是基于本地知识的ChatGLM应用实现。基于本地文档类知识来增强ChatGLM的回答。这应该是最能落地的项目了。
-
整体流程如下图:
Med-ChatGLM(哈工大)
Dolly 2.0 (databricks)
IDPChat (白海)
- 中文多模态模型,基于预训练大模型LLaMA和开源文生图预训练模型Stable Diffusion为基础,快速构建而来。
- 开发者可以根据场景需求,便捷地对其进行微调优化。
参考资料
- 开发者笑疯了! LLaMa惊天泄露引爆ChatGPT平替狂潮,开源LLM领域变天
- 训练ChatGPT的必备资源:语料、模型和代码库完全指南
- 用ChatGPT训练羊驼:「白泽」开源,轻松构建专属模型,可在线试玩
- 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- 世界首款真开源类ChatGPT大模型Dolly 2.0,可随意修改商用
- 中文多模态模型问世!IDPChat生成图像文字,只需5步+单GPU