文章目录
- SeeThroughNet: Resurrection of Auxiliary Loss by Preserving Class Probability Information
- 摘要
- 本文方法
- Class Probability Preserving Pooling
- SeeThroughNet
SeeThroughNet: Resurrection of Auxiliary Loss by Preserving Class Probability Information
摘要
辅助损失函数是在主分支损失之外的附加损失,有助于优化神经网络的学习过程。
为了计算语义分割领域中中间层特征图与ground truth之间的辅助损失,每个特征图的大小必须与ground truth匹配
在所有使用分割模型的辅助损失的研究中,要么使用下采样函数来减少ground truth的大小,要么使用上采样函数来增加特征图的大小,以匹配特征图和地面真相之间的分辨率。
但是在通过下采样和上采样选择代表性值的过程中,信息的丢失是不可避免的
本文方法
引入了类概率保留池化(CPP)来减少语义分割任务中ground truth下采样时的信息损失

类概率保持(CPP)池化效果的可视化。对于被遮挡的火车(红色框中)、被遮挡的建筑(橙色框中公交车站)和远处的柱子(黄色框中),与DeepLabV3+原始模型相比,DeepLabV3+模型w/ CPP在grada - cam可视化(左列)中显示出更精细和更强的激活。在推理结果中(右列),w/ CPP模型显示了正确和精细的分割。
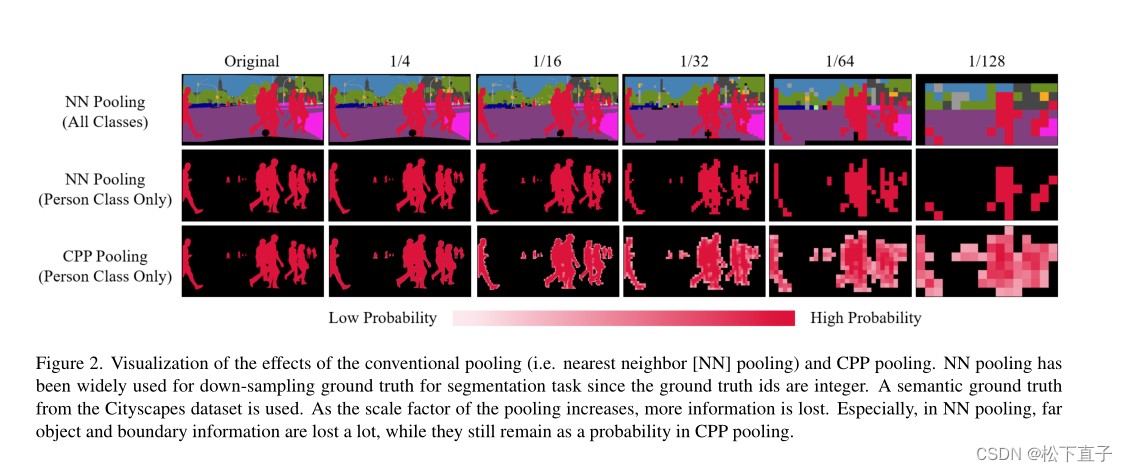
传统池化(即最近邻[NN]池化)和CPP池化效果的可视化。由于GT值为整数,神经网络池化被广泛应用于地面真实值的下采样分割任务。使用了来自Cityscapes数据集的语义ground truth。随着池的规模因子的增加,会丢失更多的信息。特别是在神经网络池化中,远目标和边界信息丢失了很多,而在CPP池化中,远目标和边界信息仍然是一种概率。
本文方法
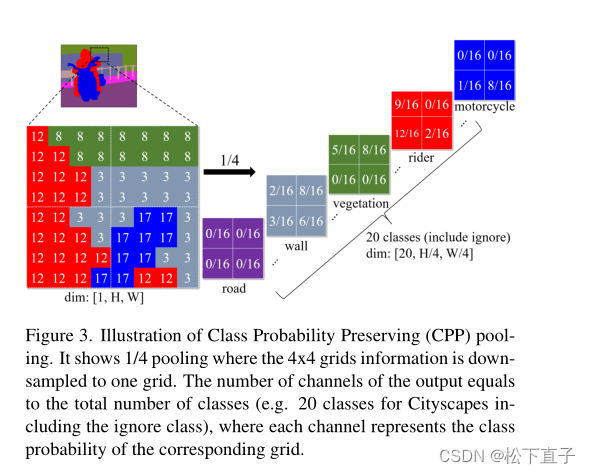
类概率保留(CPP)池化的说明。它显示了1/4池化,其中4x4网格信息被下采样到一个网格。输出的通道数等于类的总数(例如Cityscapes的20个类,包括忽略类),其中每个通道表示对应网格的类概率。
Class Probability Preserving Pooling
CPP池化不是从输入映射中对应的接受区域中确定一个代表值,而是计算与区域中每个类匹配的网格(或像素)的数量,然后使用该数字作为每个类的概率。例如,图3显示了1/4 CPP池,其中4x4网格向下采样到一个网格。
在输入映射中,统计4x4区域中0类(道路)的个数,成为0类(道路)输出通道对应网格的概率值。
对于其他类(例如,cityscape总共有20个类,包括忽略类)也会进行相同的计算。如图所示,输出网格中的每个位置都保持一定的类概率。
更详细地说,在CPP池化中,一个类k的输出Y网格被计算为:
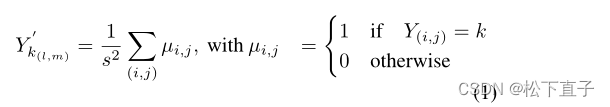
为了测量两个概率分布之间的差异,我们使用Kullback-Leibler (KL)散度,写为公式2中的DKL。设pi(x)和qi(x)分别为该层的语义预测输出和语义ground truth的CPP池化结果,损失函数为:
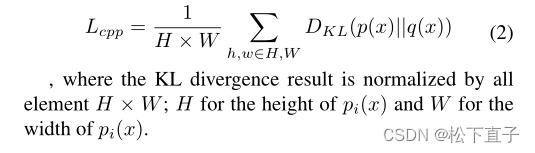
SeeThroughNet
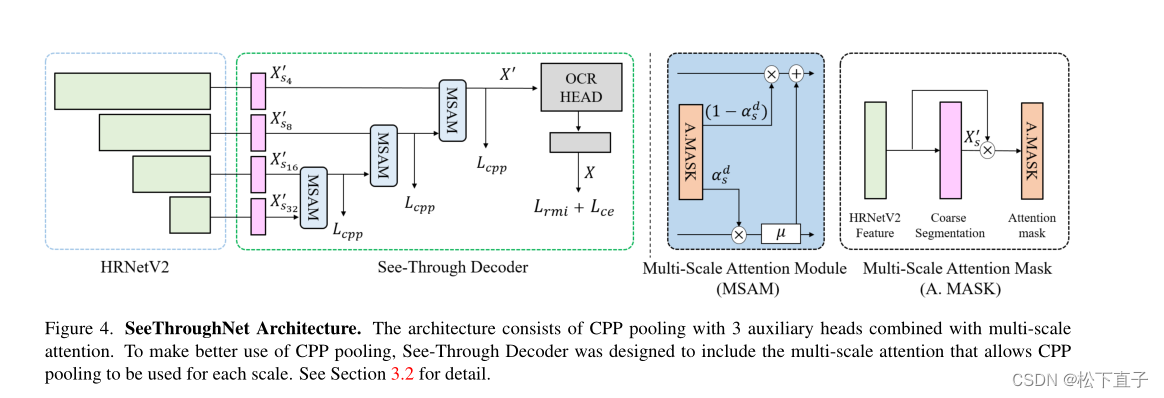
主干网络:HRNetV2-W48,输出四种不同的尺度特征
SeeThrough解码器:
粗语义分割头由(3x3 conv)→(BN)→(ReLU)→(1x1 conv)组成
使用三个辅助损失,采用由CPP池化生成的标签y0,由于类概率保留标签,解码器从更大的图像中学习潜在的存在信息,当使用下采样时,这些信息就消失了。
在相邻尺度语义分割图之间使用解码器中可训练的相对注意掩码αds
在较小的图上使用双线性上采样操作µ来匹配分辨率(多尺度注意模块[图4中的蓝框])
多尺度粗分割XS按公式3所示顺序聚合,得到细分割特征X。
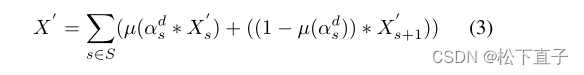
采用OCR Head来预测最终的语义分割输出X
对于双分辨率训练,我们遵循比例因子r为r=0.5和r=1.0
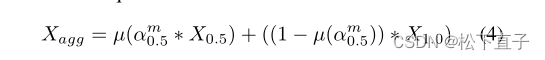
总体目标函数
最终的语义分割预测X和标签Y的损失:Lce是交叉熵损失。I代表互信息,b是批大小,c是类。对于λ,我们使用0.5
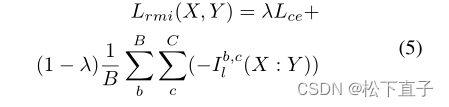
我们利用KL散度(公式2)得到方程中的辅助损耗Ldecoder
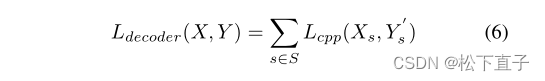
总损失
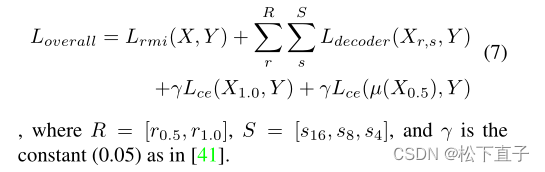






![[ARM+Linux] 基于全志h616外设开发笔记](https://img-blog.csdnimg.cn/4536d97120b142dfa06e22eb878a693c.png)