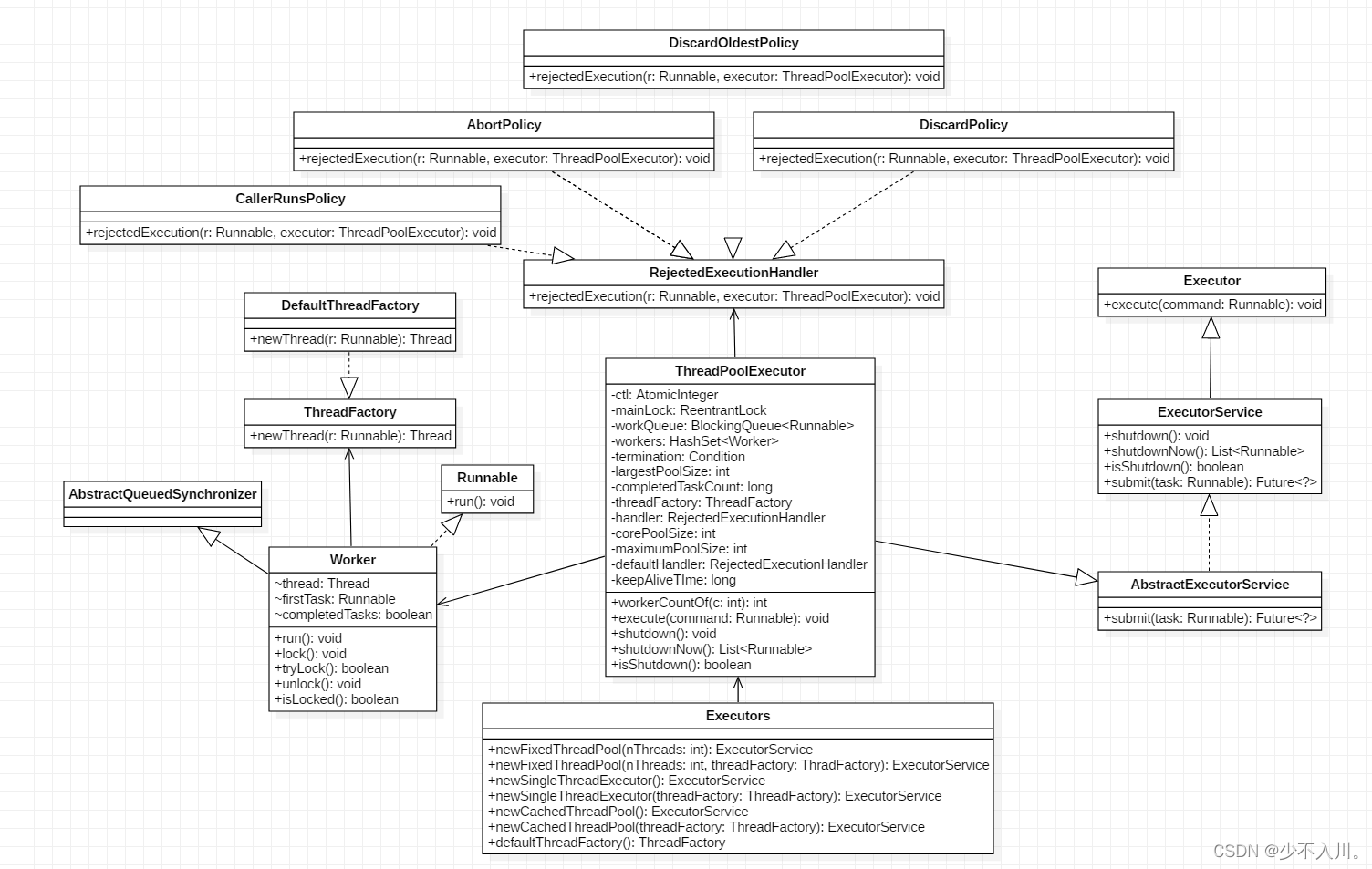
目录
消息队列的比较:
kafka的架构:
kafka为什么可以做到这么高的吞吐量:
kafka分区类型:
请看下篇文章:生产者 ACK的配置
消息队列的比较:
消息队列的产品有很多中比如:React MQ 、Kafka等。
为什么选择Kafka作为消息队列来处理数据,当时我们组也是做了大量的调研;我们当时调研考虑的主要是指标吞吐量这一块,因为大数据流式处理对数据的吞吐量要求是非常高的,在这快React MQ是比较厉害的。吞吐量可以达到1万多每秒,通过后来的调研发现kafka的吞吐量比React MQ更高,如果使用恰当的话吞吐量甚至可以达到10万+没秒。
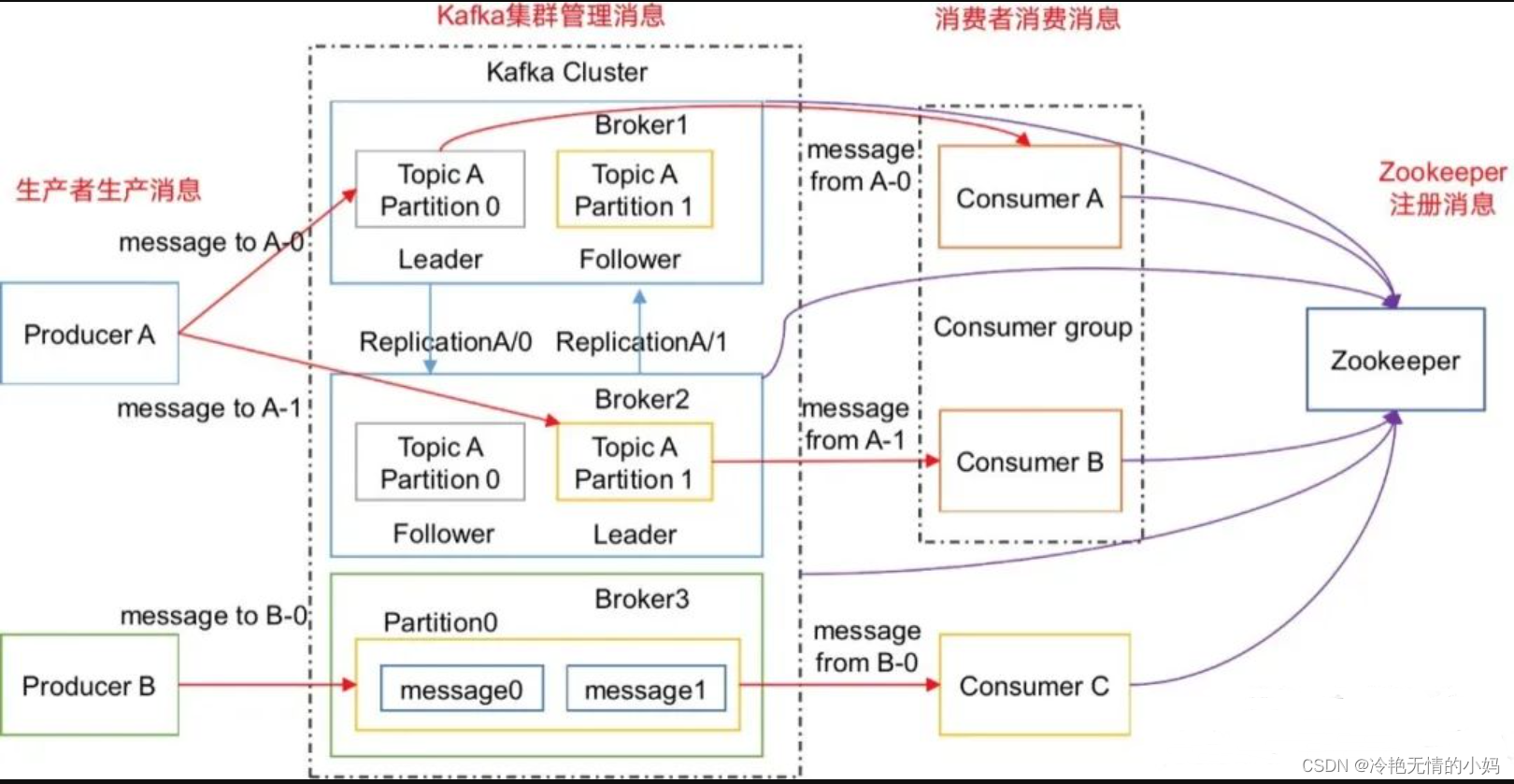
kafka的架构:
Kafka的架构主要包含生产者、Broker和消费者,其中Broker是集群的,一个Broker可以包含多个Topic,Topic里边主要是来存储数据的同时包含多个Partition ,用来增加数据传输的并发度,Broker和消费者信息都存储在Zookeeper上边。
kafka为什么可以做到这么高的吞吐量:
首先从生产者说起,生产者发送数据是按照批进行发送的并不是一条一条发送的,从这里就已经可以保证kafka一个比较高的吞吐量了。生产者来一条消息以后会进入一个拦截器,在拦截器里边可以对数据进行一个整体的修改操作,一般这里是不做特殊的处理的,数据从拦截器出来以后就会进入到序列化器,在序列化器里边将数据转换成一个二进制流的形式放入Broker里边。
kafka分区类型:
经过序列化器以后数据就会走到分区器,Kafka使用的分区器是一个叫做Hash的分区器,Hash分区器我们可以对其进行重写。分区的方式有很多种,简单来说可以分为以下几类:
1、数据带有Key:分区器会根据Key计算Hash然后根据计算后的Hasf来决定数据最终去往那个分区。
2、数据带有分区号:如果数据带有分区号的话会直接进入对应的分区里面。
3、这里还有一个累加器的东西,这个累加器相当于是一个缓冲区,这个缓冲区其实是一个HashMap其中Key是Topic加分区号的形式,Value是一个双端队列。
所以这里会使用双端队列原因是因为消息发送失败的时候会有一个重试的机制,如果消息没有发送成功会再次放入双端队列中之后会被再次发送,其次还有一个Send线程来管理每个区的大小,因为生产者底层是按照批次来进行数据发送的,这里面的感觉,就是像是一个轮询,但是这样描述也不是特别的准确。
首先它在向双端队列方数据的时候会先做一下判断(判断这个数据是否已经达到这个批次)如果达到了这个就会通过Send线程就会讲这批数据发出去,反之则继续等待;还有一种情况是按照时间来操作的,如果消息达到一定的时间以后回去检查一下有没有达到这个发送的批次阈值。
生产者将数据发送到Broker的过程可能会出现消息的重复或者丢失的情况,这个主要是靠ACK的配置来决定的。


![[ARM+Linux] 基于全志h616外设开发笔记](https://img-blog.csdnimg.cn/4536d97120b142dfa06e22eb878a693c.png)