🌻算法,不如说它是一种思考方式🍀
算法专栏: 👉🏻123
一、🌱459. 重复的子字符串
- 题目描述:给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
- 来源:力扣(LeetCode)
- 难度:简单
- 提示:
1 <= s.length <= 104
s 由小写英文字母组成 - 示例 1:
输入: s = “abab”
输出: true
解释: 可由子串 “ab” 重复两次构成。
示例 2:
输入: s = “aba”
输出: false
🌴解题
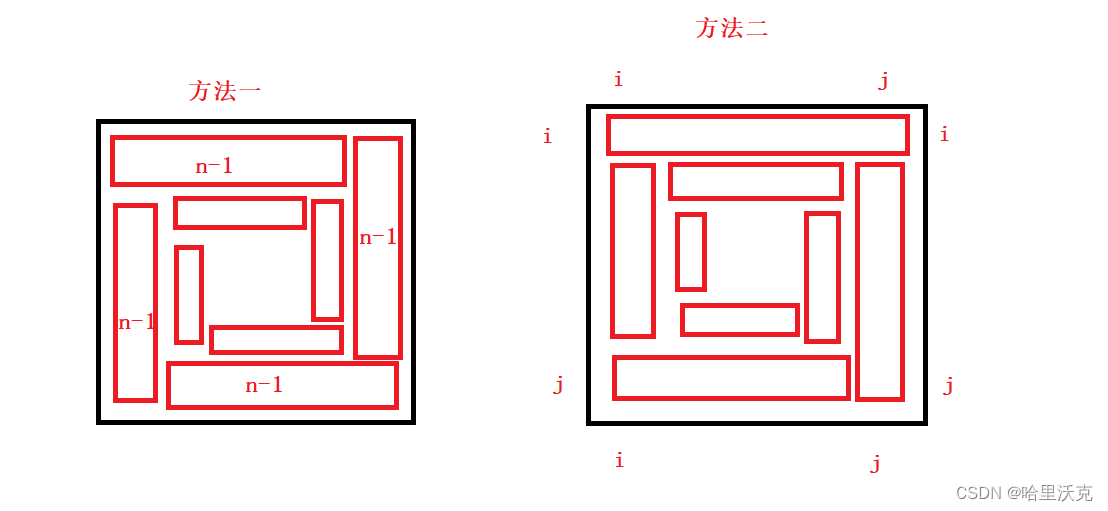
枚举子字符串长度
使用两层 for 循环:
外层 for 遍历子字符串长度 i,所以遍历的范围是 1 ~ 字符串长度一半,注意字符串长度为 1 是不满足返回 false。对于每一个子字符串长度需要确定是否可以重复来构成原字符串,即用字符串长度对子字符串取余为 0。例如下图字符串这种情况就会出现错误判断:

内层 for 遍历字符串 j,直到结束(j+i < s.length()),如下图:

code:
class Solution {
public boolean repeatedSubstringPattern(String s) {
int n = s.length();
if(n==1)
return false;
boolean tag=false;
for(int i=1;i<=n/2;i++){//间隔
if(n%i!=0)
continue;
for(int j=0;j+i<n;j++){
if(s.charAt(j)!=s.charAt(j+i))
break;
if((j+i==n-1)&&(s.charAt(j)==s.charAt(j+i)))
tag=true;
}
if(tag==true)
break;
}
return tag;
}
}

一行代码~
我们先看个例子:
字符串是:s1 = abc abc,我们可以看出是重复子字符串构成的,如果我们把这个字符串复制追加到后面:s2 = abc abc abc abc,那么 s1 肯定是 s2 的一个子字符串,并且可以知道 s1 在 s2 中第 2 次出现的首个下标号是在字符串 s1 的范围内。

字符串是:s2 = abcabac,不是重复子字符串构成的:

是重复子字符串构成的字符串,就表示字符串是可以拆解的:s = s’ + s’,那么 S = s + s = s’ + s’ + s’ + s’ ,即第二次出现的位置不会超过字符串 s 的长度。
(s + s).indexOf(s, 1)就是表示字符串 s 在 index = 1 开始出现的下标。
所以可以写出如下代码:
class Solution {
public boolean repeatedSubstringPattern(String s) {
return (s + s).indexOf(s, 1) != s.length();
}
}

KMP 方法
有了前面一种解题方法,那我们使用 KMP 算法也容易理解了,就是在 S 中找有没有子字符串 s,并且只能在 S 的前一半开始的子字符串。
class Solution {
public boolean repeatedSubstringPattern(String s) {
return kmp(s + s, s);
}
public boolean kmp(String query, String pattern) {
int n = query.length();
int m = pattern.length();
int[] fail = new int[m];
Arrays.fill(fail, -1);
for (int i = 1; i < m; ++i) {
int j = fail[i - 1];
while (j != -1 && pattern.charAt(j + 1) != pattern.charAt(i)) {
j = fail[j];
}
if (pattern.charAt(j + 1) == pattern.charAt(i)) {
fail[i] = j + 1;
}
}
int match = -1;
for (int i = 1; i < n - 1; ++i) {
while (match != -1 && pattern.charAt(match + 1) != query.charAt(i)) {
match = fail[match];
}
if (pattern.charAt(match + 1) == query.charAt(i)) {
++match;
if (match == m - 1) {
return true;
}
}
}
return false;
}
}
对比上一个方法,在时间复杂度有了优化。(s + s).indexOf(s, 1) 就是一种字符串的暴力解法,源码:
public static int indexOf(byte[] value, int valueCount, byte[] str, int strCount, int fromIndex) {
byte first = str[0];
int max = (valueCount - strCount);
for (int i = fromIndex; i <= max; i++) {
// 找到第一个匹配的字符
if (value[i] != first) {
while (++i <= max && value[i] != first);
}
// 找后面匹配的字符
if (i <= max) {
int j = i + 1;
int end = j + strCount - 1;
for (int k = 1; j < end && value[j] == str[k]; j++, k++);
if (j == end) {
// 子字符串匹配,返回第一个字符的下标
return i;
}
}
}
return -1;
}
public static int indexOfLatin1Unsafe(byte[] src, int srcCount, byte[] tgt, int tgtCount, int fromIndex) {
assert fromIndex >= 0;
assert tgtCount > 0;
assert tgtCount <= tgt.length;
assert srcCount >= tgtCount;
char first = (char)(tgt[0] & 0xff);
int max = (srcCount - tgtCount);
for (int i = fromIndex; i <= max; i++) {
// 找到第一个匹配的字符
if (getChar(src, i) != first) {
while (++i <= max && getChar(src, i) != first);
}
// 找后面匹配的字符
if (i <= max) {
int j = i + 1;
int end = j + tgtCount - 1;
for (int k = 1;
j < end && getChar(src, j) == (tgt[k] & 0xff);
j++, k++);
if (j == end) {
// 子字符串匹配
return i;
}
}
}
return -1;
}
返回第一页。☝
☕物有本末,事有终始,知所先后。🍭
🍎☝☝☝☝☝我的CSDN☝☝☝☝☝☝🍓