文章目录
- Bean生命周期源码
- 生成BeanDefinition
- Spring容器启动时创建单例Bean
- 合并BeanDefinition
Bean生命周期源码
我们创建一个ApplicationContext对象时,这其中主要会做两件时间:包扫描得到BeanDefinition的set集合,创建非懒加载的单例Bean
public static void main(String[] args) {
// 创建一个Spring容器
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = (UserService) context.getBean("userService");
userService.test();
}
生成BeanDefinition
在线流程图
首先我们来看AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
// 构造DefaultListableBeanFactory、AnnotatedBeanDefinitionReader、ClassPathBeanDefinitionScanner
// 这里创建ClassPathBeanDefinitionScanner时,还会添加一个includeFilters,包含@Component注解
this();
register(componentClasses);
refresh();
}
接下来是refresh()方法
public void refresh() throws BeansException, IllegalStateException {
...
// 会拿到上一步创建的ClassPathBeanDefinitionScanner,调用scan方法进行包扫描
invokeBeanFactoryPostProcessors(beanFactory);
/// 会创建非懒加载单例bean
finishBeanFactoryInitialization(beanFactory);
...
}
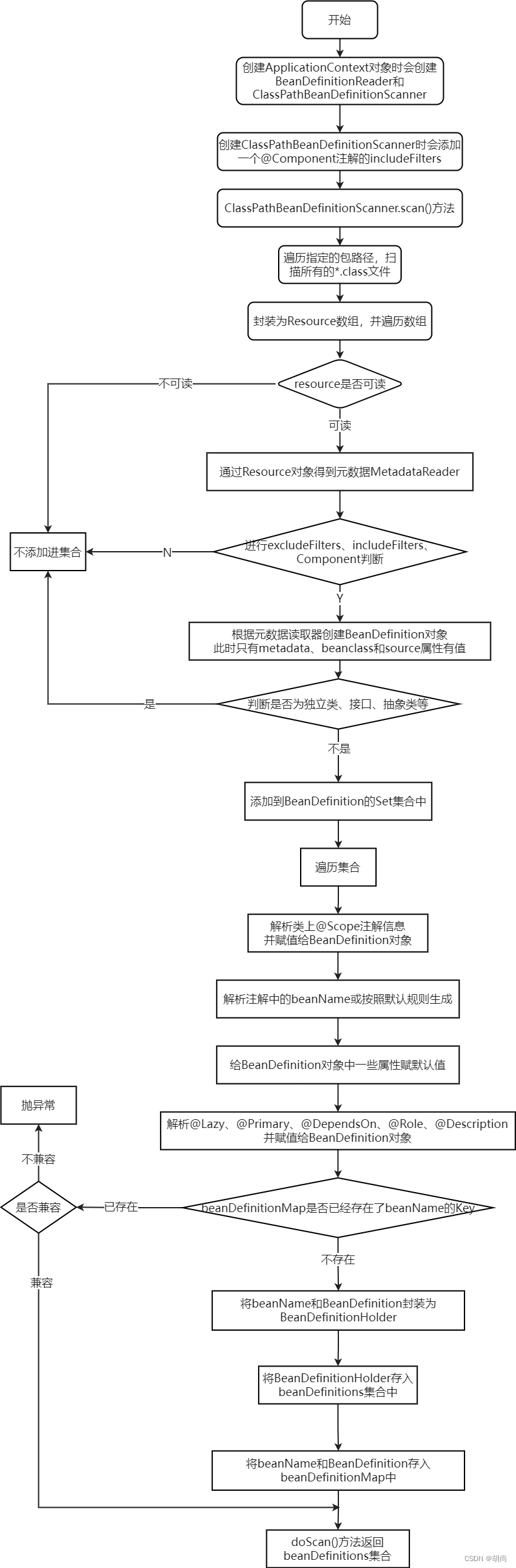
先看包扫描的逻辑,ClassPathBeanDefinitionScanner类主要做的事情就是包扫描完后再将得到的BeanDefinition注册进Spring容器中。
在scan(String... basePackages)方法中会调用doScan(String... basePackages)方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
// 创建一个set集合存放扫描到的BeanDefinition
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 可以传多个包路径,但我们一般都只传一个包路径
for (String basePackage : basePackages) {
// 调这个方法就会得到BeanDefinition集合,该方法扫描得到的BeanDefinition对象中主要只是有metadata、beanclass和source属性
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 遍历BeanDefinition集合,解析类的元数据信息为BeanDefinition的其他属性赋值
for (BeanDefinition candidate : candidates) {
// 解析类上@Scope注解信息
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 得到beanName,首先解析@Component注解中有没有指定beanName,如果没有指定再去按照默认是生成规则生成
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 包扫描的ScannedGenericBeanDefinition和AnnotatedGenericBeanDefinition,这两个BeanDefinition都满足下面两个if
if (candidate instanceof AbstractBeanDefinition) {
// 给BeanDefinition赋一些默认值
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 解析@Lazy、@Primary、@DependsOn、@Role、@Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查Spring容器beanDefinitionMap中是否已经存在该beanName,不存在才会走下面的if逻辑
if (checkCandidate(beanName, candidate)) {
// BeanDefinition中没有存beanName,而是把他们封装为了一个BeanDefinitionHolder对象
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
// 保存到set集合中
beanDefinitions.add(definitionHolder);
// 这里又从BeanDefinitionHolder取出beanName和BeanDefinition,把BeanDefinition注册进容器中的beanDefinitionMap中
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents(String basePackage)方法逻辑
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
// 我们可以定义一个resources/META-INF/Spring.components文件,然后就仅仅匹配个文件中指定的类与注解
// 而不扫描指定包路径下的所有*.class文件
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 我们创建的Spring项目一般会走这个逻辑
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents(String basePackage)方法逻辑,该方法扫描得到的BeanDefinition对象中主要只是有beanclass和source属性
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
// 返回值 存放BeanDefinition对象的Set集合
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 获取指定包路径下所有的*.class文件资源,将 com.hs 变为 classpath*:com/hs/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 封装为Resource对象
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍历每一个class文件资源对象
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
// 判断当前资源是否可读
if (resource.isReadable()) {
try {
// 得到元数据读取器
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// excludeFilters、includeFilters判断,判断类上是否有@Component,再去判断是否符合@Conditional
if (isCandidateComponent(metadataReader)) {
// 当上面的条件满足后,才会将当前类封装为BeanDefinition对象
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 这里还会对当前类进行进一步判断,这个条件满足之后才会将BeanDefinition对象添加进set集合中
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
... ...
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, ex);
}
}
else {
...
}
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
Spring容器启动时创建单例Bean
在线流程图网址
首先我们来看AnnotationConfigApplicationContext的构造方法
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
// 构造DefaultListableBeanFactory、AnnotatedBeanDefinitionReader、ClassPathBeanDefinitionScanner
// 这里创建ClassPathBeanDefinitionScanner时,还会添加一个includeFilters,包含@Component注解
this();
register(componentClasses);
refresh();
}
接下来是refresh()方法
public void refresh() throws BeansException, IllegalStateException {
...
// 会拿到上一步创建的ClassPathBeanDefinitionScanner,调用scan方法进行包扫描
invokeBeanFactoryPostProcessors(beanFactory);
/// 会创建非懒加载单例bean
finishBeanFactoryInitialization(beanFactory);
...
}
现在就跟finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory)方法
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
... ...
// 实例化非懒加载的单例Bean
beanFactory.preInstantiateSingletons();
}
最终创建的方法是preInstantiateSingletons()
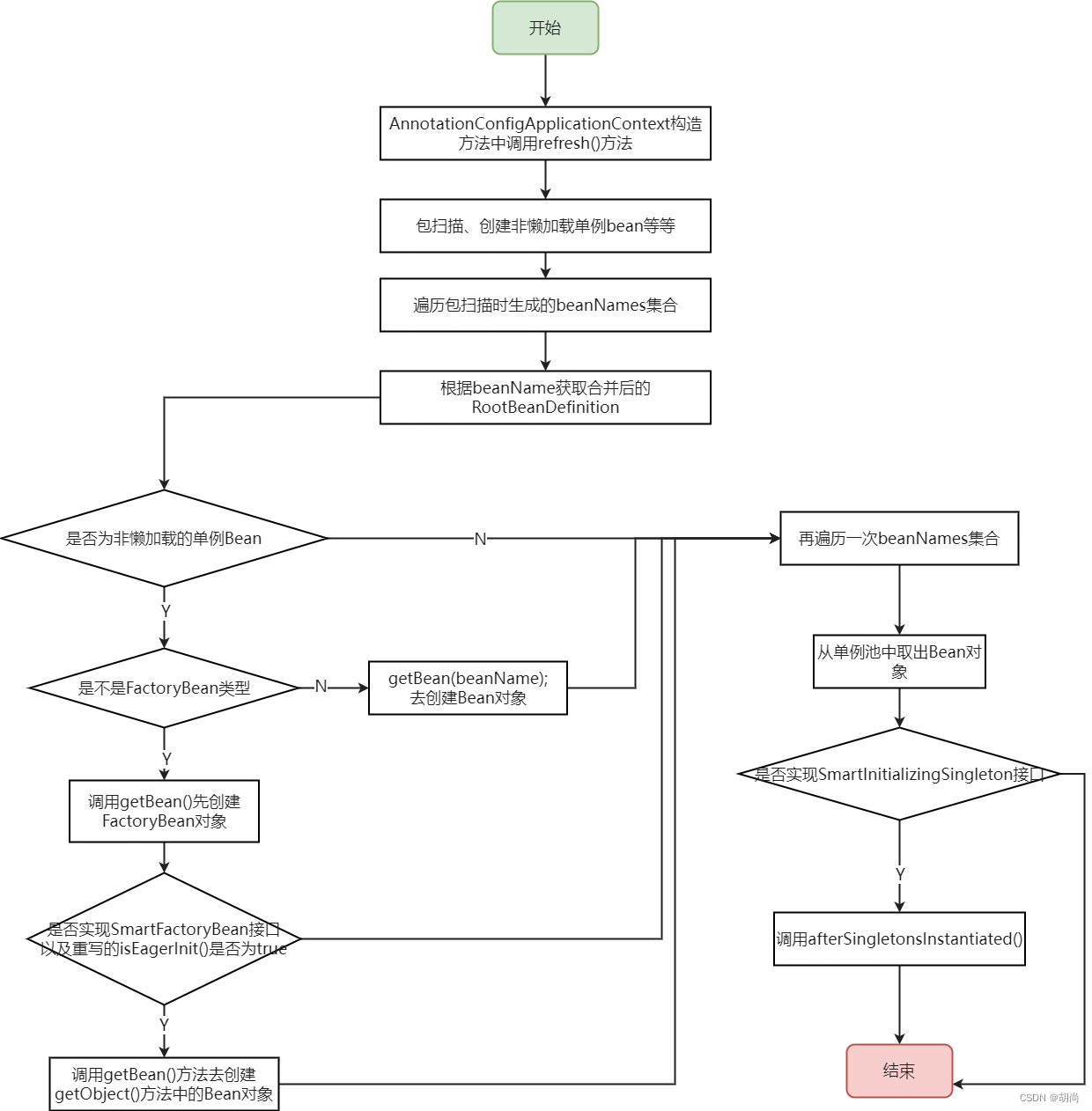
// 首先遍历beanNames集合,将包扫描时创建的BeanDefinition全部完成合并操作
// 判断非懒加载的单例bean
// 判断是不是FactoryBean,如果是则创建FactoryBean对象,如果不是则创建Bean对象
// 所有非懒加载单例Bean都存入单例池之后,再遍历一次beanNames集合,判断有没有实现SmartInitializingSingleton接口
public void preInstantiateSingletons() throws BeansException {
if (logger.isTraceEnabled()) {
logger.trace("Pre-instantiating singletons in " + this);
}
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 所以非懒加载单例Bean初始化
for (String beanName : beanNames) {
// 根据beanName 获取合并后的BeanDefinition
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 判断不是抽象的BeanDefinition、单例、不是懒加载
// 一般使用注解方式创建的Bean都不是抽象的,使用XML方式定义Bean时有一个abstract属性来指定
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断当前类是不是FactoryBean
if (isFactoryBean(beanName)) {
// 获取FactoryBean对象,加&前缀后获取的是factoryBean对象,而不是getObject()方法返回的对象
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
FactoryBean<?> factory = (FactoryBean<?>) bean;
// 判断当前类有没有实现SmartFactoryBean接口,如果实现了则调用isEagerInit()方法,将方法返回值赋值给isEagerInit
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(
(PrivilegedAction<Boolean>) ((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
// 所以我们一般实现FactoryBean接口,在Spring容器启动时是不会去创建getObject()方法的Bean对象
// 除非我们实现的是SmartFactoryBean接口重写isEagerInit()方法并返回true
if (isEagerInit) {
// 创建FactoryBean.getObject()方法返回的对象
getBean(beanName);
}
}
}
else {
// 一般的Bean都不是FactoryBean,就会直接调用getBean()方法去创建Bean对象
getBean(beanName);
}
}
}
// 所有的非懒加载单例Bean都创建完了后,又会进行一次遍历
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
// 判断当前已经创建好了的单例Bean有没有实现SmartInitializingSingleton接口,如果实现了则调用重写的afterSingletonsInstantiated()方法
if (singletonInstance instanceof SmartInitializingSingleton) {
StartupStep smartInitialize = this.getApplicationStartup().start("spring.beans.smart-initialize")
.tag("beanName", beanName);
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
smartInitialize.end();
}
}
}
合并BeanDefinition
通过扫描得到所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition
父子BeanDefinition实际用的比较少,使用是这样的,比如:
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child"/>
这么定义的情况下,child是单例Bean。
<bean id="parent" class="com.zhouyu.service.Parent" scope="prototype"/>
<bean id="child" class="com.zhouyu.service.Child" parent="parent"/>
但是这么定义的情况下,child就是原型Bean了。
因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。
如果child它自己定义了scope属性那么就用自己的,如果没有定义那么就用的parent的
之后child需要根据BeanDefinition来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition,也就是RootBeanDefinition。
上面的两行代码最终会生成四个BeanDefinition,合并之后不会在原BeanDefinition上修改,而是会创建一个RootBeanDefinition,会保存在mergedBeanDefinitions这个Map<String, RootBeanDefinition>中
我们现在所知的就有两个Map了:beanDefinitions、mergedBeanDefinitions。
在线流程图网址

底层源码是在AbstractBeanFactory类的 getMergedLocalBeanDefinition(String beanName)方法中进行合并的
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, @Nullable BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
RootBeanDefinition previous = null;
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null || mbd.stale) {
previous = mbd;
// 如果当前BeanDefinition没有指定parentName属性,那么就会根据当前BeanDefinition直接创建一个RootBeanDefinition
if (bd.getParentName() == null) {
// Use copy of given root bean definition.
if (bd instanceof RootBeanDefinition) {
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();
}
else {
mbd = new RootBeanDefinition(bd);
}
}
else {
// 如果当前BeanDefinition指定parentName属性那么走下面的逻辑
// pbd表示parentBeanDefinition,是父BeanDefinition,下面的逻辑是为pdb赋值,采用的方式的递归调用本方法
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());
if (!beanName.equals(parentBeanName)) {
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
BeanFactory parent = getParentBeanFactory();
if (parent instanceof ConfigurableBeanFactory) {
pbd = ((ConfigurableBeanFactory) parent).getMergedBeanDefinition(parentBeanName);
}
else {
throw new NoSuchBeanDefinitionException(...);
}
}
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanDefinitionStoreException(...);
}
// 子BeanDefinition的属性覆盖父BeanDefinition的属性,这就是合并
mbd = new RootBeanDefinition(pbd);
mbd.overrideFrom(bd);
}
// 如果scope没值就给默认值singleton
if (!StringUtils.hasLength(mbd.getScope())) {
mbd.setScope(SCOPE_SINGLETON);
}
if (containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()) {
mbd.setScope(containingBd.getScope());
}
// 将新创建的RootBeanDefinition存入Map集合中
if (containingBd == null && isCacheBeanMetadata()) {
this.mergedBeanDefinitions.put(beanName, mbd);
}
}
if (previous != null) {
copyRelevantMergedBeanDefinitionCaches(previous, mbd);
}
return mbd;
}
}