一. 概述

- 当前最为流行最受欢迎的Spring Boot,基于Spring Boot就可以快速方便的构建出一个Spring应用程序。
- Spring Framework,即Spring框架,是整个Spring家族当中最为底层,最为基础的一个框架。
- Spring Data封装了一系列访问数据库的技术。
- Spring Cloud用来构建微服务项目
- 以及Spring Security这样的安全框架
Spring发展到今天已经形成了一种开发生态圈,Spring提供了若干个子项目,每一个子项目都能够完成特定的功能来解决特定领域的问题,而我们在开发一个项目的时候,会遇到各种各样的业务场景,那我们会根据业务开发的需要取选择对应的技术,从而简化以及解决对应的业务难题。
而在现在的企业开发当中,开发人员更喜欢偏向于在项目当中选择Spring家族提供的这一系列的解决方案,为什么呢?
因为这些框架它都属于Spring体系内的框架,框架之间的整合会非常的容易,甚至可以说是无缝衔接,所以这是当前企业开发当中非常流行,也是非常受欢迎的一种解决方案,被我们亲切的称为Spring全家桶,而Spring家族开发的这么多子项目,其实它都是基于一个基础框架的,也就是这个Spring Framework,即Spring框架

基于Spring Boot就可以快速的来开发一个Spring的应用程序,在SpringBoot的介绍中也看到了,“尽可能快的来构建一个Spring应用”,所以这个Spring Boot它只是简化了Spring应用的配置,它的底层还是Spring,它只是简化了Spring的开发而已。
Spring家族旗下这么多的技术,最基础、最核心的是 SpringFramework。其他的spring家族的技术,都是基于SpringFramework的,SpringFramework中提供很多实用功能,如:依赖注入、事务管理、web开发支持、数据访问、消息服务等等。
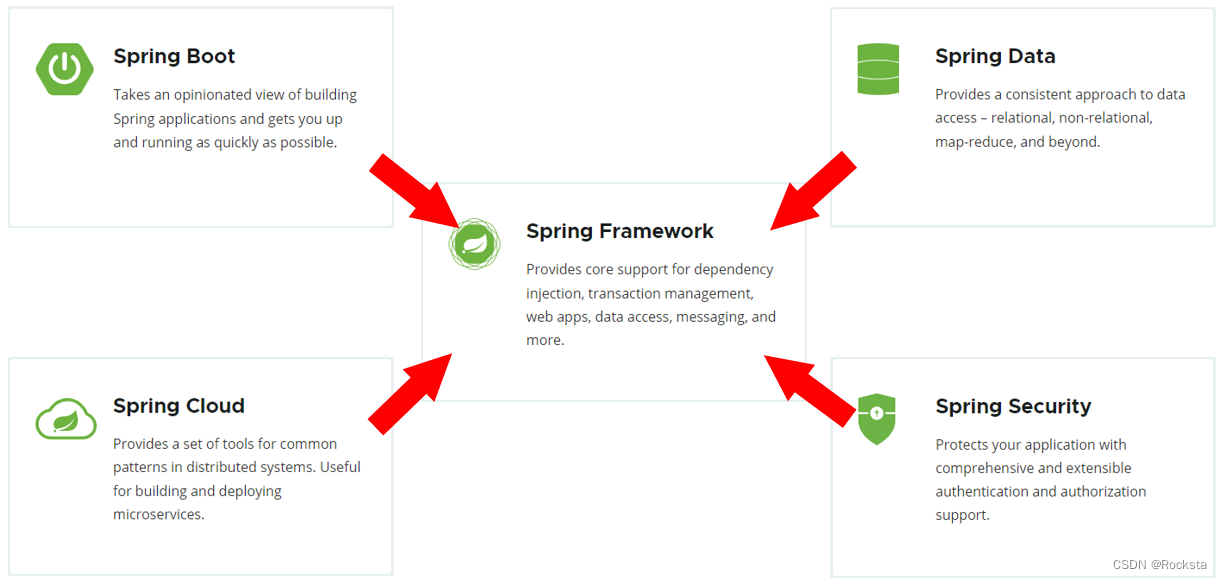
- 而如果我们在项目中,直接基于SpringFramework进行开发,存在两个问题:配置繁琐、入门难度大。

- 所以基于此呢,spring官方推荐我们从另外一个项目开始学习,那就是目前最火爆的SpringBoot。
- 总结Spring Boot框架:Spring Boot是Spring家族的一个子项目,可以帮助我们非常快速的构建Spring应用程序,简化Spring应用程序的配置开发,从而提高开发效率。
- 现在绝大部分的项目,都是基于Spring Boot进行开发的,所以这也是当前企业最为主流的开发方式。
二. Spring Boot Web
- 接下来,我们就直接通过一个SpringBoot的web入门程序,让大家快速感受一下,基于SpringBoot进行Web开发的便捷性。
- 基于Spring Boot进行Web应用程序开发的便捷性和基本的操作步骤
1. SpringBootWeb快速入门
1.1 需求
- 需求:基于SpringBoot的方式开发一个web应用,浏览器发起请求/hello后,给浏览器返回字符串 “Hello World ~”。
- 当我们在浏览器地址栏发起这个请求之后,这个请求要被我们所开发的web应用程序处理,处理完了以后,我们的web应用程序要给浏览器来返回一个字符串hello world,然后在浏览器当中展示出这个hello world即可,这个就是入门程序的需求。

1.2 开发步骤
第1步:创建SpringBoot工程项目
第2步:定义HelloController类,添加方法hello,并添加注解
第3步:测试运行
1.2.1 创建SpringBoot工程(需要联网)
- 基于Spring官方骨架,创建SpringBoot工程。
- 第一步:我们是基于SpringBoot进行web应用程序的开发,此时IDEA会自动连接Spring的官 网去创建SpringBoot工程。
-
Group组织名就是域名倒写 Artifact:模块名 Package name:包名 Artifact / 工件:模块名
Location:代表的就是我当前所创建出来的Spring Boot工程,最终放在哪个磁盘目录下呢?

- 基本信息描述完毕之后,勾选web开发相关依赖。
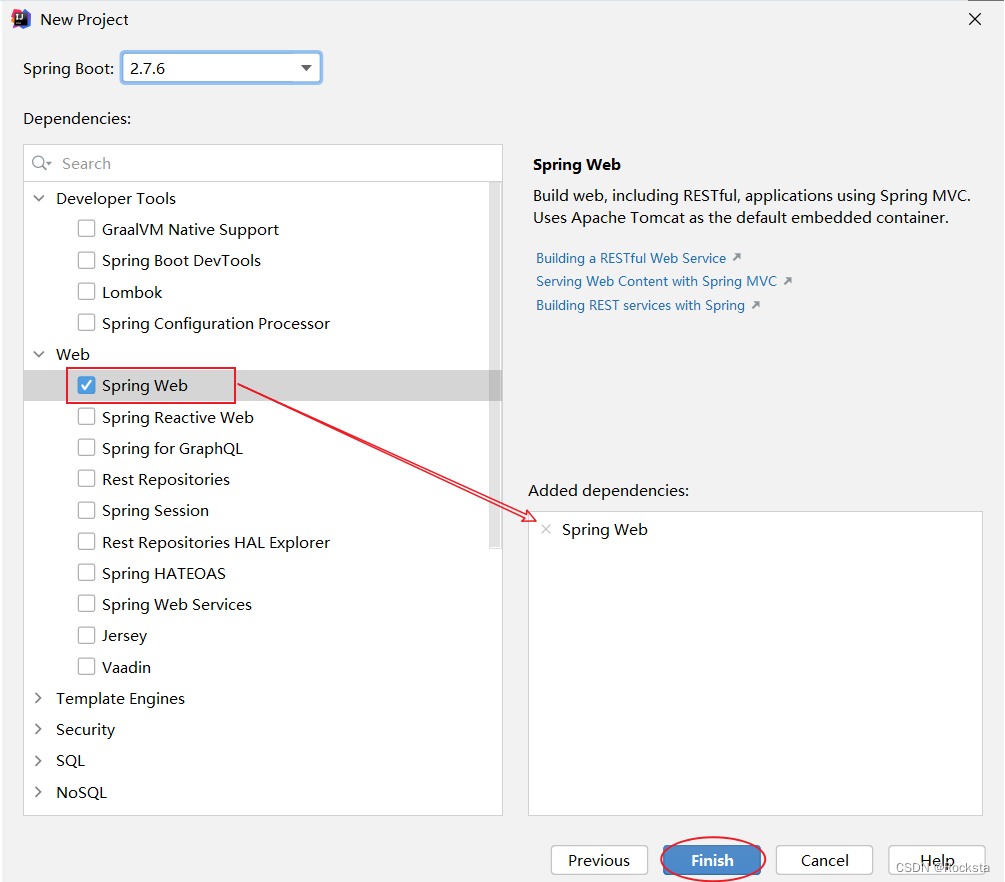
- 点击Finish之后,就会联网创建这个SpringBoot工程,创建好之后,结构如下:
- 注意:在联网创建过程中,会下载相关资源(请耐心等待)
- 下面的进度条会一直在加载,这个过程就是在下载Spring Boot进行web开发的相关依赖

pom.xml配置文件信息
- 首先我们先来看一下pom.xml这一份配置文件,在这份配置文件当中,最上面有这么一堆标签叫做parent,parent这里指定了一个坐标,这个是Spring Boot的父工程,我们把创建的所有的Spring Boot工程,它都需要继承自这个父工程,这个呢Maven当中叫做继承,就是来指定一个父工程
- 往下走这里就定义了我们当前项目的坐标信息,而下面这一块是项目的描述信息,以及我们所选择的Spring Boot版本所对应的JDK的版本是11版本。

- 那下面这一块就是添加了两个依赖,一个依赖就是Spring Boot进行Web开发的依赖
- 还有一个依赖是进行单元测试的依赖
- 再往下走还有一个插件,这个是Spring Boot项目的一个Maven插件

目录信息:
- 在java目录下给我们自动创建了一个类,这个类在Spring Boot当中我们称之为启动类。


1.2.2 定义请求处理类
- 在com.gch这个包下创建一个子包controller

- 然后在controller包下新建一个类:HelloController
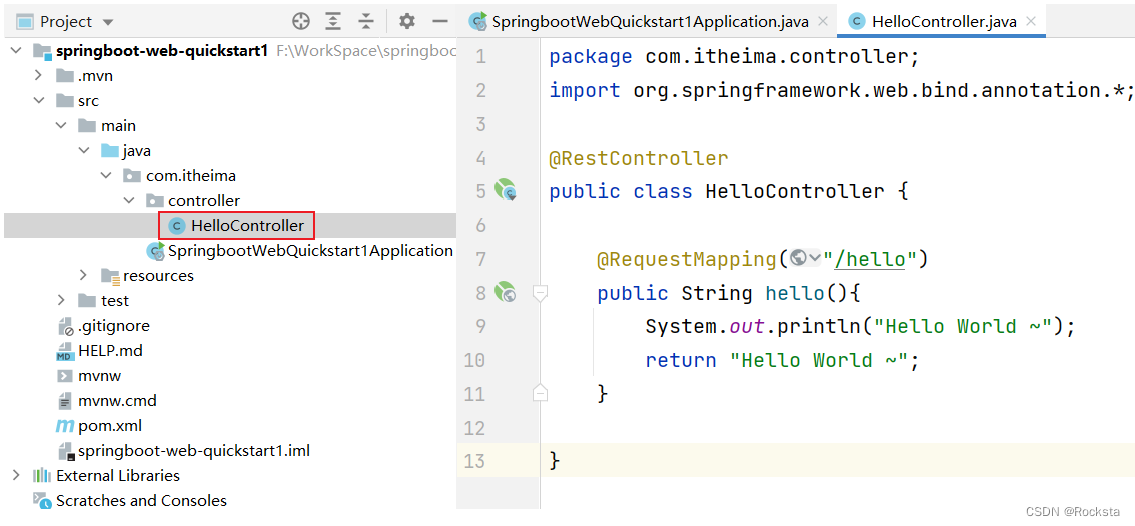
- 这个类定义好了,要标识它是一个请求处理类,还要指定它要处理的请求是/hello,所以需要 在这个类上加一个注解@RestController,然后在方法上再加上一个注解@RequestMapping,那RequestMapping里面指定的value值是它要处理的请求路径是什么,是/hello
package com.gch.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
请求处理类
*/
@RestController // 该注解用来标识当前类就是Spring当中的一个请求处理类而不是普通类
public class HelloController {
/**
* 请求处理方法
* @return:该方法的返回值就是我们要返回给浏览器的数据
* @RequestMapping注解是建立url路径跟我们这个方法之间的对应关系的
* 当我们的程序运行起来之后,它会自动的占用一个端口号8080,所以我们要想访问当前这个服务端的程序,将来要访问的端口号就是8080
* 协议://主机[:端口][/路径]
* http://localhost:8080/hello
* @RequestMapping里面指定的value值就是它要处理的请求路径是什么
*/
@RequestMapping("/hello") // 指定它要处理的请求路径,这个指的是浏览器将来请求/hello这个地址呢,最终就会调用这个方法
public String hello(){
System.out.println("Hello World~");
return "Hello World";
}
}
1.2.3 运行测试
- 运行SpringBoot自动生成的引导类
package com.gch;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 自动创建的这个类在SpringBoot当中我们称之为启动类
* 简单说这个类就是用来启动SpringBoot工程的
* 由于这个类的写法也是非常固定的,因此在创建SpringBoot工程的时候这个类已经给我们自动创建好了
*/
@SpringBootApplication
public class SpringbootWebQuickstartApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebQuickstartApplication.class, args);
}
}
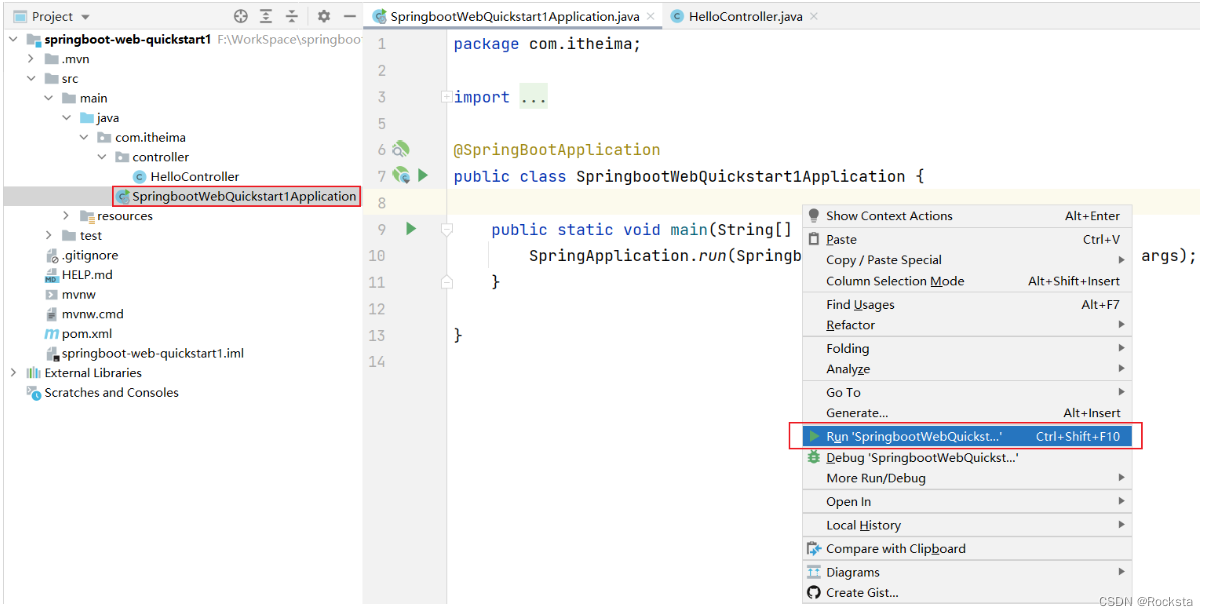
运行结果:
- 运行启动类,启动类将我们的web应用启动起来之后,它会自动占用一个端口号8080。

打开浏览器,输入 http://localhost:8080/hello 
- http代表的是请求的协议 localhost代表的是我们要访问的是当前本机的服务
- 8080代表的是我们访问的端口 Tomcat服务器的端口号就是8080
- /hello代表的就是访问的资源
- 打开浏览器,访问8080端口的/hello这个资源,那此时就会请求到刚才我们所编写的请求处理方法
- 当我们在浏览器地址栏发起这个请求之后,这个请求要被我们所开发的服务器端的web应用程序处理,处理完了以后,我们服务器端的web应用程序要给浏览器来返回一个字符串hello world,然后在浏览器当中展示出这个hello world即可,这个就是入门程序的需求。
三. Http协议
3.1 HTTP-概述

在入门程序中,我们在浏览器发起了一个请求,请求路径是localhost:8080/hello,回车之后,我们就访问到了服务器端的web应用程序,并且,也拿到了服务器端返回回来的数据:Hello World~。
那其实呢,我们在浏览器地址栏输入这个地址之后,浏览器默认会自动的在请求路径前面加上一个协议:http://,这个我们就称之为HTTP协议。

HTTP:Hyper Text Transfer Protocol(超文本传输协议),规定了浏览器与服务器之间数据传输 的规则。
2.1.1 介绍
什么是数据传输的规则:
说白了就是客户端浏览器与服务器之间进行数据交互的数据格式
- 比如我们客户端浏览器,将来要请求服务器来获取一些数据,那此时浏览器就需要给服务器端发送请求,那服务器端再给浏览器响应对应的数据,那么浏览器给服务器发送请求是需要携带请求数据,最起码你得告诉服务器,我需要什么东西,那服务器接收到这些请求数据之后,服务器就需要来解析这些数据,而服务器要想成功的解析数据,前提服务器得知道浏览器给我发送过来的请求数据长什么样子,具体的数据格式是什么样子的,每一项代表什么含义,否则,服务器端无法解析。
- 也就是说,浏览器和服务器之间,它们得建立好一个约定,我浏览器发送数据,将来就长这个样子,我就给你按照这个格式来写,服务器端你就按照这个格式解析就可以了,那这样呢,服务器端就能够知道客户端浏览器的意图了,那么同理,服务器端处理完请求之后,需要给客户端浏览器来响应一些数据,那响应的数据返回给客户端浏览器之后,浏览器也是需要来解析这些数据的,而浏览器要想成功解析,就必须得要求服务器按照一定的格式来返回这些数据,而这些数据传输的格式,都是在HTTP协议当中规定的,所以我们所说的这个http就是数据传输的规则,数据传输的格式,主要就包括两个方面,一个是请求数据的格式,一个是响应数据的格式。
- http是互联网上应用最为广泛的一种网络协议
- http协议要求:浏览器在向服务器发送请求数据时,或是服务器在向浏览器发送响应数据 时,都必须按照固定的格式进行数据传输
- Request Headers:请求的数据 Response Headers:响应的数据 View parsed:原始的数据格式
- 原始的数据格式其实就是一个文本字符串,将来浏览器发送请求的时候,就会将这么一个文本字符串带到服务器端去,而这个格式是非常固定的。

浏览器向服务器进行请求时:
- 服务器按照固定的格式进行解析
- 请求数据格式:
- 第一行叫做请求行,里面就指定了请求的方式是GET请求、请求的资源路径以及请求的协议。
- 第一行之后的这些被称之为请求头,而每一个请求头它的格式:前面是请求头的名字,后面是请求头的值,请求头的名字和请求头的值中间用:分隔开。
- 这个格式是固定的,将来浏览器就可以把这个数据发送到服务端,服务端就可以根据这个固定的格式来解析数据。

-
浏览器按照固定的格式进行解析
-
响应数据格式:
-
将来服务器端给浏览器响应的就是这样一个文本字符串,浏览器只需要按照指定的格式来解析就可以了。

所以,我们学习HTTP主要就是学习请求和响应数据的具体格式内容。
3.2 特点
 我们刚才初步认识了HTTP协议,那么我们在看看HTTP协议有哪些特点:
我们刚才初步认识了HTTP协议,那么我们在看看HTTP协议有哪些特点:
- 基于TCP协议: 面向连接,安全
TCP是一种面向连接的(建立连接之前是需要经过三次握手)、可靠的、基于字节流的传输层
通信协议,在数据传输方面更安全TCP它是一种面向连接的安全的协议,也就是说,每一次请求之前,要先进行三次握手,连接完了之后确定双方都有收发能力了,我再来传输数据,这样呢不容易数据包,更加安全。
- 基于请求-响应模型的: 一次请求对应一次响应(先请求后响应)
请求和响应是一一对应关系,如果没有请求,也就没有响应
- HTTP协议是无状态协议: 对于数据 / 事务处理没有记忆能力。每次请求-响应都是独立的。
所谓无状态指的是每一次请求响应都是独立的,后一次请求是不会记录前一次请求数据的。无状态指的是客户端浏览器发送 HTTP 请求给服务端之后,服务端根据请求响应数据,响应完后,不会记录任何信息。
- 缺点: 多次请求间不能共享数据(多次请求间不能进行数据的共享)
- 优点: 速度快
正是因为多次请求之间不会进行数据共享,后一次请求不会记录前一次请求的数据,这也就意味着它的速度会更快一些,而多次请求之间不能共享数据,那也就意味着有很多的功能,HTTP协议就实现不了。
就比如我这里有一个后台管理系统,在这个后台管理系统的业务需求当中就要求,必须用户登录之后才可以访问系统当中的数据,当我点击登录按钮执行登陆操作的时候,有一次请求响应,登陆完成之后进入系统,这一次请求响应结束,接下来我再来访问课程管理的数据,而当我点击课程管理的时候,它就要去访问课程的数据,而在访问课程数据的时候,我是需要知道这个用户到底有没有登录的,如果登录成功,我再给它返回课程的数据,如果没有登录成功,是不允许访问课程的数据,由于登录请求和访问课程管理数据的这个请求是两次不同的请求,而HTTP协议它又是无状态的,在两次请求之间,它是没办法共享数据的,那这也就造成了这一次课程管理的请求,它并不知道上一次用户是否登录成功了,那这就出现问题了。解决方案:web会话技术。
请求之间无法共享数据会引发的问题:
- 如:京东购物。加入购物车和去购物车结算是两次请求
- 由于HTTP协议的无状态特性,加入购物车请求响应结束后,并未记录加入购物车是何 商品
- 发起去购物车结算的请求后,因为无法获取哪些商品加入了购物车,会导致此次请求无 法正确展示数据
具体使用的时候,我们发现京东是可以正常展示数据的,原因是 Java 早已考虑到这个问题,并提出了使用会话技术 (Cookie 、 Session) 来解决这个问题。
刚才提到HTTP协议是规定了请求和响应数据的格式,那具体的格式是什么呢?
重点:请求数据的格式和响应数据的格式
3.2 HTTP-请求协议
 浏览器和服务器是按照HTTP协议进行数据通信的。
浏览器和服务器是按照HTTP协议进行数据通信的。
HTTP协议又分为:请求协议和响应协议
-
请求协议:浏览器将数据以请求格式发送到服务器
-
包括:请求行、请求头 、请求体
-
-
响应协议:服务器将数据以响应格式返回给浏览器
-
包括:响应行 、响应头 、响应体
-
在HTTP1.1版本中,浏览器访问服务器的几种方式:
| 请求方式 | 请求说明 |
|---|---|
| GET | 获取资源。 向特定的资源发出请求。例:百度安全验证 |
| POST | 传输实体主体。 向指定资源提交数据进行处理请求(例:上传文件),数据被包含在请求体中。 |
| OPTIONS | 返回服务器针对特定资源所支持的HTTP请求方式。 因为并不是所有的服务器都支持规定的方法,为了安全有些服务器可能会禁止掉一些方法,例如:DELETE、PUT等。那么OPTIONS就是用来询问服务器支持的方法。 |
| HEAD | 获得报文首部。 HEAD方法类似GET方法,但是不同的是HEAD方法不要求返回数据。通常用于确认URI的有效性及资源更新时间等。 |
| PUT | 传输文件。 PUT方法用来传输文件。类似FTP协议,文件内容包含在请求报文的实体中,然后请求保存到URL指定的服务器位置。 |
| DELETE | 删除文件。 请求服务器删除Request-URI所标识的资源 |
| TRACE | 追踪路径。 回显服务器收到的请求,主要用于测试或诊断 |
| CONNECT | 要求用隧道协议连接代理。 HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
在我们实际应用中常用的也就是 :GET、POST

- 请求协议指的就是请求数据的格式
- 那这个请求数据的格式,我们刚才已经看到了,就是一些文本字符串
- 请求数据的格式分为三个部分:请求行、请求头、请求体
- 首先请求数据格式的第一个部分:请求行,请求行指的是请求数据格式的第一行,而这个请求行它又是由三个部分组成的(请求方式、资源路径、协议/版本):
- 第一个部分就是这个GET,POST,这是第一部分,那这个指的是请求方式。这个请求方式,之前在讲解HTML的form表单的时候说过,这个表单的方式有两种,一种是GET,一种是POST,那其实GET和POST就是HTTP的请求方式,当然HTTP的请求方式有很多,我们这里先知道GET和POST就可以了。
- /请求路径?请求参数 请求路径和请求参数之间使用?连接
- 请求参数格式:参数名=参数值&参数名=参数值
- 请求方式之后,有一个空格,空格后面就是第二个部分的内容:/brand/findAll请求路径后面跟上的是请求的参数,那这个部分指的是请求的资源路径。
- 那资源路径之后,又有一个空格,空格之后就是第三个部分:HTTP/1.1,这个代表的是协议以及协议的版本。
- 以上就是请求数据格式的第一部分请求行的格式。
2. 请求数据格式的第二个部分:请求头(第二行开始,格式:key=value)
- 请求头指的就是从第二行开始,一直到后面的这一部分数据,请求头的格式是key:value形式的键值对。
- 前面的这个部分指的是请求头的名字,后面这部分指的是请求头对应的值,中间使用:进行分隔。
- http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
- 在请求头当中携带了很多的信息,包括浏览器的版本,请求的主机地址,请求的数据格式等等。
- 接下来,介绍一下常见的请求头它所代表的含义:

- Host:localhost:8080,代表的是我们要请求的是当前本机的8080端口的服务。
- User-Agent:代表的是浏览器的版本,也就是说客户端浏览器它得告诉服务器端,我当前请求用的是哪一个浏览器,我的版本是什么。
- 那告诉服务器端这个浏览器版本有什么用呢?
- 这个地方一般会用于浏览器的兼容性处理。
- 因为市面上有很多的浏览器,而不同的浏览器它们的内核是有差异的,这就造成了同一段程序在不同的浏览器解析出来,它的效果是不一样的,这个呢,我们称之为浏览器的兼容性问题。
- 那我们在服务器端,如果拿到了客户端浏览器的版本,我就可以有针对性的进行处理,从而保证不论你采用什么样的浏览器,你最终访问到的效果都是一样的,那这就是解决浏览器的兼容性问题。
- 而解决浏览器的兼容性问题,最核心的就是我们在服务器端得拿到浏览器的版本。
- Accept:text/*:表示我浏览器期望接收的是一个文本;image/*:表示我浏览器期望接收的是一个图片
- Accept-Language:zh-CN,比如我这里传递了一个zh-CN,这就相当于我浏览器告诉服务器端,我浏览器期望接收到的是简体中文的语言。
- Accept-Encoding:gzip,代表我浏览器可以接收gzip的压缩格式
- Content-Type:application/json,就代表请求体的格式,它是一个json格式的数据。
- Content-Length:161,就代表这个请求体的大小是161个字节。
3. 请求数据格式的第三个部分:请求体(POST请求,存放请求参数)
- 请求体是POST请求特有的一个组成部分,POST请求最后一个部分就是请求体,它是用来存放请求参数的。
- 在这个请求体和请求行之间是有一个空行存在的,通过一个空行将这两部分分离开来- - (作用:用于标记请求头结束)。
- 而在POST请求里面,它就把请求参数放在了请求体这个位置,那之前我们在讲解HTML的form表单的时候,我们就介绍过,GET请求和POST请求的区别,在这里我们再来回顾一下:
- 在GET请求当中,请求参数是在请求行当中的,具体的表现形式,就是在请求路径之后跟上?key=value,如果有多个参数,后面再跟上&key=value的形式。而GET请求它是没有请求体的,并且它的请求大小是有限制的。
- 而如果是POST请求,它的请求参数是携带在请求体当中,它的请求大小没有限制。






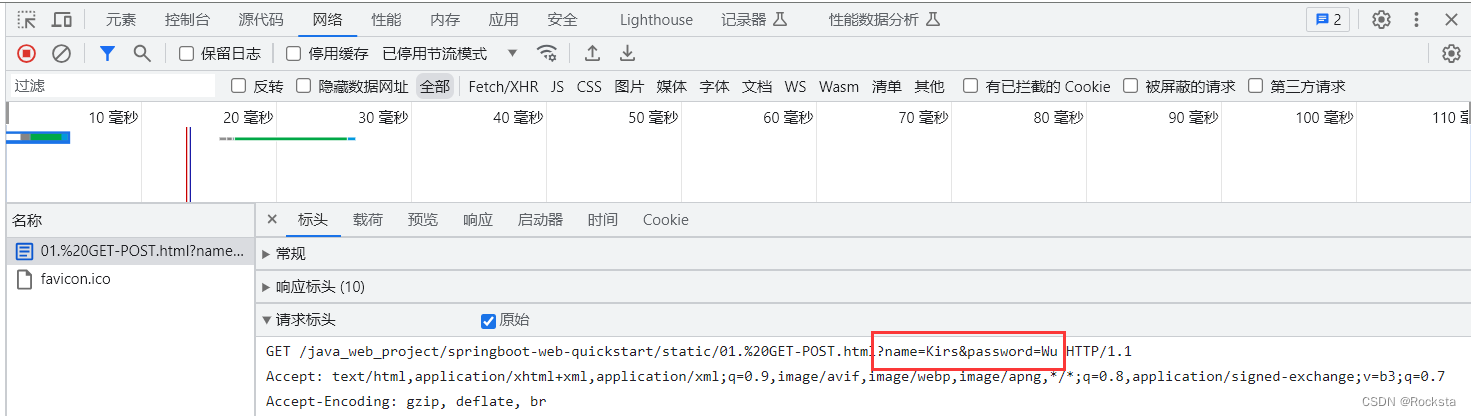
一. GET方式的请求协议:

请求行 :HTTP请求中的第一行数据。由:请求方式、资源路径、协议/版本组成(之间使用空格分隔)
-
请求方式:GET
-
资源路径:/brand/findAll?name=OPPO&status=1
-
请求路径:/brand/findAll
-
请求参数:name=OPPO&status=1
-
请求参数是以key=value形式出现
-
多个请求参数之间使用
&连接
-
-
请求路径和请求参数之间使用
?连接
-
-
协议/版本:HTTP/1.1
请求头 :第二行开始,上图黄色部分内容就是请求头。格式为key: value形式
常见的HTTP请求头有:
- Host: 表示请求的主机名
- User-Agent: 浏览器版本。 例如:Chrome浏览器的标识类似Mozilla/5.0 ...Chrome/79 ,IE浏览器的标识类似Mozilla/5.0 (Windows NT ...)like Gecko
- Accept:表示浏览器能接收的资源类型,如text/*,image/*或者*/*表示所有;
- Accept-Language:表示浏览器偏好的语言,服务器可以据此返回不同语言的网页;
- Accept-Encoding:表示浏览器可以支持的压缩类型,例如gzip, deflate等。
- Content-Type:请求主体的数据类型
- Content-Length:数据主体的大小(单位:字节)
-
http是个无状态的协议,所以在请求头设置浏览器的一些自身信息和想要响应的形式。这样服务器在收到信息后,就可以知道是谁,想干什么了
举例说明:服务器端可以根据请求头中的内容来获取客户端浏览器的相关信息,有了这些信息服务器端就可以处理不同的业务需求。
比如:
不同浏览器解析HTML和CSS标签的结果会有不一致,所以就会导致相同的代码在不同的浏览器会出现不同的效果
服务器端根据客户端请求头中的数据获取到客户端的浏览器类型,就可以根据不同的浏览器设置不同的代码来达到一致的效果(这就是我们常说的浏览器兼容问题)
请求体 :存储请求参数
-
GET请求的请求参数在请求行中,故不需要设置请求体
二. POST方式的请求协议:
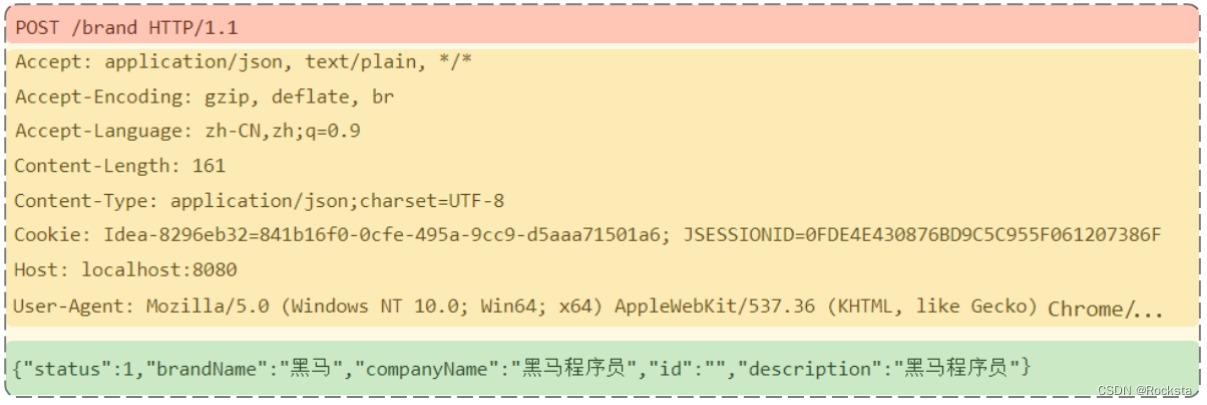
-
请求行(以上图中红色部分):包含请求方式、资源路径、协议/版本
-
请求方式:POST
-
资源路径:/brand
-
协议/版本:HTTP/1.1
-
-
请求头(以上图中黄色部分)
-
请求体(以上图中绿色部分) :存储请求参数
-
请求体和请求头之间是有一个空行隔开(作用:用于标记请求头结束)
-
GET请求和POST请求的区别:
| 区别方式 | GET请求 | POST请求 |
|---|---|---|
| 请求参数 | 请求参数在请求行中。 例:/brand/findAll?name=OPPO&status=1 | 请求参数在请求体中 |
| 请求参数长度 | 请求参数长度有限制(浏览器不同限制也不同) | 请求参数长度没有限制 |
| 安全性 | 安全性低。原因:请求参数暴露在浏览器地址栏中。 | 安全性相对高 |
演示:GET请求与POST请求
- 在IDEA当中,我已经准备好了一个HTML页面
- 在这个HTML页面当中我定义了两个form表单,在这个form表单当中的表单项是完全一致的,只是它们的提交方式不一样,第一个表单它的提交方式是GET,第二个表单提交方式是POST
点击IDEA的悬浮工具条,然后选择一个浏览器打开


GET方式提交:

POST方式提交:


3.3 HTTP-响应协议

3.1 格式介绍
- HTTP协议响应数据的格式
- 响应协议也就是响应数据的格式,响应数据的格式与请求数据的格式非常的类似,也是由三个部分组成的,分别是响应行、响应头和响应体
- 与HTTP的请求一样,HTTP响应的数据也分为3部分:响应行、响应头 、响应体


- 响应行:响应行(以上图中红色部分):响应数据的第一行。
- 响应行也是由三个部分组成的,响应行由"协议及协议的版本"、"响应状态码"、"状态码描述"组成。
-
协议/版本:HTTP/1.1
-
第一个部分就是HTTP/1.1,这个代表的是就是协议以及协议的版本
-
响应状态码:200
-
第一部分之后有一个空格,空格之后是第二部分是一个数字,这个数字就代表了响应的状态码,这个状态码指的就是服务器端要告诉客户端这次响应到底是怎么样的状态,是成功还是失败。这里所出现的200代表的是成功。
-
状态码描述:OK
-
第二个部分之后又有一个空格,空格之后是第三个部分,它是一个英文,这个英文就是用来描述前面的状态码的。这里的OK就代表成功了。
-
其实这个状态码有很多,而我们一般会将其分为五类,分别从100多一直到500多。
2. 响应头(以上图中黄色部分):响应数据的第二行开始。格式为key:value形式。
- 响应头当中是用来描述响应信息的。
- 从第二行开始以key:value形式体现出来的这一块数据都是响应头的数据。
3. 响应体(以上图中绿色部分): 响应数据的最后一部分。存储响应的数据
- 响应体当中存储的就是响应回来的数据,响应体是整个响应数据的最后一个部分
- 跟请求体一样,响应体和响应头之间有一个空行隔开(作用:用于标记响应头结束)
- 响应体我们一般也叫响应正文,这个里面所展示的这个JSON格式的数据,就是响应正文的内容,将来,浏览器解析到这些数据之后,再配合着前端的代码实现,就可以展示对应的页面信息了。
响应状态码:

- 响应状态码的分类:
- 在HTTP协议当中,响应的状态码大概分为这么五类,分别是100多,200多,一直到500多。
- 100多代表的是响应中,它是一个临时状态码。
- 其实就是说,服务器端已经接收到了客户端的请求,但是服务器端发现客户端的请求还没有发送完整,服务器端先给客户端一个临时的响应状态码,告诉客户端你要继续发送完整的请求数据。
- 这一类的响应状态码比较少见,大家在后面的项目当中可能会用到一个技术叫Web Socket,拿使用Web Socket的时候,就会发现它的状态码就是100多,是101,目前这个了解即可。
- 200多这个状态码代表的是成功,成功的意思是这一次的请求响应已经被成功的接收和处理了,已经处理完成了,那我给你返回一个200多。客户端发送了请求,服务端已经成功的处理了这个请求并且响应也是成功的,那这个是我们最想看到的状态码,这也是每一个软件工程开发师的幸运数字。
- 那这个状态码是我们开发人员最希望看到的一个状态码。
- 第三类是300多,300多代表的是重定向的状态码。

- 所谓重定向它的含义指的是这里呢,有一个客户端浏览器,客户端浏览器要去访问A服务器上的资源,接下来呢,它要发送请求到A服务器,但是这个资源已经被我挪到了另外一个服务器B服务器当中,那么此时A服务器就可以给浏览器返回一个状态码就是300多,并且呢,在这个状态码里面告诉浏览器,你再去访问B服务器上的这个资源就可以,那此时浏览器拿到响应回来的状态码以及响应回来的这个路径之后,接下来,浏览器会自动的再去请求B服务器上的资源,从而获得响应数据,那这个过程是浏览器自动完成的,那这个呢,我们就称之为重定向。
- 当然,在这幅图当中A和B有可能是同一台服务器,只是资源的位置不用而已。
- 接下来的这两类状态码400多和500多比较常见也比较重要,它们都代表的是错误的情况。
- 那将来我们在开发项目的时候,只有你知道了这些状态码的含义,你才能够知道具体的错误到底出现在什么位置,我们才能够知道怎么来解决这些错误。
- 400多代表的是客户端错误。
- 客户端错误指的是处理发生错误了,责任是在客户端的。比如,我们随便在浏览器的地址栏当中输入一个地址,那这个地址如果不存在,此时就会出现一个状态码,那就是400多,那一旦出现了400多的状态码,那我就知道,这个问题是在客户端。那我就需要去检查客户端的请求路径,检查客户端的请求参数,然后把它们改正确就可以了。
- 最后一类500多指的是服务器错误。
- 服务器错误代表的是如果将来处理发生错误,责任在服务端。
- 那比如我们在访问我们的Web程序时,由于代码的Bug出现了一个异常,那此时就会响应一个500多的状态码,那看到这个状态码之后,我们就知道这个问题出现在服务端,那我需要去检查一下服务端的日志,去看一下是否有异常产生,然后再依据异常的堆栈信息,把对应的异常解决掉就可以了。
常见的响应状态码:
- 200它表示的是OK,OK它所代表的意思就是客户端发送了请求,服务端已经成功的处理了这个请求并且响应也是成功的。这个是我们最想看到的状态码,也是每一个软件开发工程师的幸运数字。
- 302表示的是重定向,就是说客户端浏览器请求的资源已经转移到了另外一个位置,那这个位置,我服务器可以通过一个响应头Location返回给你,告诉你对应的URL地址,那么浏览器拿到这个状态码之后并且拿到了响应头Location,它就会自动的去请求Location这个响应头对应的请求路径,然后再去获取这个页面的资源,那这就是302状态码。
- 还有一个304状态码,它的意思就是服务器端要告诉客户端你所请求的这个资源自上次请求以后我服务器端并没有做任何的修改,你可以直接去访问你自己的本地缓存就可以了,就不用再访问服务器再来获取这个资源了。那此时,服务器的压力就减轻了,因为就不存在数据传输的过程了。
- 400表示的是Bad Request,Bad Request指的就是客户端的请求语法有错误,不能被服务器理解,比如客户端所传递的请求参数,格式错误等等,那此时就会出现400这个状态码。
- 403指的是服务器端接收到了请求,但是拒绝访问,一般来说,都是因为你没有权限来访问这个资源,那我就给你返回一个403。
- 404是我们将来所见到的客户端最为常见的一个错误,叫Not Found,Not Found代表的是你所请求的资源不存在,那一般呢,就是我们输入的请求路径是有误的,或者网站资源被删除了,找不到这个网站资源了。
- 405代表的是请求方式有误。比如,我们服务端所提供的这个请求的资源,它要求必须以GET方式来请求,而我们使用的是POST的请求方式,那这个时候,就会出现405,请求的方法不被允许。
- 428代表的是服务器要求有条件的请求。那这个指的意思就是说当我们去访问一个服务端的资源的时候,它要求我们必须要携带对应的一些条件,比如我们要携带一些特定的请求头,如果我携带了这个请求头,它才允许我访问,那如果我们没有携带,那此时就会返回一个状态码428。
- 429代表的是请求数太多了,那这个代表的是用户在指定的时间内发送了太多的请求,造成服务器的压力比较大,那这个时候就会出现429。429可以配合这一个响应头叫做Retry-After,代表的是在多长时间以后,我们可以再次尝试请求。
- 431指的就是我们所请求的数据,请求头的字段太多了,服务器不愿意处理。
- 500也是我们将来见的比较多的一类状态码,如果是5开头的,都代表的是服务器端异常。
- 500代表的是服务器端发生了不可预期的错误,一般都是服务器端抛异常了,那如果出现500,我们就需要去看一下服务器端的日志,来看一下在控制台当中是不是出现了异常,如果出现异常,我们需要去解决这个问题。500代表的是服务器端发生了异常或者是错误。
- 503指的是服务器尚未准备好处理请求。比如我们服务器刚刚启动,我还没有启动完成呢,浏览器发起了一个请求,那此时就会报出503。
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| 200 | OK | 客户端请求成功,即处理成功,这是我们最想看到的状态码 |
| 302 | Found | 指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified | 告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 |
| 400 | Bad Request | 客户端请求有语法错误,不能被服务器所理解 |
| 403 | Forbidden | 服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 |
| 404 | Not Found | 请求资源不存在,一般是URL输入有误,或者网站资源被删除了 |
| 405 | Method Not Allowed | 请求方式有误,比如应该用GET请求方式的资源,用了POST |
| 428 | Precondition Required | 服务器要求有条件的请求,告诉客户端要想访问该资源,必须携带特定的请求头 |
| 429 | Too Many Requests | 指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 |
| 431 | Request Header Fields Too Large | 请求头太大,服务器不愿意处理请求,因为它的头部字段太大。请求可以在减少请求头域的大小后重新提交。 |
| 500 | Internal Server Error | 服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 |
| 503 | Service Unavailable | 服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 |
常见的HTTP响应头有:

- Content-Type:表示该响应内容的类型。比如我们这里响应了一个内容,它的类型是一个json,所以在Content-Type这一栏显示的就是:application/json。那将来客户端浏览器获取到这个数据之后,它就会按照json格式的数据来处理。
- Content-Length:指的是响应内容的长度(单位是字节)。那通过这个响应头客户端就能知道服务器给我响应回来的数据它的长度到底是多长。
- Content-Encoding:表示该响应数据的压缩算法。比如我们这里设置了一个gzip,那这就表示服务器端在传输数据的时候采用的是gziip的算法进行压缩的,那将来客户端拿到数据之后也要使用gzip的算法来进行解压缩。
- Cache-Control:指示客户端应如何缓存。缓存的意思就是你第一次在访问的时候你访问服务器,把服务器返回的数据,缓存在浏览器本地,下一次你再来访问的时候,你就不用再请求服务器了,你直接读本地的文件,这样速度会更快一些,而且也会降低服务器端的压力。在设置客户端如何缓存的时候,可以设置这么一块信息,叫做max-age=300,这就代表我缓存这一块的这个数据,最多只存储300秒,300秒之后缓存的数据就没了,那我就需要再次请求服务器端再来获取数据。
- Set-Cookie: 告诉浏览器为当前页面所在的域设置cookie。什么是cookie在后面介绍Web会话技术的时候再来详细介绍。(cookie是指储存在用户本地终端上的数据,是基于网络浏览器的一种机制,它的作用是存储用户的上网行为信息,以便在以后的网页浏览中给予相应的个性化服务。)

3.4 HTTP-协议解析
- HTTP协议的解析就是根据HTTP的请求格式来解析请求数据以及响应数据。
- 解析HTTP协议,其实分为两个部分,一个是客户端,一个是服务端。
- 而对于客户端浏览器,各大厂商已经给我们提供了,它里面就内置了解析HTTP协议的程序,我们不需要操作。我们作为一名服务端开发工程师,需要做的就是在服务器端通过Java程序来接收客户端浏览器发起的请求,并获取请求数据,然后,再参照HTTP协议的请求数据格式对请求数据进行解析,然后还需要参照HTTP协议的响应数据格式给浏览器再响应对应的数据。
- 刚才我们提到在浏览器里面就已经内置了解析HTTP协议的程序,那浏览器获取到响应回来的数据之后会自动解析,从而完成这一次请求响应。
- 接下来我们就需要去研究一下,在服务器端我们怎么样解析HTTP的数据,并且给浏览器响应数据。
- 其实按照我们目前的知识储备,我们是可以把这个程序写出来的。在TCP网络编程这样的技术中,我们可以通过Socket以及Server Socket就可以写出一个服务器端的程序了,然后浏览器就可以来发送HTTP的请求,我们就可以通过ServerSocket来接收客户端发起的这个请求,那接收到请求之后,我们就可以获取到这个请求的数据,那读取出来的请求数据呢就是一些字符串,而这个字符串,它的格式我们前面学过是固定的,那我们就可以按照字符串的组成规则来解析它,同理,我们也可以通过ServerSocket来获取到输出流,然后就可以按照HTTP响应数据的格式给浏览器,响应一个固定格式的字符串,那这样呢,就完成了一次网络请求。
- 服务器是可以使用java完成编写,是可以接受页面发送的请求和响应数据给前端浏览器的,而在开发中真正用到的Web服务器,我们不会自己写的,都是使用目前比较流行的web服务器。如:Tomcat
- 我们所开发的Web程序要解析HTTP协议,那其他所有的Web项目要开发,也都需要去解析HTTP协议,而HTTP协议它是标准的,是统一固定的,所以这部分解析HTTP协议的代码也是非常通用的,所以有很多公司已经把这些代码都已经写好了,而且还封装到了一个软件程序当中供我们来使用,而这个软件就是我们所说的Web服务器。
- Web服务器软件有很多,其中最为流行也是最受欢迎的就是阿帕奇基金会下的Tomcat服务器。
- 这些Web服务器本质上就是一个软件程序,就是对HTTP协议进行了封装,使程序员不必直接对HTTP协议进行操作,因为毕竟是比较繁琐的,也就是说,如果有了这些Web服务器,HTTP协议的解析和处理的代码,我们都不用去做了,开发人员只需要关注我们当前项目的业务实现逻辑就可以了,这样使得Web程序的开发更加简单,更加便捷,也更加高效。