一.区别
几乎所有的操作系统都支持同时运行多个任务,每个任务通常是一个程序,每一个运行中的程序就是一个进程,即进程是应用程序的执行实例。现代的操作系统几乎都支持多进程并发执行。
注意,并发和并行是两个概念,并行指在同一时刻有多条指令在多个处理器上同时执行;并发是指在同一时刻只能有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。
但事实的真相是,对于一个 CPU 而言,在某个时间点它只能执行一个程序。也就是说,只能运行一个进程,CPU 不断地在这些进程之间轮换执行。那么,为什么用户感觉不到任何中断呢?
这是因为相对人的感觉来说,CPU 的执行速度太快了(如果启动的程序足够多,则用户依然可以感觉到程序的运行速度下降了)。所以,虽然 CPU 在多个进程之间轮换执行,但用户感觉到好像有多个进程在同时执行。
线程是进程的组成部分,一个进程可以拥有多个线程。在多线程中,会有一个主线程来完成整个进程从开始到结束的全部操作,而其他的线程会在主线程的运行过程中被创建或退出。
当进程被初始化后,主线程就被创建了,对于绝大多数的应用程序来说,通常仅要求有一个主线程,但也可以在进程内创建多个顺序执行流,这些顺序执行流就是线程。
当一个进程里只有一个线程时,叫作单线程。超过一个线程就叫作多线程。
每个线程必须有自己的父进程,且它可以拥有自己的堆栈、程序计数器和局部变量,但不拥有系统资源,因为它和父进程的其他线程共享该进程所拥有的全部资源。线程可以完成一定的任务,可以与其他线程共享父进程中的共享变量及部分环境,相互之间协同完成进程所要完成的任务。
多个线程共享父进程里的全部资源,会使得编程更加方便,需要注意的是,要确保线程不会妨碍同一进程中的其他线程。
线程是独立运行的,它并不知道进程中是否还有其他线程存在。线程的运行是抢占式的,也就是说,当前运行的线程在任何时候都可能被挂起,以便另外一个线程可以运行。
多线程也是并发执行的,即同一时刻,Python 主程序只允许有一个线程执行,这和全局解释器锁有关系。
一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发运行。
从逻辑的角度来看,多线程存在于一个应用程序中,让一个应用程序可以有多个执行部分同时执行,但操作系统无须将多个线程看作多个独立的应用,对多线程实现调度和管理以及资源分配,线程的调度和管理由进程本身负责完成。
简而言之,进程和线程的关系是这样的:操作系统可以同时执行多个任务,每一个任务就是一个进程,进程可以同时执行多个任务,每一个任务就是一个线程。当然,不同进程中的线程也能并发执行
总结:
线程:cpu调度的最小单元,线程依赖于进程,线程间数据共享,开销小。
也叫轻量级进程,它被包涵在进程之中,是进程中的实际运作单位。线程是程序中一个单一的顺序控制流程。进程内一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位即运行中的程序的调度单位
线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
进程:一个运行的程序就是一个进程,系统分配资源的最小单元,进程的内存空间相互独立,开销大
二.线程的创建
python中,有关线程开发的部分被单独封装到了模块中,和线程相关的模块有以下 2 个:
- _thread:是 Python 3 以前版本中 thread 模块的重命名,此模块仅提供了低级别的、原始的线程支持,以及一个简单的锁。功能比较有限。正如它的名字所暗示的(以 _ 开头),一般不建议使用 thread 模块;
- threading:Python 3 之后的线程模块,提供了功能丰富的多线程支持,推荐使用。
本文就以 threading 模块为例进行讲解。Python 主要通过两种方式来创建线程:
1.使用 threading 模块中 Thread 类的构造器创建线程。即直接对类 threading.Thread 进行实例化创建线程,并调用实例化对象的 start() 方法启动线程。
Thread 类提供了如下的 __init__() 构造器,可以用来创建线程:
__init__(self, group=None, target=None, name=None, args=(), kwargs=None, *,daemon=None)
此构造方法中,以上所有参数都是可选参数,即可以使用,也可以忽略。其中各个参数的含义如下:
- group:指定所创建的线程隶属于哪个线程组(此参数尚未实现,无需调用);
- target:指定所创建的线程要调度的目标方法(最常用);
- args:以元组的方式,为 target 指定的方法传递参数;
- kwargs:以字典的方式,为 target 指定的方法传递参数;
- daemon:指定所创建的线程是否为后代线程。
输出这些参数,初学者只需记住 target、args、kwargs 这 3 个参数的功能即可。
import threading
#定义线程要调用的方法,*add可接收多个以非关键字方式传入的参数
def action(*add):
for arc in add:
#调用 getName() 方法获取当前执行该程序的线程名
print(threading.current_thread().getName() +" :"+ arc)
#定义为线程方法传入的参数
my_tuple = ("线程1","线程2","线程3")
#创建线程
thread = threading.Thread(target = action,args =my_tuple)
#启动线程
thread.start()#实际是调用threading的run()方法输出:

2.继承 threading 模块中的 Thread 类创建线程类。即用 threading.Thread 派生出一个新的子类,将新建类实例化创建线程,并调用其 start() 方法启动线程。需要重写父类的run()方法,该方法其实就是上面target的中要执行的函数参数
import threading
#创建子线程类,继承自 Thread 类
class my_Thread(threading.Thread):
def __init__(self,add):
threading.Thread.__init__(self)
self.add = add
# 重写run()方法
def run(self):
for arc in self.add:
#调用 getName() 方法获取当前执行该程序的线程名
print(threading.current_thread().getName() +" :"+ arc)
#定义为 run() 方法传入的参数
my_tuple = ("线程1","线程2","线程3")
#创建子线程
mythread = my_Thread(my_tuple)
#启动子线程
mythread.start()
#主线程执行此循环
for i in range(5):
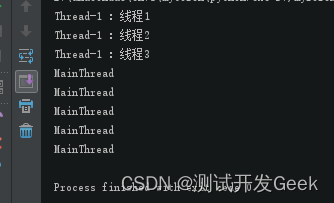
print(threading.current_thread().getName())输出:

子线程 Thread-1 执行的是 run() 方法中的代码,而 MainThread 执行的是主程序中的代码,它们以快速轮换 CPU 的方式在执行。
补充--守护进程setDaemon和阻塞进程join:
join的作用:join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程再继续执行或者终止.
import threading
#创建子线程类,继承自 Thread 类
class my_Thread(threading.Thread):
def __init__(self,add):
threading.Thread.__init__(self)
self.add = add
# 重写run()方法
def run(self):
for arc in self.add:
#调用 getName() 方法获取当前执行该程序的线程名
print(threading.current_thread().getName() +" :"+ arc)
#定义为 run() 方法传入的参数
my_tuple = ("线程1","线程2","线程3")
#创建子线程
mythread = my_Thread(my_tuple)
#启动子线程
mythread.start()
mythread.join()#阻塞主线程,等待子线程结束后在执行主线程
#主线程执行此循环
for i in range(5):
print(threading.current_thread().getName())输出:
注意和没有阻塞线程结果的区别:

setDaemon的作用:这个方法基本和join是相反的。不管子线程是否完成,都要和主线程—起退出。将线程声明为守护线程,必须在start()方法调用之前设置,如果不设置为守护线程程序会被无限挂起。当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。
import time,sys
import threading
#创建子线程类,继承自 Thread 类
class my_Thread(threading.Thread):
def __init__(self,add):
threading.Thread.__init__(self)
self.add = add
# 重写run()方法
def run(self):
for arc in self.add:
#调用 getName() 方法获取当前执行该程序的线程名
print(threading.current_thread().getName() +" :"+ arc)
time.sleep(1)
#定义为 run() 方法传入的参数
my_tuple = ("线程1","线程2","线程3")
#创建子线程
mythread = my_Thread(my_tuple)
mythread.setDaemon(True)#设置守护线程为True,为False择相当于没设置守护进程
#启动子线程
mythread.start()
print('---------------主线程执行结束-----------------')输出:

如果为False或者不设置,则结果为:

三.进程的创建
Python multiprocessing 模块提供了 Process 类,该类可用来在 Windows 平台上创建新进程。和使用 Thread 类创建多线程方法类似,使用 Process 类创建多进程也有以下 2 种方式:
- 直接创建 Process 类的实例对象,由此就可以创建一个新的进程;
- 通过继承 Process 类的子类,创建实例对象,也可以创建新的进程。注意,继承 Process 类的子类需重写父类的 run() 方法。
| 属性名或方法名 | 功能 |
|---|---|
| run() | 第 2 种创建进程的方式需要用到,继承类中需要对方法进行重写,该方法中包含的是新进程要执行的代码。 |
| start() | 和启动子线程一样,新创建的进程也需要手动启动,该方法的功能就是启动新创建的线程。 |
| join([timeout]) | 和 thread 类 join() 方法的用法类似,其功能是在多进程执行过程,其他进程必须等到调用 join() 方法的进程执行完毕(或者执行规定的 timeout 时间)后,才能继续执行; |
| is_alive() | 判断当前进程是否还活着。 |
| terminate() | 中断该进程。 |
| name属性 | 可以为该进程重命名,也可以获得该进程的名称。 |
| daemon | 和守护线程类似,通过设置该属性为 True,可将新建进程设置为“守护进程”。 |
| pid | 返回进程的 ID 号。大多数操作系统都会为每个进程配备唯一的 ID 号。 |
通过Process类创建进程
和使用 thread 类创建子线程的方式非常类似,使用 Process 类创建实例化对象,其本质是调用该类的构造方法创建新进程。Process 类的构造方法格式如下:
def __init__(self,group=None,target=None,name=None,args=(),kwargs={})
其中,各个参数的含义为:
- group:该参数未进行实现,不需要传参;
- target:为新建进程指定执行任务,也就是指定一个函数;
- name:为新建进程设置名称;
- args:为 target 参数指定的参数传递非关键字参数;
- kwargs:为 target 参数指定的参数传递关键字参数。
from multiprocessing import Process
import os,time
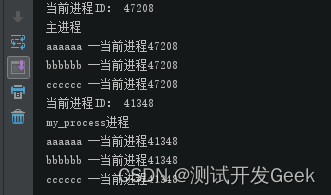
print("当前进程ID:",os.getpid())
# 定义一个函数,准备作为新进程的 target 参数
def action(name,*add):
print(name)
for arc in add:
print("%s --当前进程%d" % (arc,os.getpid()))
if __name__=='__main__':
#定义为进程方法传入的参数
my_tuple = ("aaaaaa","bbbbbb","cccccc")
#创建子进程,执行 action() 函数
my_process = Process(target = action, args = ("my_process进程",*my_tuple))
#启动子进程
my_process.start()
# time.sleep(2)
#主进程执行该函数
action("主进程",*my_tuple)
子进程创建需要时间,在这个空闲时间,父线程继续执行代码,子进程创建完成后显示
输出:
通过Process继承类创建进程通
和使用 thread 子类创建线程的方式类似,除了直接使用 Process 类创建进程,还可以通过创建 Process 的子类来创建进程。
需要注意的是,在创建 Process 的子类时,需在子类内容重写 run() 方法。实际上,该方法所起到的作用,就如同第一种创建方式中 target 参数执行的函数。
另外,通过 Process 子类创建进程,和使用 Process 类一样,先创建该类的实例对象,然后调用 start() 方法启动该进程
from multiprocessing import Process
import os
print("当前进程ID:",os.getpid())
# 定义一个函数,供主进程调用
def action(name,*add):
print(name)
for arc in add:
print("%s --当前进程%d" % (arc,os.getpid()))
#自定义一个进程类
class My_Process(Process):
def __init__(self,name,*add):
super().__init__()
self.name = name
self.add = add
def run(self):
print(self.name)
for arc in self.add:
print("%s --当前进程%d" % (arc,os.getpid()))
if __name__=='__main__':
#定义为进程方法传入的参数
my_tuple = ("aaaaaa","bbbbbb","cccccc")
my_process = My_Process("my_process进程",*my_tuple)
#启动子进程
my_process.start()
#主进程执行该函数
action("主进程",my_tuple)
该程序的运行结果与上一个程序的运行结果大致相同,它们只是创建进程的方式略有不同而已
输出:

守护进程setdaemon和进程同步join,作用类似于在线程中的作用
join:父进程 必须等待子进程运行结束
from multiprocessing import Process
import time
def show(name):
print("Process name is " + name)
time.sleep(2)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
print('我是父进程')

如果没有设阻塞则结果为:
from multiprocessing import Process
import time
def show(name):
print("Process name is " + name)
time.sleep(2)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
# proc.join()
print('我是父进程')

setdaemon:只要主进程结束,子进程就结束
from multiprocessing import Process
import time
def show(name):
print("Process name is " + name)
time.sleep(2)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.daemon=True
proc.start()
print('我是父进程')
输出:

设置进程启动的3种方式
已经详解介绍了 2 种创建进程的方法,即分别使用 os.fork() 和 Process 类来创建进程。其中:
使用 os.fork() 函数创建的子进程,会从创建位置处开始,执行后续所有的程序,主进程如何执行,则子进程就如何执行;
而使用 Process 类创建的进程,则仅会执行if "__name__"="__main__"之外的可执行代码以及该类构造方法中 target 参数指定的函数(使用 Process 子类创建的进程,只能执行重写的 run() 方法)。
实际上,Python 创建的子进程执行的内容,和启动该进程的方式有关。而根据不同的平台,启动进程的方式大致可分为以下 3 种:
spawn:使用此方式启动的进程,只会执行和 target 参数或者 run() 方法相关的代码。Windows 平台只能使用此方法,事实上该平台默认使用的也是该启动方式。相比其他两种方式,此方式启动进程的效率最低。
fork:使用此方式启动的进程,基本等同于主进程(即主进程拥有的资源,该子进程全都有)。因此,该子进程会从创建位置起,和主进程一样执行程序中的代码。注意,此启动方式仅适用于 UNIX 平台,os.fork() 创建的进程就是采用此方式启动的。
forserver:使用此方式,程序将会启动一个服务器进程。即当程序每次请求启动新进程时,父进程都会连接到该服务器进程,请求由服务器进程来创建新进程。通过这种方式启动的进程不需要从父进程继承资源。注意,此启动方式只在 UNIX 平台上有效。
总的来说,使用类 UNIX 平台,启动进程的方式有以上 3 种,而使用 Windows 平台,只能选用 spawn 方式(默认即可)。
手动设置进程启动方式的方法,大致有以下 2 种
1.Python multiprocessing 模块提供了一个set_start_method() 函数,该函数可用于设置启动进程的方式。需要注意的是,该函数的调用位置,必须位于所有与多进程有关的代码之前
import multiprocessing
import os
print("当前进程ID:", os.getpid())
# 定义一个函数,准备作为新进程的 target 参数
def action(name, *add):
print(name)
for arc in add:
print("%s --当前进程%d" % (arc, os.getpid()))
if __name__ == '__main__':
# 定义为进程方法传入的参数
my_tuple = ("aaaaaa", "bbbbbb", "cccccc")
# 设置进程启动方式
multiprocessing.set_start_method('spawn')
# 创建子进程,执行 action() 函数
my_process = multiprocessing.Process(target=action, args=("my_process进程", *my_tuple))
# 启动子进程
my_process.start()
由于此程序中进程的启动方式为 spawn,因此该程序可以在任意( Windows 和类 UNIX 上都可以 )平台上执行

2. 除此之外,还可以使用 multiprocessing 模块提供的 get_context() 函数来设置进程启动的方法,调用该函数时可传入 “spawn”、“fork”、“forkserver” 作为参数,用来指定进程启动的方式。
需要注意的一点是,前面在创建进程是,使用的 multiprocessing.Process() 这种形式,而在使用 get_context() 函数设置启动进程方式时,需用该函数的返回值,代替 multiprocessing 模块调用 Process()
import multiprocessing
import os
print("当前进程ID:", os.getpid())
# 定义一个函数,准备作为新进程的 target 参数
def action(name, *add):
print(name)
for arc in add:
print("%s --当前进程%d" % (arc, os.getpid()))
if __name__ == '__main__':
# 定义为进程方法传入的参数
my_tuple = ("aaa", "bbb", "bbb")
# 设置使用 fork 方式启动进程
ctx = multiprocessing.get_context('spawn')
# 用 ctx 代替 multiprocessing 模块创建子进程,执行 action() 函数
my_process = ctx.Process(target=action, args=("my_process进程", *my_tuple))
# 启动子进程
my_process.start()