rownum先百度一波https://www.cnblogs.com/xfeiyun/p/16355165.html
rownum是oracle特有的一个关键字。
对于基表,在insert记录时,oracle就按照insert的顺序,将rownum分配给每一行记录,因此在select一个基表的时候,rownum的排序是根据insert记录的顺序显示的。
CREATE TABLE TEST.CC_STUDENT_02 (ID VARCHAR2(256), USERNAME VARCHAR2(22))
INSERT INTO test.CC_STUDENT_02 VALUES(1,1);
INSERT INTO test.CC_STUDENT_02 VALUES(2,2);
INSERT INTO test.CC_STUDENT_02 VALUES(1,1);
INSERT INTO test.CC_STUDENT_02 VALUES(2,2);
INSERT INTO test.CC_STUDENT_02 VALUES(3,3);
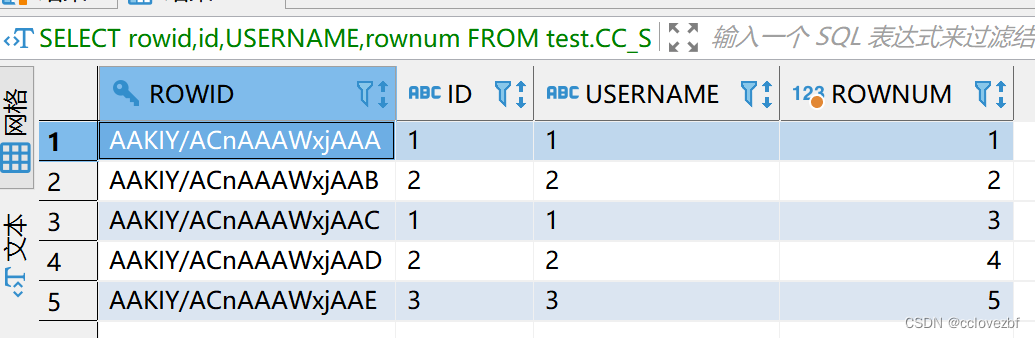
注意注意注意对于子查询来说,rownum会重新生成
SELECT id ,USERNAME ,r1 ,rownum AS r2 FROM (
SELECT rowid ,id,USERNAME,rownum AS r1FROM test.CC_STUDENT_02 ORDER BY id )t
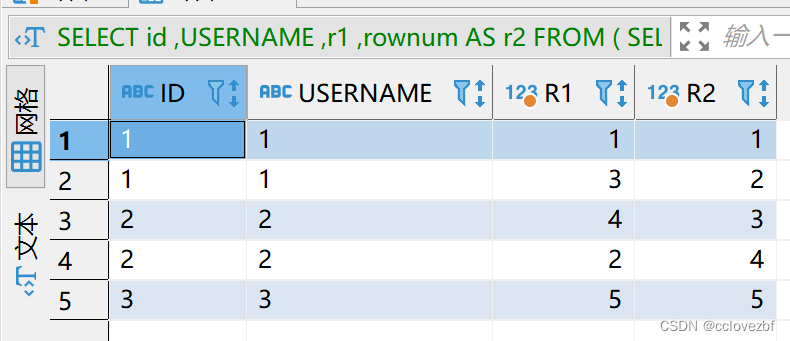
r1还是我们最开是插入的顺序,就是oracle最初给这5条记录赋予的行数。
r2是因为我们把order by 当作了t表,oracle把这个t表当作一个新的表,再重新赋予了rownum
如何使用rownum去分页查询或者查询指定行。
1、rownum对于等于某值的查询条件:如果想找到第一条查询数据,可以使用rownum=1作为查询条件,但是想找到第二条查询数据,使用rownum=2则查不到数据,原因是:rownum都是从1开始,但是1以上的自然数与rownum做等于时,都认为是false条件,所以无法查询到rownum=n (n>1的自然数)
SELECT id,USERNAME,rownum AS r1 FROM test.CC_STUDENT_02
WHERE ROWNUM =1 --只能查到第一行WHERE ROWNUM =2 --查不到任何数据
2、rownum对于大于某值的查询条件:要是想查询出第二行以后的记录,直接使用rownum>2是查不出数据的,原因是rownum是一个总是以1开始的伪例,rownum>n (n>1的自然数)依然不成立。可以使用子查询来解决,注意子查询中的rownum必须要有别名,否则还是不会查出记录来,这是因为rownum不是某个表的列,如果不起别名的话,无法知道rownum是子查询的列还是主查询的列。例如:
SELECT id,USERNAME,rownum AS r1 FROM test.CC_STUDENT_02
WHERE ROWNUM >0 --查出全部数据
WHERE ROWNUM >1 --查不到任何数据
3、rownum对于小于某值的查询条件: rownum对于rownum<n((n>1的自然数)的条件认为是成立的,所以可以找到记录。
注意:对于查询rownum在某区间的数据,必须使用子查询,例如要查询rownum在第二行到第三行之间的数据,包括第二行和第三行数据,那么我们只能写以下语句,先让它返回小于等于三的记录行,然后在主查询中判断新的rownum的别名列大于等于二的记录行。但是这样的操作会在大数据集中影响速度。
SELECT id ,USERNAME ,r1 ,rownum AS r2 FROM (
SELECT id,USERNAME,rownum AS r1 --注意这里要取别名FROM test.CC_STUDENT_02 t1
WHERE ROWNUM <4
)t2
WHERE r1>1 --上面不取别名 这里写rownum是t1还是t2的呢?
4、rownum和排序 Oracle中的rownum的是在取数据的时候产生的序号,所以想对指定排序的数据去指定的rowmun行数据就必须注意了。
其实这里就是说你是想要insert的排序的rownum还是你自己定义的排序规则。
实战分析
说说我遇到和rownum遇到的一个问题。
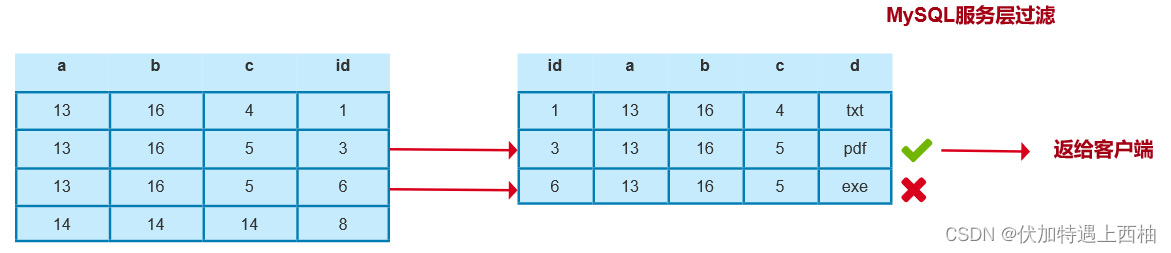
我向对方发http请求,对方从oracle数据返回500条数据,总数据大概有5w条,我每获取500条数据就落地写到hdfs,然后500一追加,一般几分钟就跑完了。突然有一天别人反馈我这边数据重复了,我就惊呆了,查询hdfs数据确实重复了。
那么此时有个问题,是我写重复了还是数据库重复了,先要别人查了下,数据库是ok的
那么我开始自己检查,突然发现比如第300-310 共10条数据和第1300-1310的10条数据是重复的。这个时候又有问题,是我程序写错了,还是对方传错了?
后来检查的时候是发现没有order by (还是order by month)就用了rownum,导致这500数据不稳定,有时候会重复。
说下原因 如果你没有order by 系统还是默认有个排序规则。或者你order by month(这个比较通用的字段 例如 sex vip) 这种排序是很容易出现问题的!!!!
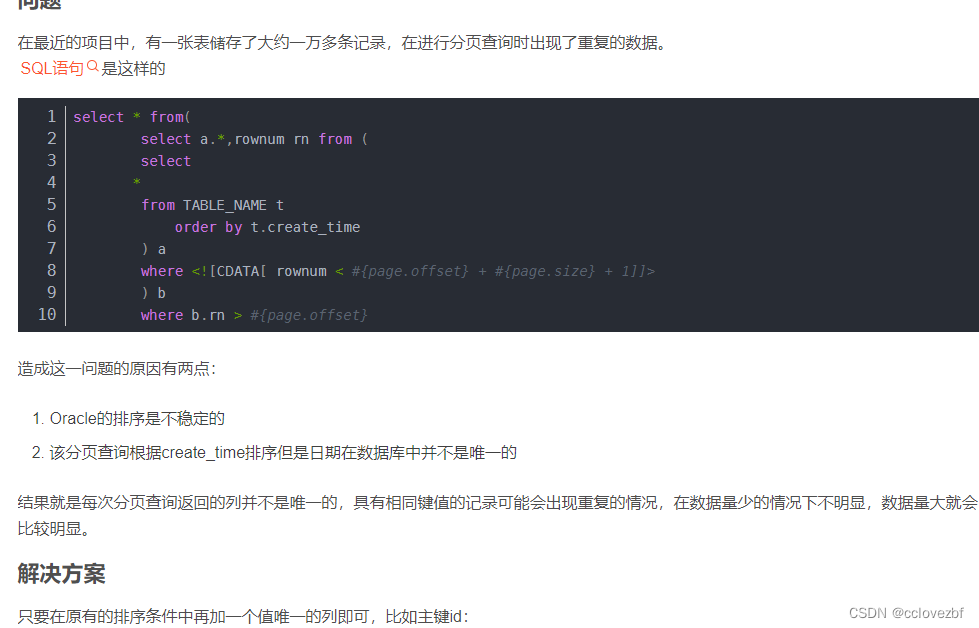
当时排查就是发现他没有order by 。。 后面select* from table order by month,name,id 就好了,总之尽可能的保证排序的唯一性。当然你要是前端展示无所谓,重复就重复了,谁还记得第1页和第100页的数据是否重复。
rowid 照例先百度一波。Oracle中的rowid
ROWID是ORACLE中的一个重要的概念。用于定位数据库中一条记录的一个相对唯一地址值。通常情况下,该值在该行数据插入到数据库表时即被确定且唯一。ROWID它是一个伪列,它并不实际存在于表中。它是ORACLE在读取表中数据行时,根据每一行数据的物理地址信息编码而成的一个伪列。所以根据一行数据的ROWID能找到一行数据的物理地址信息。从而快速地定位到数据行。数据库的大多数操作都是通过ROWID来完成的,而且使用ROWID来进行单记录定位速度是最快的。
说的有点多,个人理解,其实可以把rowid看作是该条数据存放的物理地址,在这张表内是唯一的(感觉是在整个数据库也是唯一的)。 也可以理解为java中每个对象在堆中地址值,地址唯一,但是你不知道地址是哪里,
Oracle中的rowid 这篇文章详细介绍了rowid的每个字母都代表啥。。
接着来说rowid有什么用?
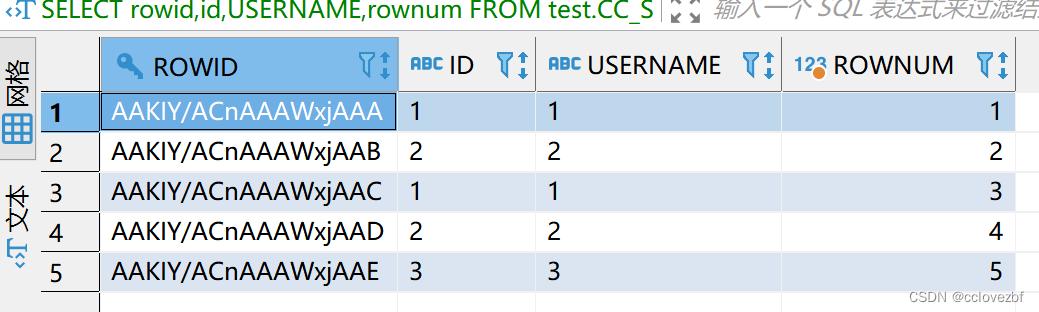
oracle数据库中存在两条相同的数据,怎么删除其中的一条呢 比如删除第二条id=1的数据?
使用rownum我好像想不出来怎么删
这个时候就可以用rowid了,因为他代表的是每条数据的唯一值,可以间接性的看作是mysql的主键。
DELETE FROM test.CC_STUDENT_02 cs WHERE rowid ='AAKIY/ACnAAAWxjAAC'
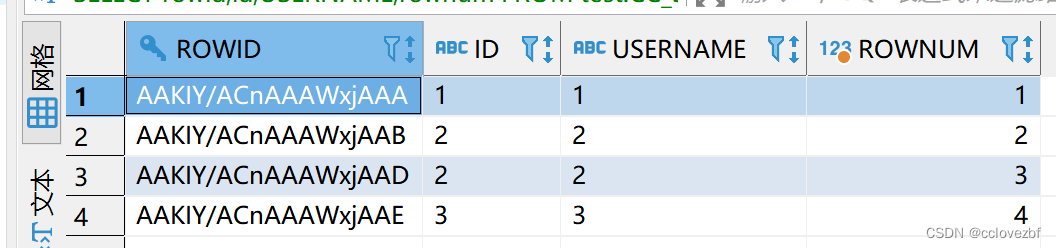
其实在这里就rowid就相当于唯一键。
那么问题来了,如果有多条重复数据怎么同时删除所有重复的数据呢?
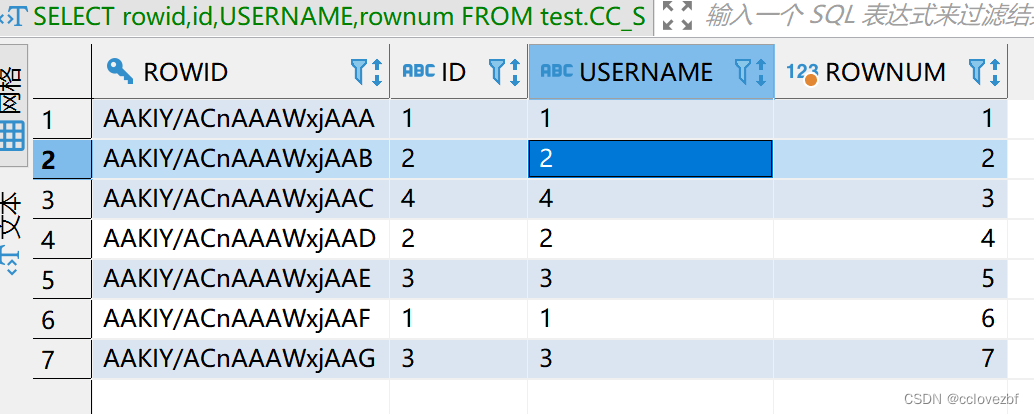
删除思路参考 rowid的作用
思路就是 找到相同的id和name的最大rowid 然后not in
DELETE FROM test.CC_STUDENT_02 t1 WHERE rowid NOT IN (SELECT max(rowid) FROM test.CC_STUDENT_02 t2 WHERE t1.id=t2.id AND t1.USERNAME=t2.USERNAME )
delete from emp where rowid not in (select max(rowid) from test.CC_STUDENT_02 group by id,name)

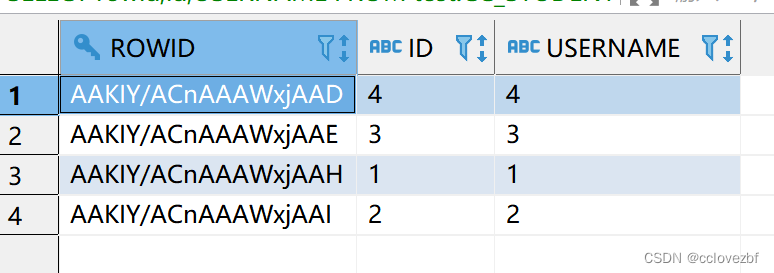
差不多懂了一点基础的用法。那么我现在有个问题,rowid 代表的这条数据的唯一性,而且rowid只存在于oracle,现在我把oracle数据迁移到hive了,怎么替代rowid呢?
目前就想到一个hash(*) 和一个把所有rowid也导入到hive。