参考笔记
【机器学习】五分钟搞懂如何评价二分类模型!混淆矩阵、召回率、精确率、准确率超简单解释,入门必看!_哔哩哔哩_bilibili
混淆矩阵的概念_GIS_JH的博客-CSDN博客
机器学习中的混淆矩阵,准确率,精确率,召回率,F1,ROC/AUC,AP/MAP_混淆矩阵准确率预测精度召回率_胤风的博客-CSDN博客 课程教学资源:
8、源码分享 混淆矩阵、召回率、精准率、ROC曲线等指标一键导出【小学生都会的Pytorch】_哔哩哔哩_bilibili
上一节笔记:pytorch进阶学习(六):如何对训练好的模型进行优化、验证并且对训练过程进行准确率、损失值等的可视化,新手友好超详细记录_好喜欢吃红柚子的博客-CSDN博客
目录
一、二分类模型评价指标(理论介绍)
1. 混淆矩阵
1.1 简介
1.2 TP、FP、FN、TN
2. 二级指标
2.1 准确率
2.2 精确率
2.3 召回率
3. 三级指标 F1
二、混淆矩阵、召回率、精准率、ROC曲线等指标的可视化
1. 数据集的生成和模型的训练
2. 模型验证
2.1 具体步骤
2.2 关于eval函数的解释
2.3 代码
2.4运行结果
3. 混淆矩阵、ROC曲线等指标的图像绘制
3.1 代码
3.2 输出结果
一、二分类模型评价指标(理论介绍)
1. 混淆矩阵
1.1 简介
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
- 在下图是否为猫的预测中,表格左上(实际为正和预测为正)和右下(实际为负和预测为负)是预测正确的值。
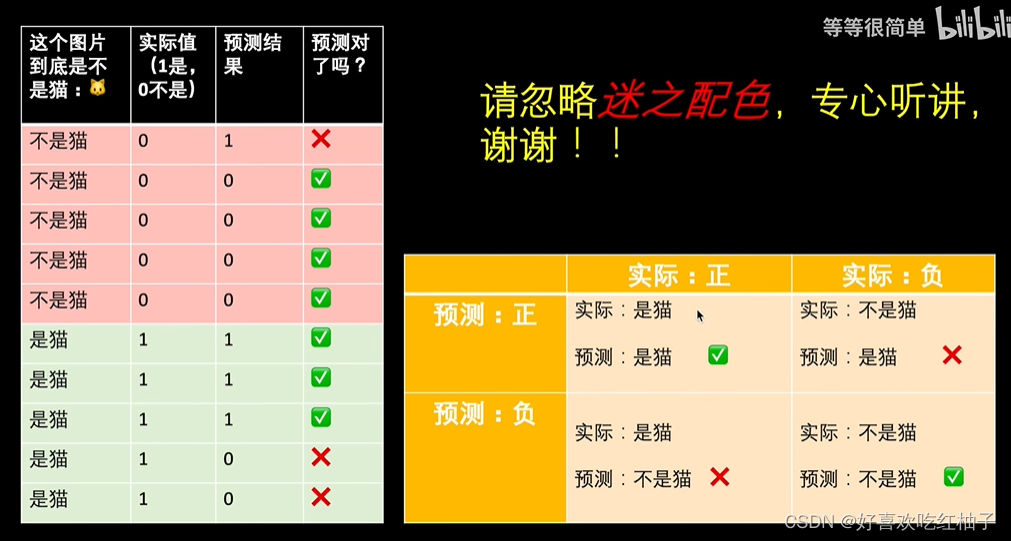
- 根据左边表格的数据,可以得出右边表格中的数字,即得到了混淆矩阵


1.2 TP、FP、FN、TN
- True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
- False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
- False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
- True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
在下图中:
- 真实是猫,预测为猫(正):TP
- 真实不是猫,预测不是猫(负):TN
- 真实不是猫,预测是猫(正):FP
- 真实是猫,预测不是猫(正):PN

2. 二级指标
2.1 准确率
所有样本中真正预测对的个数占所有样本的比例。

2.2 精确率
预测为正(预测是猫:4)的样本中实际上为正(实际为猫:3)的个数。
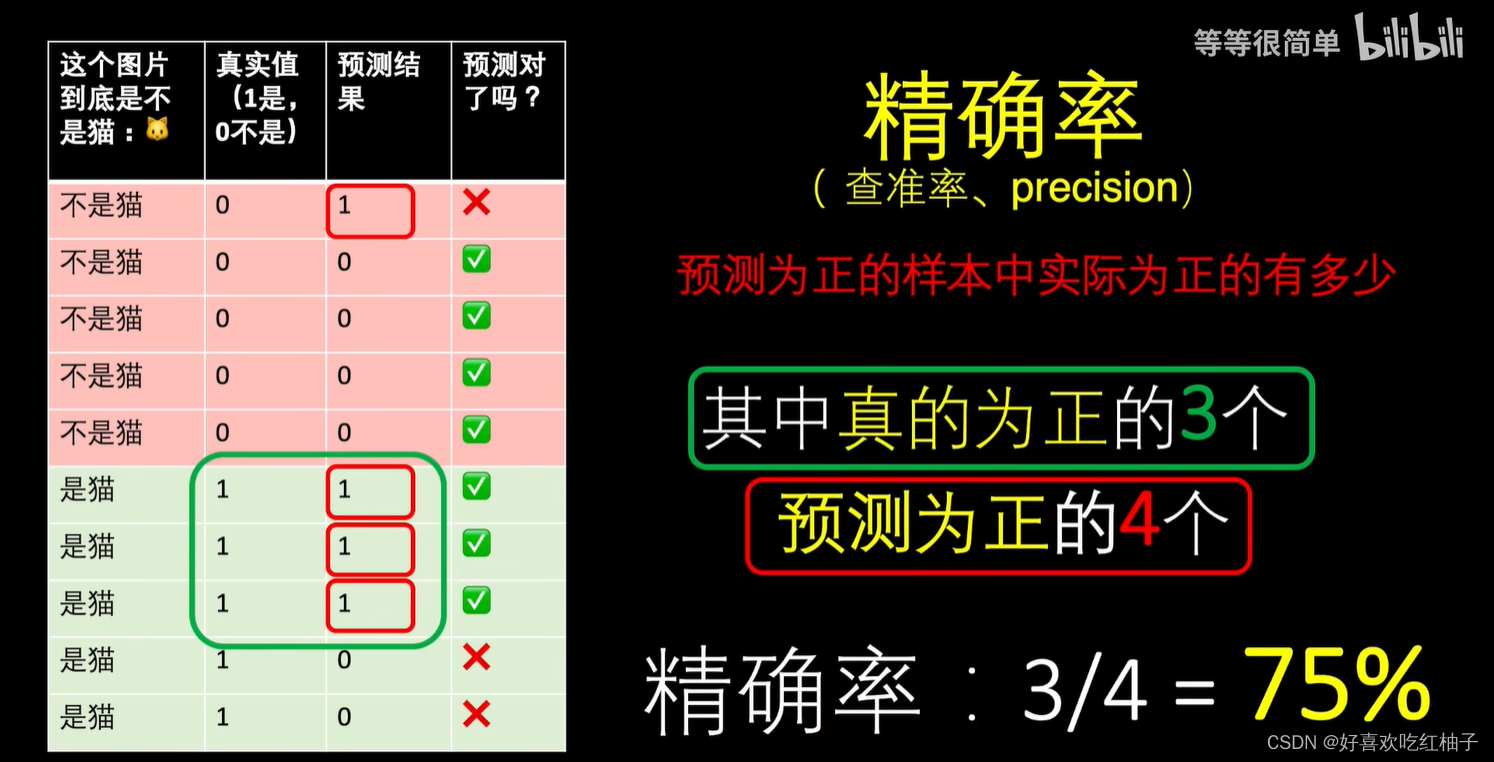
2.3 召回率
实际为正的样本中(实际为猫:5)预测为正(预测为猫:3)的有多少。

3. 三级指标 F1
需要综合的考虑精确率和召回率两者的分数,于是引入了F1值,它是精确率和召回率的调和平均。

二、混淆矩阵、召回率、精准率、ROC曲线等指标的可视化
1. 数据集的生成和模型的训练
在这里,dataset数据集的生成和模型的训练使用到的代码和上一节一样,可以看前面的具体代码。
pytorch进阶学习(六):如何对训练好的模型进行优化、验证并且对训练过程进行准确率、损失值等的可视化,新手友好超详细记录_好喜欢吃红柚子的博客-CSDN博客
- CreateDataset.py生成数据集train.txt和test.txt文件
- PreTrainedModel.py对模型进行预训练,这里我们使用resnet34作为基本网络结构,下载预训练权重文件进行参数调整,对神经网络全连接层进行调整,经过参数加载、冻结、训练等一系列迁移学习的步骤之后,设置epoch=50,完成对网络的训练,并且保存正确率最高的epoch训练出的参数权重,在我这里即为BEST_resnet_epoch_50_acc_87.1.pth,进行后续使用;

2. 模型验证
2.1 具体步骤
- 加载预训练模型:resnet34的网络框架,修改fc层的输出为5
- 加载模型参数:使用上一步训练好的"./BEST_resnet_epoch_50_acc_87.1.pth"文件,加载进模型中进行使用
- 加载需要进行预测的图片:我们使用test.txt文件进行测试,其中共有866张图片。
- 获取结果:eval函数计算出对图片数据集进行预测的预测标签、概率和
2.2 关于eval函数的解释
这段代码定义了一个名为eval的函数,该函数接受两个参数:dataloader和 model。函数内部首先定义了三个空列表label_list、likelihood_list和 pred_list。
- 使用model.eval()将模型设置为评估模式,以便在推理时使用。
- 使用torch.no_grad()上下文管理器禁用梯度计算,以便在推理时不会计算梯度,从而提高推理速度。
- 在for循环中,使用dataloader加载数据,得到图片数据X和真实标签y。然后将数据转移到GPU上,并将图片传入模型中,得到预测值pred。
- pred_softmax 是一个numpy数组,它代表了模型对每个类别的预测概率分布。pred_softmax的第i个元素表示模型预测输入属于第i个类别的概率。 在函数中,pred_softmax是通过将pred张量传递给torch.softmax函数并使用cpu().numpy()方法将结果转换为numpy数组而获得的。
- 使用torch.softmax函数将pred转换为概率分布,并使用numpy函数将其转换为numpy数组。然后,使用numpy.argmax 函数获取概率最大的标签,并将其添加到label_list 中。使用numpy.max函数获取概率最大的值,并将其添加到likelihood_list 中。
- 将 pred_softmax添加到pred_list中。最后,函数返回三个列表 label_list、likelihood_list和pred_list。
2.3 代码
代码在结果展示时运用到了进度条,需要pip一下tqdm
pip install tqdm
'''
1.单幅图片验证
2.多幅图片验证
'''
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.models import resnet34
from utils import LoadData, write_result
import pandas as pd
from tqdm import tqdm
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
def eval(dataloader, model):
label_list = []
likelihood_list = []
pred_list = []
model.eval()
with torch.no_grad():
# 加载数据加载器,得到里面的X(图片数据)和y(真实标签)
for X, y in tqdm(dataloader, desc="Model is predicting, please wait"):
# 将数据转到GPU
X = X.cuda()
# 将图片传入到模型当中就,得到预测的值pred
pred = model(X)
pred_softmax = torch.softmax(pred,1).cpu().numpy()
# 获取可能性最大的标签
label = torch.softmax(pred,1).cpu().numpy().argmax()
label_list.append(label)
# 获取可能性最大的值(即概率)
likelihood = torch.softmax(pred,1).cpu().numpy().max()
likelihood_list.append(likelihood)
pred_list.append(pred_softmax.tolist()[0])
return label_list,likelihood_list, pred_list
if __name__ == "__main__":
'''
加载预训练模型
'''
# 1. 导入模型结构
model = resnet34(pretrained=False)
num_ftrs = model.fc.in_features # 获取全连接层的输入
model.fc = nn.Linear(num_ftrs, 5) # 全连接层改为不同的输出
device = "cuda" if torch.cuda.is_available() else "cpu"
# 2. 加载模型参数
model_loc = "./BEST_resnet_epoch_50_acc_87.1.pth"
model_dict = torch.load(model_loc)
model.load_state_dict(model_dict)
model = model.to(device)
'''
加载需要预测的图片
'''
valid_data = LoadData("test.txt", train_flag=False)
test_dataloader = DataLoader(dataset=valid_data, num_workers=4, pin_memory=True, batch_size=1)
'''
获取结果
'''
# 获取模型输出
label_list, likelihood_list, pred = eval(test_dataloader, model)
# 将输出保存到exel中,方便后续分析
label_names = ["daisy", "dandelion","rose","sunflower","tulip"] # 可以把标签写在这里
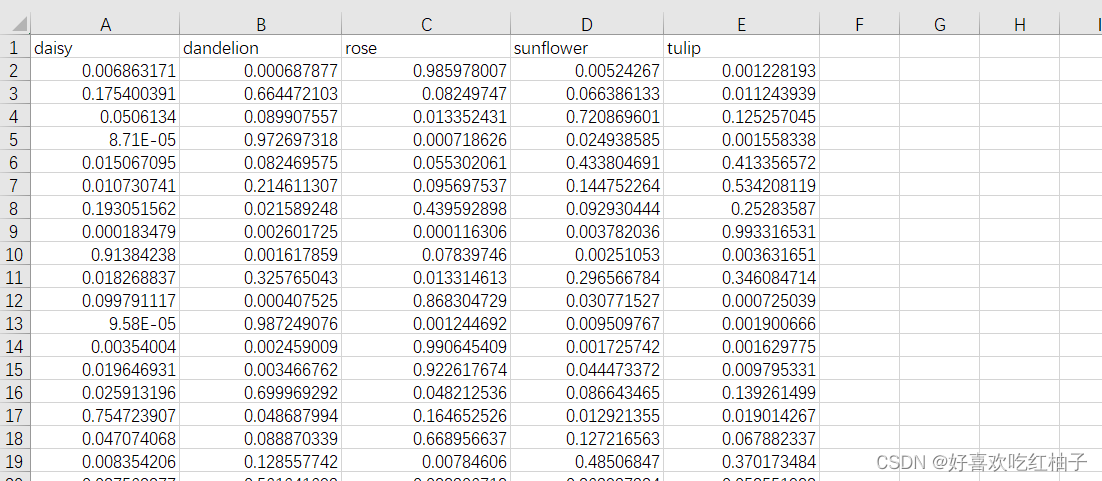
df_pred = pd.DataFrame(data=pred, columns=label_names)
df_pred.to_csv('pred_result.csv', encoding='gbk', index=False)
print("Done!")
2.4运行结果
模型对test集中的866张图片进行预测,生成了pred_result.csv文件,保存着每张图片对每个类别的预测概率。

pred_result.csv展示:
3. 混淆矩阵、ROC曲线等指标的图像绘制
3.1 代码
需要用到sklearn包,pip安装
pip install scikit-learn
'''
模型性能度量
'''
from sklearn.metrics import * # pip install scikit-learn
import matplotlib.pyplot as plt # pip install matplotlib
import numpy as np # pip install numpy
from numpy import interp
from sklearn.preprocessing import label_binarize
import pandas as pd # pip install pandas
'''
读取数据
需要读取模型输出的标签(predict_label)以及原本的标签(true_label)
'''
target_loc = "test.txt" # 真实标签所在的文件
target_data = pd.read_csv(target_loc, sep="\t", names=["loc","type"])
true_label = [i for i in target_data["type"]]
# print(true_label)
predict_loc = "pred_result.csv" # 3.ModelEvaluate.py生成的文件
predict_data = pd.read_csv(predict_loc)#,index_col=0)
predict_label = predict_data.to_numpy().argmax(axis=1)
predict_score = predict_data.to_numpy().max(axis=1)
'''
常用指标:精度,查准率,召回率,F1-Score
'''
# 精度,准确率, 预测正确的占所有样本种的比例
accuracy = accuracy_score(true_label, predict_label)
print("精度: ",accuracy)
# 查准率P(准确率),precision(查准率)=TP/(TP+FP)
precision = precision_score(true_label, predict_label, labels=None, pos_label=1, average='macro') # 'micro', 'macro', 'weighted'
print("查准率P: ",precision)
# 查全率R(召回率),原本为对的,预测正确的比例;recall(查全率)=TP/(TP+FN)
recall = recall_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("召回率: ",recall)
# F1-Score
f1 = f1_score(true_label, predict_label, average='macro') # 'micro', 'macro', 'weighted'
print("F1 Score: ",f1)
'''
混淆矩阵
'''
label_names = ["daisy", "dandelion","rose","sunflower","tulip"]
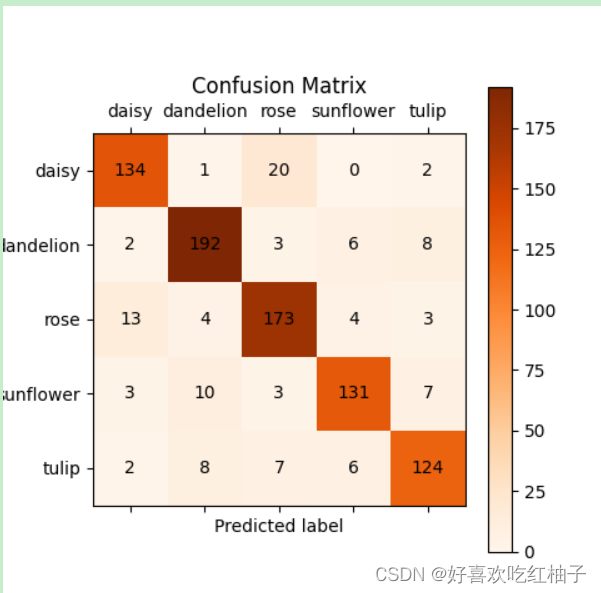
confusion = confusion_matrix(true_label, predict_label, labels=[i for i in range(len(label_names))])
plt.matshow(confusion, cmap=plt.cm.Oranges) # Greens, Blues, Oranges, Reds
plt.colorbar()
for i in range(len(confusion)):
for j in range(len(confusion)):
plt.annotate(confusion[j,i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.xticks(range(len(label_names)), label_names)
plt.yticks(range(len(label_names)), label_names)
plt.title("Confusion Matrix")
plt.show()
'''
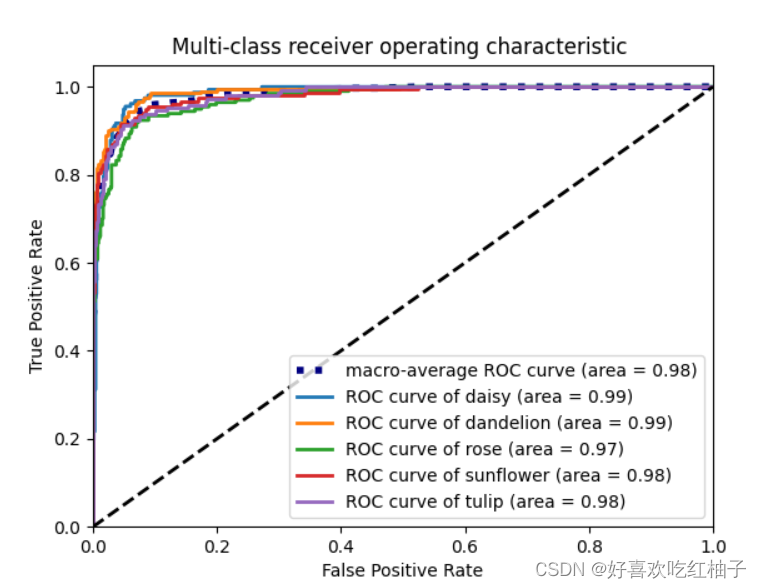
ROC曲线(多分类)
在多分类的ROC曲线中,会把目标类别看作是正例,而非目标类别的其他所有类别看作是负例,从而造成负例数量过多,
虽然模型准确率低,但由于在ROC曲线中拥有过多的TN,因此AUC比想象中要大
'''
n_classes = len(label_names)
# binarize_predict = label_binarize(predict_label, classes=[i for i in range(n_classes)])
binarize_predict = label_binarize(true_label, classes=[i for i in range(n_classes)])
# 读取预测结果
predict_score = predict_data.to_numpy()
# 计算每一类的ROC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(binarize_predict[:,i], [socre_i[i] for socre_i in predict_score])
roc_auc[i] = auc(fpr[i], tpr[i])
# print("roc_auc = ",roc_auc)
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
lw = 2
plt.figure()
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], lw=lw, label='ROC curve of {0} (area = {1:0.2f})'.format(label_names[i], roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Multi-class receiver operating characteristic ')
plt.legend(loc="lower right")
plt.show()
3.2 输出结果

混淆矩阵
ROC曲线
![[java]String类](https://img-blog.csdnimg.cn/1bfe2a4363654fae9affd5edc9d7724b.png)