开源社区的进展
在 ChatGPT 以外,谷歌、脸书等互联网巨头,也都发布过千亿级参数的大语言模型,但在交谈问答方面表现相对 ChatGPT 来说都显得一般。根据科学人员推测,很重要的一部分原因是缺失了RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)和PPO(Proximal Policy Optimization,近线策略优化)部分。因此,开源社区开始尝试在当前开源的千亿级参数大语言模型基础上,添加 RLHF 技术,尽力复现 ChatGPT 效果。
目前已知有两个开源项目在进行中:
- colossal:https://github.com/hpcaitech/ColossalAI/tree/main/applications/ChatGPT
- chatllama:https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
目前而言,尚未看到这两个项目的实际性公开测试结论。一些零星的,对 LLAMA 模型的单机版体验报告,也都表示达不到 meta 公司发表的 LLAMA 论文中宣称的,更小参数规模匹配 GPT-3 效果的程度。
不过多年来开源社区和商业厂商分阵营对抗的历史经验,依然让很多人目光投向了还在蹒跚学步的开源模型们。甚至已经有岗位招聘中,开始要求"熟悉学界、业界最新研究成果,包括但不限于 instructGPT、LLaMA、LaMDA,国内的悟道、M6 等大模型"。
即使有了开源模型的第一步基础,要通过开源技术,在本地化部署环境中完整复现 ChatGPT,依然还有重重难关。
首先,ChatGPT 已知是千亿级参数规模的大模型,单独一张 GPU 卡连最基础的加载都无法完成。本地化训练需要大规模的 GPU 并行计算能力。openai 公司没有公布 ChatGPT 的训练成本,但外界有多种不同的猜测。第一种猜测依据 openai 曾经公开的 GPT-3 训练数据,根据当时 V100 显卡的公有云最低优惠包年价,计算得到理论极限最低成本为 460 万美元。第二种猜测依据 AI 业界著名人士 Elliot Turner 的推文,但他没有提供任何消息的准确来源,据称是 1200 万美元。
此外,还有一些其他可类比的情况。比如上一次震惊世界的 AI,围棋界的 alphago,训练投入是3500 万美元。比如 NVIDIA 公布自己的千亿级参数规模大模型 Megatron-LM,训练过程使用了 3072 张 80GB A100 显卡。根据市价,一张 A100 显卡大概需要两万美元,这 3072 张显卡的市价超过六千万美元,转换为人民币大概在四伍亿元左右。
考虑到 GPU 硬件技术的发展,每一代 CPU 产品性能都有接近 50% 的提升,重新训练一个 ChatGPT 的成本肯定会逐渐下降,但短期来看,至少两三年内,还不是一般科技公司可以畅想的未来。大家更可能的选择,是在大公司的模型或云服务基础上,实现自己的上层应用。
其次,ChatGPT 作为 GPT-3.5 的兄弟模型,在标准的 GPT 思想以外,还加入了 RLHF(Reinforcement Learning from Human Feedback)技术。并针对 Chat 这个场景,引入了和 instructGPT 不同的标注数据:由专门的人员,编写一部分对话数据加入训练。这些对话中,他们即扮演提问用户,也扮演 AI 机器人。然后 ChatGPT 在强化学习的奖励模型中,又让专门的人员对随机生成的若干条回答手动标记排名,通过 PPO(Proximal Policy Optimization)策略进行微调。
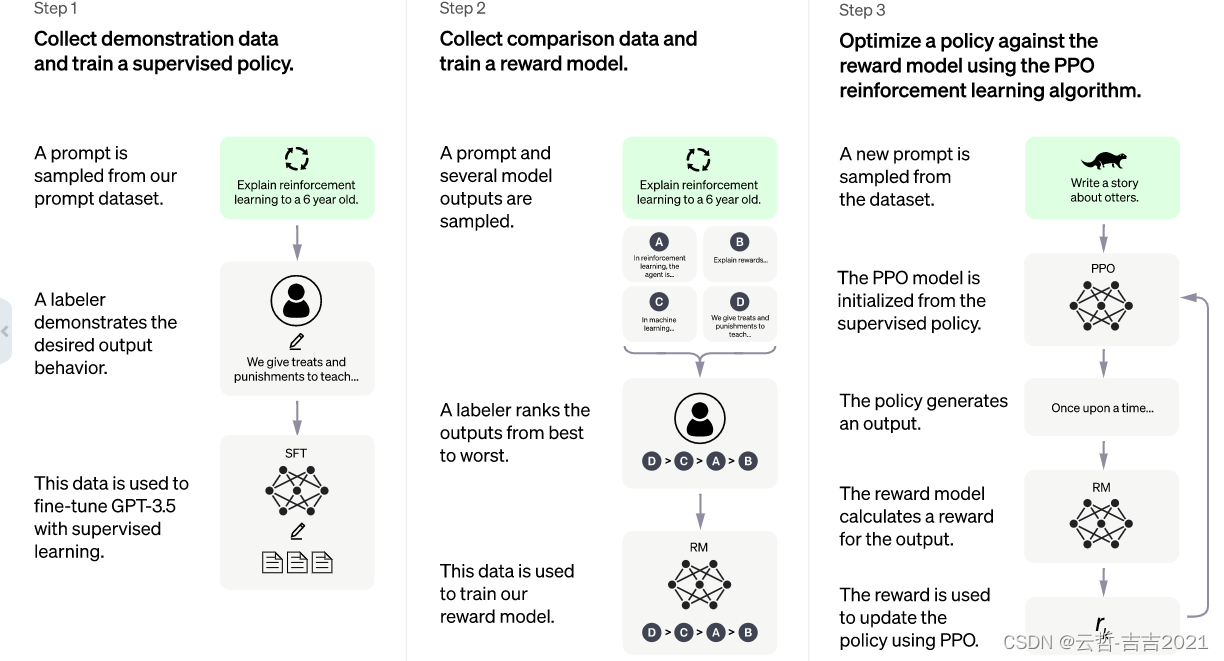 在初始训练中,openai 公司只雇佣了 40 个标注人员。但产品上线以后,ChatGPT 两个月内获取了 1 亿用户,海量标注数据在产品运行中自然而然的产生。在最近一次用户协议迭代中,openai 公司宣布直接使用 API 调用 ChatGPT 能力的用户数据不会被用于训练。换言之:通过网页端直接聊天的数据,已经足够 ChatGPT 的模型优化更新了。
在初始训练中,openai 公司只雇佣了 40 个标注人员。但产品上线以后,ChatGPT 两个月内获取了 1 亿用户,海量标注数据在产品运行中自然而然的产生。在最近一次用户协议迭代中,openai 公司宣布直接使用 API 调用 ChatGPT 能力的用户数据不会被用于训练。换言之:通过网页端直接聊天的数据,已经足够 ChatGPT 的模型优化更新了。
中国在以往的 AI 应用中,同样大量使用了标注手段,相对低廉的人工成本和工程师成本在这方面也有一定的优势。但这些数据,是否会公开成为开源模型的一部分,供所有公司使用?还是沿着 ChatGPT 的路线,几家大公司比拼谁能更早构建用户反馈数据的护城河?
最后,即使获得了可靠的预训练大模型,在本地化部署环境做推理计算,依然有较高的成本。对特定领域内容进行微调也有一定难度。可能后续还是需要引入一些模型压缩方案,例如量化、蒸馏、剪枝、参数共享等等。知识蒸馏是之前大模型压缩的常用方案,但目前 ChatGPT 只开放 API 不开放模型,就很难直接进行知识蒸馏。一种可能的途径是利用 ChatGPT 的思维链功能,将问答记录里的思维链过程作为压缩小模型的训练数据。但这种使用方式在 openai 的用户协议中是明确禁止的。
无论如何,作为 ChatGPT 技术的使用者,我们可以关注类似技术的迭代更新,并保持对几年后,技术普及化的美好期待。