第三章(2):深入理解NTLK库基本使用方法
本节主要介绍了NLTK库的基本使用方法,其中对NLTK的安装与配置进行了介绍。随后,对文本处理中常用的分词、句子分割和词性标注这三个任务进行了详细讲解。
如果感觉有用,
不妨给博主来个一键三连,白天科研,晚上肝文,实属不易~ ~拜托了!

目录
- 第三章(2):深入理解NTLK库基本使用方法<br><br>
- 1. NTLK库基本使用介绍
- 1.1 NTLK安装与配置
- 1.2 分词
- 1.2.1 什么叫做分词
- 1.2.2 使用NLTK进行分词
- 1.2.3 不同类型的分词器
- 1.2.4 分词实践
- 1.3 句子分割
- 1.3.1 规则法
- 1.3.2 机器学习法
- 1.4 词性标注
- 1.4.1 什么是词性标注
- 1.4.2 示例
- 1.5 总结
1. NTLK库基本使用介绍
NLTK(Natural Language Toolkit)是一个广泛使用的Python库,是由Steven Bird和Edward Loper在宾夕法尼亚大学计算机和信息科学系开发。该库提供了丰富的自然语言处理工具和语料库,可以用于文本分类、词性标注、实体识别、情感分析等任务。
在本节,我们将介绍NLTK的基本用法,并通过实例展示如何使用NLTK进行文本处理和分析。希望通过本篇文章,读者对于如何使用NLTK进行自然语言处理有一个基本的了解。
1.1 NTLK安装与配置
安装NLTK库的方法与安装其他Python库的方法相同,需要在终端中执行以下命令:
pip install nltk
这将会下载并安装最新版本的NLTK库。如果需要特定版本的NLTK,可以使用以下命令:
pip install nltk==x.x.x
其中,x.x.x是所需版本的具体版本号。例如,要安装NLTK 3.4.5版本,可以使用以下命令:
pip install nltk==3.4.5
安装完成后,我们还需要下载一些语料库和模型,以便使用NLTK进行自然语言处理任务。我们可以使用nltk.download()函数下载这些数据集和模型。
import nltk
import nltk
nltk.download()
但是不出意外会出现如下错误:
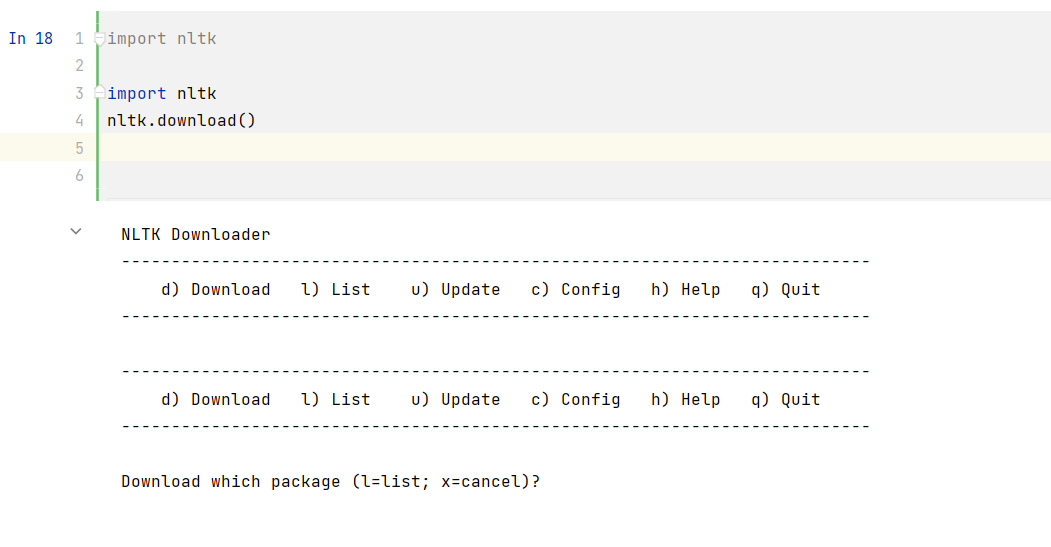
我们可以参考如下教程进行解决:成功解决NLTK包的安装错误_安静到无声的博客-CSDN博客
是否安装成功,可以采用如下示例进行验证:
from nltk.corpus import stopwords
print(stopwords.words('english'))
实验结果:

1.2 分词
1.2.1 什么叫做分词
在NLP中,分词是指将一段文本拆分成更小的单元,也就是所谓的“标记”(tokens)。这些标记可以是单词、短语、符号或任何其他你希望在文本处理过程中处理的部分。常见的分词方法包括空格分隔符、标点符号、正则表达式、最大匹配算法等等。
例如,我们有一个包含以下文本的字符串:
text = "I like to go hiking on the weekends."
print(text)
实验结果:
I like to go hiking on the weekends.
如果使用空格作为分隔符来进行分词,得到以下结果:
["I", "like", "to", "go", "hiking", "on", "the", "weekends."]
分词对于许多自然语言处理任务都非常重要,因为它对文本的结构和意义的表示有很大影响。例如,在文本分类和信息检索中,分词可以使我们更好地了解文档的内容和主题,以便更准确地进行分类或搜索。
1.2.2 使用NLTK进行分词
NLTK提供了word_tokenize()函数来帮助我们进行基于单词的分词。以下是一个例子:
import nltk
from nltk.tokenize import word_tokenize
text = "I like to go hiking on the weekends."
tokens = word_tokenize(text)
print(tokens)
实验结果:
['I', 'like', 'to', 'go', 'hiking', 'on', 'the', 'weekends', '.']
word_tokenize()函数将文本解析为一系列单独的单词,在这个例子中,每个单词被作为列表中的一个元素返回。此外,该函数还添加了一个句点标记,表示句子的结尾。
在许多情况下,仅仅对输入文本调用word_tokenize()是不够的。例如,如果我们有一段内容包含逗号、句点、短语或其他标点符号,并希望保留它们,那么我们需要使用不同的分词器来处理它们。如下所示,nltk.tokenize()库提供了多种分词器。
1.2.3 不同类型的分词器
word_tokenize()函数
该分词器会将输入文本解析为一系列单独的单词,它将根据空格和标点符号来确定单词的边界。因此,在某些情况下,word_tokenize()可能无法很好地处理特定的文本输入,示例如下:
from nltk.tokenize import word_tokenize
text = "I'm eating a slice of cake, I'll be done soon."
tokens = word_tokenize(text)
print(tokens)
实验结果:
['I', "'m", 'eating', 'a', 'slice', 'of', 'cake', ',', 'I', "'ll", 'be', 'done', 'soon', '.']
在这个例子中,word_tokenize()将cake,解析成两个标记,因为逗号也被视为一个分隔符,而I'm被分割成立两个标记,并没有把’分开。
TweetTokenizer()函数
此分词器是一种专门针对推文和其他社交媒体文本的分词器。与word_tokenize()不同,它将保留诸如表情符号、@提到的人、#话题等内容。
例如:
from nltk.tokenize import TweetTokenizer
text = "I'm eating a slice of cake, I'll be done soon. 😋 #cake"tknzr = TweetTokenizer()
tokens = tknzr.tokenize(text)
print(tokens)
实验结果:
["I'm", 'eating', 'a', 'slice', 'of', 'cake', ',', "I'll", 'be', 'done', 'soon', '.', '😋', '#cake']
RegexpTokenizer()函数(正则表达式切分)
RegexpTokenizer()是Python中NLTK库提供的一种分词器,可使用正则表达式来定义分割文本的规则。
在使用RegexpTokenizer()时,我们需要首先导入它:
from nltk.tokenize import RegexpTokenizer
然后,我们可以创建一个RegexpTokenizer()对象:
tokenizer = RegexpTokenizer(pattern, gaps=False, discard_empty=True, flags=re.UNICODE)
pattern参数指定了要使用的正则表达式模式。gaps参数指定是否应从匹配的文本之间的间隙处分割字符串。如果gaps参数设置为True,则RegexpTokenizer()将返回所有不匹配正则表达式的部分。默认情况下,gaps参数设置为False,即只返回与正则表达式匹配的部分。discard_empty参数指定是否应丢弃分割后为空的令牌。默认情况下,discard_empty参数设置为True,即如果分割后的令牌为空,则将其忽略。flags参数传递给正则表达式引擎,用于指定各种标志。
以下是一个例子,演示如何使用RegexpTokenizer()将文本分成单独的单词:
from nltk.tokenize import RegexpTokenizer
text = "This is a sample text, showing off the RegexpTokenizer! Isn't it great? We can use it to split the text into tokens."
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(text)
print(tokens)
实验结果:
['This', 'is', 'a', 'sample', 'text', 'showing', 'off', 'the', 'RegexpTokenizer', 'Isn', 't', 'it', 'great', 'We', 'can', 'use', 'it', 'to', 'split', 'the', 'text', 'into', 'tokens']
在这个例子中,我们首先定义了要处理的文本字符串,并创建了一个RegexpTokenizer()对象,该对象使用\w+正则表达式模式来将文本分成单独的单词。
1.2.4 分词实践
在进行分词时,有一些最佳实践是需要注意:
- 将文本转化为小写,统一命名实践。
text = "The quick brown FOX jumped over the LAZY dog."
text = text.lower()
print(text)
实验结果:
the quick brown fox jumped over the lazy dog.
- 去除文本中的特殊字符和数字,以便只关注字母和单词
import re
text = "The quick brown fox 2 jumped over the LAZY dog."
text = re.sub(r'[^a-zA-Z\s]', '', text)
print(text)
实验结果:
The quick brown fox jumped over the LAZY dog
这段代码先定义了一个字符串 text,然后使用正则表达式替换函数 re.sub() 将其中的非字母、非空格字符去除,并将结果保存回 text 变量中。
具体来说,re.sub(pattern, repl, string) 函数用于在字符串 string 中查找与 pattern 匹配的子字符串,并将其替换为新的字符串 repl。在这个例子中,我们使用 pattern 参数 r'[^a-zA-Z\s]' 来匹配所有非字母和非空格字符,然后将其替换为空字符串 ''。因此,最终的结果是将 text 中的数字 2 和句点 . 去除,仅保留了字母和空格。
- 去除停用词,以避免过多的标记。
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
print("stop_words有:{}".format(stop_words))
text = "The quick brown fox jumped over the lazy dog."
tokens = word_tokenize(text)
filtered_tokens = [token for token in tokens if token not in stop_words]
print(filtered_tokens)
实验结果:
stop_words有:{'is', 'was', 'can', 'should', 'he', "you'll", 'she', "it's", 'below', 'in', 'other', 'more', 'which', 'most', "shouldn't", 'y', 'own', 'all', 'theirs', 'whom', 'have', 'of', 'same', 'am', "haven't", 'down', 'shan', 'who', 'over', 'while', 'yours', "you're", 'be', 've', 'didn', 'yourselves', 'what', 'myself', 'hers', 'such', 'but', 'not', 'do', 'shouldn', 'an', 'your', "don't", 'our', 't', 'just', 'from', 'because', 'as', 'are', 'hadn', 'so', 'up', 'few', 'it', 'after', 'i', 'will', 'and', "hadn't", 'wasn', "didn't", "weren't", 'then', 'nor', 'been', 'had', 'their', 'having', 're', "doesn't", 'themselves', 'off', 'ours', 'its', "couldn't", 'further', 'll', 'my', 'when', "mightn't", "shan't", 'during', 'why', 'at', 'about', 'above', 'with', 'weren', 'won', 'd', "wasn't", 'no', 'only', "won't", 'me', 'm', 'ourselves', 'once', 'those', 'ain', 'aren', 'has', "mustn't", 'these', "she's", 'the', 'out', 'under', 'mustn', 'we', 'where', 'herself', "isn't", 'to', 'both', "wouldn't", 'too', 'any', "that'll", 'doing', 'by', "hasn't", 'them', 'this', 'a', "should've", 'for', 'through', 'needn', 'there', 'that', 'himself', 'did', 'were', 'ma', 'hasn', 'wouldn', 'her', 'itself', 'against', 'his', "aren't", 'o', 'does', 'on', 'now', 'they', 'before', 'very', 'each', "you'd", 'how', 'doesn', "you've", "needn't", 'don', 'until', 's', 'here', 'being', 'between', 'haven', 'again', 'isn', 'than', 'or', 'couldn', 'some', 'into', 'mightn', 'you', 'yourself', 'him', 'if'}
['The', 'quick', 'brown', 'fox', 'jumped', 'lazy', 'dog', '.']
在这个例子中,我们从原始分词列表中去除了英语停用词(如“the”、“and”等),以保留最有意义的标记。
- 选择适当的分词器来处理不同类型的文本。
在某些情况下,简单的空格或标点符号分隔符可能已足够满足需求。在其他情况下,可能需要使用更高级的分词器来处理社交媒体文本、病历记录或其他特定类型的数据源。
1.3 句子分割
句子分割是自然语言处理中的一个基本任务,目的是将一个文本段落分成独立的句子。在 NLP 中,句子分割通常是文本预处理的第一步,因为许多后续的任务(如分词、词性标注、命名实体识别等)都需要从句子级别开始进行处理。本文将介绍如何使用 NLTK 库对文本进行句子分割。
1.3.1 规则法
规则法是句子分割的传统方法之一,其基本思想是通过手动编写规则将句子从段落中分割出来。常见的规则包括查找断句符号(如句点、感叹号、问号)和特殊缩略词(如Mr.、Dr.等),以及根据特定文本结构进行分割(如列表项、章节标题等)。由于规则法分割句子的效果取决于规则的精确性和覆盖面,因此存在一些问题,例如难以应对复杂的文本结构、需要频繁更新规则等。
在 NLTK 中,可以使用 PunktSentenceTokenizer 类来实现基于规则的句子分割。其核心思想是利用已有的大量文本样本,通过学习训练数据中常见的断句模式,来构建分割器并在新文本上进行句子分割操作。该类通常使用默认的训练数据集(包括各种英语文献、新闻和网络数据),也可以使用自己的数据集进行训练。
以下是使用 PunktSentenceTokenizer 进行句子分割的示例代码:
import nltk
text = "This is a sample text. It contains two sentences."
sent_tokenizer = nltk.tokenize.PunktSentenceTokenizer()
sentences = sent_tokenizer.tokenize(text)
print(sentences)
实验结果:
['This is a sample text.', 'It contains two sentences.']
在上述代码中,我们先定义了一个字符串 text。然后,我们创建了一个 PunktSentenceTokenizer 分割器,并将其存储在变量 sent_tokenizer 中。最后,我们调用 sent_tokenizer.tokenize(text) 函数,将输入的文本段落分割成两个句子,存储在列表 sentences 中。可以看到,这个函数的输出结果与输入的句子是一致的。
1.3.2 机器学习法
机器学习法是句子分割的主流方法之一,其基本思想是将句子分割问题看作一个二分类问题,即将文本分成句子和非句子两类。针对已有的标注数据,我们可以通过不同的分类算法(如朴素贝叶斯、支持向量机等)来训练模型,并在新的数据上进行预测。
在 NLTK 中,可以使用 nltk.sentiment.util 模块中的 sent_tokenize() 函数来实现基于机器学习的句子分割。该函数基于一个英语句子分割器的数据集,使用未经训练的标识符进行分割。要使用该函数,需要先确保已安装所需的包和数据集,具体的安装方法可以参考前面的示例代码。
以下是使用 sent_tokenize() 进行句子分割的示例代码:
import nltk
text = "This is a sample text. It contains two sentences."
sentences = nltk.sent_tokenize(text)
print(sentences)
实验结果:
['This is a sample text.', 'It contains two sentences.']
在上述代码中,我们导入了 nltk 库,并使用 nltk.sent_tokenize(text) 函数将输入的文本段落分割成两个句子,存储在列表 sentences 中。可以看到,输出结果与前面使用规则法的示例是一致的。
1.4 词性标注
词性标注是自然语言处理中的一个重要任务,它的目的是为给定文本中的每个单词或词汇标注其所属的词性。在 NLP 中,词性标注通常是文本预处理的必要步骤之一,因为很多后续的任务(如实体识别、语义分析、句子分析等)都需要对文本中的单词进行标注。
1.4.1 什么是词性标注
在自然语言处理领域中,词性标注是指为给定的单词或词汇标注其在上下文中所扮演的语法角色的任务。这些语法角色通常表示为成分或标记,如名词、动词、形容词、副词、代词等。例如,下面是一句话:
“我可以跳过这道难题。”
其中,“我”、“可以”、“跳过”和“这道”分别表示不同的语法意义(主语、情态动词、动词和形容词短语)。通过对每个单词进行词性标注,我们可以更好地了解这个句子的语法结构和含义。
词性标注的主要目的是为了帮助自然语言处理任务更好地理解文本。例如,在命名实体识别中,我们可以将被标注为“名词”类型的单词视为可能的实体名称。在信息检索中,我们可以将被标注为“动词”类型的单词作为查询中的关键字。在机器翻译中,我们也可以使用词性标记来在不同的语言之间进行单词的对齐和转换。
1.4.2 示例
在使用 NLTK 进行词性标注之前,需要先下载 punkt 和 averaged_perceptron_tagger 数据。其中averaged_perceptron_tagger 数据是 NLTK 中一个已经训练好的基于感知器算法(Perceptron Algorithm)和平均感知器算法(Averaged Perceptron Algorithm)的词性标注模型。它通过学习大量的已经标注好的数据,提取单词的特征,并对每个单词进行词性标注。这个模型的优点是速度快、准确率高,能够快速地对大规模文本进行词性标注。
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
接着,我们可以使用 pos_tag 函数实现词性标注。pos_tag 可以将文本中的词语进行标注,并返回标注后的词语列表。
import nltk
# 分词
text = "Hello, how are you? I hope you are doing well. Today is a good day!"
tokens = nltk.word_tokenize(text)
# 标注词性
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)
代码中,我们首先将文本 text 进行分词处理,并使用 pos_tag 函数对 tokens 列表进行词性标注,得到 tagged_tokens 列表。输出结果为:
复制代码
[('Hello', 'NNP'), (',', ','), ('how', 'WRB'), ('are', 'VBP'), ('you', 'PRP'), ('?', '.'), ('I', 'PRP'), ('hope', 'VBP'), ('you', 'PRP'), ('are', 'VBP'), ('doing', 'VBG'), ('well', 'RB'), ('.', '.'), ('Today', 'NN'), ('is', 'VBZ'), ('a', 'DT'), ('good', 'JJ'), ('day', 'NN'), ('!', '.')]
其中,每个元素是一个二元组,第一个元素为单词,第二个元素为对应的词性标签。例如,“Hello”被标注为“NNP”(专有名词)、“how”被标注为“WRB”(疑问副词)等。
1.5 总结
本节主要介绍了NLTK库的基本使用方法,其中对NLTK的安装与配置进行了介绍。随后,对文本处理中常用的分词、句子分割和词性标注这三个任务进行了详细讲解。
参考:
NLTK_百度百科 (baidu.com)
成功解决NLTK包的安装错误_安静到无声的博客-CSDN博客







![【C++】对数组指针的理解,例如 int (*p)[3]](https://img-blog.csdnimg.cn/0b69ad41f6394c93839bb6cd02012ee5.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5rW36L2wUHJv,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)