很久很久之前,写入重入问题的文章
如果你在笔试的实际,面试官问
——下面这个代码有什么问题?
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
int NUM = 0;
void * PrintNum(void * ptr)
{
while(NUM++ < 200000000) {
}
printf("%s,NUM:%d\n", (char*)ptr, NUM);
NUM = 0;
}
int main(int argc,char ** argv)
{
pthread_t thread1 = -1;
char thread1_name[] = "thread2";
if(pthread_create(&thread1, NULL, PrintNum, thread1_name)!=0) {
printf("thread1 creat error\n");
}
pthread_t thread2 = -1;
char thread2_name[] = "thread2";
if(pthread_create(&thread1, NULL, PrintNum, thread2_name)!=0) {
printf("thread1 creat error\n");
}
void * result1;
void * result2;
pthread_join(thread1, &result1);
pthread_join(thread2, &result2);
}这个代码有以下问题:
在创建第二个线程时,使用了错误的变量名。
应该将 pthread_create(&thread1, NULL, PrintNum, thread2_name)
改为 pthread_create(&thread2, NULL, PrintNum, thread2_name)。
在 PrintNum 函数中,没有使用同步机制来保证对全局变量 NUM 的访问是线程安全的。多个线程同时访问 NUM 可能会导致数据不一致或者程序出现错误。应该使用互斥锁等同步机制来保证线程安全。
在 PrintNum 函数中,使用了一个死循环来模拟线程执行的时间。这样会导致线程一直占用 CPU 资源,影响系统的性能。应该使用 sleep 函数等待一段时间,让线程进入阻塞状态,释放 CPU 资源。
在 main 函数中,没有检查线程创建和等待的返回值,线程创建和等待可能会失败,应该检查返回值并进行错误处理。
在 main 函数中,没有释放线程资源。
应该在线程执行完毕后调用 pthread_exit 函数或者 pthread_cancel 函数来释放线程资源。
在 main 函数中,没有使用 return 语句来结束程序,应该在程序执行完毕后使用 return 语句来结束程序。
上面的答案是我把代码扔给chatgpt得到的回复。
综上所述,这个代码需要进行一些修改才能正确地运行。
修改下代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
unsigned long int NUM = 0;
void * PrintNum(void * ptr)
{
unsigned long int count = 0;
while(NUM++ < 20000) {
count++;
}
printf("%s run %lu in NUM:%lu \n", (char*)ptr, count, NUM);
NUM = 0;
pthread_exit(NULL);
}
int main(int argc,char ** argv)
{
pthread_t thread1 = -1;
char thread1_name[] = "thread2";
if(pthread_create(&thread1, NULL, PrintNum, thread1_name)!=0) {
printf("thread1 creat error\n");
}
pthread_t thread2 = -1;
char thread2_name[] = "thread2";
if(pthread_create(&thread2, NULL, PrintNum, thread2_name)!=0) {
printf("thread1 creat error\n");
}
void * result1;
void * result2;
pthread_join(thread1, &result1);
pthread_join(thread2, &result2);
return 0;
}执行函数输出
thread2 .....run 18188 in NUM:20001
thread2 .....run 6812 in NUM:20001发现在计算里面,两个线程对全局变量的执行次数是不一样的。
然后我就进行了各种捣鼓
直到最后,才完成了我最初的想法
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <semaphore.h>
#include <string.h>
unsigned long int g_num = 0;
unsigned long int count_thread1 = 0, count_thread2 = 0;
#define RUN_COUNT 2000
pthread_mutex_t mutex;
pthread_cond_t cond;
int cond_flag = 1;
void * print_num(void * ptr)
{
while(1) {
pthread_mutex_lock(&mutex);
if (g_num >= RUN_COUNT) {
pthread_mutex_unlock(&mutex);
break;
}
if (strcmp((char*)ptr, "thread1") == 0) {
if (cond_flag != 1) {
pthread_cond_wait(&cond, &mutex);
}
} else if (strcmp((char*)ptr, "thread2") == 0) {
if (cond_flag != 2) {
pthread_cond_wait(&cond, &mutex);
}
}
if (strcmp((char*)ptr, "thread1") == 0) {
count_thread1++;
cond_flag = 2;
} else if (strcmp((char*)ptr, "thread2") == 0) {
count_thread2++;
cond_flag = 1;
}
g_num++;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
if (strcmp((char*)ptr, "thread1") == 0) {
printf("%s run %lu in g_num:%lu \n", (char*)ptr, count_thread1, g_num);
} else if (strcmp((char*)ptr, "thread2") == 0) {
printf("%s run %lu in g_num:%lu \n", (char*)ptr, count_thread2, g_num);
}
g_num = 0;
printf("%s run over \n", (char*)ptr);
pthread_exit(NULL);
}
int main(int argc,char ** argv)
{
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
pthread_t thread1 = -1;
char thread1_name[] = "thread1";
if(pthread_create(&thread1, NULL, print_num, thread1_name)!=0) {
printf("thread1 creat errorn");
return -1;
}
pthread_t thread2 = -1;
char thread2_name[] = "thread2";
if(pthread_create(&thread2, NULL, print_num, thread2_name)!=0) {
printf("thread1 creat errorn");
return -1;
}
while (1) {
if (g_num > RUN_COUNT) {
if (count_thread1 < RUN_COUNT/2) {
cond_flag = 1;
pthread_cond_signal(&cond);
} else if (count_thread2 < RUN_COUNT/2) {
cond_flag = 2;
pthread_cond_signal(&cond);
} else {
break;
}
}
}
void * result1;
void * result2;
pthread_join(thread1, &result1);
pthread_join(thread2, &result2);
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
return 0;
}代码输出
thread2 run 1000 in g_num:2000
thread2 run over
thread1 run 1001 in g_num:2001
thread1 run over上面的两段代码,第一段对临界区没有做任何保护,两个线程在调度的时候,对临界区的访问也是随机的。
第二段加上了条件变量和锁保护,让整个过程进入规则性运行,从而保证了软件的逻辑。
如果只增加锁保护而不增加条件变量的话,那只能保证临界区一个时间片内有一个线程访问,但是并不能保证对临界区访问的顺序性。
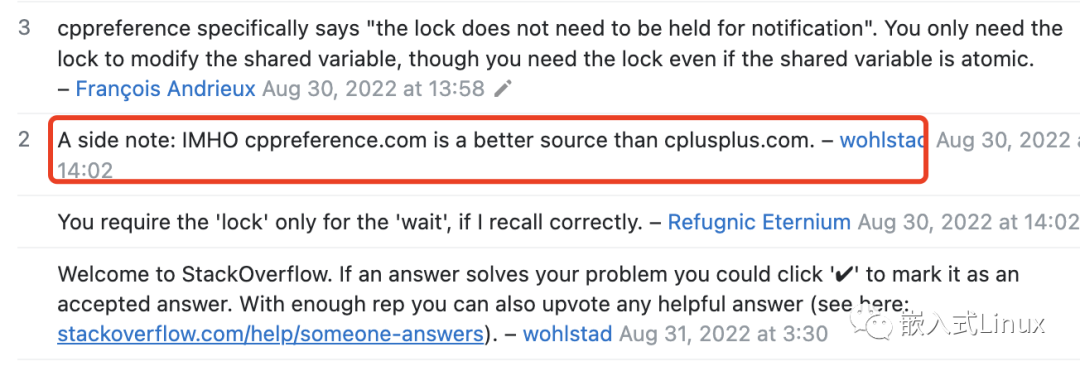
C++中的条件变量使用,大家可以看看这些链接
https://en.cppreference.com/w/cpp/thread/condition_variable
https://stackoverflow.com/questions/73543664/do-i-need-to-lock-the-mutex-before-calling-condition-variablenotify
https://www.zhihu.com/question/541037047