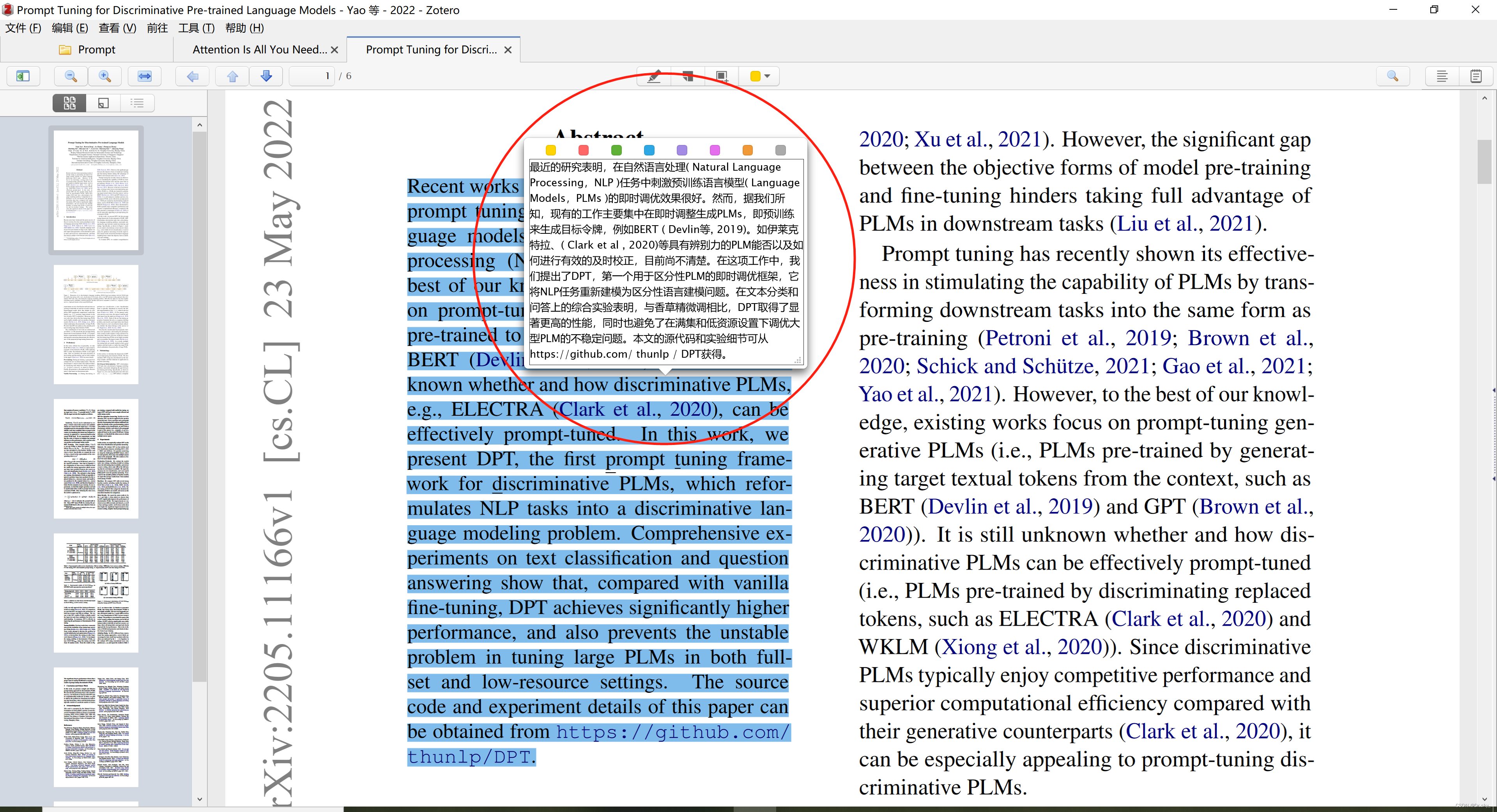
接上文的Binary Classifier,将数据分成“是2”和“非2”两类。
Performance Measures 分类效果评价方法
Accuracy(准确性)
y_train_2 = (y_train == 2)
...
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_2)
from sklearn.model_selection import cross_val_score
accuracy = cross_val_score(sgd_clf, X_train, y_train_2, cv=4, scoring="accuracy")
print(accuracy)
# [0.97066667 0.9674 0.97653333 0.9748 ]
虽然这个准确性不错,但是如果数据有偏向性呢?假设构造一个分类器,对所有数据都分类成“非2”,再看准确性:
class Never2Classifier(BaseEstimator):
def fit(self, X, y=None):
return self
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
...
from sklearn.model_selection import cross_val_score
never_2_clf = Never2Classifier()
print(cross_val_score(never_2_clf, X_train, y_train_2, cv=4, scoring="accuracy"))
# [0.90253333 0.90093333 0.90033333 0.899 ]
这个说明只有10%的图像是2(肯定的啊,只是0~9十个数字的手写库,一定会保证每个数字占1/10左右)。所以,对于有偏的数据集(skewed datasets,指某些类比其他类拥有更多的数据),准确性(accuracy)并不是一个很好的指标。
Confusion Matrix(混淆矩阵)
# 训练模型
y_train_2 = (y_train == 2)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_2)
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
# 计算混淆矩阵
# cross_val_predict进行k-fold cross-validation,但是不返回分数
# 返回的是每个fold上的预测
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_2, cv=4)
print(confusion_matrix(y_train_2, y_train_pred))
# 输出
[[53230 812]
[ 847 5111]]
解释:
每一行表示一个分类,每一列表示一个预测分类。比如第一行表示“非2”的分类(the negative class),所以53230个被正确判定为“非2”(true negatives),812个被错误地判定为“是2”(false positive);第二行表示“是2”的分类(the positive class),847被错误地判定为“非2”(false negatives),5111个被正确判定为“是2”(true positive)。一个好的分类器应该只有true positive和true negative,所以应该只在主对角线(左上到右下)有非零数值,其他位置都应该是0。
| 预测为正 | 预测为负 | |
|---|---|---|
| 实际为正 | TP | FN |
| 实际为负 | FP | TN |
精确率 precision = TP / (TP + FP)
召回率 recall = TP / (TP + FN) 也称为 sensitivity、true positive rate(TPR)
记忆方法:precision表示当预测为正时,正确的概率,所以÷竖向;recall表示只能预测出多少正,所以÷横向。
from sklearn.metrics import precision_score, recall_score
print(precision_score(y_train_2, y_train_pred)) # 其实就是 5111/(5111+812) 约0.863
print(recall_score(y_train_2, y_train_pred)) # 其实就是 5111/(5111+847) 约0.858
F1 score则结合了precision和recall。只有二者都大时,f1 score才会大。

使用方法是类似的:
from sklearn.metrics import precision_score, recall_score, f1_score
print(f1_score(y_train_2, y_train_pred)) # 0.8603652891170777
Precision/Recall Trade-off(精确率和召回率的权衡)
对于precision和recall双高的情况,f1 score挺好的,但对于某些特殊情况,比如一个监控系统,完全可以低precision,高recall(可以有很多次假警报,即高FP,但基本所有小偷都抓到了,即低FN)。但是这样的话,f1是比较低的。
从随机梯度下降(SGD)分类器的设计思路考虑:对于每个实例,代入decision function计算分数。如果这个分数高于阈值,就会分到positive类,否则分入negative类。这样的话,如果阈值降低,会有更多的FP,因为FP和FN的总量是一定的,那么FN会降低,所以recall会升高,precision会降低;相反,如果阈值升高,FP变少,FN变多,则recall降低,precision升高,如下图所示:
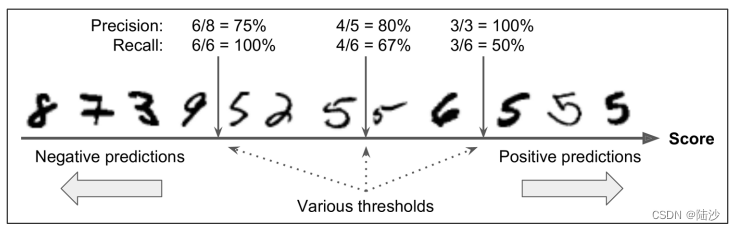
虽然scikit learn不允许直接获取这个阈值,但是却可以拿到用decision function计算出的分数。那么,可以先拿到所有实例的分数(cross_val_predict),然后绘制recall-threshold,precision-threshold曲线,然后选择threshold。
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import precision_recall_curve
y_scores = cross_val_predict(sgd_clf, X_train, y_train_2, cv=4, method="decision_function")
precisions, recalls, thresholds = precision_recall_curve(y_train_2, y_scores)
# np.argmax指寻找第一个满足precisions>=0.9的索引
recall_90_precision = recalls[np.argmax(precisions >= 0.9)] # 打印出来是 0.8217522658610272
threshold_90_precision = thresholds[np.argmax(precisions >= 0.9)] # 868.8893539759117
# 绘图
plt.figure(figsize=(8, 4))
# precision最后一个值是1,recall最后一个值是0,可以不必显示。而且threshold也比它俩少一个数值
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.legend(loc="center right", fontsize=16)
plt.xlabel("Threshold", fontsize=16)
plt.grid(True)
# x轴范围
plt.axis([-50000, 50000, 0, 1])
# r:表示红色虚线
# 绘制线段
plt.plot([threshold_90_precision, threshold_90_precision], [0., 0.9], "r:")
plt.plot([-50000, threshold_90_precision], [0.9, 0.9], "r:")
plt.plot([-50000, threshold_90_precision], [recall_90_precision, recall_90_precision], "r:")
# 绘制两个点
plt.plot([threshold_90_precision], [0.9], "ro")
plt.plot([threshold_90_precision], [recall_90_precision], "ro")
plt.show()
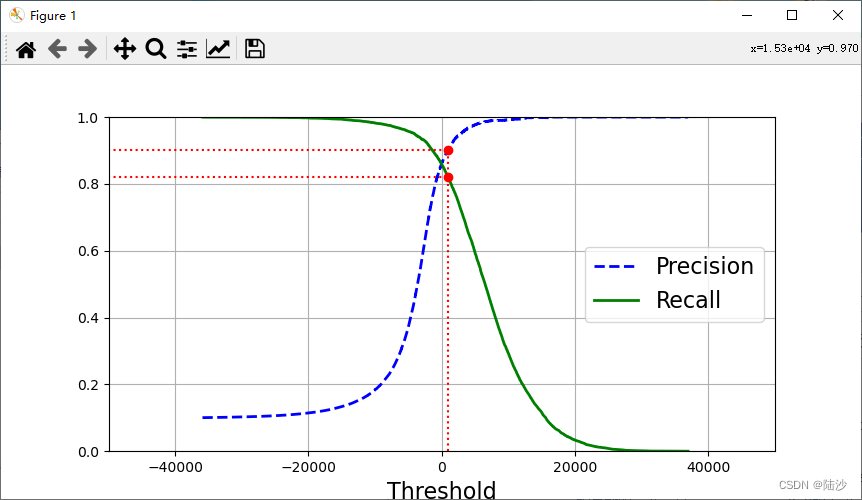
y_train_pred_90 = (y_scores >= threshold_90_precision)
from sklearn.metrics import precision_score, recall_score
print(precision_score(y_train_2, y_train_pred_90))
print(recall_score(y_train_2, y_train_pred_90))
0.9
0.8217522658610272
例如,以下代码演示了如何将阈值设置为 0.3:
在下面的代码中,predict_proba() 函数返回的是一个二维数组,第一列是预测为负例的概率,第二列是预测为正例的概率。我们通过 [:, 1] 来获取预测为正例的概率,并与阈值比较,将结果转换为 0 或 1。
from sklearn.linear_model import SGDClassifier
clf = SGDClassifier(loss='log')
clf.fit(X_train, y_train)
threshold = 0.3
y_pred = (clf.predict_proba(X_test)[:, 1] > threshold).astype(int)
ROC Curve
ROC曲线的横轴是FPR(False positive rate),纵轴是TPR(True positive rate,也就是recall,sensitivity)。其中,TNR(True negative rate,也叫specifitivity)。ROC也是sensitivity和1-specificity的曲线。
FPR = 1 - TNR
TNR = TN / (TN+FP)
根据模型的预测结果,将样本按照从高到低的概率值排序,然后在不同的阈值下计算 TPR 和 FPR,就可以得到 ROC 曲线。ROC 曲线越靠近左上角,说明模型的性能越好。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_2, y_scores)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, linewidth=2)
plt.plot([0, 1], [0, 1], 'b--') # dashed diagonal
plt.axis([0, 1, 0, 1])
plt.xlabel('FPR')
plt.ylabel('TPR(Recall)')
plt.grid(True)
fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)]
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:")
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:")
plt.plot([fpr_90], [recall_90_precision], "ro")
plt.show()
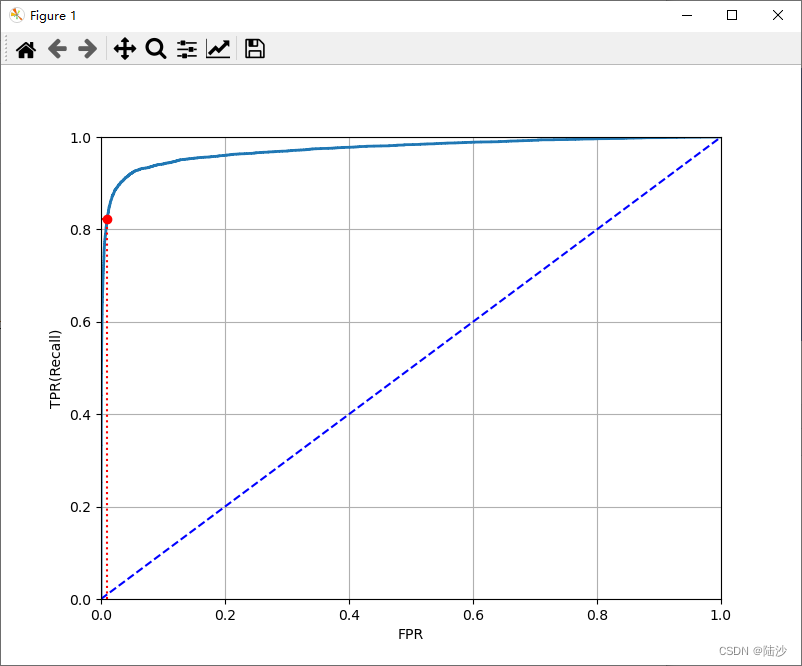
比较两个分类器的好坏可以用AUC。AUC就是area under the curve,指ROC曲线下面的面积。最好的分类器auc=1,随便一个分类器auc=0.5,scikit learn提供了计算函数。
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_train_2, y_scores))
# 0.9735367947441673
另一种曲线PR:
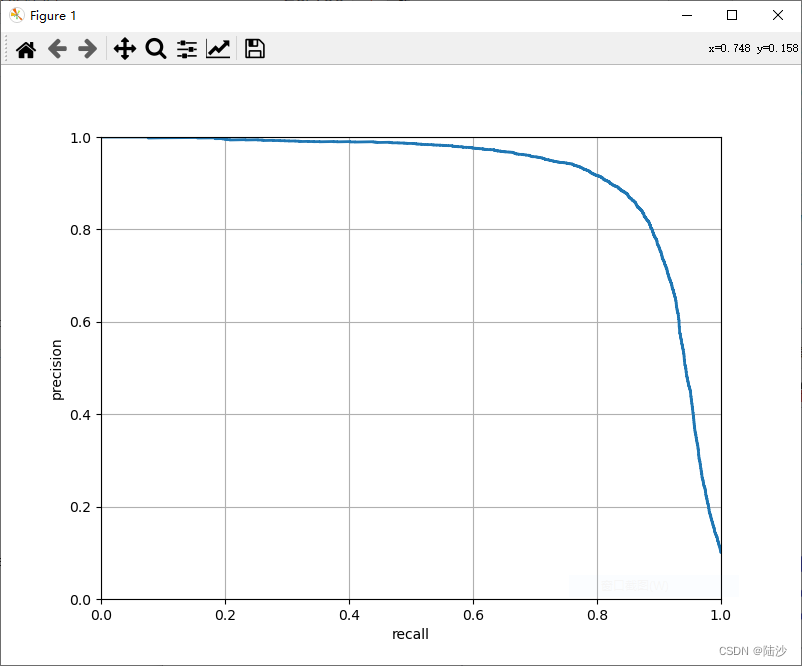
选PR还是ROC?
如果positive类比较少或者相比false negative,更关心false positive,那就应该使用PR,否则使用ROC。
比较随机森林和SGD:
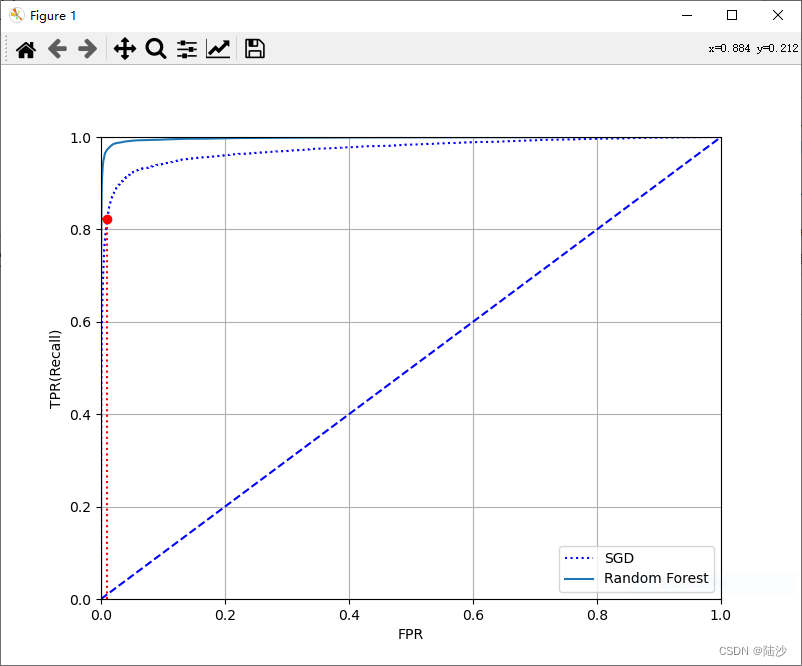
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve
forest_clf = RandomForestClassifier(random_state=42)
# 返回值是一个array,每行代表一个实例,包含其在各类的概率
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_2, cv=4,
method="predict_proba")
# 取第二列
y_scores_forest = y_probas_forest[:, 1]
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_2, y_scores_forest)
fpr, tpr, thresholds = roc_curve(y_train_2, y_scores)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr,"b:", label="SGD")
plt.plot(fpr_forest, tpr_forest, label="Random Forest")
plt.plot([0, 1], [0, 1], 'b--') # dashed diagonal
plt.legend(loc="lower right")
plt.axis([0, 1, 0, 1])
plt.xlabel('FPR')
plt.ylabel('TPR(Recall)')
plt.grid(True)
fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)]
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:")
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:")
plt.plot([fpr_90], [recall_90_precision], "ro")
plt.show()