视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)
- 尚硅谷大数据技术Hadoop教程-笔记01【大数据概论】
- 尚硅谷大数据技术Hadoop教程-笔记02【Hadoop-入门】
- 尚硅谷大数据技术Hadoop教程-笔记03【Hadoop-HDFS】
- 尚硅谷大数据技术Hadoop教程-笔记04【Hadoop-MapReduce】
- 尚硅谷大数据技术Hadoop教程-笔记05【Hadoop-Yarn】
- 尚硅谷大数据技术Hadoop教程-笔记06【Hadoop-生产调优手册】
- 尚硅谷大数据技术Hadoop教程-笔记07【Hadoop-源码解析】
目录
06_尚硅谷大数据技术之Hadoop(生产调优手册)V3.3
P143【143_尚硅谷_Hadoop_生产调优手册_核心参数_NN内存配置】14:15
P144【144_尚硅谷_Hadoop_生产调优手册_核心参数_NN心跳并发配置】03:12
P145【145_尚硅谷_Hadoop_生产调优手册_核心参数_开启回收站】07:16
P146【146_尚硅谷_Hadoop_生产调优手册_HDFS压测环境准备】05:55
P147【147_尚硅谷_Hadoop_生产调优手册_HDFS读写压测】18:55
P148【148_尚硅谷_Hadoop_生产调优手册_NN多目录配置】08:25
P149【149_尚硅谷_Hadoop_生产调优手册_DN多目录及磁盘间数据均衡】08:42
P150【150_尚硅谷_Hadoop_生产调优手册_添加白名单】10:02
P151【151_尚硅谷_Hadoop_生产调优手册_服役新服务器】13:07
P152【152_尚硅谷_Hadoop_生产调优手册_服务器间数据均衡】03:16
P153【153_尚硅谷_Hadoop_生产调优手册_黑名单退役服务器】07:46
P154【154_尚硅谷_Hadoop_生产调优手册_存储优化_5台服务器准备】11:21
P155【155_尚硅谷_Hadoop_生产调优手册_存储优化_纠删码原理】08:16
P156【156_尚硅谷_Hadoop_生产调优手册_存储优化_纠删码案例】10:42
P157【157_尚硅谷_Hadoop_生产调优手册_存储优化_异构存储概述】08:36
P158【158_尚硅谷_Hadoop_生产调优手册_存储优化_异构存储案例实操】17:40
P159【159_尚硅谷_Hadoop_生产调优手册_NameNode故障处理】09:09
P160【160_尚硅谷_Hadoop_生产调优手册_集群安全模式&磁盘修复】18:32
P161【161_尚硅谷_Hadoop_生产调优手册_慢磁盘监控】09:19
P162【162_尚硅谷_Hadoop_生产调优手册_小文件归档】08:11
P163【163_尚硅谷_Hadoop_生产调优手册_集群数据迁移】03:18
P164【164_尚硅谷_Hadoop_生产调优手册_MR跑的慢的原因】02:43
P165【165_尚硅谷_Hadoop_生产调优手册_MR常用调优参数】12:27
P166【166_尚硅谷_Hadoop_生产调优手册_MR数据倾斜问题】05:26
P167【167_尚硅谷_Hadoop_生产调优手册_Yarn生产经验】01:18
P168【168_尚硅谷_Hadoop_生产调优手册_HDFS小文件优化方法】10:15
P169【169_尚硅谷_Hadoop_生产调优手册_MapReduce集群压测】02:54
P170【170_尚硅谷_Hadoop_生产调优手册_企业开发场景案例】15:00
06_尚硅谷大数据技术之Hadoop(生产调优手册)V3.3
P143【143_尚硅谷_Hadoop_生产调优手册_核心参数_NN内存配置】14:15
第1章 HDFS—核心参数
连接成功
Last login: Wed Mar 29 10:21:43 2023 from 192.168.88.1
[root@node1 ~]# cd ../../
[root@node1 /]# cd /opt/module/hadoop-3.1.3/
[root@node1 hadoop-3.1.3]# cd /home/atguigu/
[root@node1 atguigu]# su atguigu
[atguigu@node1 ~]$ bin/myhadoop.sh start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [node1]
Starting datanodes
Starting secondary namenodes [node3]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
[atguigu@node1 ~]$ jpsall
bash: jpsall: 未找到命令...
[atguigu@node1 ~]$ bin/jpsall
=============== node1 ===============
28416 NameNode
29426 NodeManager
29797 JobHistoryServer
28589 DataNode
36542 Jps
=============== node2 ===============
19441 DataNode
20097 ResourceManager
20263 NodeManager
27227 Jps
=============== node3 ===============
19920 NodeManager
26738 Jps
19499 SecondaryNameNode
19197 DataNode
[atguigu@node1 ~]$ jmap -heap 28416
Attaching to process ID 28416, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.241-b07
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 1031798784 (984.0MB)
NewSize = 21495808 (20.5MB)
MaxNewSize = 343932928 (328.0MB)
OldSize = 43515904 (41.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 153616384 (146.5MB)
used = 20087912 (19.157325744628906MB)
free = 133528472 (127.3426742553711MB)
13.076672863227923% used
From Space:
capacity = 11534336 (11.0MB)
used = 7559336 (7.209144592285156MB)
free = 3975000 (3.7908554077148438MB)
65.53767811168323% used
To Space:
capacity = 16777216 (16.0MB)
used = 0 (0.0MB)
free = 16777216 (16.0MB)
0.0% used
PS Old Generation
capacity = 68681728 (65.5MB)
used = 29762328 (28.383567810058594MB)
free = 38919400 (37.116432189941406MB)
43.33369131306655% used
16190 interned Strings occupying 1557424 bytes.
[atguigu@node1 ~]$ jmap -heap 19441
Attaching to process ID 19441, please wait...
Error attaching to process: sun.jvm.hotspot.debugger.DebuggerException: cannot open binary file
sun.jvm.hotspot.debugger.DebuggerException: sun.jvm.hotspot.debugger.DebuggerException: cannot open binary file
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal$LinuxDebuggerLocalWorkerThread.execute(LinuxDebuggerLocal.java:163)
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal.attach(LinuxDebuggerLocal.java:278)
at sun.jvm.hotspot.HotSpotAgent.attachDebugger(HotSpotAgent.java:671)
at sun.jvm.hotspot.HotSpotAgent.setupDebuggerLinux(HotSpotAgent.java:611)
at sun.jvm.hotspot.HotSpotAgent.setupDebugger(HotSpotAgent.java:337)
at sun.jvm.hotspot.HotSpotAgent.go(HotSpotAgent.java:304)
at sun.jvm.hotspot.HotSpotAgent.attach(HotSpotAgent.java:140)
at sun.jvm.hotspot.tools.Tool.start(Tool.java:185)
at sun.jvm.hotspot.tools.Tool.execute(Tool.java:118)
at sun.jvm.hotspot.tools.HeapSummary.main(HeapSummary.java:49)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.tools.jmap.JMap.runTool(JMap.java:201)
at sun.tools.jmap.JMap.main(JMap.java:130)
Caused by: sun.jvm.hotspot.debugger.DebuggerException: cannot open binary file
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal.attach0(Native Method)
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal.access$100(LinuxDebuggerLocal.java:62)
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal$1AttachTask.doit(LinuxDebuggerLocal.java:269)
at sun.jvm.hotspot.debugger.linux.LinuxDebuggerLocal$LinuxDebuggerLocalWorkerThread.run(LinuxDebuggerLocal.java:138)
[atguigu@node1 ~]$ jmap -heap 28589
Attaching to process ID 28589, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.241-b07
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 1031798784 (984.0MB)
NewSize = 21495808 (20.5MB)
MaxNewSize = 343932928 (328.0MB)
OldSize = 43515904 (41.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 102236160 (97.5MB)
used = 89542296 (85.3941879272461MB)
free = 12693864 (12.105812072753906MB)
87.58378248948317% used
From Space:
capacity = 7864320 (7.5MB)
used = 7855504 (7.4915924072265625MB)
free = 8816 (0.0084075927734375MB)
99.88789876302083% used
To Space:
capacity = 9437184 (9.0MB)
used = 0 (0.0MB)
free = 9437184 (9.0MB)
0.0% used
PS Old Generation
capacity = 35651584 (34.0MB)
used = 8496128 (8.1025390625MB)
free = 27155456 (25.8974609375MB)
23.830997242647058% used
15014 interned Strings occupying 1322504 bytes.
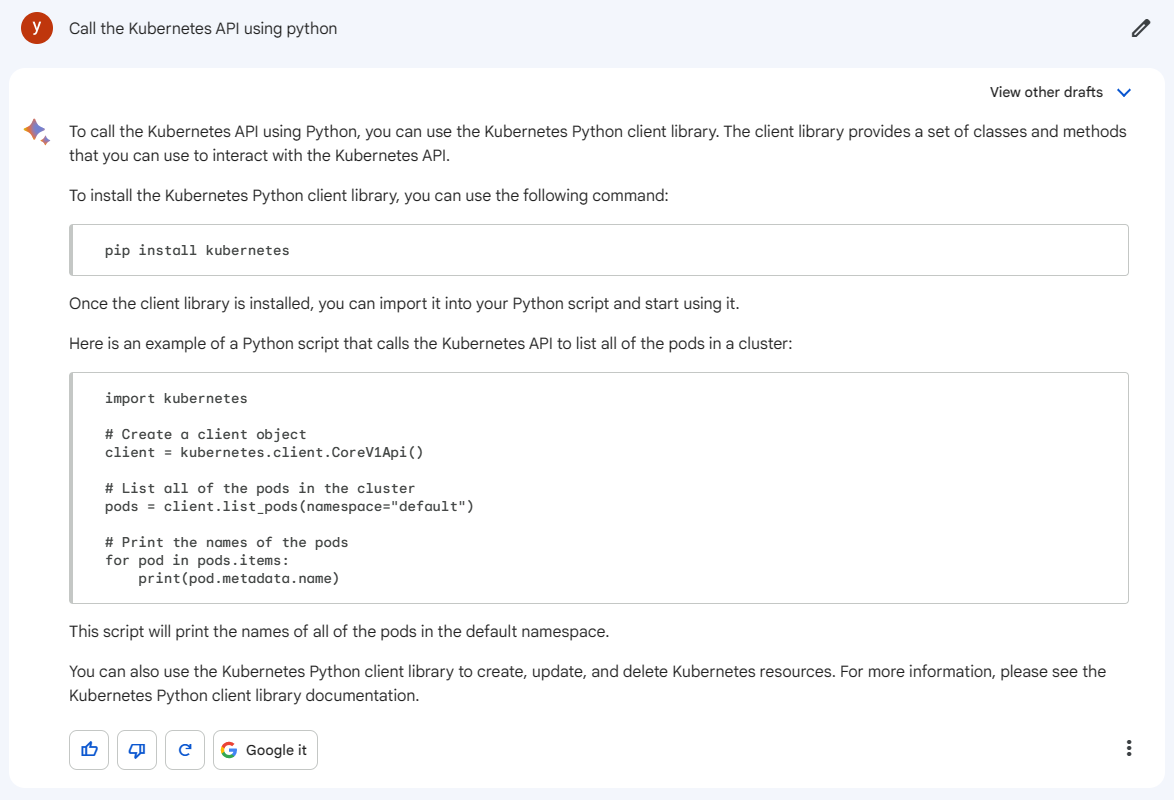
[atguigu@node1 ~]$ cd /opt/module/hadoop-3.1.3/etc/hadoop
[atguigu@node1 hadoop]$ xsync hadoop-env.sh
==================== node1 ====================
sending incremental file list
sent 62 bytes received 12 bytes 148.00 bytes/sec
total size is 16,052 speedup is 216.92
==================== node2 ====================
sending incremental file list
hadoop-env.sh
sent 849 bytes received 173 bytes 2,044.00 bytes/sec
total size is 16,052 speedup is 15.71
==================== node3 ====================
sending incremental file list
hadoop-env.sh
sent 849 bytes received 173 bytes 2,044.00 bytes/sec
total size is 16,052 speedup is 15.71
[atguigu@node1 hadoop]$ /home/atguigu/bin/myhadoop.sh stop
=================== 关闭 hadoop集群 ===================
--------------- 关闭 historyserver ---------------
--------------- 关闭 yarn ---------------
Stopping nodemanagers
Stopping resourcemanager
--------------- 关闭 hdfs ---------------
Stopping namenodes on [node1]
Stopping datanodes
Stopping secondary namenodes [node3]
[atguigu@node1 hadoop]$ /home/atguigu/bin/myhadoop.sh start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [node1]
Starting datanodes
Starting secondary namenodes [node3]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
[atguigu@node1 hadoop]$ jpsall
bash: jpsall: 未找到命令...
[atguigu@node1 hadoop]$ /home/atguigu/bin/jpsall
=============== node1 ===============
53157 DataNode
54517 Jps
53815 NodeManager
54087 JobHistoryServer
52959 NameNode
=============== node2 ===============
43362 NodeManager
43194 ResourceManager
42764 DataNode
44141 Jps
=============== node3 ===============
42120 DataNode
42619 NodeManager
42285 SecondaryNameNode
43229 Jps
[atguigu@node1 hadoop]$ jmap -heap 52959
Attaching to process ID 52959, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.241-b07
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 1073741824 (1024.0MB)
NewSize = 21495808 (20.5MB)
MaxNewSize = 357564416 (341.0MB)
OldSize = 43515904 (41.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 150470656 (143.5MB)
used = 94290264 (89.92220306396484MB)
free = 56180392 (53.577796936035156MB)
62.66355614213578% used
From Space:
capacity = 17825792 (17.0MB)
used = 0 (0.0MB)
free = 17825792 (17.0MB)
0.0% used
To Space:
capacity = 16777216 (16.0MB)
used = 0 (0.0MB)
free = 16777216 (16.0MB)
0.0% used
PS Old Generation
capacity = 66584576 (63.5MB)
used = 30315816 (28.911415100097656MB)
free = 36268760 (34.588584899902344MB)
45.529787559208906% used
15017 interned Strings occupying 1471800 bytes.
[atguigu@node1 hadoop]$ jmap -heap 53815
Attaching to process ID 53815, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.241-b07
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 1031798784 (984.0MB)
NewSize = 21495808 (20.5MB)
MaxNewSize = 343932928 (328.0MB)
OldSize = 43515904 (41.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 127926272 (122.0MB)
used = 40883224 (38.989280700683594MB)
free = 87043048 (83.0107192993164MB)
31.95842680383901% used
From Space:
capacity = 8388608 (8.0MB)
used = 8371472 (7.9836578369140625MB)
free = 17136 (0.0163421630859375MB)
99.79572296142578% used
To Space:
capacity = 10485760 (10.0MB)
used = 0 (0.0MB)
free = 10485760 (10.0MB)
0.0% used
PS Old Generation
capacity = 37748736 (36.0MB)
used = 11004056 (10.494285583496094MB)
free = 26744680 (25.505714416503906MB)
29.15079328748915% used
14761 interned Strings occupying 1313128 bytes.
[atguigu@node1 hadoop]$ P144【144_尚硅谷_Hadoop_生产调优手册_核心参数_NN心跳并发配置】03:12
Linux系统-让用户自定义脚本在任意地方都可执行-配置方法
1.2 NameNode心跳并发配置
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
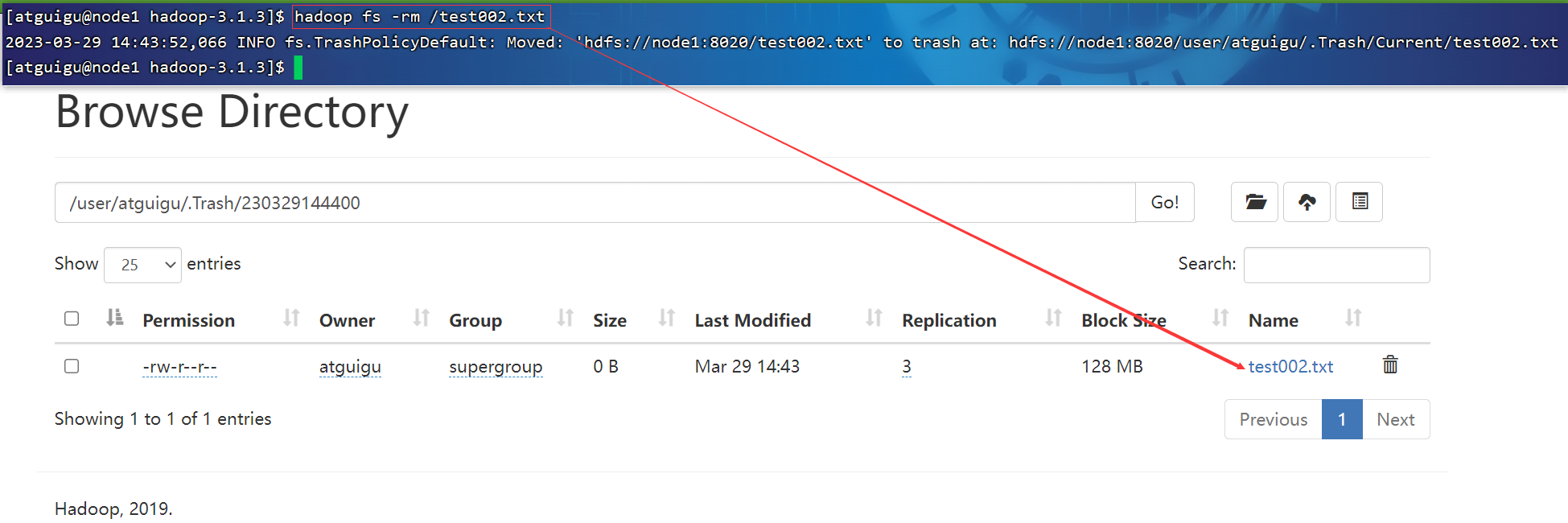
P145【145_尚硅谷_Hadoop_生产调优手册_核心参数_开启回收站】07:16
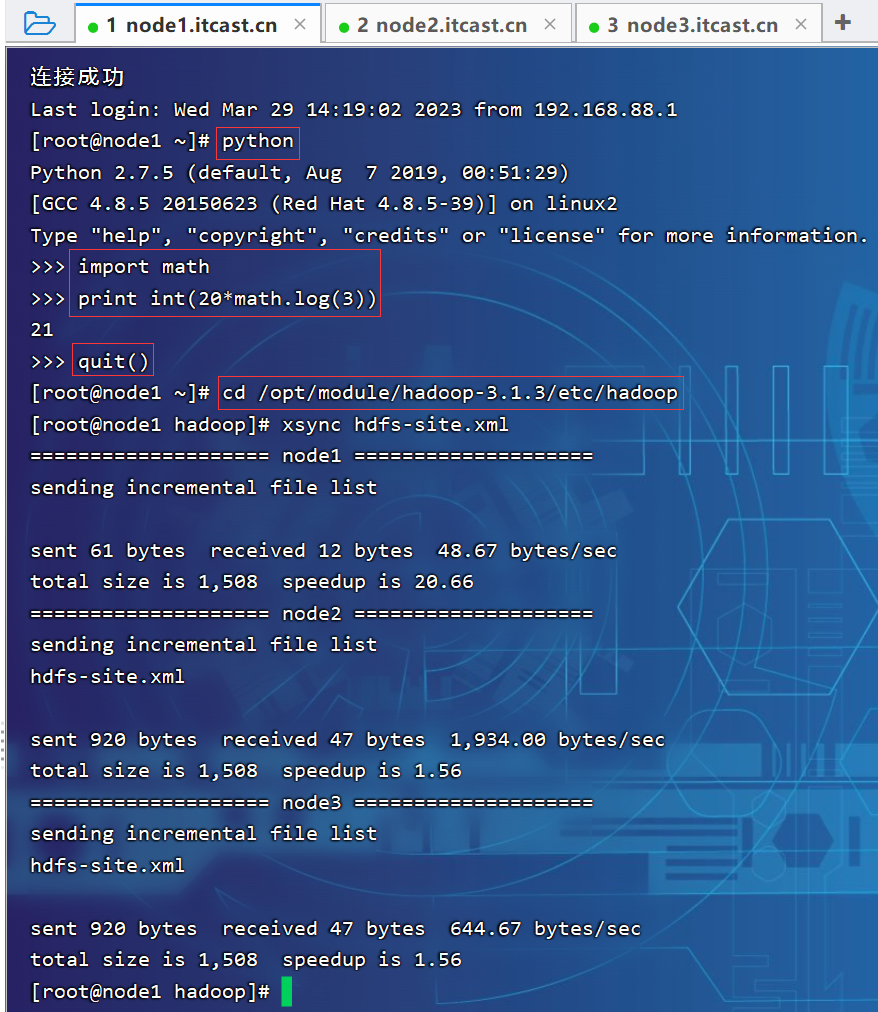
1.3 开启回收站配置
启用回收站,修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
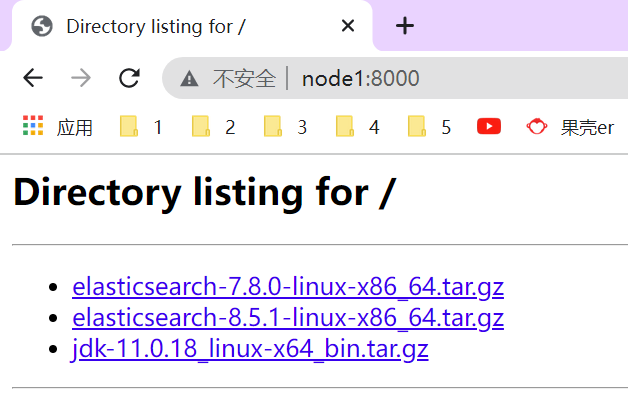
P146【146_尚硅谷_Hadoop_生产调优手册_HDFS压测环境准备】05:55
第2章 HDFS—集群压测

cd /opt/module/software/,python -m SimpleHTTPServer,允许外部通过“主机名称+端口号”的方式下载文件。
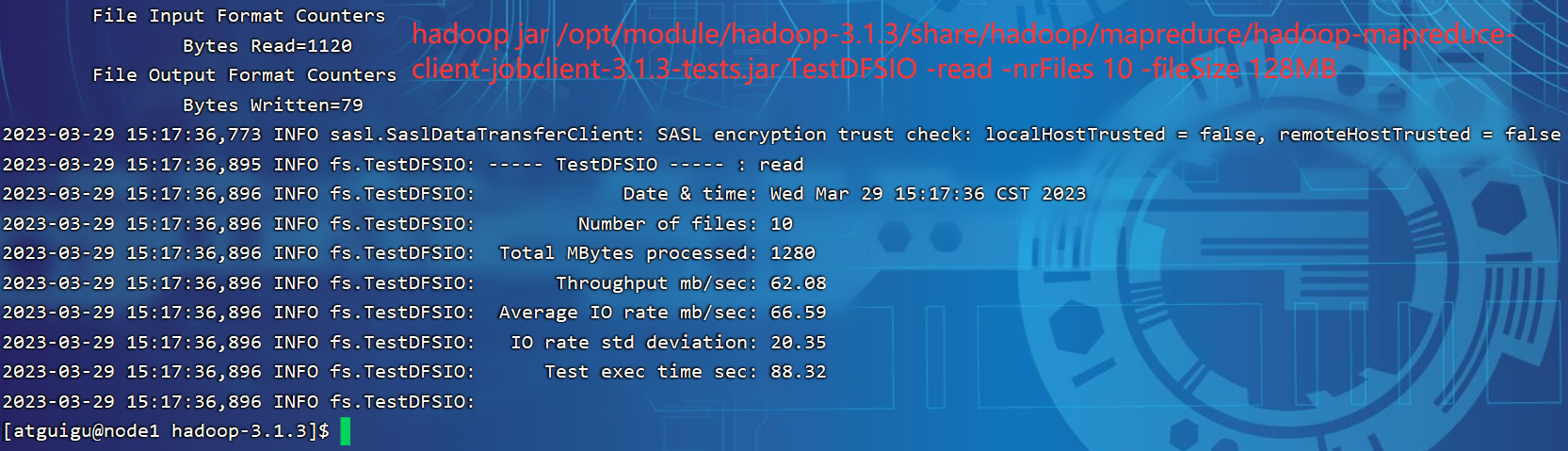
P147【147_尚硅谷_Hadoop_生产调优手册_HDFS读写压测】18:55
2.1 测试HDFS写性能
2.2 测试HDFS读性能

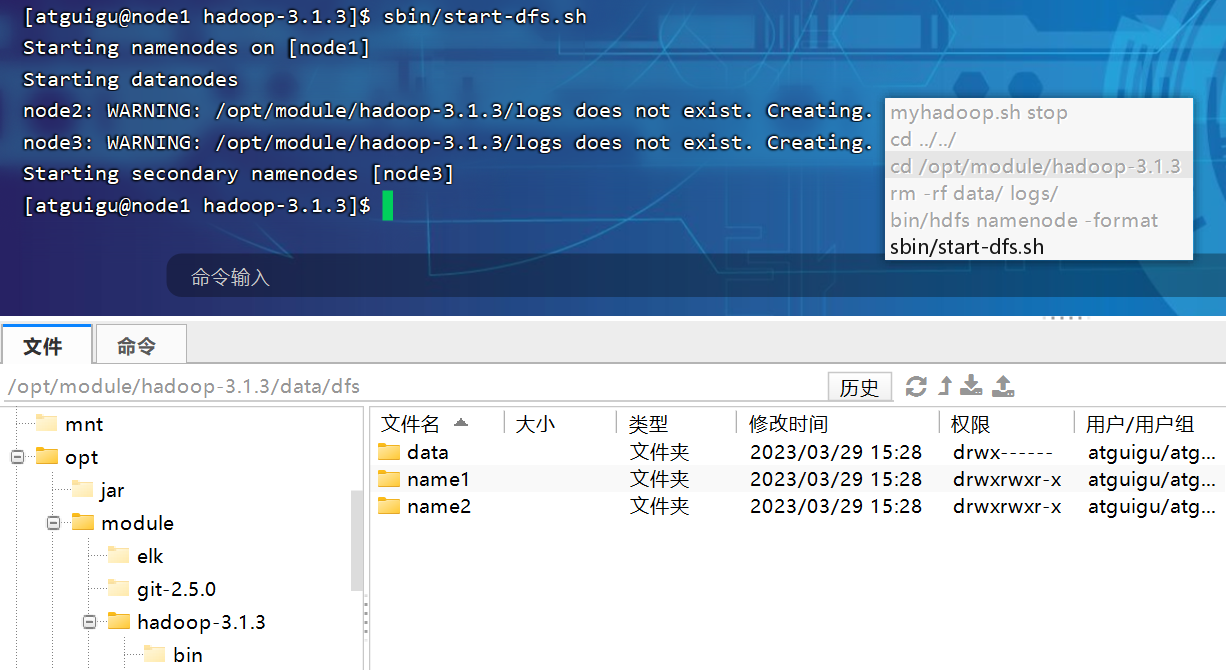
P148【148_尚硅谷_Hadoop_生产调优手册_NN多目录配置】08:25
第3章 HDFS—多目录
3.1 NameNode多目录配置
P149【149_尚硅谷_Hadoop_生产调优手册_DN多目录及磁盘间数据均衡】08:42
3.2 DataNode多目录配置
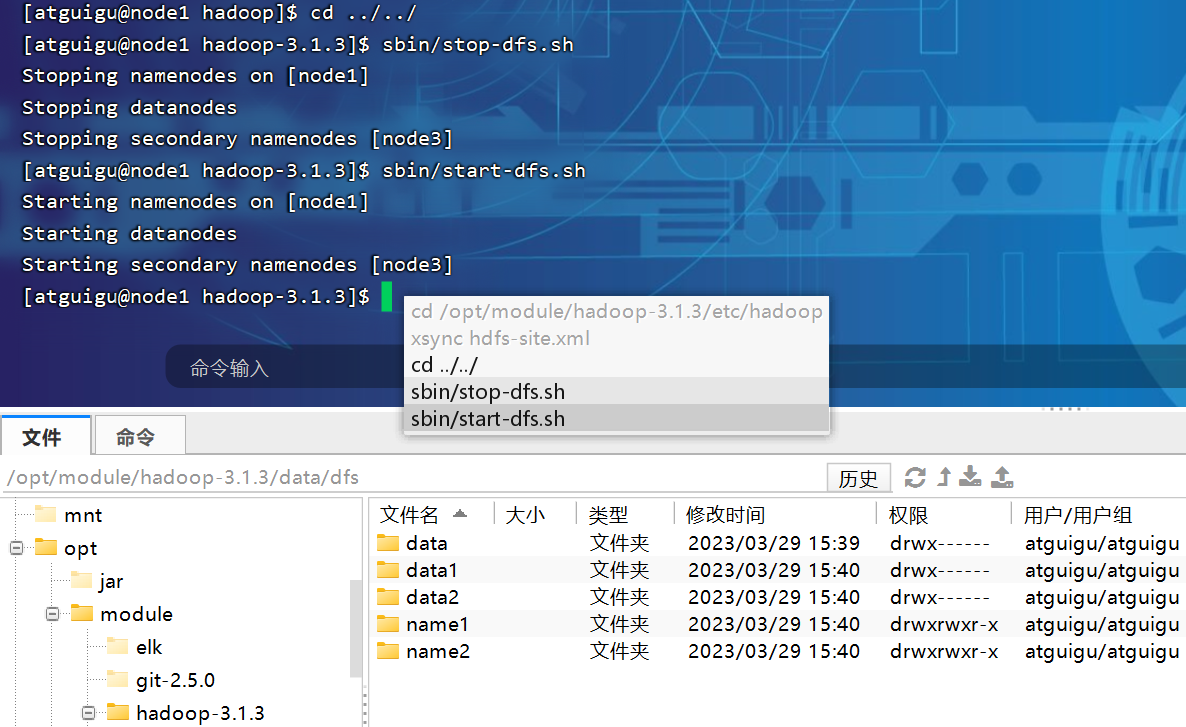
3.3 集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可以执行磁盘数据均衡命令。(Hadoop3.x新特性)
(1)生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json

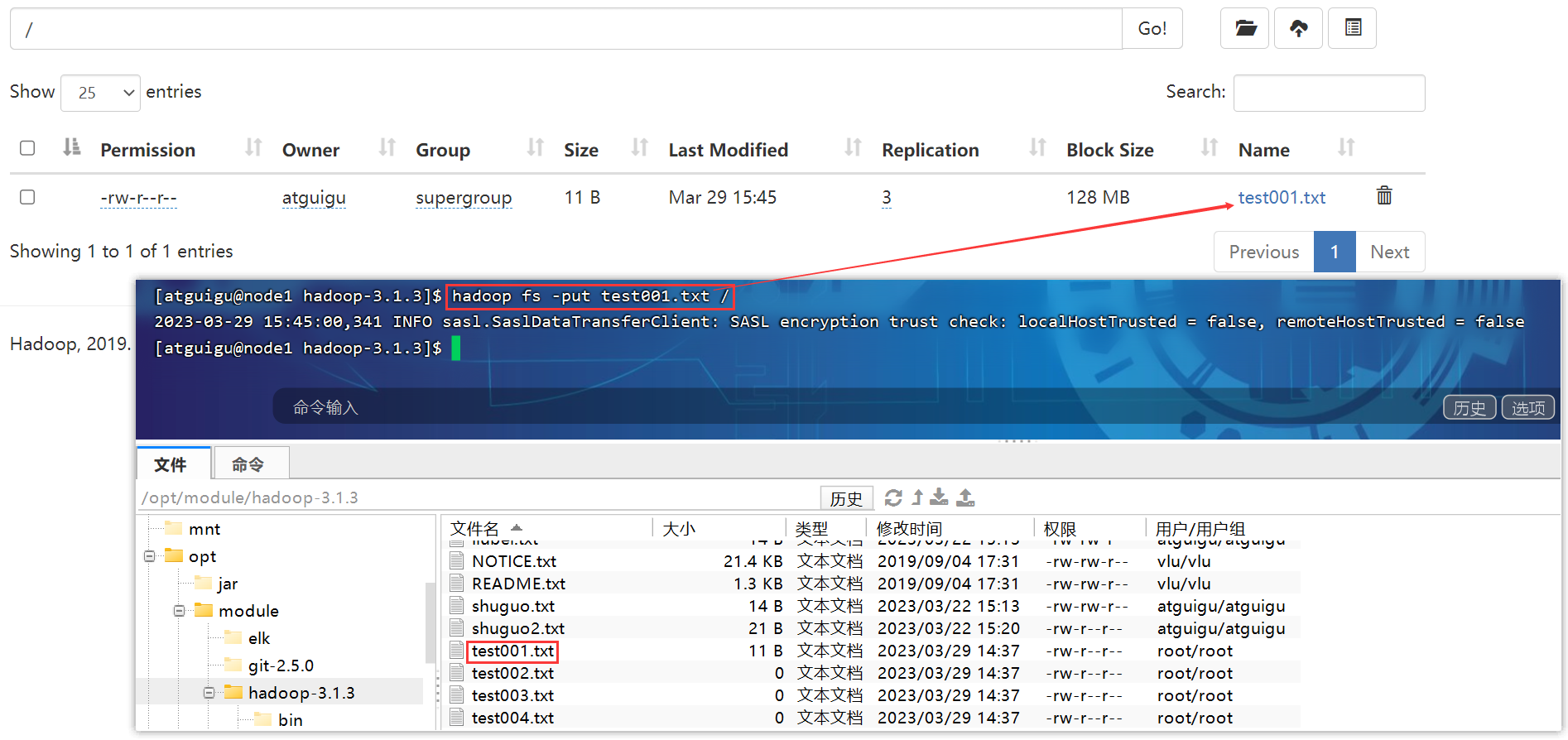
P150【150_尚硅谷_Hadoop_生产调优手册_添加白名单】10:02
第4章 HDFS—集群扩容及缩容
4.1 添加白名单
白名单:表示在白名单中配置的主机IP地址可以用来存储数据。
企业中:配置白名单,可以尽量防止黑客恶意访问攻击。

P151【151_尚硅谷_Hadoop_生产调优手册_服役新服务器】13:07
4.2 服役新服务器
需求:随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。


P152【152_尚硅谷_Hadoop_生产调优手册_服务器间数据均衡】03:16
4.3 服务器间数据均衡
P153【153_尚硅谷_Hadoop_生产调优手册_黑名单退役服务器】07:46
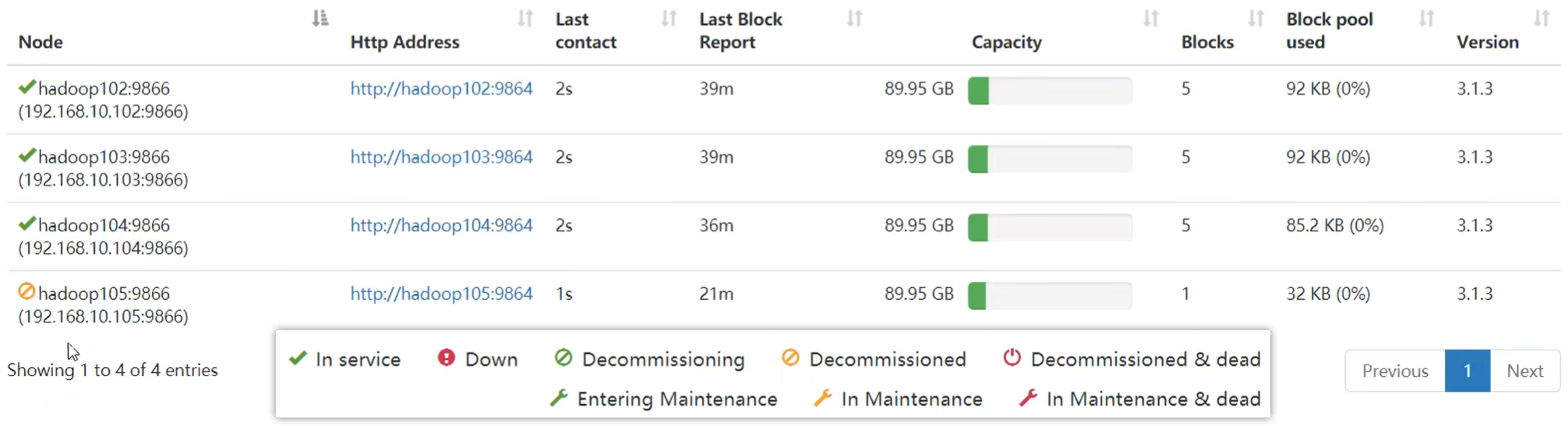
4.4 黑名单退役服务器
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据。
企业中:配置黑名单,用来退役服务器。
P154【154_尚硅谷_Hadoop_生产调优手册_存储优化_5台服务器准备】11:21
克隆虚拟机,删除hadoop-3.1.3目录下的data与logs,修改xsync、myhadoop.sh、jpsall脚本。
P155【155_尚硅谷_Hadoop_生产调优手册_存储优化_纠删码原理】08:16
第5章 HDFS—存储优化
注:演示纠删码和异构存储需要一共5台虚拟机。尽量拿另外一套集群。提前准备5台服务器的集群。
5.1 纠删码
5.1.1 纠删码原理

P156【156_尚硅谷_Hadoop_生产调优手册_存储优化_纠删码案例】10:42
5.1.2 纠删码案例实操
纠删码策略是给具体一个路径设置。所有往此路径下存储的文件,都会执行此策略。
默认只开启对RS-6-3-1024k策略的支持,如要使用别的策略需要提前启用。

P157【157_尚硅谷_Hadoop_生产调优手册_存储优化_异构存储概述】08:36
5.2 异构存储(冷热数据分离)
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
5.2.1 异构存储Shell操作
(1)查看当前有哪些存储策略可以用
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs storagepolicies -listPolicies
(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
(5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations
(6)查看集群节点
hadoop dfsadmin -report
P158【158_尚硅谷_Hadoop_生产调优手册_存储优化_异构存储案例实操】17:40
5.2.2 测试环境准备
1)测试环境描述
服务器规模:5台
集群配置:副本数为2,创建好带有存储类型的目录(提前创建)。
P159【159_尚硅谷_Hadoop_生产调优手册_NameNode故障处理】09:09
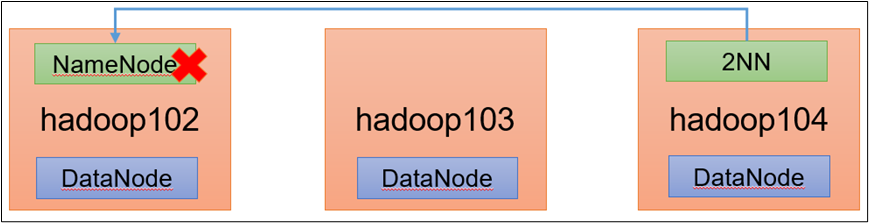
第6章 HDFS—故障排除
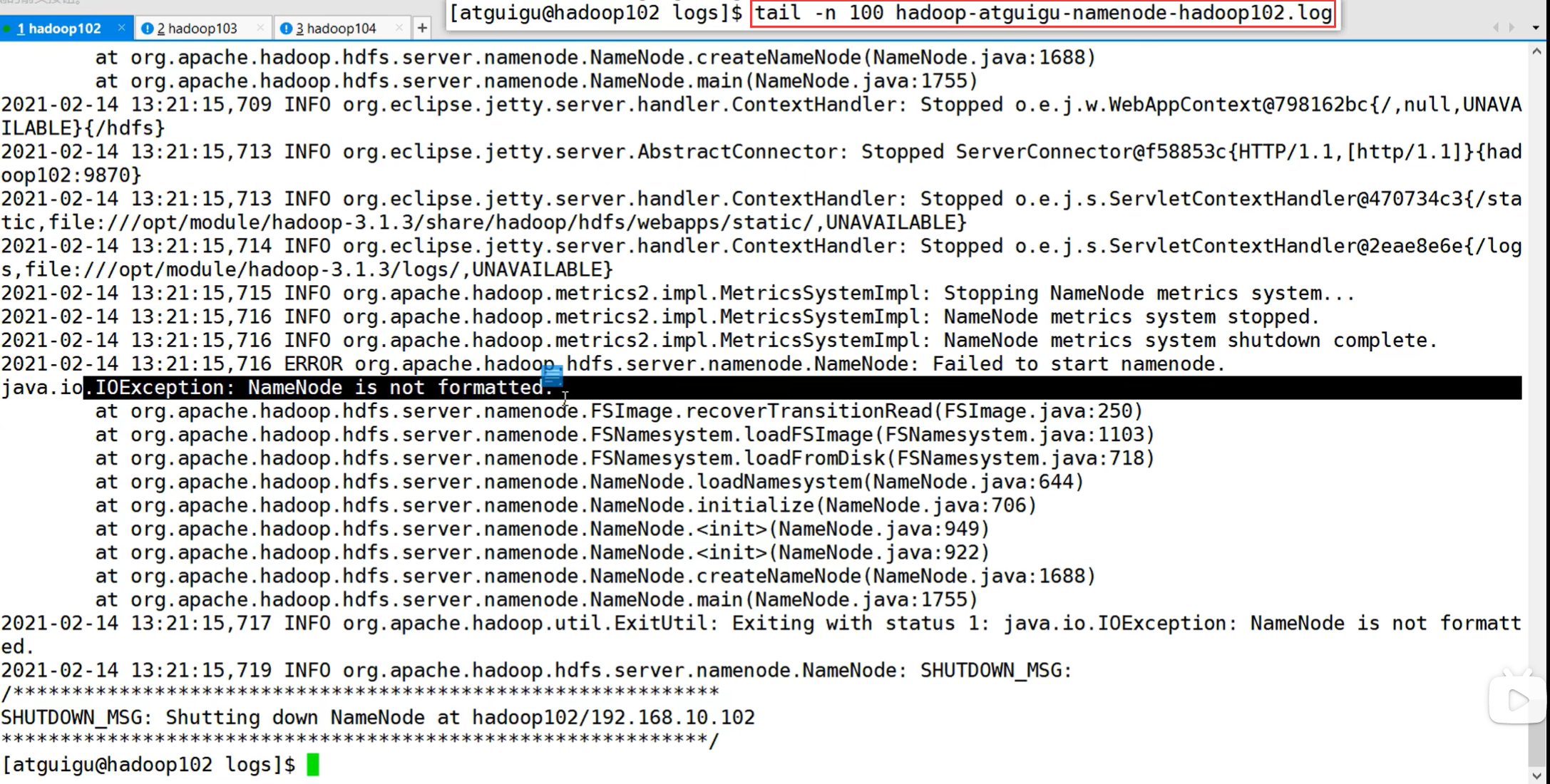
注意:采用三台服务器即可,恢复到Yarn开始的服务器快照。
拷贝SecondaryNameNode中数据到原NameNode存储数据目录。namenode挂掉了,就将secondNamenode的数据拷贝过去。

P160【160_尚硅谷_Hadoop_生产调优手册_集群安全模式&磁盘修复】18:32
6.2 集群安全模式&磁盘修复
1)安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
2)进入安全模式场景
- NameNode在加载镜像文件和编辑日志期间处于安全模式;
- NameNode再接收DataNode注册时,处于安全模式
P161【161_尚硅谷_Hadoop_生产调优手册_慢磁盘监控】09:19
6.3 慢磁盘监控
“慢磁盘”指的时写入数据非常慢的一类磁盘。其实慢性磁盘并不少见,当机器运行时间长了,上面跑的任务多了,磁盘的读写性能自然会退化,严重时就会出现写入数据延时的问题。
如何发现慢磁盘?
正常在HDFS上创建一个目录,只需要不到1s的时间。如果你发现创建目录超过1分钟及以上,而且这个现象并不是每次都有。只是偶尔慢了一下,就很有可能存在慢磁盘。
可以采用如下方法找出是哪块磁盘慢:
1)通过心跳未联系时间。
2)fio命令,测试磁盘的读写性能。
P162【162_尚硅谷_Hadoop_生产调优手册_小文件归档】08:11
6.4 小文件归档
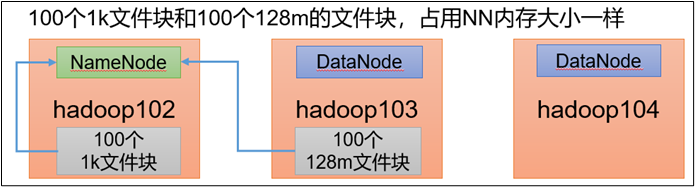
1)HDFS存储小文件弊端
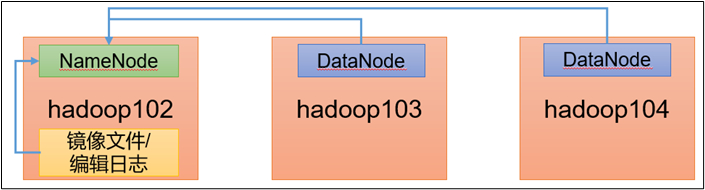
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2)解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
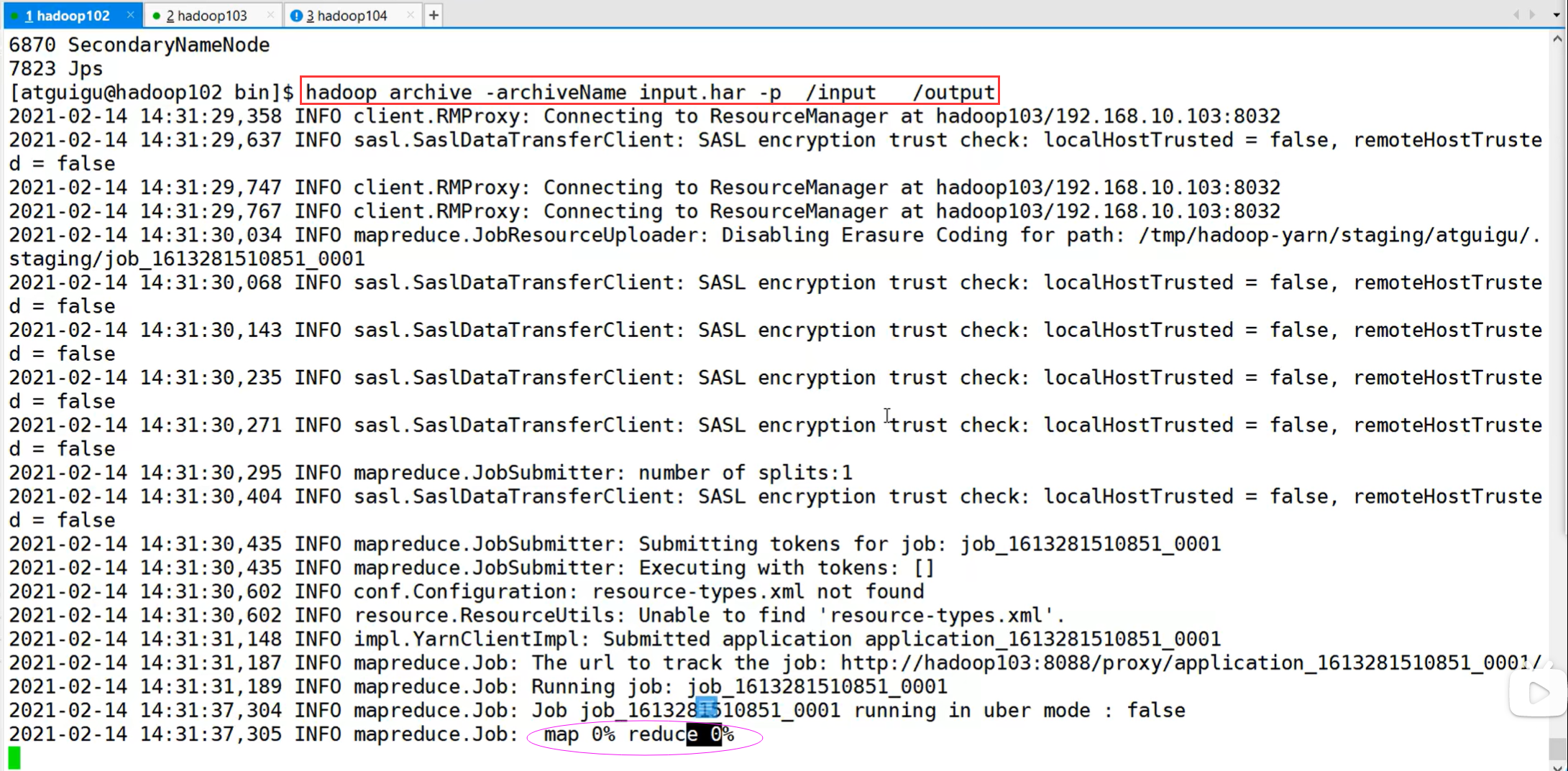
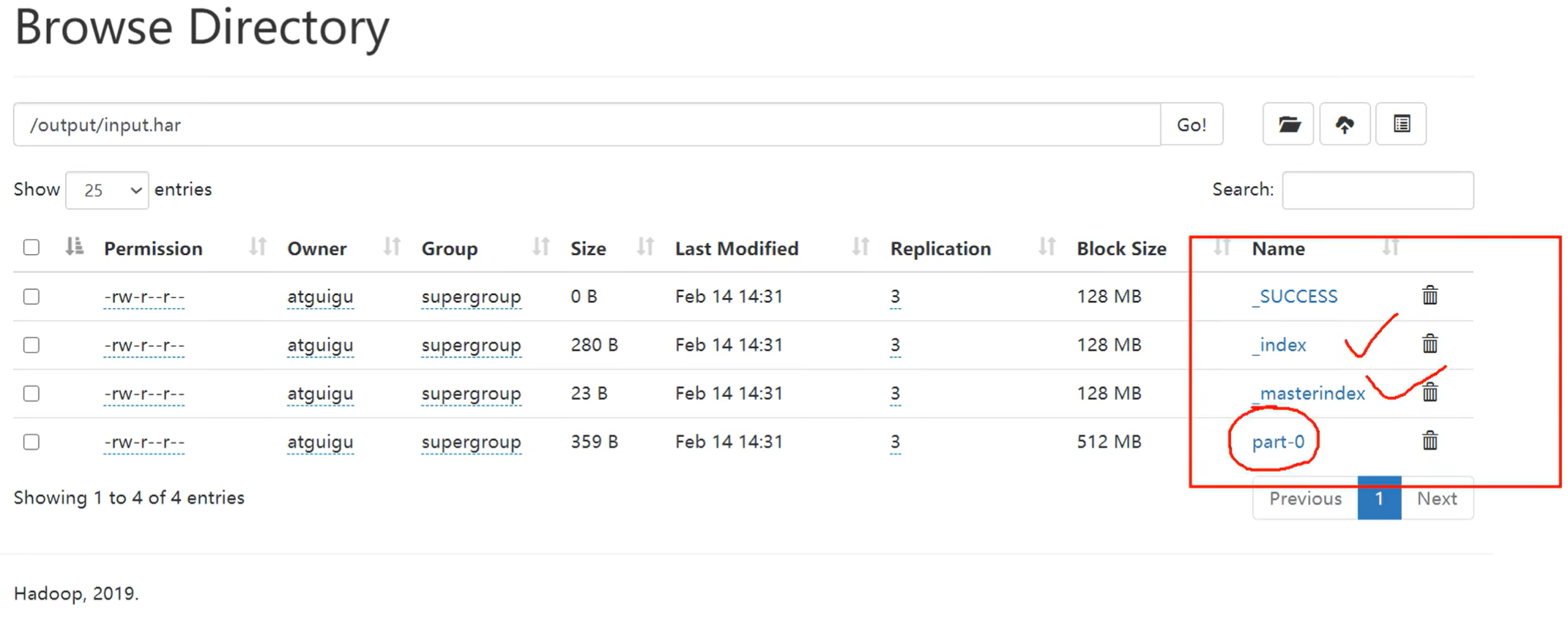
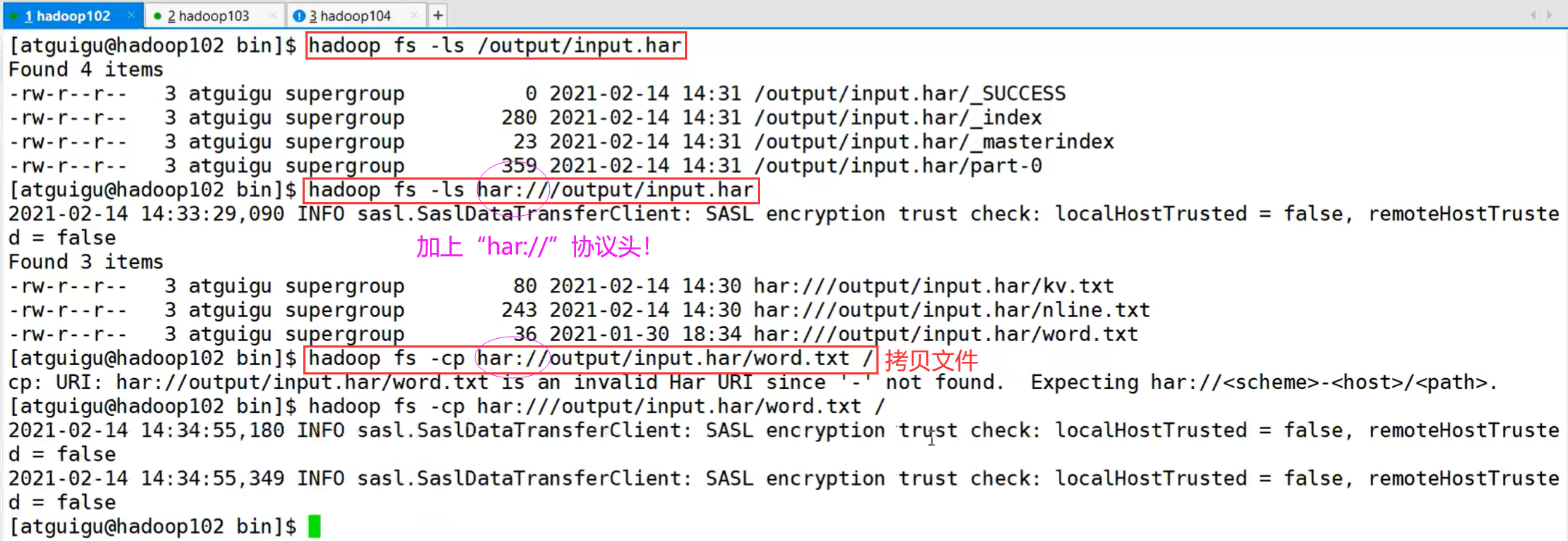
P163【163_尚硅谷_Hadoop_生产调优手册_集群数据迁移】03:18
第7章 HDFS—集群迁移
7.1 Apache和Apache集群间数据拷贝
7.2 Apache和CDH集群间数据拷贝
P164【164_尚硅谷_Hadoop_生产调优手册_MR跑的慢的原因】02:43
第8章 MapReduce生产经验
8.1 MapReduce跑的慢的原因
MapReduce程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘、网络
2)I/O操作优化
(1)数据倾斜
(2)Map运行时间太长,导致Reduce等待过久
(3)小文件过多
P165【165_尚硅谷_Hadoop_生产调优手册_MR常用调优参数】12:27
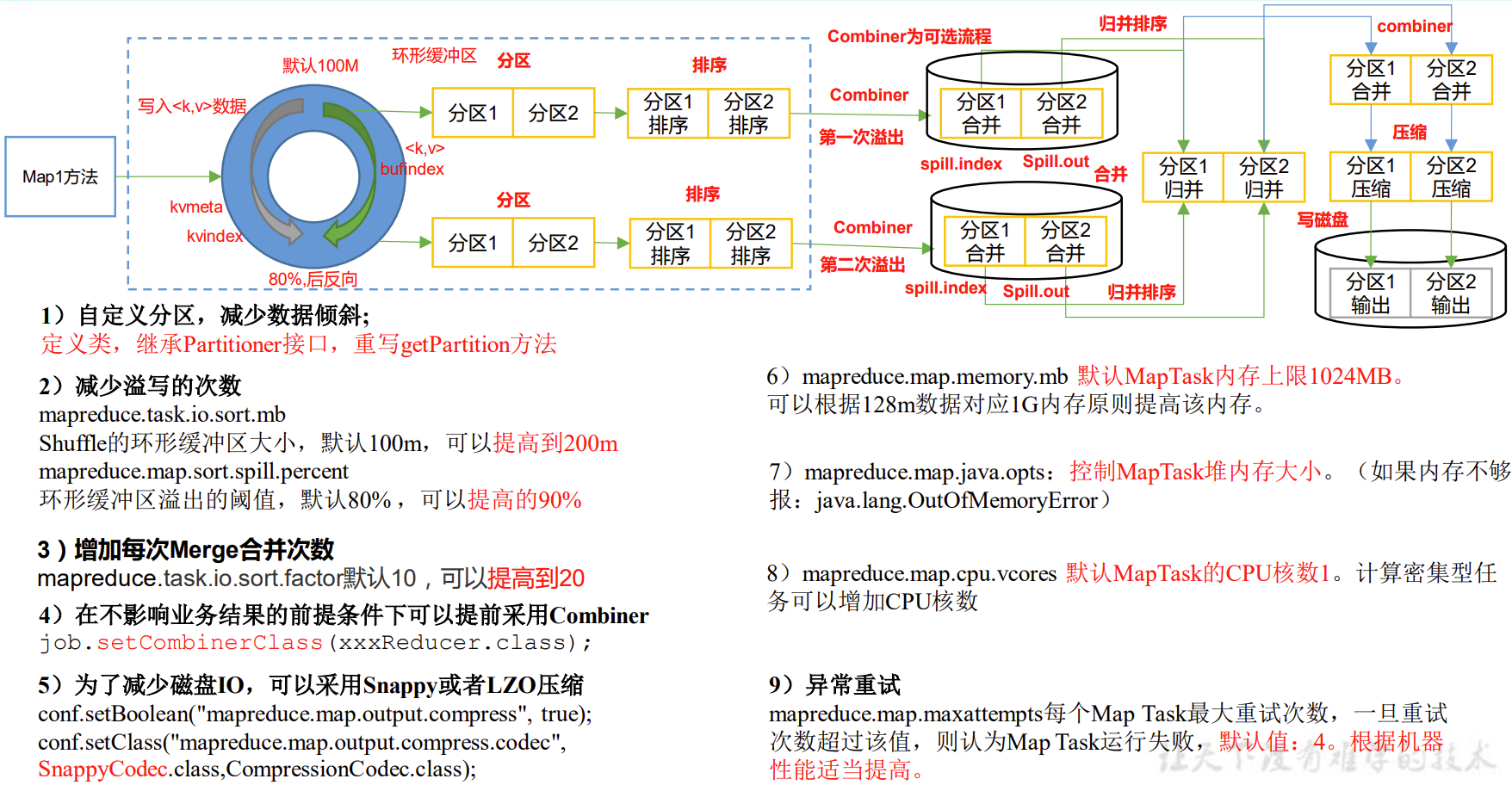
8.2 MapReduce常用调优参数

P166【166_尚硅谷_Hadoop_生产调优手册_MR数据倾斜问题】05:26
8.3 MapReduce数据倾斜问题
P167【167_尚硅谷_Hadoop_生产调优手册_Yarn生产经验】01:18
第9章 Hadoop-Yarn生产经验
9.1 常用的调优参数
9.2 容量调度器使用
9.3 公平调度器使用
P168【168_尚硅谷_Hadoop_生产调优手册_HDFS小文件优化方法】10:15
第10章 Hadoop综合调优
10.1 Hadoop小文件优化方法
10.1.1 Hadoop小文件弊端
10.1.2 Hadoop小文件解决方案
4)开启uber模式,实现JVM重用(计算方向)
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。
P169【169_尚硅谷_Hadoop_生产调优手册_MapReduce集群压测】02:54
10.2 测试MapReduce计算性能
P170【170_尚硅谷_Hadoop_生产调优手册_企业开发场景案例】15:00
10.3 企业开发场景案例
10.3.1 需求
10.3.2 HDFS参数调优
10.3.3 MapReduce参数调优
10.3.4 Yarn参数调优
10.3.5 执行程序