目录
About
Install
macOS Homebrew
macOS、Linux和WSL上的二进制文件
Windows上的二进制文件(非WSL)
从源代码生成和安装
Usage
Pretty print
dsq的管道数据
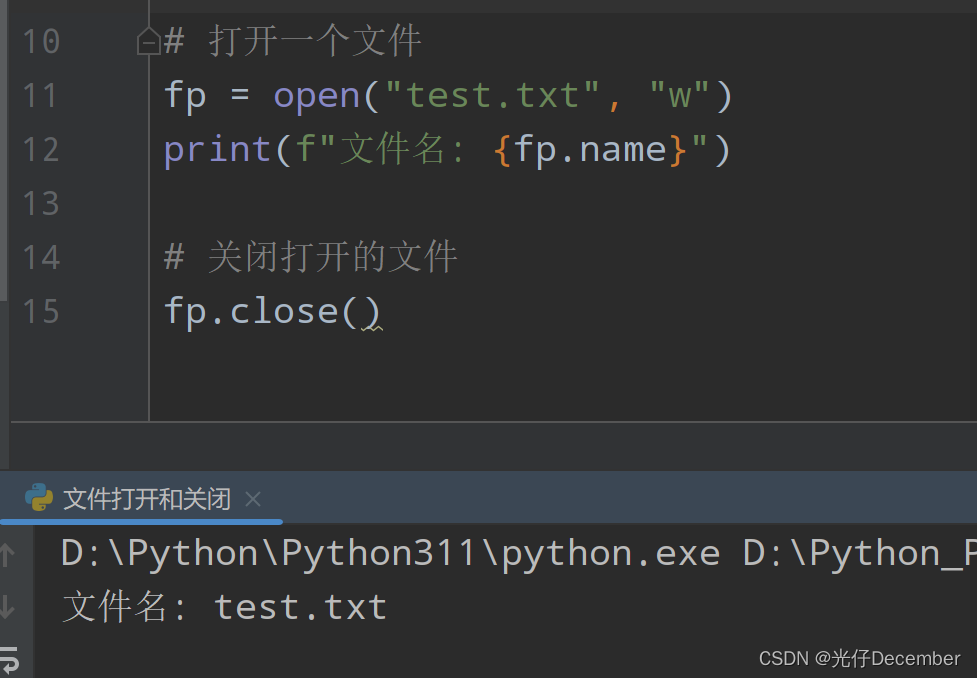
多个文件和连接
无需查询即可将数据转换为JSON
嵌套在对象中的对象数组
嵌套对象值
Nested arrays
REGEXP
Standard Library
输出列顺序
转储推断架构
Caching
Interactive REPL
转换CSV和TSV文件中的数字
Supported Data Types
Engine
Comparisons
Benchmark
Notes
About
这是DataStation(GUI)的CLI配套工具,用于对数据文件运行SQL查询。因此,如果您想要这个GUI版本,请查看DataStation。
Install
每个版本都提供了amd64(x86_64)的二进制文件。
macOS Homebrew
dsq在macOS Homebrew上可用:
$ brew install dsq
macOS、Linux和WSL上的二进制文件
在macOS、Linux和WSL上,您可以运行以下操作:
$ curl -LO "https://github.com/multiprocessio/dsq/releases/download/0.20.2/dsq-$(uname -s | awk '{ print tolower($0) }')-x64-0.20.2.zip"
$ unzip dsq-*-0.20.2.zip
$ sudo mv dsq /usr/local/bin/dsq
或者从发布页面手动安装,解压并将dsq添加到$PATH。
Windows上的二进制文件(非WSL)
下载最新的Windows版本,解压它,并将dsq添加到$PATH。
从源代码生成和安装
如果您在另一个平台或架构上,或者想要获取最新版本,可以使用Go1.18+:
$ go install github.com/multiprocessio/dsq@latest
dsq可能会在Go移植到的其他平台上工作,如AARC64和OpenBSD,但测试和构建仅在x86_64 Windows/Linux/macOS上运行。
Usage
您可以将数据管道传输到dsq,也可以将文件名传递给它。注意:管道数据在Windows上不起作用。
如果要传递文件,则其内容类型必须具有通常的扩展名。
For example:
$ dsq testdata.json "SELECT * FROM {} WHERE x > 10"
Or:
$ dsq testdata.ndjson "SELECT name, AVG(time) FROM {} GROUP BY name ORDER BY AVG(time) DESC"
Pretty print
默认情况下dsq打印丑陋的JSON。这是最有效的模式。
$ dsq testdata/userdata.parquet 'select count(*) from {}'
[{"count(*)":1000}
]
如果您想要更漂亮的JSON,可以通过管道dsq到jq。
$ dsq testdata/userdata.parquet 'select count(*) from {}' | jq
[
{
"count(*)": 1000
}
]
或者,您可以使用-p或--pretty中的dsq启用漂亮打印,这将在ASCII表中显示您的结果。
$ dsq --pretty testdata/userdata.parquet 'select count(*) from {}'
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
dsq的管道数据
当将数据传输到dsq时,需要设置-s标志并指定文件扩展名或MIME类型。
For example:
$ cat testdata.csv | dsq -s csv "SELECT * FROM {} LIMIT 1"
Or:
$ cat testdata.parquet | dsq -s parquet "SELECT COUNT(1) FROM {}"
多个文件和连接
您可以将多个文件传递给DSQ。只要支持有效格式的数据文件,就可以对所有文件作为表运行SQL。每个表都可以通过字符串{N}访问,其中N是命令行上传递的文件列表中文件的0-based索引。
例如,这连接了两个不同来源类型的数据集(CSV和JSON)。
$ dsq testdata/join/users.csv testdata/join/ages.json \
"select {0}.name, {1}.age from {0} join {1} on {0}.id = {1}.id"
[{"age":88,"name":"Ted"},
{"age":56,"name":"Marjory"},
{"age":33,"name":"Micah"}]
由于dsq使用标准SQL,您还可以提供file-table-names别名:
$ dsq testdata/join/users.csv testdata/join/ages.json \
"select u.name, a.age from {0} u join {1} a on u.id = a.id"
[{"age":88,"name":"Ted"},
{"age":56,"name":"Marjory"},
{"age":33,"name":"Micah"}]
无需查询即可将数据转换为JSON
作为dsq testdata.csv "SELECT * FROM {}"将支持的文件类型转换为JSON的缩写,您可以跳过查询,转换后的JSON将转储到stdout。
For example:
$ dsq testdata.csv
[{...some csv data...},{...some csv data...},...]
嵌套在对象中的对象数组
DataStation和dsq的SQL集成在对象数组上运行。如果对象数组恰好位于top-level,则无需执行任何操作。但是,如果数组数据嵌套在对象中,则可以向表引用添加“路径”参数。
例如,如果您有以下数据:
$ cat api-results.json
{
"data": {
"data": [
{"id": 1, "name": "Corah"},
{"id": 3, "name": "Minh"}
]
},
"total": 2
}
您需要告诉dsq数组数据的路径是"data.data":
$ dsq --pretty api-results.json 'SELECT * FROM {0, "data.data"} ORDER BY id DESC'
+----+-------+
| id | name |
+----+-------+
| 3 | Minh |
| 1 | Corah |
+----+-------+
如果只有一个表,也可以使用速记{"path"}或{'path'}:
$ dsq --pretty api-results.json 'SELECT * FROM {"data.data"} ORDER BY id DESC'
+----+-------+
| id | name |
+----+-------+
| 3 | Minh |
| 1 | Corah |
+----+-------+
可以对路径使用单引号或双引号。
多张Excel工作表
包含多个工作表的Excel文件存储为一个对象,键为工作表名称,值为作为对象数组的工作表数据。
如果您有一个Excel文件,其中包含两个名为Sheet1和Sheet2的工作表,则可以在第二个工作表上运行dsq,方法是将工作表名称指定为路径:
$ dsq data.xlsx 'SELECT COUNT(1) FROM {"Sheet2"}'
限制:嵌套数组
不能指定通过数组的路径,只能指定对象。
嵌套对象值
举个例子最简单。假设您有以下名为user_addresses.json的JSON文件:
$ cat user_addresses.json
[
{"name": "Agarrah", "location": {"city": "Toronto", "address": { "number": 1002 }}},
{"name": "Minoara", "location": {"city": "Mexico City", "address": { "number": 19 }}},
{"name": "Fontoon", "location": {"city": "New London", "address": { "number": 12 }}}
]
可以按如下方式查询嵌套字段:
$ dsq user_addresses.json 'SELECT name, "location.city" FROM {}'
如果需要消除表格的歧义:
$ dsq user_addresses.json 'SELECT name, {}."location.city" FROM {}'
Caveat: PowerShell, CMD.exe
在PowerShell和CMD.exe上,必须用反斜杠转义内部双引号:
> dsq user_addresses.json 'select name, \"location.city\" from {}'
[{"location.city":"Toronto","name":"Agarrah"},
{"location.city":"Mexico City","name":"Minoara"},
{"location.city":"New London","name":"Fontoon"}]
解释了嵌套对象
嵌套对象被折叠,它们的新列名成为.连接的值的JSON路径。路径中的实际点必须用反斜杠转义。因为.在SQL中是一个特殊字符,所以必须引用整个新列名。
限制:整个对象检索
您无法查询整个对象,必须请求生成标量值的特定路径。
例如,在上面的user_addresses.json示例中,您不能这样做:
$ dsq user_addresses.json 'SELECT name, {}."location" FROM {}'
因为location不是标量值。它是一个物体。
Nested arrays
嵌套数组存储在SQLite中时会转换为JSON字符串。由于SQLite支持查询JSON字符串,您可以将该数据作为结构化数据访问,即使它是一个字符串。
如果在fields.json中有这样的数据:
[
{"field1": [1]},
{"field1": [2]},
]
您可以请求整个字段:
$ dsq fields.json "SELECT field1 FROM {}" | jq
[
{
"field1": "[1]"
},
{
"field1": "[2]",
}
]
JSON operators
可以使用SQL JSON运算符获取数组中的第一个值。
$ dsq fields.json "SELECT field1->0 FROM {}" | jq
[
{
"field1->0": "1"
},
{
"field1->0": "2"
}
]
REGEXP
由于DataStation和dsq构建在SQLite上,因此可以使用x REGEXP 'y'进行过滤,其中x是某个列或值,y是REGEXP字符串。SQLite不选择regexp实现。DataStation和dsq使用Go的regexp实现,这比PCRE2更为有限,因为Go对PCRE2的支持还不是很成熟。
$ dsq user_addresses.json "SELECT * FROM {} WHERE name REGEXP 'A.*'"
[{"location.address.number":1002,"location.city":"Toronto","name":"Agarrah"}]
Standard Library
dsq注册go-sqlite3-stdlib,因此您可以访问许多不属于SQLite基的统计信息、url、数学、字符串和regexp函数。
查看所有可用扩展功能的项目文档。
输出列顺序
当发出JSON(即没有--pretty标志)时,对象内的键是无序的。
如果顺序对你很重要,你可以用jq过滤:dsq x.csv 'SELECT a, b FROM {}' | jq --sort-keys。
使用--pretty标志,列顺序完全按字母顺序排列。目前,顺序不可能依赖于SQL查询顺序。
转储推断架构
对于任何受支持的文件,您都可以转储推断出的模式,而不是转储数据或运行SQL查询。为此,设置--schema标志。
推断的模式非常简单,只支持JSON类型。如果底层格式(如Parquet)支持finer-grained数据类型(如int64),则这不会显示在推断的模式中。它将显示为number。
For example:
$ dsq testdata/avro/test_data.avro --schema --pretty
Array of
Object of
birthdate of
string
cc of
Varied of
Object of
long of
number or
Unknown
comments of
string
country of
string
email of
string
first_name of
string
gender of
string
id of
number
ip_address of
string
last_name of
string
registration_dttm of
string
salary of
Varied of
Object of
double of
number or
Unknown
title of
string
通过在设置--schema标志时省略--pretty标志,可以将其打印为结构化JSON字符串。
Caching
有时,您希望对不经常更改的数据集进行一些探索。通过打开--cache或-C标志,DataStation将把导入的数据存储在磁盘上,而不会在运行结束时删除它。
启用缓存后,DataStation将计算您指定的所有文件的SHA1总和。如果总和发生变化,则它将重新导入所有文件。否则,当运行带有缓存标志的其他查询时,将重用该现有数据库,而不会重新导入文件。
由于DataStation上没有缓存时使用in-memory数据库,因此打开缓存时的初始查询可能比关闭缓存时稍长。不过,后续查询将大大加快(对于大型数据集)。
例如,在此查询上使用缓存的第一次运行可能需要30秒:
$ dsq some-large-file.json --cache 'SELECT COUNT(1) FROM {}'
但是,当您运行另一个查询时,可能只需要1s。
$ dsq some-large-file.json --cache 'SELECT SUM(age) FROM {}'
不是因为我们缓存了任何结果,而是因为我们缓存了将文件导入SQLite的过程。
因此,即使您更改了查询,只要文件没有更改,缓存也是有效的。
为了使其永久化,您可以在您的环境中导出DSQ_CACHE=true。
Interactive REPL
使用-i或--interactive标志输入交互式REPL,您可以在其中运行多个SQL查询。
$ dsq some-large-file.json -i
dsq> SELECT COUNT(1) FROM {};
+----------+
| COUNT(1) |
+----------+
| 1000 |
+----------+
(1 row)
dsq> SELECT * FROM {} WHERE NAME = 'Kevin';
(0 rows)
转换CSV和TSV文件中的数字
CSV和TSV文件不允许指定其中包含的单个值的类型。默认情况下,所有值都被视为字符串。
这可能导致查询中出现意外结果。考虑以下示例:
$ cat scores.csv
name,score
Fritz,90
Rainer,95.2
Fountainer,100
$ dsq scores.csv "SELECT * FROM {} ORDER BY score"
[{"name":"Fountainer","score":"100"},
{"name":"Fritz","score":"90"},
{"name":"Rainer","score":"95.2"}]
注意score列仅包含数值。不过,按该列排序会产生意外的结果,因为这些值被视为字符串,并按词汇进行排序。(可以看出,单个分数作为字符串导入,因为它们在JSONresult.中被引用)
使用-n或--convert-numbers标志auto-detect并转换导入文件中的数值(整数和浮点):
$ dsq ~/scores.csv --convert-numbers "SELECT * FROM {} ORDER BY score"
[{"name":"Fritz","score":90},
{"name":"Rainer","score":95.2},
{"name":"Fountainer","score":100}]
注意现在分数是如何作为数字导入的,以及结果集中的记录是如何按其数值排序的。还请注意,JSON结果中不再引用单个分数。
为了使其永久化,您可以在您的环境中导出DSQ_CONVERT_NUMBERS=true。启用此选项将禁用某些优化。
Supported Data Types
| Name | File Extension(s) | Mime Type | Notes |
|---|---|---|---|
| CSV | csv | text/csv | |
| TSV | tsv, tab | text/tab-separated-values | |
| JSON | json | application/json | 必须是对象数组或对象数组的路径。 |
| Newline-delimited JSON | ndjson, jsonl | application/jsonlines | |
| Concatenated JSON | cjson | application/jsonconcat | |
| ORC | orc | orc | |
| Parquet | parquet | parquet | |
| Avro | avro | application/avro | |
| YAML | yaml, yml | application/yaml | |
| Excel | xlsx, xls | application/vnd.ms-excel | 如果有多张图纸,则必须指定图纸路径。 |
| ODS | ods | application/vnd.oasis.opendocument.spreadsheet | 如果有多张图纸,则必须指定图纸路径。 |
| Apache Error Logs | NA | text/apache2error | 当前仅在管道中工作。 |
| Apache Access Logs | NA | text/apache2access | 当前仅在管道中工作。 |
| Nginx Access Logs | NA | text/nginxaccess | 当前仅在管道中工作。 |
| LogFmt Logs | NA | text/logfmt | 当前仅在管道中工作。 |
Engine
在后台,dsq使用DataStation作为库,在后台,DataStation使用SQLite支持对任意(结构化)数据的此类SQL查询。
Comparisons
| Name | Link | Caching | Engine | Supported File Types | Binary Size |
|---|---|---|---|---|---|
| dsq | Here | Yes | SQLite | CSV、TSV、JSON的一些变体、拼花地板、Excel、ODS(OpenOffice Calc)、ORC、Avro、YAML、日志 | 49M |
| q | http://harelba.github.io/q/ | Yes | SQLite | CSV, TSV | 82M |
| textql | https://github.com/dinedal/textql | No | SQLite | CSV, TSV | 7.3M |
| octoql | https://github.com/cube2222/octosql | No | Custom engine | JSON, CSV, Excel, Parquet | 18M |
| csvq | https://github.com/mithrandie/csvq | No | Custom engine | CSV | 15M |
| sqlite-utils | https://github.com/simonw/sqlite-utils | No | SQLite | CSV, TSV | 不适用,不是一个二进制文件 |
| trdsql | https://github.com/noborus/trdsql | No | SQLite、MySQL或PostgreSQL | JSON、TSV、LTSV、TBLN、CSV的一些变体 | 14M |
| spysql | https://github.com/dcmoura/spyql | No | Custom engine | CSV, JSON, TEXT | 不适用,不是一个二进制文件 |
| duckdb | https://github.com/duckdb/duckdb | ? | Custom engine | CSV, Parquet | 35M |
Not included:
- clickhouse-local:这里列出的所有工具中速度最快的,但它太大了(超过2GB),不能合理地被认为是任何环境的好工具
- sqlite3:需要多个命令来接收CSV,对于one-liners来说并不太好
- datafusion-cli:非常快(仅比clickhouse-local慢),但需要多个命令来接收CSV,因此对于one-liners来说并不太好
Benchmark
该基准测试于2022年6月19日运行。它在OVH上的专用裸机实例上运行,具有:
- 64 GB DDR4 ECC 2133 MHz
- 软RAID中的2x450 GB SSD NVMe
- 英特尔至强E3-1230v6-4c/8t-3.5GHz/3.9 GHz
它对well-known纽约黄色出租车出行数据集运行SELECT passenger_count, COUNT(*), AVG(total_amount) FROM taxi.csv GROUP BY passenger_count查询。具体来说,使用2021 4月份的CSV文件。这是一个200MB的CSV文件,大约有200万行,18列,大部分是数值。
脚本在这里。它是octosql开发人员运行的基准测试的一种修改。
| Program | Version | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|---|
| dsq | 0.20.1(缓存打开) | 1.151 ± 0.010 | 1.131 | 1.159 | 1.00 |
| duckdb | 0.3.4 | 1.723 ± 0.023 | 1.708 | 1.757 | 1.50 ± 0.02 |
| octosql | 0.7.3 | 2.005 ± 0.008 | 1.991 | 2.015 | 1.74 ± 0.02 |
| q | 3.1.6(缓存打开) | 2.028 ± 0.010 | 2.021 | 2.055 | 1.76 ± 0.02 |
| sqlite3 * | 3.36.0 | 4.204 ± 0.018 | 4.177 | 4.229 | 3.64 ± 0.04 |
| trdsql | 0.10.0 | 12.972 ± 0.225 | 12.554 | 13.392 | 11.27 ± 0.22 |
| dsq | 0.20.1 (default) | 15.030 ± 0.086 | 14.895 | 15.149 | 13.06 ± 0.13 |
| textql | fca00ec | 19.148 ± 0.183 | 18.865 | 19.500 | 16.63 ± 0.21 |
| spyql | 0.6.0 | 16.985 ± 0.105 | 16.854 | 17.161 | 14.75 ± 0.16 |
| q | 3.1.6 (default) | 24.061 ± 0.095 | 23.954 | 24.220 | 20.90 ± 0.20 |
*虽然dsq和q构建在sqlite3之上,但sqlite3中没有内置的方法来缓存摄取的文件,而无需编写脚本
Not included:
- clickhouse-local:比任何一个都快,但超过2GB,因此不是合理的general-purposeCLI
- datafusion-cli:只比clickhouse-local慢,但需要多个命令来接收CSV,不能执行one-liners
- sqlite-utils:需要几分钟才能完成
Notes
OctoSQL、duckdb和SpyQL实现了自己的SQL引擎。dsq、q、trdsql和textql将数据复制到SQLite中,并依赖SQLite引擎执行查询。
实现自己的SQL引擎的工具在1)摄取和2)作用于数据子集(例如有限列或有限行)的查询方面可以做得更好。这些工具实现了SQL的ad-hoc子集,这些子集可能缺失或与您喜欢的语法不同。另一方面,依赖SQLite的工具具有提供well-tested和well-documentedSQL引擎的优势。DuckDB与众不同,因为它背后有一家专注的公司。
dsq在SQLite内置函数的基础上还附带了许多有用的函数(例如best-effort日期解析、URL解析/提取、统计函数等)。
转自项目内 README.md
multiprocessio/dsq: Commandline tool for running SQL queries against JSON, CSV, Excel, Parquet, and more. (github.com)![]() https://github.com/multiprocessio/dsq
https://github.com/multiprocessio/dsq
![[Java] Socket (UDP , TCP)](https://img-blog.csdnimg.cn/f31b3b461589484fa9d70bbdf539a532.png)