红酒分类案例中使用分箱处理
描述
在建立分类模型时,通常需要对连续特征进行离散化(Discretization)处理 ,特征离散化后,模型更加稳定,降低了过拟合风险。离散化也叫分箱(binning),是指把连续的特征值划分为离散的特征值(划分为不同的箱子),比如把0-100分的考试成绩由连续数值转换为80以上、60~80之间、60以下三个分箱值(可以用0、1、2或独热编码表示),分箱后有助于提升分类模型的表现。
本任务的实践内容包括:
1、学习并熟悉Scikit-learn中的分箱处理类KBinsDiscretizer。
2、在红酒预测案例中引入分箱处理,对比分类模型的性能。
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 0.24.2 numpy 1.19.5 pandas 1.1.5 ipython 7.16.3
分析
本任务涉及以下环节:
A)熟悉KBinsDiscretizer的参数及分箱策略
B)加载并观察红酒数据集
C)建立KNN分类模型,评估成绩
D)进行分箱预处理
E)对比模型在分箱后数据上的表现
实施
1、熟悉Scikit-learn的分箱功能
1、生成一组随机成绩
2、分别使用等宽、等频、聚类等策略以及独热编码方式进行分箱
from sklearn.preprocessing import KBinsDiscretizer
import numpy as np
# 随机生成一组成绩
np.random.seed(seed=1)
score = np.random.randint(0, 100, 12)
score.sort() # 排序
print(score)
# 等宽分箱(uniform),分4箱(n_bins),每个箱的数值宽度相同,数字顺序编码(ordinal)
bins =KBinsDiscretizer(n_bins=[4], encode='ordinal', strategy='uniform')
X = bins.fit_transform(score.reshape(-1, 1))
print(X.T)
# 等频分箱(uniform),分4箱(n_bins),每个箱的元素个数相同,数字顺序编码(ordinal)
bins =KBinsDiscretizer(n_bins=[4], encode='ordinal', strategy='quantile')
X = bins.fit_transform(score.reshape(-1, 1))
print(X.T)
# 聚类分箱(kmeans),分4箱,每个箱中的值到其1维K均值聚类簇心的距离相同,数字顺序编码(ordinal)
bins =KBinsDiscretizer(n_bins=[4], encode='ordinal', strategy='kmeans')
X = bins.fit_transform(score.reshape(-1, 1))
print(X.T)
# 等宽分箱(uniform),分4份(n_bins),每份数值宽度相同,独热编码(onehot)
bins =KBinsDiscretizer(n_bins=[4], encode='onehot', strategy='uniform')
X = bins.fit_transform(score.reshape(-1, 1))
print(X.toarray())
结果如下:
[ 1 5 9 12 16 37 64 71 72 75 76 79]
[[0. 0. 0. 0. 0. 1. 3. 3. 3. 3. 3. 3.]]
[[0. 0. 0. 1. 1. 1. 2. 2. 2. 3. 3. 3.]]
[[0. 0. 0. 0. 0. 1. 2. 2. 2. 3. 3. 3.]]
[[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]]
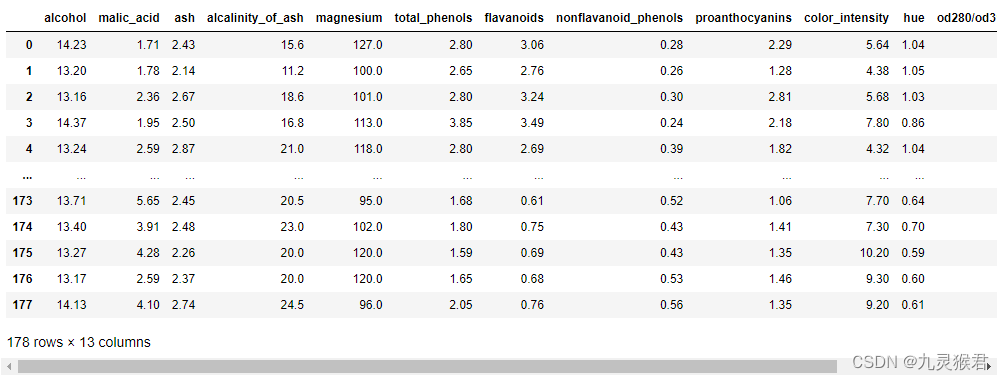
2、加载查看红酒数据集
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from IPython.display import display
import pandas as pd
# 加载、查看wine数据集
wine = load_wine()
df = pd.DataFrame(wine.data, columns=wine.feature_names)
display(df)
结果如下:
3、对比分箱前后KNN分类模型的性能
# 不进行分箱处理,直接拆分并使用KNN建模
X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, random_state=0)
knn = KNeighborsClassifier(5).fit(X_train, y_train)
score = knn.score(X_test, y_test)
print('Score without bins: %0.2f'%score) # 输出成绩
# 先进行分箱处理,再拆分建模,对比模型成绩
bins =KBinsDiscretizer(n_bins=[7 for i in range(13)], encode='ordinal', strategy='uniform')
data_bins = bins.fit_transform(wine.data)
X_train_bins, X_test_bins, y_train, y_test = train_test_split(data_bins, wine.target, random_state=0)
knn = KNeighborsClassifier(5).fit(X_train_bins, y_train)
score = knn.score(X_test_bins, y_test)
print('Score with bin: %0.2f'%score)
结果如下:
Score without bins: 0.73
Score with bin: 0.98
对连续特征进行分箱离散化后,分类模型的性能提升明显。