文章目录
- 0 前言
- 1 先来看看C语言中怎么处理这种字节数据
- 1.1 使用总结
- 2 再来看看Python当中是怎么处理字节数据的
0 前言
最近在尝试用PyQt做一个上位机,遇到很多关于字节字符串的问题,这里简单总结几个关键点。
1 先来看看C语言中怎么处理这种字节数据
玩嵌入式模块的应该知道,那种带字库的LCD模块,它里面的字库实际上编码方式就是GBK或者是GB2312,所谓“字库”,实际上就是一种字符编码和字符显示的像素编码的映射,这样在显示某个字符时,就不需要设置这个字符对应的显示像素,只需要传输这个字符对应的字库编码即可,代码编写方便很多。
所以在这种带字库的LCD显示设备当中,如果需要显示某个字符,只需要将需要显示的字符用对应的编码格式(前面提到的GBK或GB2312)进行编码。但是实际在写代码时,好像没有专门编码的步骤?
是的,这就引出了第一个问题:C语言怎么限定字符的编码方式, 复杂的函数不太清楚,这里提一个最简单也是最容易被忽略的点——C语言文本文件的编码方式。 不信可以在显示带字库LCD项目中,把显示部分的代码文件用utf8格式重新保存,这个时候显示大概率会变成乱码。
再说一个可以佐证的例子。在VS Code中新建一个文件(默认是utf8格式的),输入以下代码:
#include "stdio.h"
#include "string.h"
char s[] = "中文";
int main()
{
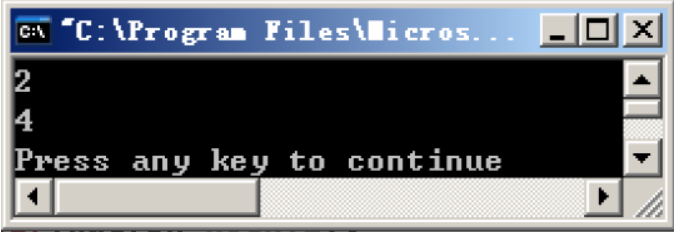
printf("中文");
printf("%d", strlen(s));
return 0;
}
然后再运行代码。如果终端使用的是powershell(5.x 或 7.x版本均可),那么大概率会输出乱码,因为powershell默认的编码方式是GBK,显示输出的UTF-8字符串当然是乱码了。
然后在右下角点击UTF-8,选择通过编码保存,选择GB2312格式,然后在重新运行,此时就会发现,终端就没有乱码了,因为输出的编码格式和终端的编码方式对上了。
总结来说,在C/C++中,程序输出(不管是输出到终端还是串口之类的)的字符串编码格式是和文件的编码方式直接挂钩的。
1.1 使用总结
那一般是怎么使用呢?这里还是以嵌入式中常用的串口输出为例。
首先我们要知道什么是字节数据。众所周知,在数据的传输过程中,是不可能直接传输我们人类能够识别的字符的,所有的内容都需要进行编码成二进制数据再进行传输,当然,一般是用十六进制表示,本质是一样的。8位二进制为一个字节。
因此就存在字符和字节数据的映射关系了,比如说规定“我”这个字符对应的二进制(十六进制为)0x01(随便的例子),那么当需要传输“我”这个字符时,那就需要传递0x01这个字节数据,此即编码。然后接收方收到这个字节数据,也按照同样的映射关系把“我”从0x01当中提取出来,此即解码。所以关键点就是两者需要使用相同的映射关系,此即编码方式,如UTF8,UTF16等等。
在C语言当中,数据的传输说实话非常随意。这个也可能是C语言设计的机制。举个例子,如果我想要传输“A”这个字符,我可以 直接传输这个字符'A' ,那么它在传输过程中会被自动按照文件编码方式编码成对应的字节数据;也可以 传输这个字符对应的数值 ,不管是二进制,十进制,十六进制都是可以的。同样,在进行运算的过程当中,字符也是可以直接作为数值进行运算的,取的就是其对应的编码值,即ASCII。
总结来说,C语言当中进行数据传输时,会非常随意,可以说没有字节数据这种概念,因为它基本可以视为就是数值,如果是在编码范围内的,也可以转换为(char()) 需要显示的字符串。
这样的设计的好处就在于传输的字节数据和显示用的字符串基本没有差别了,char可以直接运算,int数值也可以直接以字符的形式输出到终端。但是坏处可能就是太灵活,同时编码方式会受限于文本文件的编码格式。
2 再来看看Python当中是怎么处理字节数据的
相比于C语言当中的简单直接,Python在这部分比较复杂。最关键的就是它新增了字节字符串这个东西。
首先需要清楚,字节字符串本身并不是真正的字节数据,它只是一个字节数据的呈现而已,因为按照C语言中的设定,字符和字节都可以视为数值,但在python当中就不行:

也就是不能直接通过int去转换,因为它本身并不是数值。
- 字节字符串取值
那如果我就是想要取这些字节字符串中的数值怎么办?用下标去索引!

从这里可以看出,用下标索引字节字符串得到的实际上就是int类型的数据了,其实就是默认为无符号整数,如果是0xff,那输出的就是255.
上面这个是读取每个字节,那如果传输的数据是两个字节组合起来的,目标是这两个字节表示的数据,怎么办呢?这里要使用到int类中的from_bytes函数:

需要注意的是,字节字符串索引一个元素得到的是一个整形值 (
a[0]),如果是索引多个 (a[0:3])或看似索引多个 (a[0:1]) 得到的还是字节字符串
int.from_bytes这个函数的作用就是将一个字节字符串转换为整形数值,且支持多个字节。还可以指定大端模式或小端模式,和是否设置为符号整数(上面那种取一个元素的情况默认是无符号整数)。
- 字节字符串显示
除了上面说从字节字符串中取出数值进行运算外,还有就是怎么将字节字符串转换为可显示的字符串。

这是最常用的encode和decode函数,但是需要注意的是,如果print里面是字节类型的数据(byte)的话,那么显示出来的并不是实际的整数,而是字节数据的具象化:字节字符串。
这里还有一个需要注意的点,那就是第二个参数ignore,表示出现错误(一般是找不到该编码方式当中字节数据对应的字符)时要采取的方案,主要有三种选择:
restrict或不填:表示一旦出现没有对应字符的字节,直接报错ignore: 表示出现没有对应字符的字节,直接忽略,看下一个,也不输出replace: 表示出现没有对应字符的字节,用一个“?”字符代替
那除了编码和解码,还有其他方式可以显示字节数据吗?比如很多串口调试助手当中显示的内容就是去掉0x后的字符,比如显示0xAF这个字节数据,就显示AF字符串,这种是咋实现的呢?实际上用的是字节字符串的一个函数hex

不过需要注意的是,hex函数也可以单独使用,它的作用是将一个整形转换为十六进制格式并以字符串的格式输出:

最后,还有一种,就是使用repr函数把字节字符串的所有内容,包括\, x等字符都具象出来,这种可能使用得比较少。