第四章. Pandas进阶
4.7 日期数据处理
1.DataFrame的日期数据转换(to_datetime)
在日常工作中,常见的日期方式有很多种,例如’20221123’,‘2022.11.23’,‘2022/11/23’,‘23/11/2022’,‘23-Nov-22’,需要先将这些格式统一后才能进行后续的工作。
1).语法:
DataFrame.to_datetime(arg,errors=“ignore”,dayfirst=False,yearfirst=False,utc=None,box=True,format=None,exact=True,unit=None,inter_datetime=False,origin=“unix”,cache=False)
参数说明:
arg:需要转换的时间和日期
errors:值为ignore(无效的解析将返回原值),值为raise(无效的解析将引发异常),值为coerce(无效的解析将被置为NaT)
dayfirst:第一个为天,例如:23/11/2022,置为True:解析为 2022-11-23,置为False:解析为 2022-23-11
2).示例:
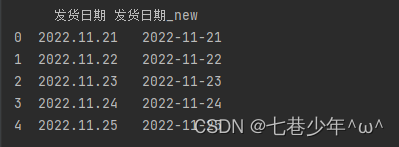
- 示例1:日期格式转换
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1',usecols=['发货日期'])
print(df)
print('*' * 50)
df['发货日期_new']= pd.to_datetime(df['发货日期'])
print(df)
结果展示:
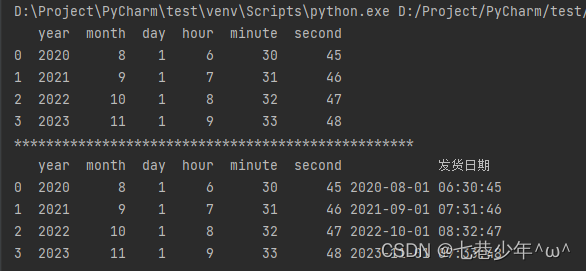
- 示例2:将多列数据组合成日期数据
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet3')
print(df)
print('*' * 50)
df['发货日期']= pd.to_datetime(df)
print(df)
结果展示:
2.访问日期属性对象(dt)
1).语法:
Series.dt()
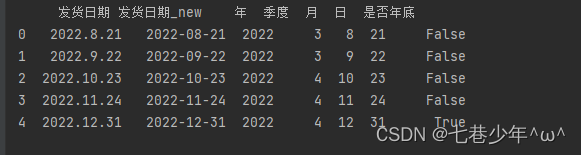
2).示例1:获取日期中的多个属性
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1', usecols=['发货日期'])
print(df)
print('*' * 50)
df['发货日期_new']= pd.to_datetime(df['发货日期'])
print(df)
df['年'],df['季度'],df['月'],df['日'],df['是否年底']=df['发货日期_new'].dt.year,df['发货日期_new'].dt.quarter,df['发货日期_new'].dt.month,df['发货日期_new'].dt.day,df['发货日期_new'].dt.is_year_end
print(df)
结果展示:
3.获取日期区间的数据
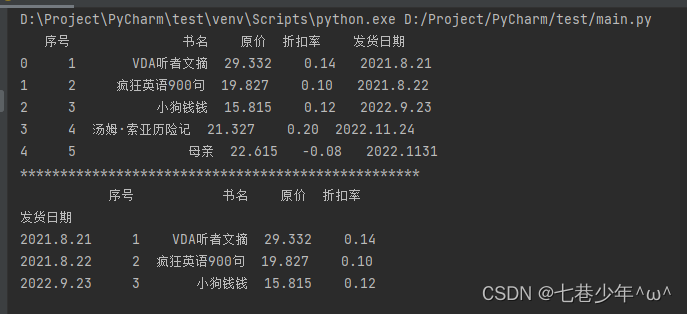
示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1')
print(df)
print('*' * 50)
df1 = df.set_index('发货日期')
df1 = df1['2021.8.21':'2022.9.23']
print(df1)
结果展示:
4.统计显示不同时期的数据(resample,to_period)
1).语法:
- 统计语法
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',kind=None, loffset=None, limit=None, base=0,on=None,level=None)
参数说明:
rule:字符串,偏移量表示目标字符串或对象转换:‘AS’(年),‘Q’(季度),‘M’(月),‘W’(星期),‘D’(天)
axis:0:表示列,1:表示行,默认0
fill_method:升采样时的差值方式,例如:bfill (用后值填充),ffill(用前值填充)
closed:降采样时,时间区间的开和闭,‘right’(默认)和 ‘left’ (right:左开右闭)
label:降采样时,如何设置聚合值的标签
convention:当重采样时,将低频转换成高频时,所采用的约定,‘start’,‘end’, 默认值‘‘start’’
kind:聚合到时期(‘period’)或时间戳(timestamp),默认聚合到时间序列的索引类型,默认值为None
loffset:聚合标签的时间矫正值,默认值为None,比如‘-1s’或Second(-1)用于将聚合标签调早1秒
limit:向前或向后填充时,允许填充的最大时期数,默认值为None
base:对于平均细分为1天的频率,聚合间隔的“origin”。例如,对于“ 5min”频率,基本范围可以是0-4。默认值为0。
- 显示语法
DataFrame.to_period(freq=None,axis=0,copy=True)
参数说明:
freq:周期索引的频率:‘AS’(年),‘Q’(季度),‘M’(月),‘W’(星期),‘D’(天)
axis:0:表示行,1:表示列,默认0
copy:是否复制数据
返回值:带周期索引的时间序列
2).示例:
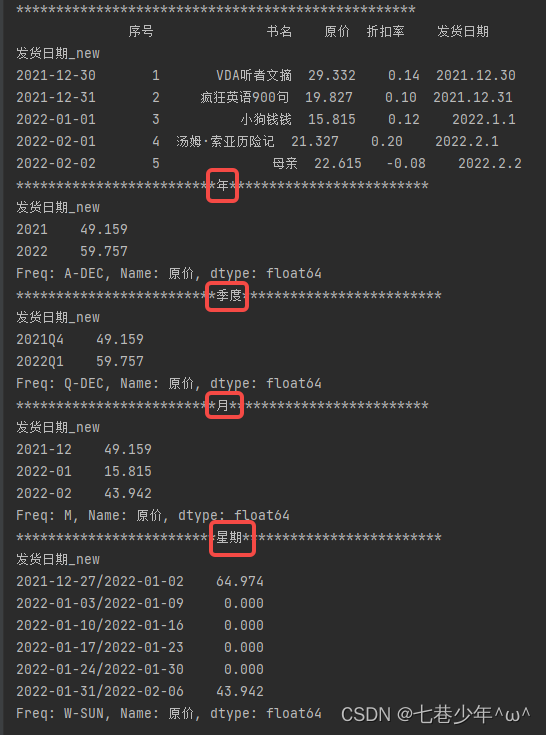
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx', sheet_name='Sheet1')
print(df)
print('*' * 50)
df['发货日期_new']= pd.to_datetime(df['发货日期'])
df = df.set_index('发货日期_new')
print(df)
# 年
print('*' * 25+'年'+'*' * 25)
df2 = df['原价'].resample('AS').sum().to_period('A')
print(df2)
# 季度
print('*' * 25+'季度'+'*' * 25)
df2 = df['原价'].resample('Q').sum().to_period('Q')
print(df2)
# 月
print('*' * 25+'月'+'*' * 25)
df2 = df['原价'].resample('M').sum().to_period('M')
print(df2)
# 星期
print('*' * 25+'星期'+'*' * 25)
df2 = df['原价'].resample('W').sum().to_period('W')
print(df2)
结果展示:
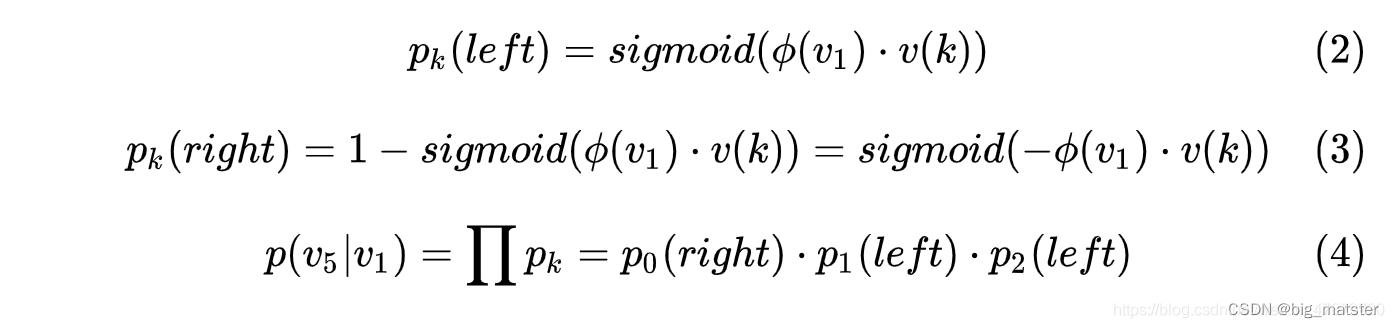




![[附源码]SSM计算机毕业设计网上鞋店管理系统JAVA](https://img-blog.csdnimg.cn/ddf9a1a15a4d4274b953fd41546d855c.png)
![[美国访问学者J1]签证的材料准备](https://img-blog.csdnimg.cn/f2acfe7e22034b488c3fadf372a1eede.jpeg)