算法思想
源于word2vec ,word2vec通过语料库中的句子序列来描述词与词之间的共现关系。进而学习到词语的向量表示,deepwalk则使用图中的节点与节点的共像现关系来学习节点的向量表示。这种借鉴的前提是点在图中的分布和词在句子中的分布都是幂律分布。
随机游走

通过构建
h
i
e
r
a
r
c
h
i
c
a
l
s
o
f
t
m
a
x
hierarchical softmax
hierarchicalsoftmax,第三步对每个结点做
y
y
y次随机游走。第四步打乱网络中的节点,可以加快随机梯度下降的速,
第五步:以每个节点为根节点生成长度为
t
t
t的随机游走。
第七步:根据生成的随机游走使用Skip-gran模型利用梯度的方法对参数进行更新。
这里得到的随机游走就相当于自然语言处理的语句,包含了点在图中的分布信息。
如何把随机游走中得到的信息用点来表示学习。


概率的部分意思是:在一个随机游走中,当给定一个顶点
v
i
v_i
vi时,
出现其的
w
w
w窗口范围内顶点的概率。
同时考虑左边窗口和右边窗口,不考虑顺序。
Softmax
为什么要使用Softmax?
P
r
(
u
k
∣
ϕ
(
v
j
)
)
Pr(u_k|\phi(v_j))
Pr(uk∣ϕ(vj))
为了方便计算
基本思想:将词典中的每个词按照词频大小构建出一颗Huffman树,保证词频较大的词处于相对比较钱的层。词频较低的词相应处于Huffma树深层的叶子节点。每一词都处于这颗Huffman树上的某个叶子节点。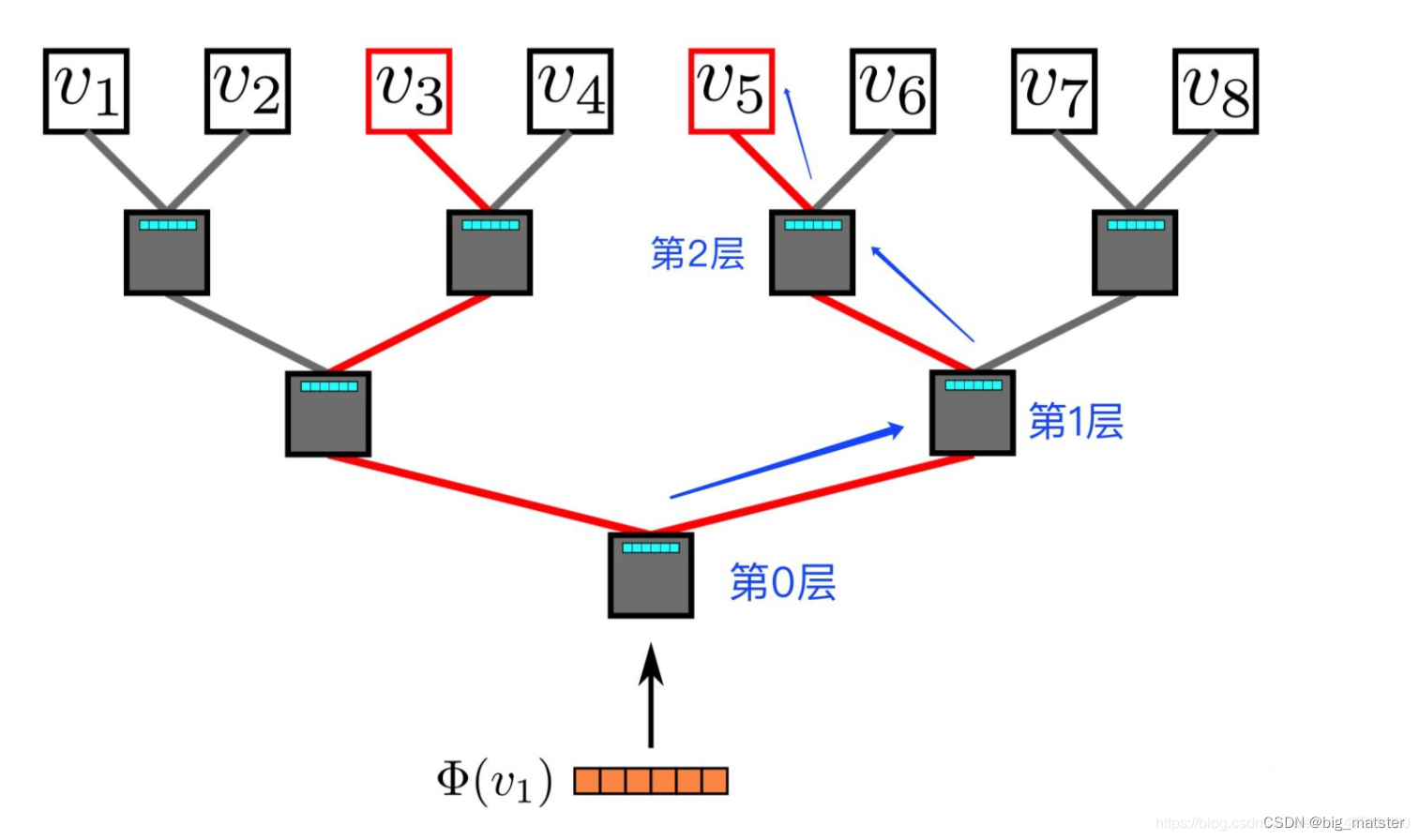
计算方法:
- 在二叉树的每一个节点上都存放一个向量,需要通过学习得到,最后的叶子节点上没有向量,显而易见,整棵树共有 ∣ V ∣ |V| ∣V∣个向量,
- 规定在第 k k k层的节点做分类时,节点的左子树为正类别,节点的右子树是负类别,该节点的向量用 V ( k ) V(k) V(k)表示。
- 那么正负累的分数如公式(2)(3)所示:在预测的时候,需要按照蓝色箭头方向做分类,第0层分类结果为负类,第一层分类结果为正类。第3层分类结果为正类,最后达到叶子节点
V
(
5
)
V(5)
V(5),最后把所有节点的分类的分数累乘起来。
p k ( l e f t ) = s i g m o i d ( ϕ ( v 1 ) × v ( k ) ) p_k(left) = sigmoid(\phi(v_1) \times v(k)) pk(left)=sigmoid(ϕ(v1)×v(k))
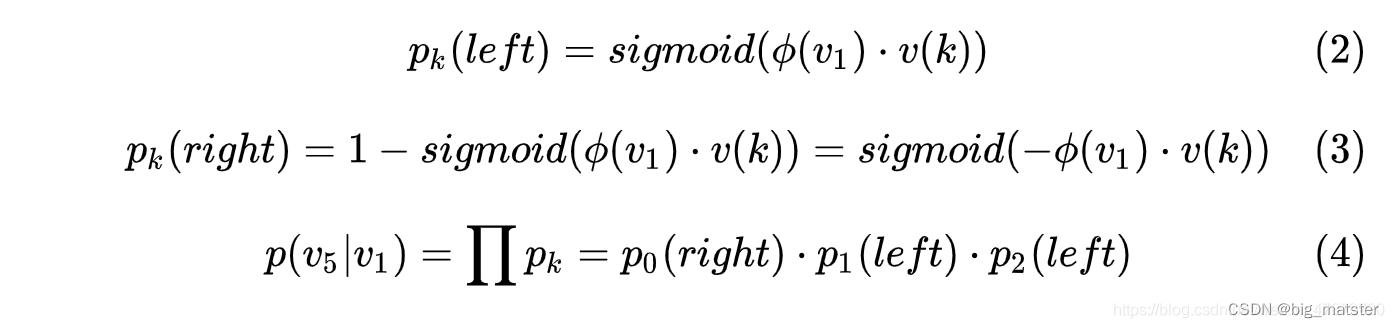
适用场景
- 图表示学习,捕捉节点局部的结构信息
- 适用于无权图,同构网络
- 在图稀疏的时候也能取得较好的表现。
- 对大型的图也能够取得较好的表现,也能够并行计算。
不足和改进
- 无法对图中的边信息(权重和不同的关系)进行处理。
- 随机游走是对节点选取的概率不够完善,没有区分广度优先和深度优先搜索,node2vec模型对此进行了改进。




![[附源码]SSM计算机毕业设计网上鞋店管理系统JAVA](https://img-blog.csdnimg.cn/ddf9a1a15a4d4274b953fd41546d855c.png)
![[美国访问学者J1]签证的材料准备](https://img-blog.csdnimg.cn/f2acfe7e22034b488c3fadf372a1eede.jpeg)