数据结构
链表和数组
-
数组
Python的list是由数组来实现的
有序的元素序列, 在内存中表现为一块连续的内存区域;
-
链表
通过指针将无序的列表链接起来, 每个节点都存储着当前节点的值和下一个节点的内存地址

-
链表和数组有什么区别?
- 实现有序的方式是不一样的, 数组是连续的内存. 链表通过持有下一个节点的内存地址来达到有序的目的;
- 基于上述的特性, 数组在进行增删改查的时候钥耗费大量的系统资源来移动元素, 而链表只需要修改保存的地址即可.
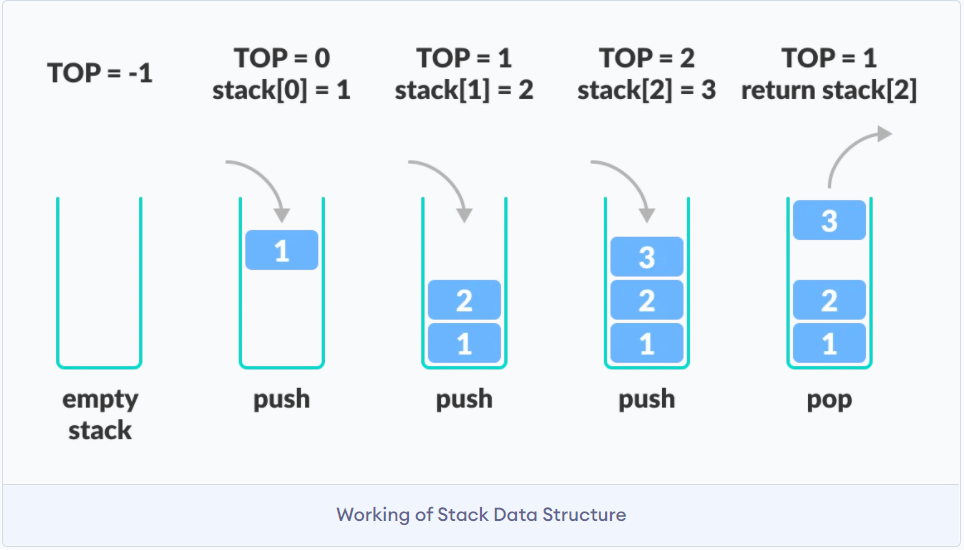
栈
栈的特点是后入先出LIFO last in first out
可以将栈想象为一个有底的玻璃瓶, 那我们存取东西都必须遵守后入先出.
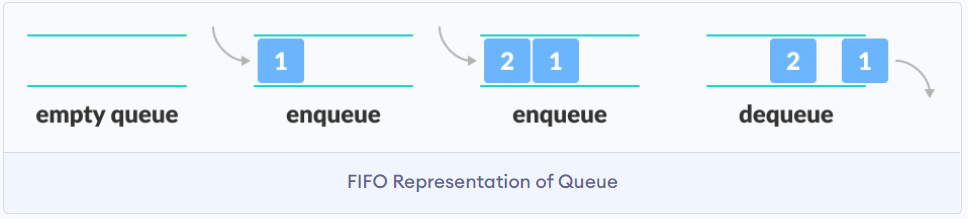
队列
队列的特点是先入先出FIFO first in first out
可以将队列想象为一个没有封口的玻璃管, 但是该玻璃管只有一个口可以添加元素, 一个口吐出元素. 那么队列获取元素必然遵守先入后出.
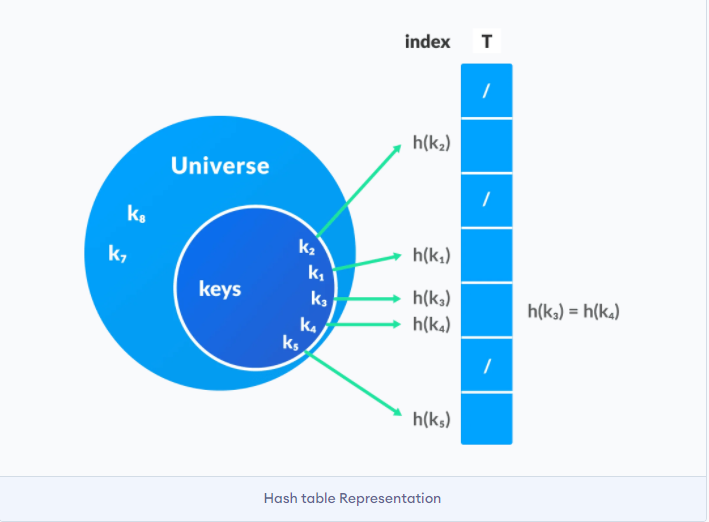
散列表
python中的dict本质就是散列表
散列表也叫hashmap. 通过将key值映射到数组中的一个位置来访问. 这个映射函数就叫做散列函数, 存放记录的数组也叫散列表
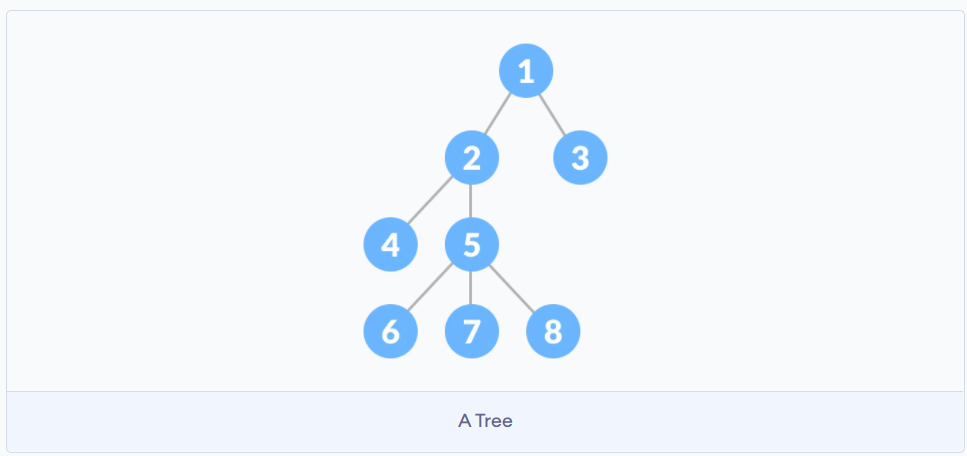
树和堆
树是一种特殊的链表结构, 每个节点下有若干个子节点
-
树的分类
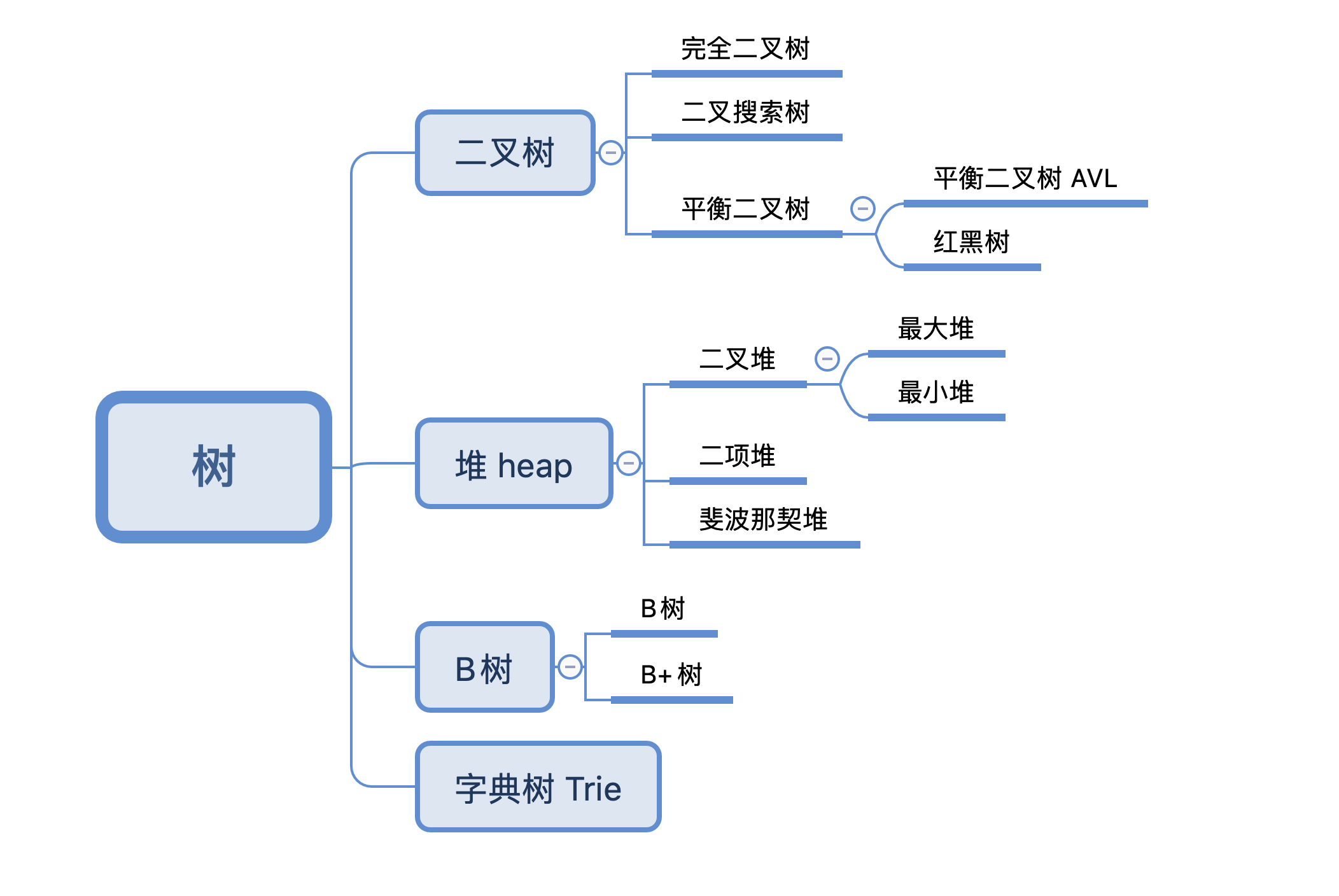
-
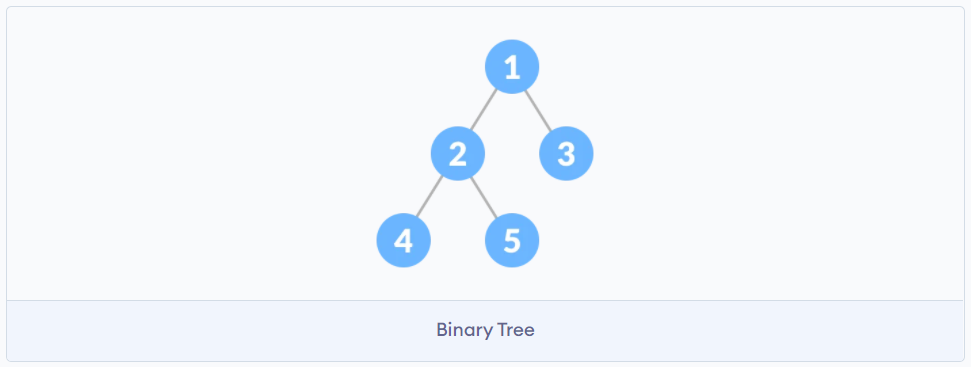
二叉树
每个节点下最多只有两个节点
-
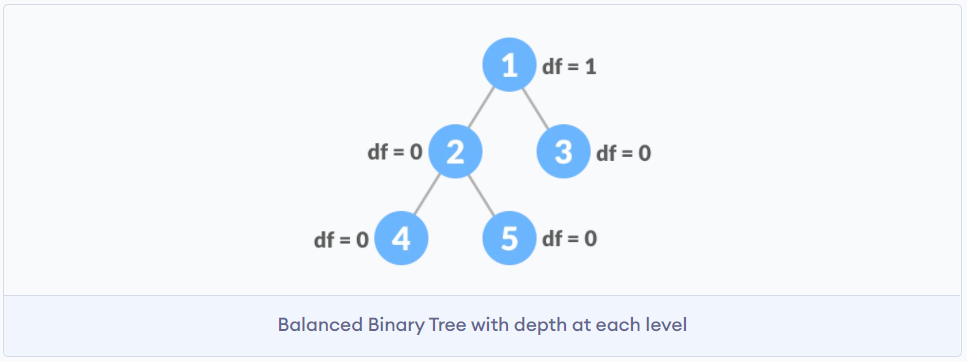
平衡二叉树
二叉树节点下可以只有一个子节点, 如果二叉树中节点
1-> 2 -> 3 -> 4 -> 5, 那么当前的树结构退化成了链表, 为了解决这么一个情况, 就有了平衡二叉树.平衡二叉树的任意节点的左子树的高度与右子树的高度差不可以超过1.
-
红黑树
因为平衡二叉树要严格保证左右子树的高度不超过1, 在实际场景中, 平衡二叉树需要频繁地进行调整.
-
-
-
二叉堆
二叉堆是一个完全二叉树, 满足当前任意节点要
<=或者>=左右子节点, 一般使用数组来实现.-
最大堆
当前任意节点要
>=左右子节点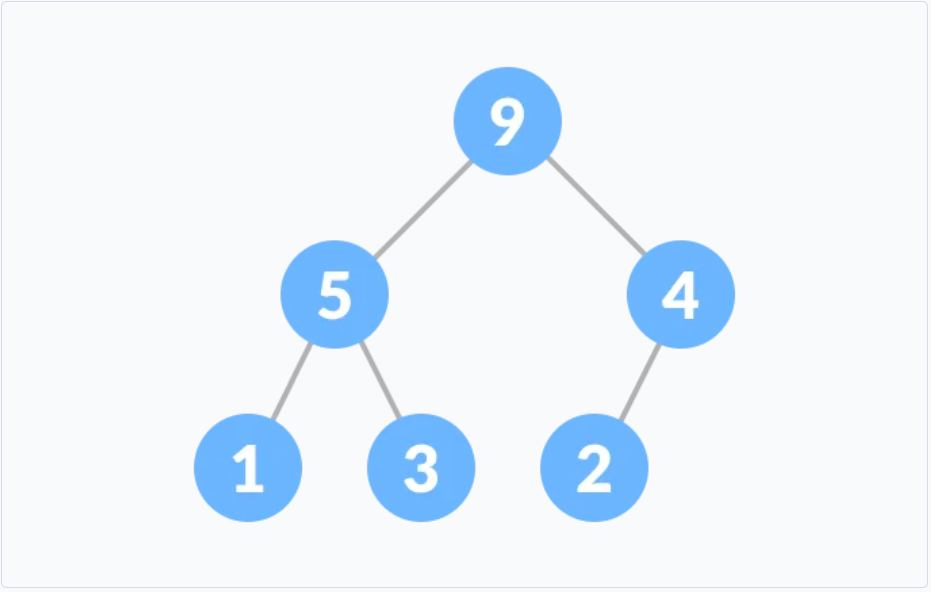
-
最小堆
略
-
-
B树
-
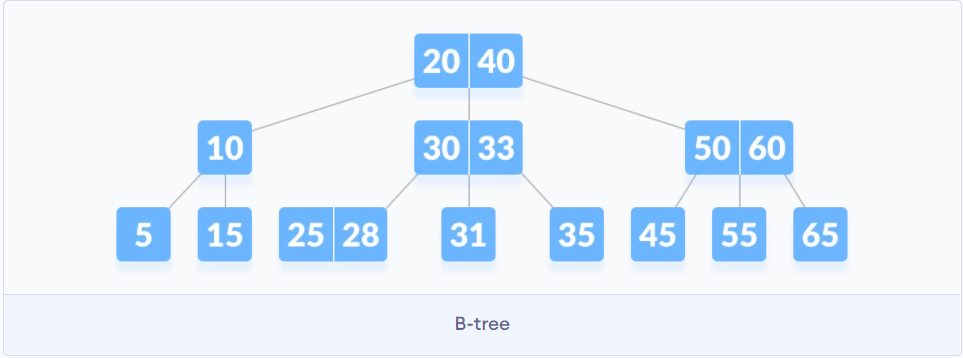
B树解决了什么问题?
B树的目的是在搜索树的基础上优化了磁盘获取的效率
大部分数据查询的瓶颈在磁盘IO上, 从磁盘中读取1kb数据和1b数据消耗的时间基本是一样的, 在平衡二叉树的基础上, 每个节点尽可能多地存储数据
-
-
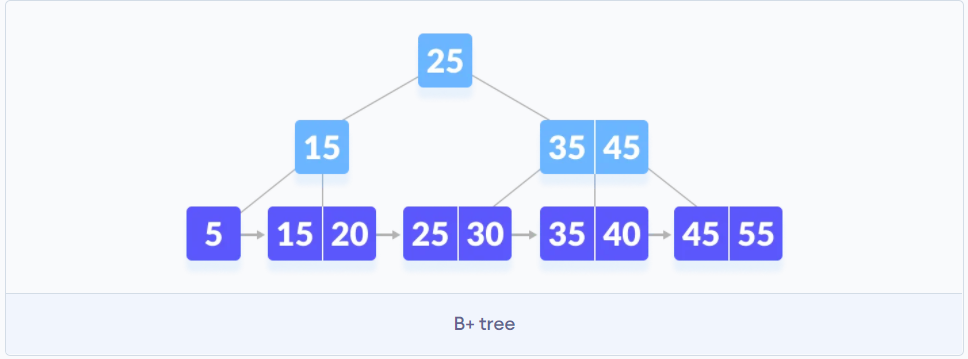
B+树解决了什么问题?
为了优化B树的查找速度, B树的每一个节点都是数据, 而B+树非子节点存储的是数据的地址(索引值), 子节点存储的是数据, 而且子节点会指向相邻的子节点, 都成一个有序链表.B树适合作文件系统. B+树适合作遍历和查找.
链表
通过指针将无序的列表链接起来. 每个节点都存储着当前节点的值和下一个节点的地址
-
链表的缺点
链表的查找是从头节点逐个节点遍历, 查找效率低.
-
链表的应用
-
系统的文件系统
我们存放在磁盘上的文件并不是连续的, 我们通过链表来对文件进行目录归类.
-
git的提交节点
-
其他数据结构的基础, 比如树结构
-
链表的种类
-
单链表

-
双链表

-
环形链表
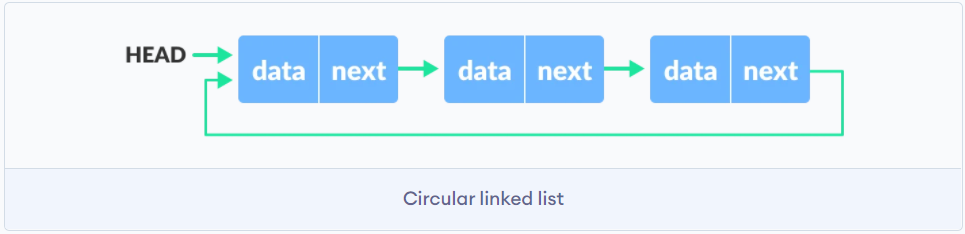
单链表的实现
-
声明Node类(自定义一个数据结构Node)
class Node: def __init__(self, data): self.data = data self.next = None def __str__(self): return f"<Node {self.data}>" -
实现LinkedList数据结构
class LinkedList: def __init__(self): self.head = None self.end = self.head def append(self, node): """ 向链表尾部添加一个节点 1. 尾部添加: end.next -> node, end -> node 2. 当前头部没有节点: head -> node :param node: :return: """ if not self.head: self.head = node else: self.end.next = node self.end = node def insert(self, index, node): """ 向index值插入一个节点 1. 插入的是中间节点: 找到index值的节点, cur.next -> node node->next 2. 遍历的过程当中, 结果index值超过了当前链表的长度, 我们抛出异常 3. 在头部插入节点: head -> node, node.next = head 4. 在尾部插入节点: 跟中间节点是一样的, 但是end -> node :param index: :param node: :return: """ # 在原index值元素的左边插入 -> 在原index-1值对应元素的右边插入 cur = self.head if index == 0: node.next = self.head self.head = node return for i in range(index-1): cur = cur.next if cur is None: raise IndexError("LinkedList insert node exceed max length") node.next, cur.next = cur.next, node if node.next is None: self.end = node def remove(self, node): """ 通过遍历删除给定的节点 1. 移除的是中间节点: cur.next -> None, prev.next -> cur.next 2. 移除的是头节点: head -> cur.next, cur.next -> None 3. 移除的是尾节点: cur.next本身指向的就是None,和1一致, end -> prev :param node: :return: """ cur = self.head prev = None while cur: if cur.data == node.data: if prev is None: self.head = cur.next else: prev.next = cur.next cur.next = None if prev and prev.next is None: self.end = prev return prev = cur cur = cur.next def reverse(self): """ 翻转当前链表 1. 中间节点: cur.next -> prev 2. 头节点: cur.next -> prev 3. 尾节点: cur.next -> prev 4. 处理原本的head和end :return: """ # 能被翻转说明链表长度 > 1 if self.head and self.head.next: cur = self.head.next prev = self.head # 原本头节点的next需要断开 self.head.next = None # 原本头节点就变成了尾节点 self.end = prev while cur: # 这里设计到next,cur, prev三个节点, 所以引入中间变量next next = cur.next cur.next = prev prev = cur cur = next # 翻转后,头节点指向了原本的尾节点 self.head = prev else: return def __str__(self): """ 通过遍历的方式打印当前链表 初始节点为Head, 如果当前指针指向的是NULL, 说明我们到达了结尾 :return: """ cur = self.head result = "" while cur: result += str(cur) + "\t" cur = cur.next return result if __name__ == "__main__": node_1 = Node(1) node_2 = Node(2) node_3 = Node(3) node_4 = Node(4) linked_list = LinkedList() linked_list.append(node_1) linked_list.append(node_2) linked_list.append(node_3) # linked_list.insert(3, Node(1.5)) linked_list.append(node_4) # linked_list.remove(Node(1.5)) linked_list.reverse() print(linked_list)
链表和数组
-
数组
Python的list是由数组来实现的
有序的元素序列, 在内存中表现为一块连续的内存区域;
-
链表
通过指针将无序的列表链接起来, 每个节点都存储着当前节点的值和下一个节点的内存地址

-
链表和数组有什么区别?
- 实现有序的方式是不一样的, 数组是连续的内存. 链表通过持有下一个节点的内存地址来达到有序的目的;
- 基于上述的特性, 数组在进行增删改查的时候钥耗费大量的系统资源来移动元素, 而链表只需要修改保存的地址即可.
栈
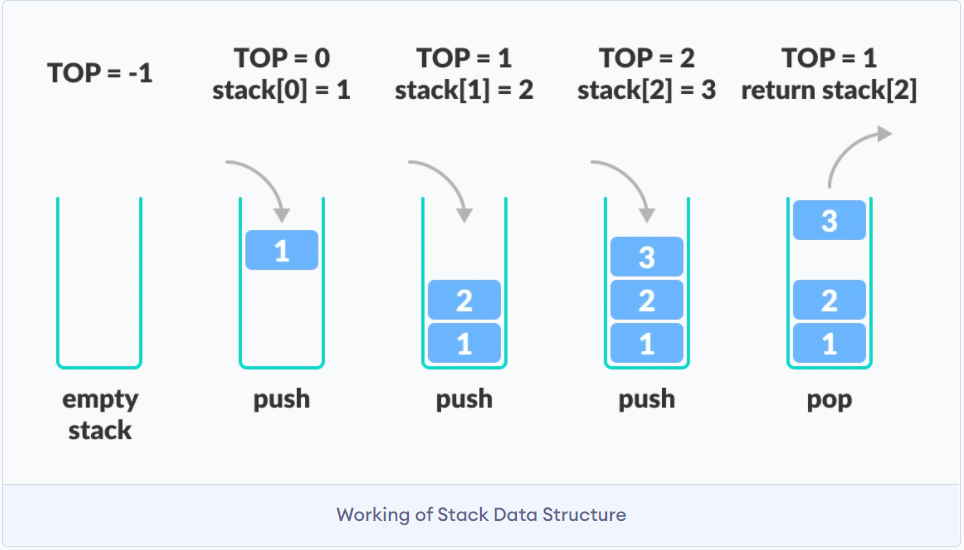
栈的特点是后入先出LIFO last in first out
可以将栈想象为一个有底的玻璃瓶, 那我们存取东西都必须遵守后入先出.
-
用
list来实现一个栈class MyStack: """ 栈有固定长度, 需要考虑栈溢出和空栈的情况 top属性用来指示栈顶的索引值 """ def __init__(self, _size=10): self.stack = [] self.top = -1 self.size = _size def is_full(self): return self.top == self.size - 1 def push(self, item): """ 首先判断当前栈是否已满 :param item: :return: """ if self.is_full(): raise Exception("StackOverflow") self.stack.append(item) self.top += 1 def is_empty(self): return self.top == -1 def pop(self): """ 首先要判断当前栈是不是空栈 :return: """ if self.is_empty(): raise Exception("StackUnderflow") self.top -= 1 return self.stack.pop() if __name__ == "__main__": # 1 + 2 * 3 my_stack = MyStack() my_stack.push(1) my_stack.push("+") my_stack.push(2) my_stack.push("*") my_stack.push(3) # 简单示例运算过程, 实际情况执行要复杂的多, 背后的指令也更优雅 # 栈只有一个元素的时候, 运算正式结束 while my_stack.top > 0: item_1 = my_stack.pop() operator = my_stack.pop() item_2 = my_stack.pop() if operator == "*": my_stack.push(item_1 * item_2) elif operator == "+": my_stack.push(item_1 + item_2) # 结果就在栈底 print(my_stack.pop())
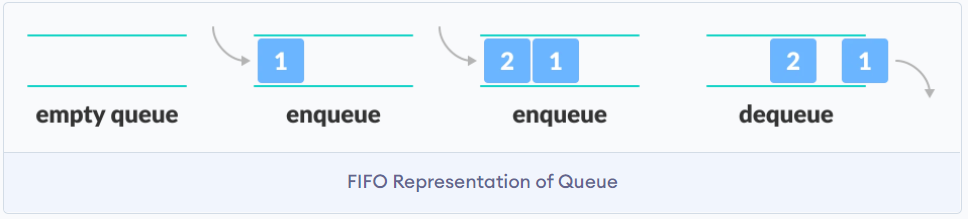
队列
队列的特点是先入先出FIFO first in first out
可以将队列想象为一个没有封口的玻璃管, 但是该玻璃管只有一个口可以添加元素, 一个口吐出元素. 那么队列获取元素必然遵守先入后出.
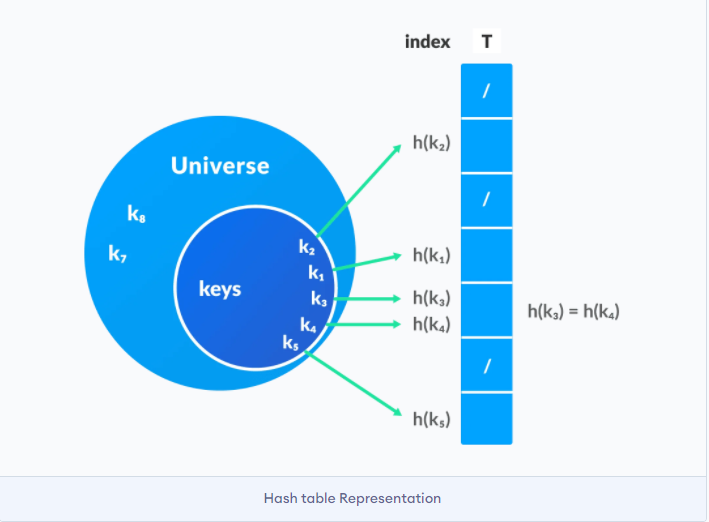
散列表
python中的dict本质就是散列表
散列表也叫hashmap. 通过将key值映射到数组中的一个位置来访问. 这个映射函数就叫做散列函数, 存放记录的数组也叫散列表
-
散列函数有哪些?
一个好得散列函数要满足以下条件: 1. 均匀铺满散列表, 节约内存空间; 2. 散列冲突概率低
-
直接定址法
适合
key是连续得或者当前表较小的情况, 否则会有巨大的空间浪费.f(n) = a*n + b f(1) = a + b f(10000) = 10000a + b -
数字分析法
找出
key值的规律, 构建冲突比较低的散列函数比如姓名, 显然姓很容易冲突, 所以根据名来定散列函数.
-
平方取中法
取关键字平方后的中间做为散列地址
-
折叠法
将关键字分割成位数相同的几个部分, 然后取这几个部分的叠加和做为散列函数
-
随机数法
选择一个随机函数, 取关键字的随机值做为散列地址, 通过用于关键字长度不同的场合
-
除留余数法
取关键字被某个大于散列表长度的数
P除后得到余数做为散列地址.
-
-
Python用的是哪种散列函数呢?
具体要看数据类型, 使用的散列函数大多也是混合方法.
-
什么是散列冲突?
不同的
key理应得到不同的散列地址, 散列冲突就是不同key得到了同一个散列地址. -
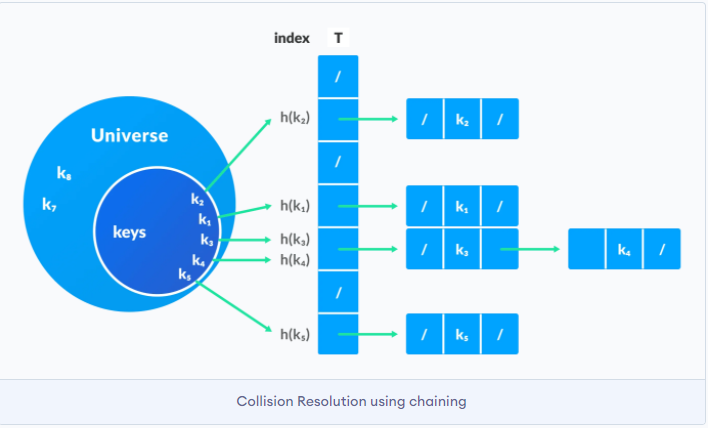
如果解决散列冲突?
-
开放寻址法(Python)
线性地扫描散列表, 直到找到一个空单元.
-
链表法(Java)
所有散列值相同的元素都放到相同位置的链表中
-
-
hashmap是线程安全的吗?-
在
jdk1.8中, 内部使用的是数组+链表+红黑树, 当进行散列冲突的时候, 注定会有一个数据丢失. -
在
python中, 由于GIL内置的数据结构都是线程安全的. 但是对于实际应用中, 我们将线程安全都是针对的操作.// 当前的函数是线程安全的 def foo(a): my_dict.update({"a": a}) // 通过dis库查看的字节码, 如果关键代码只有一条操作指令, 那就是线程安全的 import dis print(dis.dis(foo)) // 当前的函数不是线程安全的 def foo(a): my_dict['a'] += 1-
例
from threading import Thread my_dict = {"a": 0} def foo(a): for i in range(10**6): my_dict['a'] += a if __name__ == "__main__": thread_1 = Thread(target=foo, args=(1, )) thread_2 = Thread(target=foo, args=(-1, )) thread_1.start() thread_2.start() thread_1.join() thread_2.join() print(my_dict)
-
-
-
什么是线程安全?
实际应用的角度来说, 加锁的就是线程安全, 不加锁的就是线程不安全.
-
为什么在有
GIL的情况, 线程仍然是不安全的?全局解释器锁只保证了同一个时刻一个线程在运行, 但是不能保证切换到下一个线程还原的现场还有效.
-
dict扩容过程以及安全问题?PyDict_SetItem会计算key的散列值, 然后把需要的信息传递给insertdict. 在插入之前根据ma_table剩余空间的大小来判断是否扩容, 一般超过2/3就会进行扩容.2/3开始扩容原因就是要给散列函数足够的空间.
树和堆
树是一种特殊的链表结构, 每个节点下有若干个子节点
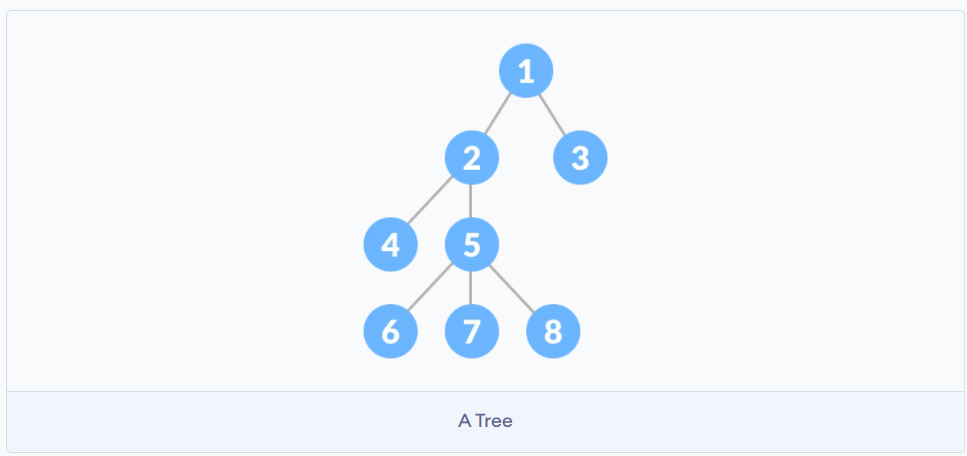
-
树的分类
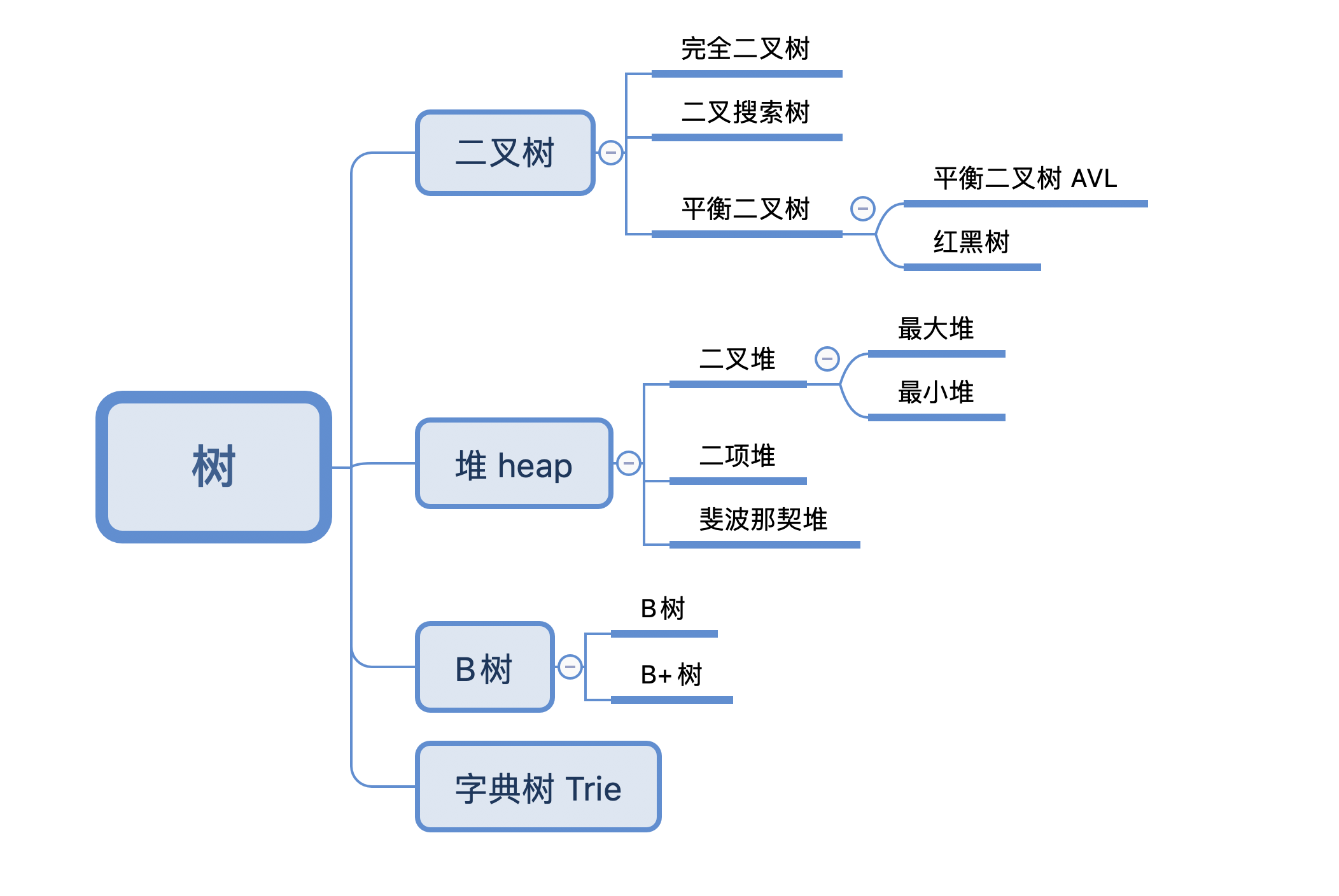
-
二叉树
每个节点下最多只有两个节点
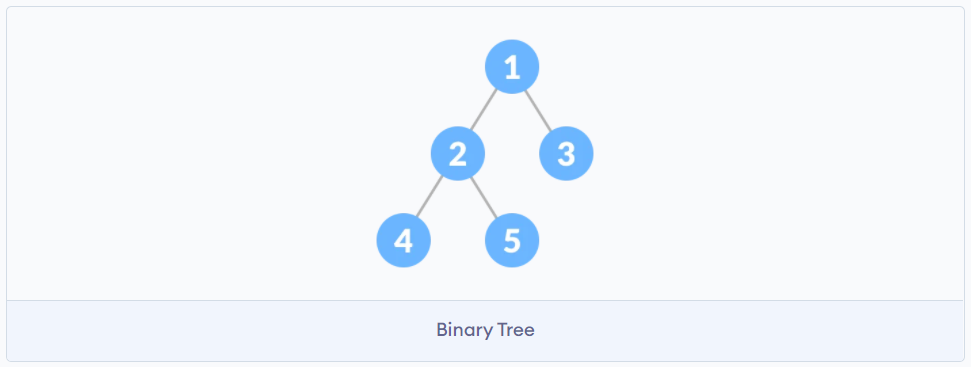
-
平衡二叉树
二叉树节点下可以只有一个子节点, 如果二叉树中节点
1-> 2 -> 3 -> 4 -> 5, 那么当前的树结构退化成了链表, 为了解决这么一个情况, 就有了平衡二叉树.平衡二叉树的任意节点的左子树的高度与右子树的高度差不可以超过1.
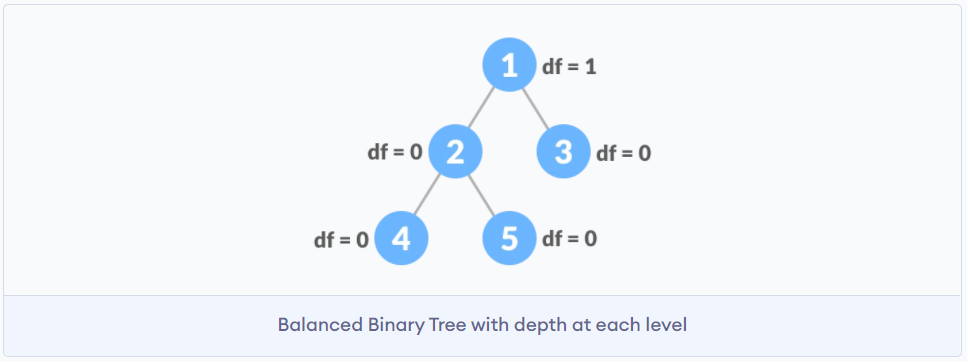
-
红黑树
因为平衡二叉树要严格保证左右子树的高度不超过1, 在实际场景中, 平衡二叉树需要频繁地进行调整.
-
-
-
二叉堆
二叉堆是一个完全二叉树, 满足当前任意节点要
<=或者>=左右子节点, 一般使用数组来实现.-
最大堆
当前任意节点要
>=左右子节点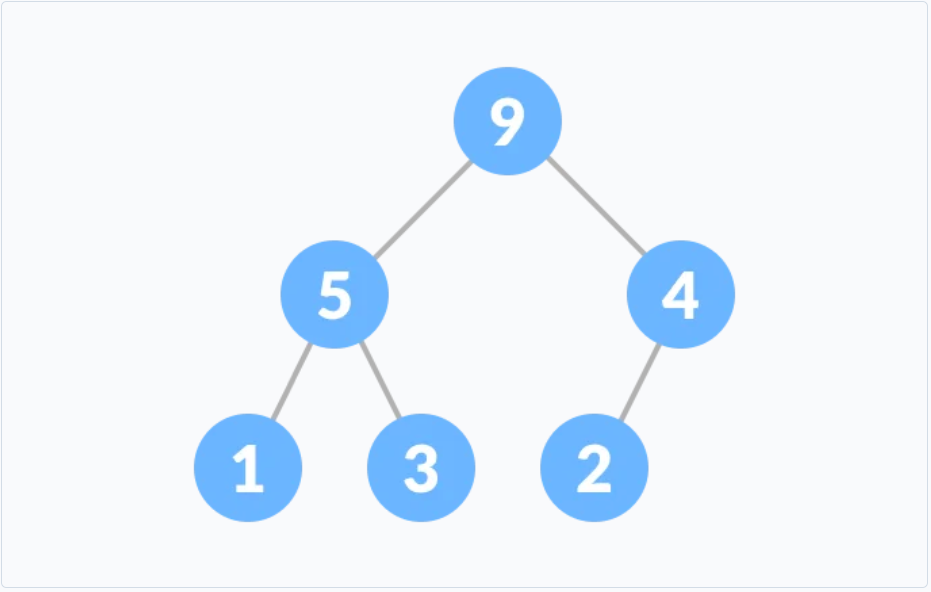
-
最小堆
略
-
-
B树
-
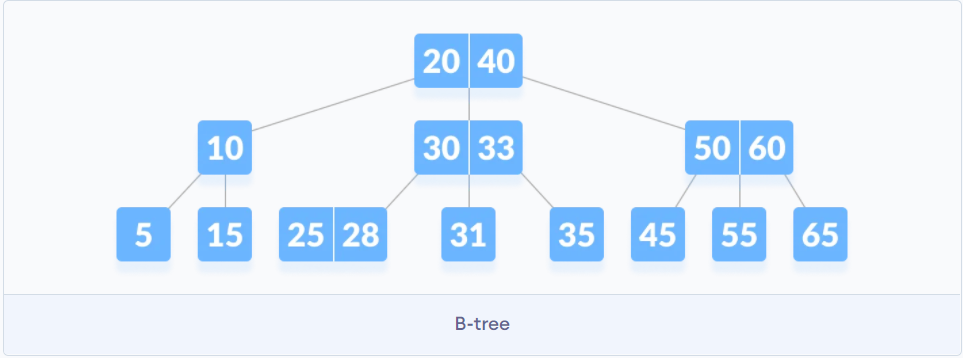
B树解决了什么问题?
B树的目的是在搜索树的基础上优化了磁盘获取的效率
大部分数据查询的瓶颈在磁盘IO上, 从磁盘中读取1kb数据和1b数据消耗的时间基本是一样的, 在平衡二叉树的基础上, 每个节点尽可能多地存储数据
-
-
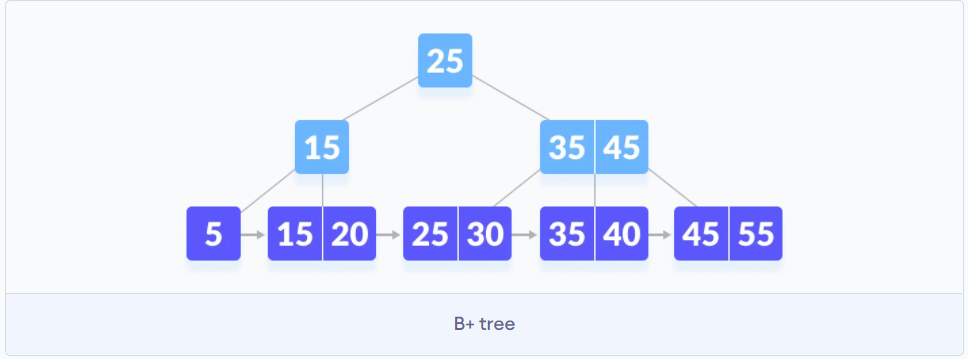
B+树解决了什么问题?
为了优化B树的查找速度, B树的每一个节点都是数据, 而B+树非子节点存储的是数据的地址(索引值), 子节点存储的是数据, 而且子节点会指向相邻的子节点, 都成一个有序链表.B树适合作文件系统. B+树适合作遍历和查找.
![[附源码]SSM计算机毕业设计网上鞋店管理系统JAVA](https://img-blog.csdnimg.cn/ddf9a1a15a4d4274b953fd41546d855c.png)
![[美国访问学者J1]签证的材料准备](https://img-blog.csdnimg.cn/f2acfe7e22034b488c3fadf372a1eede.jpeg)