前言
Auto GPT是一个实验性开源应用程序,展示了GPT-4语言模型的功能。该程序由GPT-4驱动,将LLM“思想”链接在一起,以自主实现您设定的任何目标。作为GPT-4完全自主运行的首批例子之一,Auto GPT突破了人工智能的极限。
特征
🌐 用于搜索和信息收集的互联网接入
💾 长期和短期内存管理
🧠 用于文本生成的GPT-4实例
🔗 访问热门网站和平台
🗃️ 使用GPT-3.5进行文件存储和摘要
要求
环境(只需选择一个)
-
vscode + devcontainer:它已经在.devccontainer文件夹中配置,可以直接使用
-
Python 3.8或更高版本
OpenAI API密钥
PINECONE API密钥
可选:
ElevenLabs 密钥(如果你想让人工智能说话)
安装
1、克隆仓库
git clone https://github.com/Torantulino/Auto-GPT.git
2、命令行cd Auto-GPT进入Auto-GPT目录,安装 python 所有依赖
pip install -r requirements.txt
3、环境变量文件修改
将.env.template重命名为.env,并填写OPENAI_API_KEY。如果您计划使用语音模式,请同时填写您的ELEVEN_LABS_API_KEY。
从以下位置获取OpenAI API密钥:https://platform.openai.com/account/api-keys.
从以下位置获取ElevenLabs
API密钥:https://elevenlabs.io.您可以使用网站上的“配置文件”选项卡查看xi-api-key。
如果您想在Azure实例上使用GPT,请将use_Azure设置为True,然后:
将azure.yaml.template重命名为azure.yaml,并在azure_model_map部分中提供相关的azure_api_base、azure_api_version和相关模型的所有部署ID:
azure_api_type: azure_ad
azure_api_base: your-base-url-for-azure
azure_api_version: api-version-for-azure
azure_model_map:
fast_llm_model_deployment_id: gpt35-deployment-id-for-azure // 您的gpt-3.5-turbo或gpt-4部署id
smart_llm_model_deployment_id: gpt4-deployment-id-for-azure // 您的gpt-4部署id
embedding_model_deployment_id: embedding-deployment-id-for-azure // 您的text-embedding-ad-002 v2部署id
使用
在终端中运行main.py Python脚本:(在CMD窗口中键入此脚本)
python scripts/main.py
在AUTO-GPT的每个操作之后,键入“NEXT COMMAND”以授权它们继续。
要退出程序,请键入“退出”并按Enter键。
日志
您将在文件夹中找到活动和错误日志/输出/日志,要输出调试日志,请执行以下操作:
python scripts/main.py --debug
语音模式
使用该选项可将TTS用于自动GPT
python scripts/main.py --speak
Google API Keys 配置
这一部分是可选的,如果你在运行谷歌搜索时遇到错误429,请使用官方的谷歌api。要使用google_official_search命令,您需要在环境变量中设置GoogleAPI密钥。
1、跳转到谷歌云控制台(https://console.cloud.google.com/)。
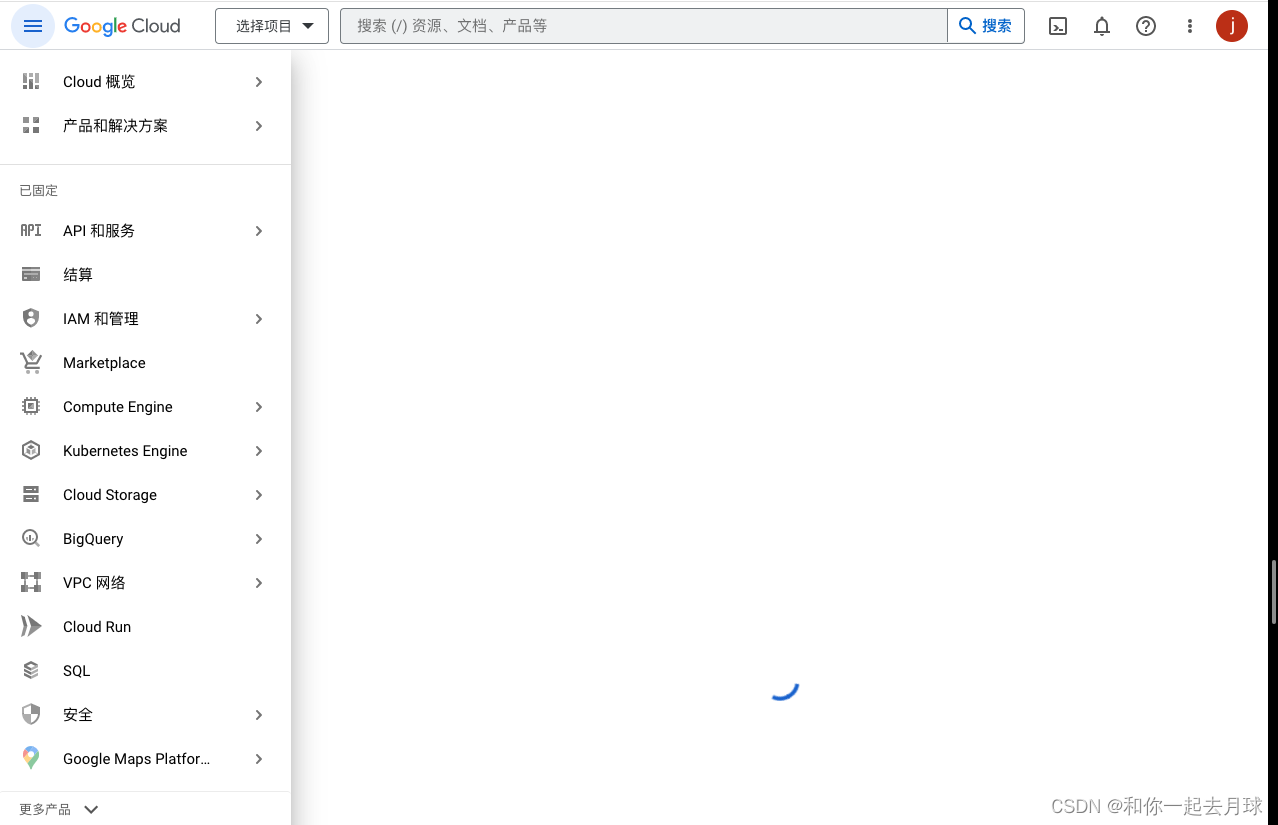
2、如果你还没有账号,就注册一个并登录。
3、单击页面顶部的“选择项目”下拉列表,然后单击“新建项目”,即可创建新项目。给它一个名字,然后点击“创建”。
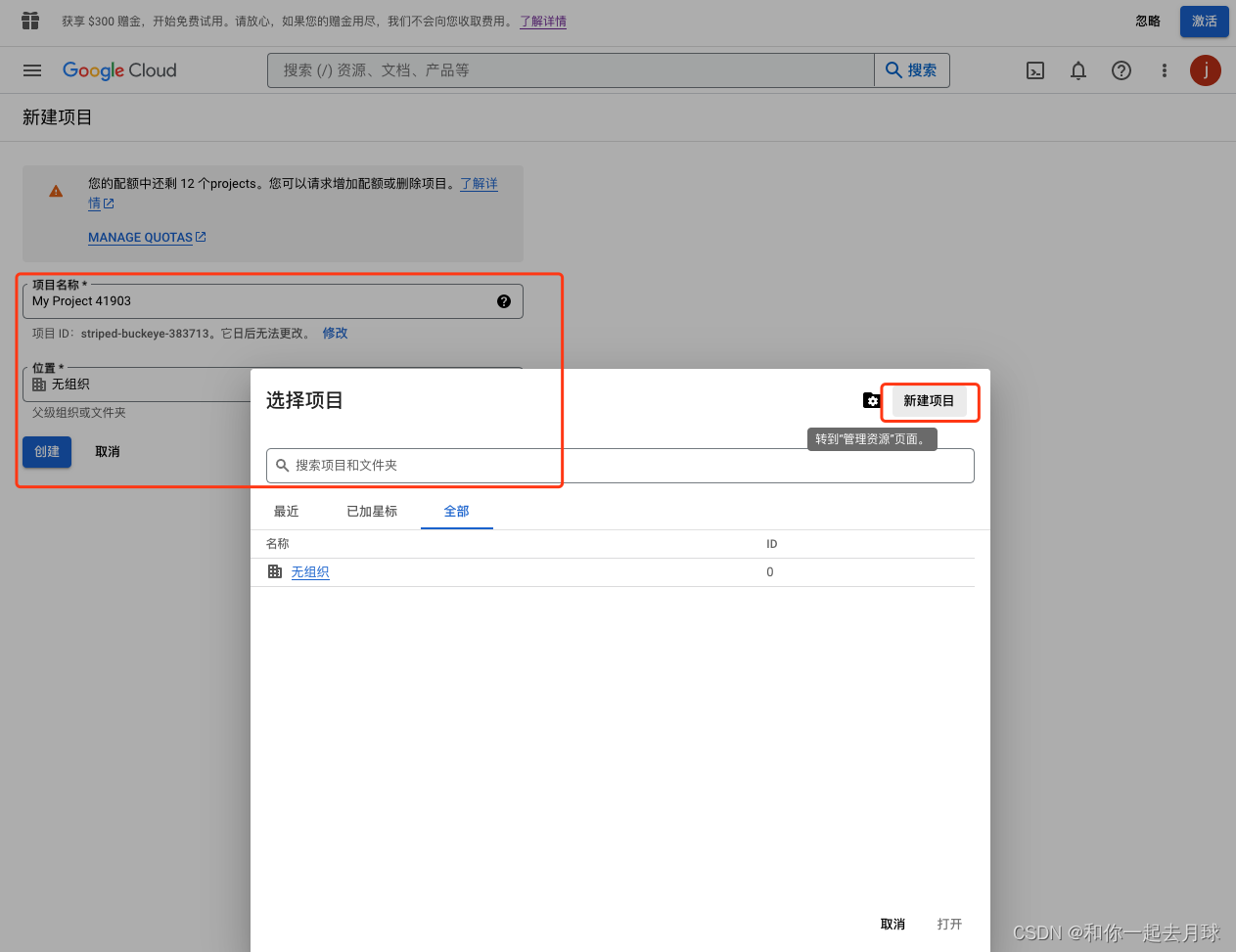
4、到APIs & Services Dashboard面板,然后单击“Enable APIs and Services”。搜索“Custom Search API”并单击它,然后单击“启用”。
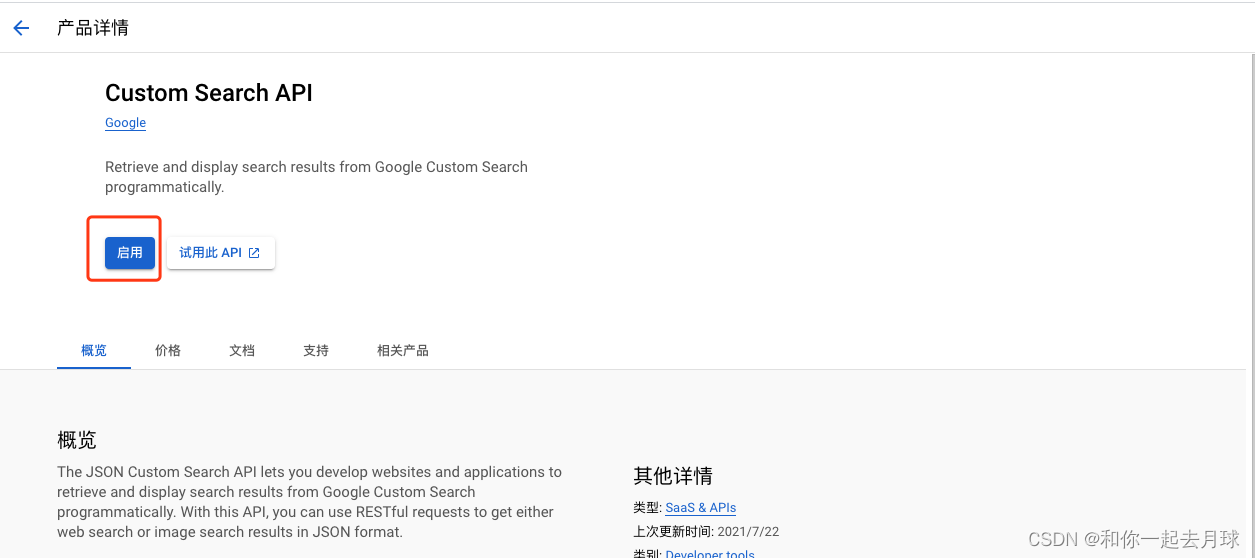
5、转到“凭据”页面,然后单击“创建凭据”。选择“API密钥”。
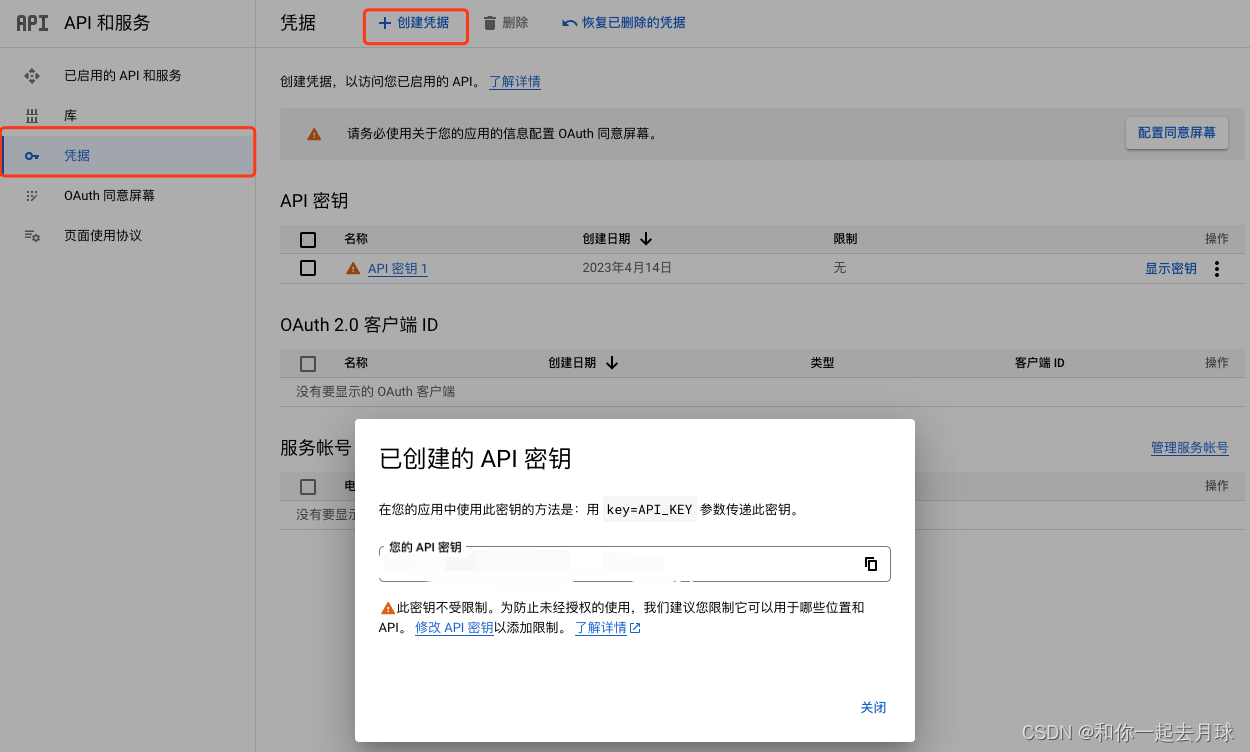
6、复制API密钥,并将其设置为计算机上名为GOOGLE_API_key的环境变量。请参阅下面的设置环境变量。
7、到“自定义搜索引擎”页面(https://cse.google.com/cse/all),然后单击“添加”。
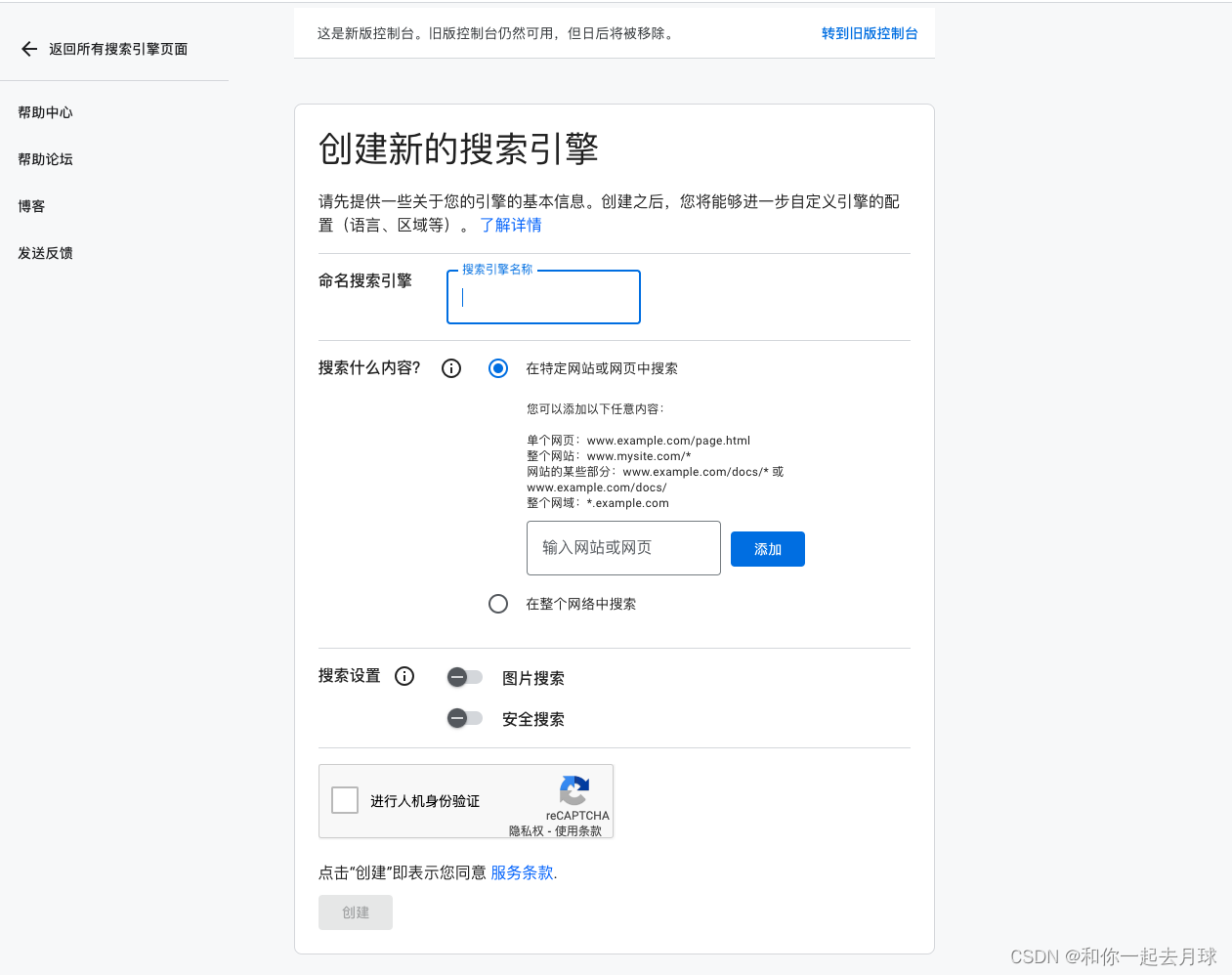
8、按照提示设置搜索引擎。您可以选择搜索整个网站或特定网站。
创建搜索引擎后,单击“控制面板”,然后单击“基础知识”。复制“搜索引擎ID”,并将其设置为机器上名为CUSTOM_Search_engine_ID的环境变量。
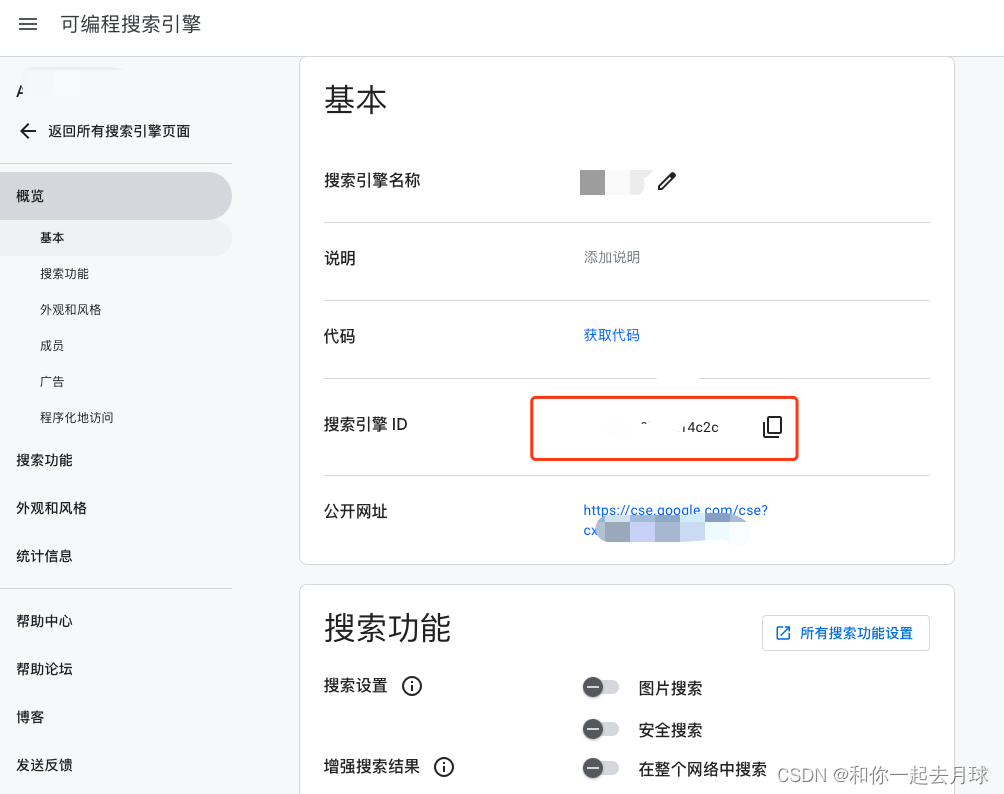
请记住,您的免费每日自定义搜索配额最多只允许100次搜索。要增加此限制,您需要为项目分配一个计费帐户,以便从每天多达1万次的搜索中获利。
设置环境变量
对于Windows用户:
setx GOOGLE_API_KEY "YOUR_GOOGLE_API_KEY"
setx CUSTOM_SEARCH_ENGINE_ID "YOUR_CUSTOM_SEARCH_ENGINE_ID"
对于macOS和Linux用户:
export GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
export CUSTOM_SEARCH_ENGINE_ID="YOUR_CUSTOM_SEARCH_ENGINE_ID"
Redis安装
需要安装docker 桌面端,运行如下命令
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
看见https://hub.docker.com/r/redis/redis-stack-server用于设置密码和附加配置。
设置以下环境变量:
MEMORY_BACKEND=redis
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_PASSWORD=
您可以选择设置
WIPE_REDIS_ON_START= False
将存储在Redis中的内存持久化。
您可以使用以下方法为redis指定内存索引:
MEMORY_INDEX=whatever
🌲 Pinecone API密钥设置
Pinecone能够存储大量基于向量的记忆,在任何给定时间只允许为代理加载相关记忆。
1、如果你还没有账户的话,就去松果注册一个账户。
2、选择“Starter”计划,避免收费。
3、在左侧边栏的默认项目下找到您的API密钥和区域。
设置环境变量
只需在.env文件中设置即可。或者,您可以从命令行设置它们(高级):
对于Windows用户:
setx PINECONE_API_KEY“YOUR_PINECONE_API_KEY”
setx PINECONE_ENV "Your pinecone region" # something like: us-east4-gcp
对于macOS和Linux用户:
export PINECONE_API_KEY=“YOUR_PINECONE_API_KEY”
export PINECONE_ENV="Your pinecone region" # something like: us-east4-gcp
设置缓存类型
默认情况下,自动GPT将使用LocalCache,而不是redis或Pinecone。
要切换到任意一个,请将MEMORY_BACKEND环境变量更改为所需的值:
local(默认)使用本地JSON缓存文件pinecone使用您在ENV设置中配置的pinecone.io帐户redis 将使用您配置的redis缓存
查看内存使用情况
使用–debug标志查看内存使用情况:)
💀 持续模式⚠️
在未经用户授权的情况下运行AI,100%自动化。不建议使用连续模式。
这是潜在的危险,可能会导致你的人工智能永远运行或执行你通常不会授权的行动。使用时风险自负。
在终端中运行main.py Python脚本:
python scripts/main.py --continuous
要退出程序,请按Ctrl+C
仅GPT3.5 模式
如果您没有访问GPT4 api的权限,此模式将允许您使用自动GPT!
python scripts/main.py --gpt3only
建议将虚拟机用于需要高度安全措施的任务,以防止对主计算机的系统和数据造成任何潜在危害。
🖼 图像生成
默认情况下,自动GPT使用DALL-e生成图像。要使用稳定扩散,需要一个HuggingFace API(https://huggingface.co/settings/tokens)令牌。
一旦您有了令牌,请在.env中设置以下变量:
IMAGE_PROVIDER=sd
HUGGINGFACE_API_TOKEN="YOUR_HUGGINGFACE_API_TOKEN"
⚠️ 局限性
这个实验旨在展示GPT-4的潜力,但也有一些局限性:
1、不是一个完善的应用程序或产品,只是一个实验
2、在复杂的、真实的业务场景中可能表现不佳。事实上,如果真的发生了,请分享你的结果!
3、运行起来相当昂贵,所以使用OpenAI设置和监控您的API密钥限制!
最后,Auto GPT 是一种人工智能语言模型,可以根据输入的文本生成类似的文本输出。虽然 Auto GPT 能够完成许多与自然语言相关的任务,但它并不能完全替代人类的工作。
虽然 Auto GPT 可以在某些方面替代人类的工作,例如生成自然语言文本,但是它仍然存在一些限制。Auto GPT 不能像人类一样具备创造力和判断力,也无法进行实际的物理操作和交互。此外,Auto GPT 的输出结果也可能存在偏差和错误,需要人类对其进行审核和修正。
因此,虽然 Auto GPT 可以在某些特定领域内替代部分人类工作,但在许多领域中,人类仍然是不可替代的,所以说能替代90%的人工作,有点夸张,创造力、判断力、沟通能力等方面的任务中都是不可替代的。