网页解析完成的是从下载回来的html文件中提取所需数据的方法,一般会用到的方法有:
正则表达式:将整个网页文档当成一个字符串用模糊匹配的方式来提取出有价值的数据
Beautidul Soup:一个强大的第三方插件
lxml:解析html网页或者xml网页
不同解析办法只是匹配的方式不同,按道理来说几种方法可以相互替换,正则表达式的语法就不做赘述,这里介绍一下Python中的一个库Beautidul Soup,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。

Beautiful Soup
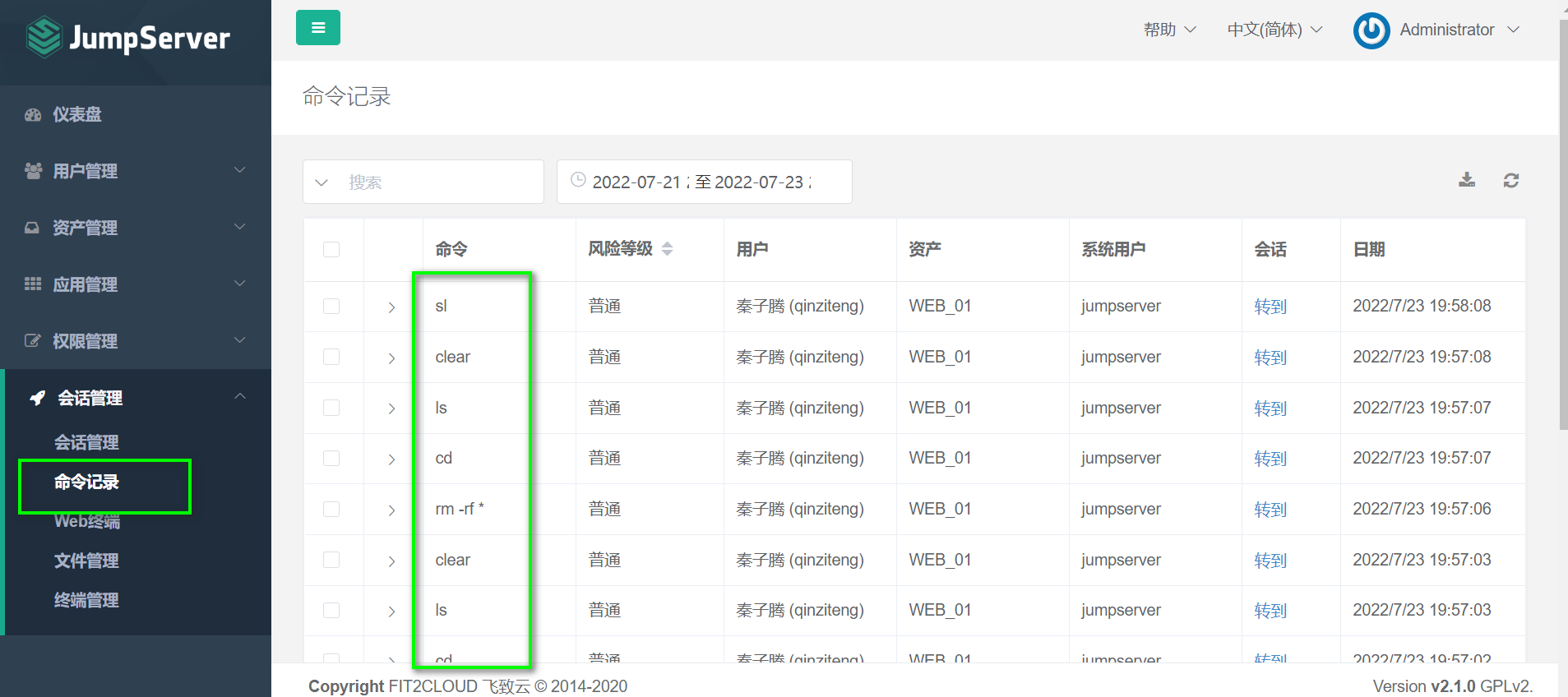
官方中文文档 搜索过程:
根据结构化解析的方式将对html的节点按照节点的名称/属性/文字进行搜索:
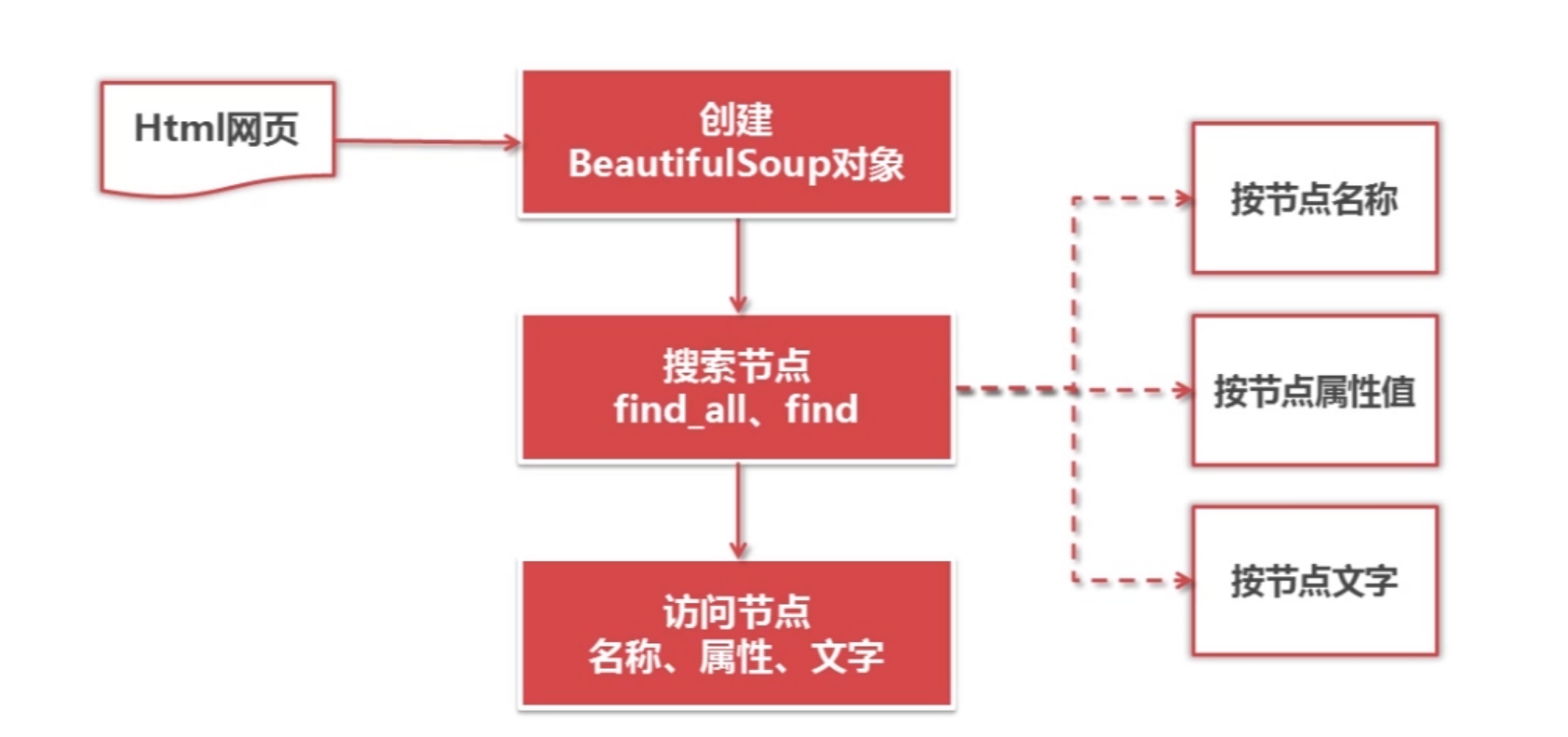
Beautiful使用方法为:
首先根据html网页和解析编码方式创建一个bs对象
调用find_all或者find方法对节点进行搜索,或者使用find()返回第一个匹配结果
对于搜索到的结果 find all(name,attrs,string)其中name参数表示节点的标签名称,attr为节点的属性名称,string为节点的文字内容。
from bs4 import BeautifulSoup
#根据HTML网页字符串创建BeautifulSoupi对象
soup=BeautifulSoup(
html doc,#HTML文档字符串
'html.parser' #HTML解析器
from_encoding='utf8'#HTML文档的编码
)
#搜索节点
#方法:
#查找所有标签为a的节点
soup.find_al1('a')
#查找所有标签为a,链接符合/view/123.htm形式的节点
soup.find_al1('a',href=‘/view/123.htm')
soup.find_all('a',href=re.compile(r'/view/\d+\.htm2))
#查找所有标签为div,class为abc,文字为Python的节点。class后加'_'是因为python的保留字
soup.find_all('div',class_='abc',string='Python')find_all方法会返回所有满足要求的节点的列表(tag对象组成的列表),至于节点内容的提取则需要借助get方法(提取属性)或者ger_text()方法(提取文本段落)。具体使用方法可以见之前的一次爬虫实战——爬取壁纸
由于 Beautiful Soup 的解析是基于正则表达式的(’html.parser’),用在缺乏正确标签结构的破损网页上很有效。但是如果想要遍历更加复杂的页面,或者想要抓取器运行得更快并且快速地浏览页面,有很多更加高级的 Python 库可用。让我们看一下许多天才网页抓取器开发者最爱的库: lxml。
CSS
CSS解析方法可以借助bs4中的BeautifulSoup('lxml').select()方法实现,该方法会执行一个css选择
find 利用 DOM 来遍历元素,并基于祖先和家族关系找到它们,而 cssselect 方法利用 CSS 选择器来寻找页面中所有可能的匹配,或者元素的后继,非常类似于 jQuery。
Xpath
菜鸟教程XPath 语法 | 菜鸟教程
https://www.cnblogs.com/hushaojun/p/16124814.html
Xpath是一种基于xml文档的解析方式。
XPath 可以用于几乎所有主要的网页抓取库,并且比其他大多数识别和同页面内容交互的方法都快得多。事实上,大多数同页面交互的选择器方法都在库内部转化为 XPath。
XPath是一种用于选取XML或HTML文档中某部分的表达式语言,通过在文档树中进行导航,可以定位到元素和元素集。在Python中,我们可以使用`lxml`库来解析XML或HTML文档并使用XPath表达式来查找特定元素。下面介绍一下如何使用XPath解析HTML或XML文档:
Xpath使用方法
1. 安装和导入`lxml`库;
2. 获取HTML或XML文档,可以通过`urllib`、`requests`等库从互联网上获取,也可以通过本地文件打开;
3. 使用`lxml`将文档转换为XPath对象,使用`parse()`方法即可;
4. 用XPath语法指南文档树的对应节点进行选择,并获取其中的内容。
以下是一个示例代码,演示了如何使用`lxml`库和XPath表达式解析HTML文档中的数据:
from lxml import etree
import requests
# 发送 HTTP 请求,请求目标页面
response = requests.get("http://www.example.com")
# 解析 HTML 内容
doc = etree.HTML(response.text)
# 使用 XPath 找到所有链接并输出其 URL 和文本内容
links = doc.xpath('//a')
for link in links:
print(link.get('href'), link.text)
在这个示例程序中,首先发送HTTP请求获取目标页面的HTML内容。然后,利用`etree.HTML`将HTML内容转换为XPath对象`doc`,接着使用XPath表达式`//a`查找所有的链接,最后遍历每一个链接,输出它的URL和文本内容。
xpath语法
XPath语法是一种用于定位XML或HTML文档节点的表达式语言,包含了众多的可用函数和操作符,常用的语法如下:
/:选择根节点;//:选择子孙节点,无论它们在文档中的位置;.:选择当前节点;..:选择当前节点的父节点;@:选择属性节点;[]:条件筛选,可以用于过滤选定的节点;|:取并集;*:通配符,匹配任意元素节点;text():匹配文本节点。
还有更多语法规则,以下是一些实例:
还有更多语法规则,以下是一些实例:
- 选取所有节点:
/ # 选择根节点//# 选择所有节点- 选取特定名称的节点:
//tagName # 选择指定名称的节点- 选取某个节点的子节点:
/bookstore/book/title # 选择 bookstore 节点的子节点 book 中的 title 节点- 选取某个节点的父节点:
/bookstore/book/title/../.. # 选择 bookstore 节点的父节点- 选取某个节点的属性:
//tagName[@attributeName='attributeValue']
//a[@href='/about']- 过滤选定的节点:
//tag[@attributeName='attributeValue'] # 筛选出 tagName 节点,其 attributeName 属性的值等于 attributeValue//tag[contains(@attributeName, 'substring')] # 筛选出 tagName 节点,其 attributeName 属性包含 substring 子字符串- 文本内容筛选:
//p[text()='paragraph text'] # 筛选出文本内容等于 paragraph text 的 p 节点
//p[starts-with(text(), 'substring')] # 筛选出文本内容以 substring 开头的 p 节点在XPath语法中,还可以使用常规数学运算符和逻辑运算符,例如+、-、*、<、<=、>等。使用这些运算符可以进行更复杂的条件筛选,以选择更特定的节点。