文章目录
- CentOS 8自动化安装MongoDB
- 安装Master-Slave集群
- 安装并测试副本集(Replica Set)集群
- 安装副本集(Replica Set)集群
- 实验测试
- 安装并测试分片集群(Sharding)
注意实验使用的是ARM架构的CentOS 8 虚拟机
CentOS 8自动化安装MongoDB
- 首先,更新系统并安装必要的依赖项:
sudo dnf update -y
sudo dnf install -y wget
- 添加 MongoDB 官方仓库:
创建一个新的仓库文件 /etc/yum.repos.d/mongodb-org.repo:
sudo nano /etc/yum.repos.d/mongodb-org.repo
将以下内容添加到文件中,保存并退出:
[mongodb-org-5.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/5.0/aarch64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-5.0.asc
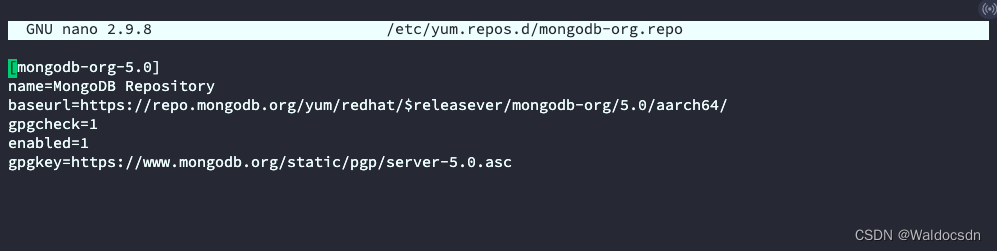
使用nano编辑器打开/etc/yum.repos.d/mongodb-org.repo文件后,按下Ctrl + X组合键退出编辑模式,按下Y键保存更改,然后按下Enter键确认保存。如果不想保存更改,则可以按下N键,然后按下Enter键不保存更改并退出编辑器。
- 安装 MongoDB:
sudo dnf install -y mongodb-org
- 启动 MongoDB 服务并设置开机自启动:
sudo systemctl start mongod
sudo systemctl enable mongod

- 检查 MongoDB 服务状态:
sudo systemctl status mongod
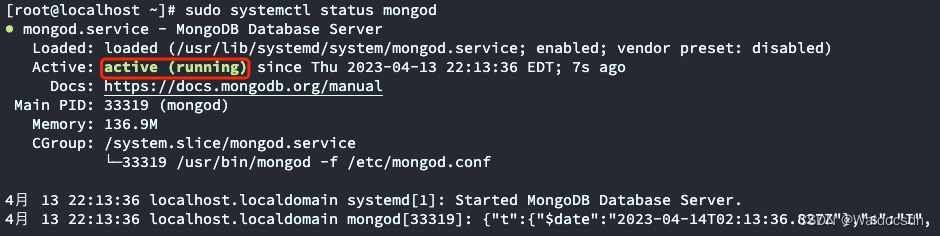
现在,已成功安装了 MongoDB。接下来,了解如何使用 MongoDB。
- 使用 mongo shell 连接到 MongoDB 服务:
mongo
这将打开一个交互式 mongo shell,您可以在其中执行 MongoDB 命令。
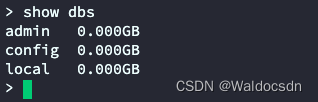
- 显示数据库列表:
show dbs
- 创建或切换到一个数据库,例如 myDatabase:
use myDatabase
- 在当前数据库中创建一个集合并插入文档:
db.myCollection.insert({name: "John", age: 30, city: "New York"})
- 查询当前集合中的所有文档:
db.myCollection.find()
这些是一些基本的 MongoDB 操作。可以在 MongoDB 官方文档中找到更多详细信息和高级功能:https://docs.mongodb.com/manual/
安装Master-Slave集群
因新版本 MongoDB 已不再支持主从复制(Master/Slave Replication),这里只讲解安装过程,不进行实际测试。如果需要请使用 MongoDB(如 3.6.x)进行实验。
注意新版本 MongoDB 已不再支持主从复制(Master/Slave Replication),需要使用 MongoDB(如 3.6.x)进行实验。MongoDB 官方建议使用副本集代替主从复制,因为副本集提供了更高的数据可用性和容错能力,同时具有自动故障转移功能。
- 首先确保您已经按照之前的步骤安装了 MongoDB
- 在服务器(CentOS 8)上创建两个单独的目录用于存储主节点和从节点的数据:
sudo mkdir -p /data/db-master
sudo mkdir -p /data/db-slave

- 更改这两个目录的所有权,使其属于当前用户:
sudo chown -R `whoami`:`whoami` /data/db-master
sudo chown -R `whoami`:`whoami` /data/db-slave

- 启动主节点实例:
mongod --dbpath /data/db-master --port 27017 --master
- 启动从节点实例:
在另一个终端窗口中运行以下命令:
mongod --dbpath /data/db-slave --port 27018 --slave --source localhost:27017
现在,您已经在同一台服务器上启动了两个 MongoDB 实例,分别作为主节点和从节点。接下来进行实验测试:
- 向主节点插入数据:
连接到主节点的 MongoDB shell:
mongo --port 27017
选择一个数据库,创建一个集合并插入文档:
use testDB
db.testCollection.insert({name: "Alice", age: 28})
- 查询主节点的数据:
db.testCollection.find()
- 查询从节点的数据:
连接到从节点的 MongoDB shell:
mongo --port 27018
在从节点 MongoDB shell 中,启用从节点查询:
rs.slaveOk()
选择数据库并查询数据:
use testDB
db.testCollection.find()
现在能在从节点上看到主节点插入的数据。
-
停止主节点以测试故障转移:
首先,在主节点运行的终端窗口中,按 Ctrl+C 停止 MongoDB 实例。 -
在从节点上启动新的主节点:
首先,停止从节点实例。然后,运行以下命令,将从节点转换为主节点:
mongod --dbpath /data/db-slave --port 27018 --master
- 向新主节点插入数据:
连接到新主节点的 MongoDB shell:
mongo --port 27018
选择相同的数据库并插入一个新文档:
use testDB
db.testCollection.insert({name: "Bob", age: 32})
- 查询新主节点上的数据:
db.testCollection.find()
现在,能在新主节点上看到之前插入的数据和新插入的数据。注意新版本 MongoDB 已不再支持主从复制(Master/Slave Replication),需要使用 MongoDB(如 3.6.x)进行实验。MongoDB 官方建议使用副本集代替主从复制,因为副本集提供了更高的数据可用性和容错能力,同时具有自动故障转移功能。
安装并测试副本集(Replica Set)集群
本实验使用在arm架构centos8上的mongodb,安装副本集(Replica Set)集群,并进行小型实验测试。在一台机器上完成,通过不同端口来模拟不同的服务器。实验测试有插入数据、查询数据、停止主节点测试故障转移、手动提升从节点为主节点、向新主节点插入数据等功能。
副本集(Replica Set)集群实验完美成功~~~
安装副本集(Replica Set)集群
- 首先,确保您已经按照之前的步骤安装了 MongoDB。
- 创建三个单独的目录,用于存储三个 MongoDB 实例的数据:
sudo mkdir -p /data/db1
sudo mkdir -p /data/db2
sudo mkdir -p /data/db3
- 更改这三个目录的所有权,使其属于当前用户:
sudo chown -R `whoami`:`whoami` /data/db1
sudo chown -R `whoami`:`whoami` /data/db2
sudo chown -R `whoami`:`whoami` /data/db3

- 启动三个 MongoDB 实例:
在三个不同的终端窗口中分别运行以下命令,将 <your server’s IP address> 替换为你的服务器 IP 地址。:
刚刚安装的MongoDB会先占用27017端口,运行以下命令以查看占用27017端口的进程PID,然后杀死该进程或更改 MongoDB 实例的端口来解决冲突:
sudo lsof -i :27017
kill <pid>
再在三个不同的终端窗口中分别运行以下命令:
mongod --dbpath /data/db1 --port 27017 --replSet rs0 --bind_ip localhost,<your server's IP address>
mongod --dbpath /data/db2 --port 27018 --replSet rs0 --bind_ip localhost,<your server's IP address>
mongod --dbpath /data/db3 --port 27019 --replSet rs0 --bind_ip localhost,<your server's IP address>
我的ip是192.168.178.130,所以命令是下面三个启动MongoDB 实例的命令:
mongod --dbpath /data/db1 --port 27017 --replSet rs0 --bind_ip localhost,192.168.178.130
mongod --dbpath /data/db2 --port 27018 --replSet rs0 --bind_ip localhost,192.168.178.130
mongod --dbpath /data/db3 --port 27019 --replSet rs0 --bind_ip localhost,192.168.178.130
- 连接到任一 MongoDB 实例的 shell:
再打开一个命令行窗口:
mongo --port 27017
- 初始化副本集:
在 MongoDB shell 中,运行以下命令:
rs.initiate({_id: "rs0", members: [{_id: 0, host: "localhost:27017"}, {_id: 1, host: "localhost:27018"}, {_id: 2, host: "localhost:27019"}]})

实验测试
现在副本集已经建立。接下来进行实验测试:
- 向主节点插入数据:
首先查找主节点:
rs.status()
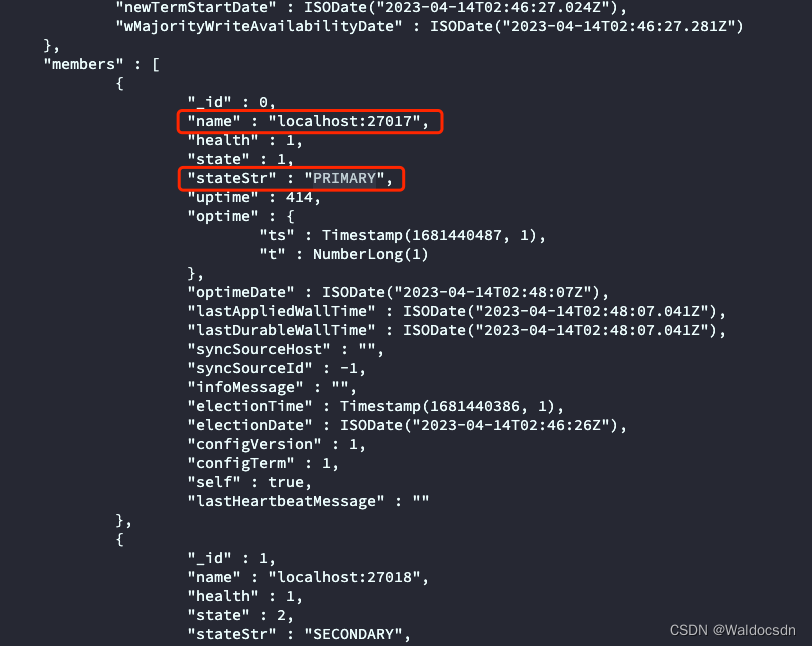
在上述信息中,找到 name 为主机名或 IP 地址的节点,其 stateStr 为 PRIMARY,则为主节点,如下图:
再打开一个命令行窗口(第5个),连接到主节点的 MongoDB shell,并选择一个数据库,创建一个集合并插入文档:
mongo --port 27017
use testDB
db.testCollection.insert({name: "Alice", age: 28})
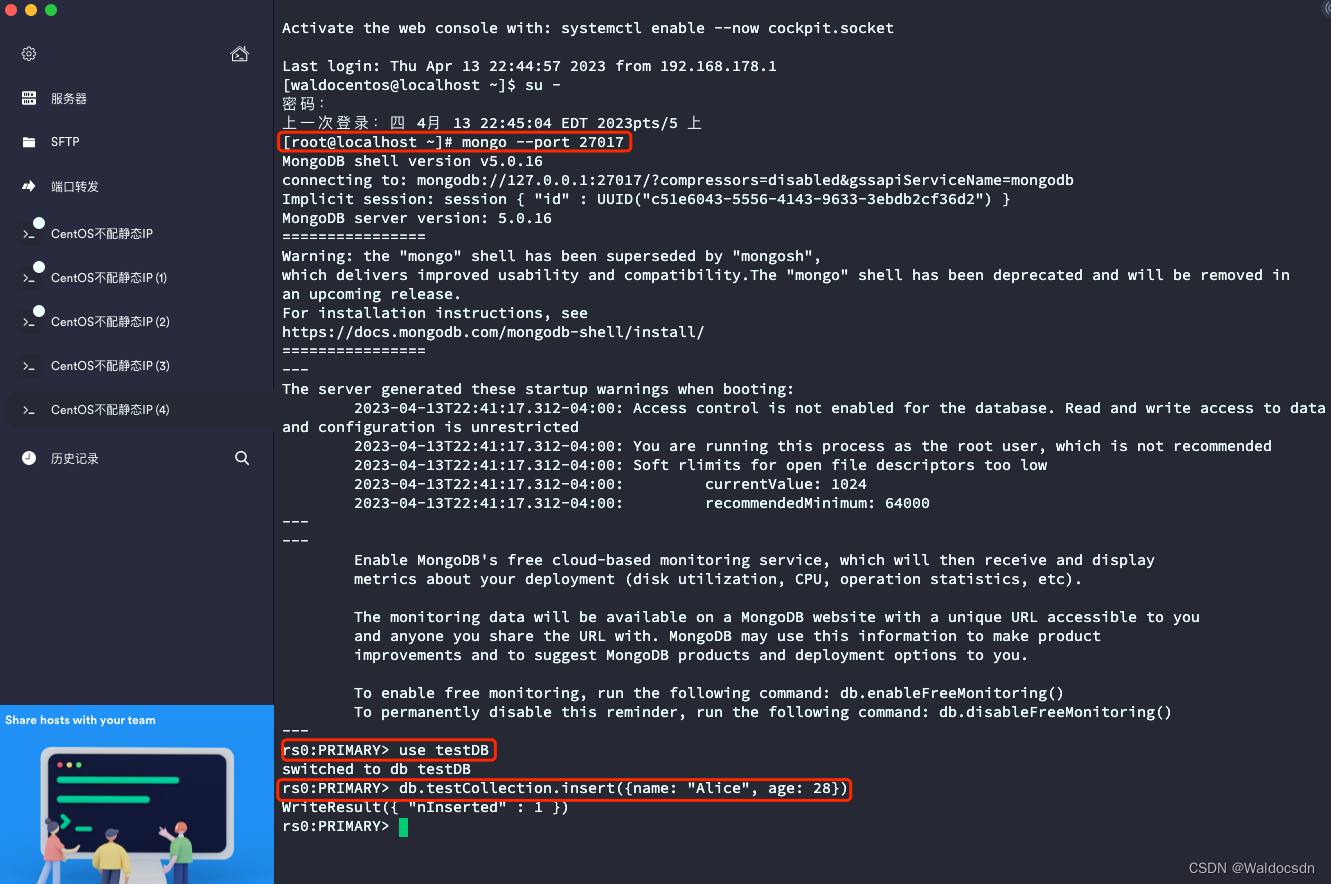
- 查询数据:
在主节点上查询数据:
db.testCollection.find()

在从节点上查询数据(再打开一个命令行窗口,这是第6个。连接到从节点的 MongoDB shell:):
mongo --port 27018
在从节点 MongoDB shell 中,启用从节点查询:
rs.secondaryOk()
选择数据库并查询数据:
use testDB
db.testCollection.find()

现在能在从节点上看到主节点插入的数据。
-
停止主节点以测试故障转移:
首先,确定当前主节点的端口(27017、27018 或 27019)。然后,在主节点运行的终端窗口中,按Ctrl+C停止 MongoDB 实例。 -
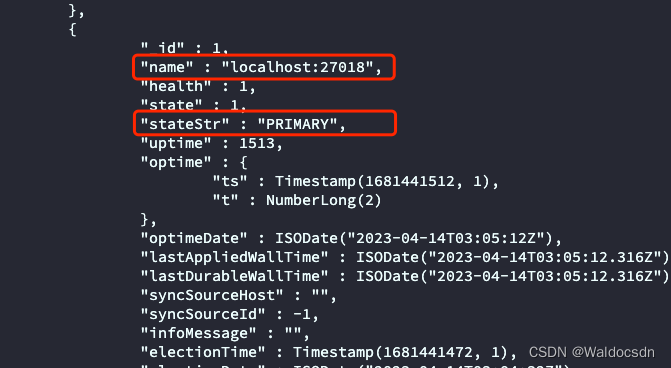
查看故障转移是否成功:
在另外两个节点上运行以下命令查看其状态:
rs.status()
在输出中,能看到另外一个节点已经成为新的主节点,其 stateStr 为 PRIMARY,是新的主节点,如下图:
- 手动提升从节点为主节点:
如果您希望手动将某个从节点提升为主节点,请在当前主节点的 MongoDB shell 中运行以下命令:
比如现在主机端口是27018,我想换成端口是27019变成主节点:
mongo --port 27018
rs.stepDown()
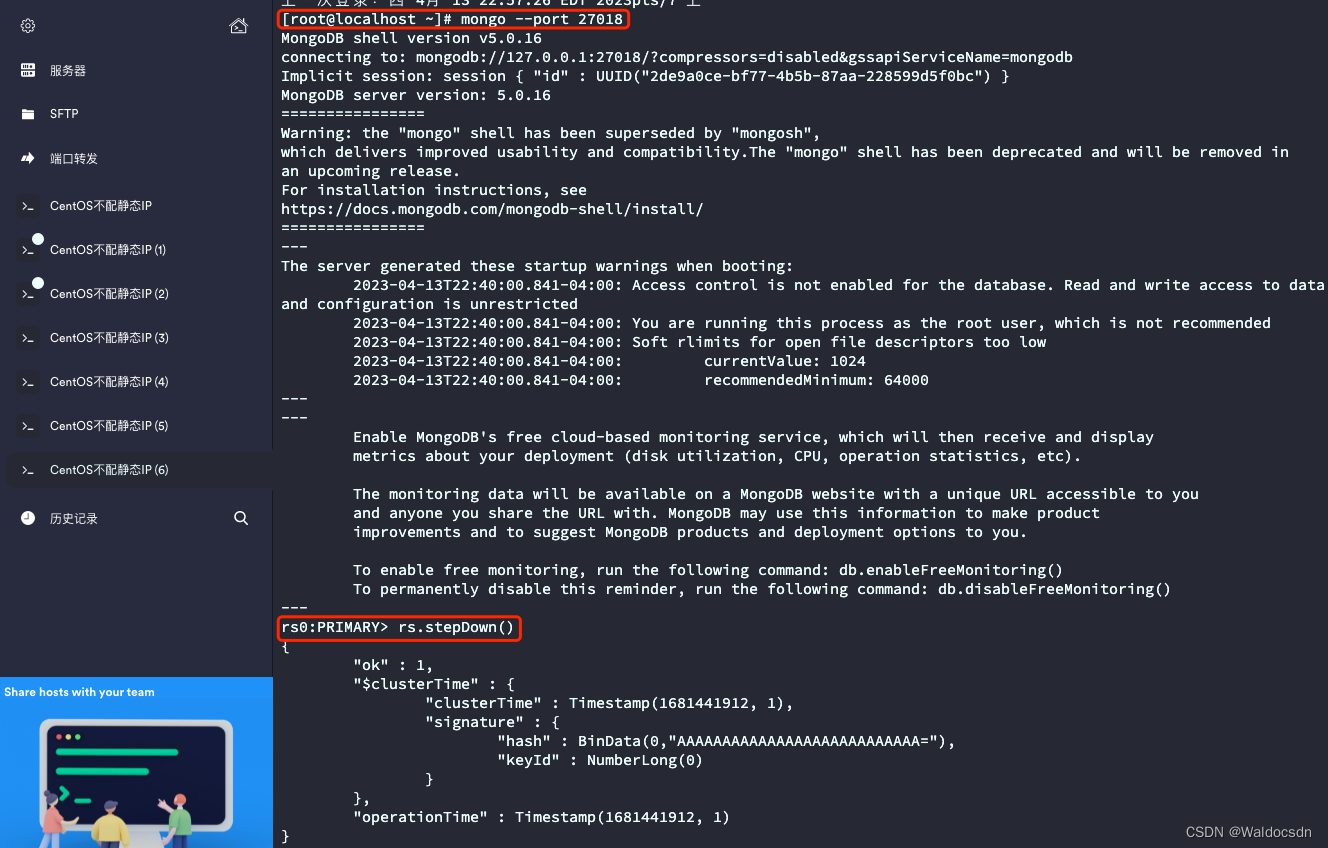
该节点(端口号)会将其主节点身份释放,并开始进行选举以产生新的主节点。
再次查看,发现主节点变成端口号是27019的机器:
rs.status()
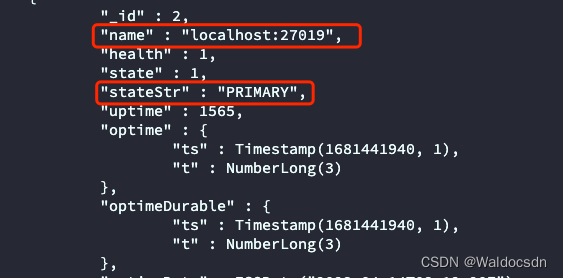
- 向新主节点插入数据:
连接到新主节点的 MongoDB shell:
mongo --port 27019
选择相同的数据库并插入一个新文档:
use testDB
db.testCollection.insert({name: "Bob", age: 32})
- 查询新主节点上的数据:
db.testCollection.find()
现在,能在新主节点上看到之前插入的数据和新插入的数据。

安装并测试分片集群(Sharding)
本实验使用在arm架构centos8上的mongodb,安装分片集群(Sharding),并进行小型实验测试。在一台机器上完成,通过不同端口来模拟不同的服务器。实验测试有插入数据、查询数据、停止主节点测试故障转移、手动提升从节点为主节点、向新主节点插入数据等功能。
在一台CentOS 8(IP:192.168.178.130)机器上配置MongoDB分片集群(Sharding)的详细步骤如下:
- 创建目录结构:
sudo mkdir -p /data/shard1 /data/shard2 /data/shard3 /data/configdb /data/mongos
- 配置分片(shard)服务器:
sudo vi /data/shard1/mongod.conf
添加以下内容:
sharding:
clusterRole: shardsvr
replication:
replSetName: shard1ReplSet
storage:
dbPath: /data/shard1
net:
bindIp: 192.168.178.130
port: 27018
重复这个过程,分别为shard2(/data/shard2/mongod.conf)和shard3(/data/shard3/mongod.conf)创建配置文件,将端口号分别更改为27019和27020,以及将replSetName更改为shard2ReplSet和shard3ReplSet。
- 配置配置服务器(config server):
sudo vi /data/configdb/mongod.conf
添加以下内容:
sharding:
clusterRole: configsvr
replication:
replSetName: ConfigReplSet
storage:
dbPath: /data/configdb
net:
bindIp: 192.168.178.130
port: 27040
- 配置mongos路由服务器:
sudo vi /data/mongos/mongos.conf
添加以下内容:
sharding:
configDB: ConfigReplSet/192.168.178.130:27040
net:
bindIp: 192.168.178.130
port: 27017
- 启动各个组件:
sudo mongod -f /data/configdb/mongod.conf
sudo mongod -f /data/shard1/mongod.conf
sudo mongod -f /data/shard2/mongod.conf
sudo mongod -f /data/shard3/mongod.conf
sudo mongos -f /data/mongos/mongos.conf
- 初始化配置服务器复制集:
mongo --host 192.168.178.130 --port 27040
在MongoDB shell中输入:
rs.initiate({_id: "ConfigReplSet", configsvr: true, members: [{_id: 0, host: "192.168.178.130:27040"}]})
- 初始化分片服务器复制集:
对于shard1、shard2和shard3,使用以下命令连接:
mongo --host 192.168.178.130 --port 27018
mongo --host 192.168.178.130 --port 27019
mongo --host 192.168.178.130 --port 27020
分别在每个shard的MongoDB shell中输入以下内容,将“shardXReplSet”替换为相应的复制集名称(例如:shard1ReplSet、shard2ReplSet、shard3ReplSet):
rs.initiate({_id: "shardXReplSet", members: [{_id: 0, host: "192.168.178.130:<shard-port>"}]})
将<shard-port>替换为分片的端口号(27018、27019或27020)。
- 添加分片到mongos:
mongo --host 192.168.178.130 --port 27017
在MongoDB shell中输入:
sh.addShard("shard1ReplSet/192.168.178.130:27018")
sh.addShard("shard2ReplSet/192.168.178.130:27019")
sh.addShard("shard3ReplSet/192.168.178.130:27020")
- 创建数据库并启用分片:
use mydb
sh.enableSharding("mydb")
- 选择集合并设置分片键:
sh.shardCollection("mydb.mycollection", {_id: "hashed"})
现在MongoDB分片集群已经设置完成。您可以插入数据、查询数据、测试故障转移等。
插入数据:
db.mycollection.insert({name: "John Doe", age: 30})
查询数据:
db.mycollection.find({name: "John Doe"})
为了在一台机器上测试故障转移和手动提升从节点为主节点,我们可以在本地模拟网络故障,停止主节点并观察从节点提升为主节点。首先,我们需要找出主节点:
use mydb
db.runCommand({isMaster: 1})
停止主节点(假设主节点是shard1,端口27018):
sudo mongod --dbpath /data/shard1 --shutdown
查看从节点(shard2或shard3)提升为主节点:
mongo --host 192.168.178.130 --port <shard-port>
将<shard-port>替换为从节点的端口号(27019或27020),然后执行:
rs.status()
找到新的主节点后,您可以使用db.mycollection.insert()命令向新的主节点插入数据。
请注意,这些命令和步骤是在一台机器上设置MongoDB分片集群的简化示例。在生产环境中,需要在多台机器上设置副本集以确保高可用性和数据冗余。
- 故障转移:
在生产环境中,每个分片都应该是一个副本集,包含多个节点。在我们的实验设置中,由于我们仅在单台机器上进行操作,每个分片都只有一个节点。因此,我们无法在此设置中直接演示故障转移。但是,我们可以介绍如何在具有多个节点的副本集中进行故障转移。
在一个具有多个节点的副本集中,当主节点发生故障时,自动发生故障转移。这时,从节点之间会发生选举,选出一个新的主节点。故障转移过程通常在几秒钟内自动完成。
- 手动提升从节点为主节点:
在具有多个节点的副本集中,您可以通过调整成员的优先级来影响主节点的选举。例如,您可以将一个从节点的优先级设置得比其他节点高,以确保它在下一次选举中被选为主节点。您可以使用以下命令调整优先级:
cfg = rs.conf()
cfg.members[1].priority = 2
rs.reconfig(cfg)
当新的主节点被选举出来后,您可以向新的主节点插入数据,如下所示:
db.mycollection.insert({name: "Jane Doe", age: 28})
请注意,我们在本教程中展示的设置是为了实验和学习目的,因此在单台机器上进行操作。然而,在生产环境中,建议使用多台机器来设置副本集,以确保高可用性和数据冗余。在实际的生产环境中,需要根据实际需求和场景调整设置和配置。