目录
- 写在前面
- 1、Counting DNA Nucleotides
- Problem
- Sample Dataset
- Sample Output
- Code
- Output
- 2、Transcribing DNA into RNA
- Problem
- Sample Dataset
- Sample Output
- Code
- Output
- 3、Complementing a Strand of DNA
- Problem
- Sample Dataset
- Sample Output
- Code
- Output
- 4、Rabbits and Recurrence Relations
- Problem
- Sample Dataset
- Sample Output
- Code
- Output
- 5、Computing GC Content
- Problem
- Sample Dataset
- Sample Output
- Code
- Output
写在前面
ROSALIND: https://rosalind.info/problems/locations/
Rosalind是一个通过解决问题来学习生物信息学和编程的平台。使用此刷题网站的好处是在学习生物信息学的同时,能够加强编程能力,并且在实践中学习,快速进步。
在此将题目与答案记录下来,方便日后翻阅查看,如有错误还望读者批评指正。
刷题之前,需要提前安装配置好python。 笔者使用的python版本是3.9.7,版本不同,相应的代码可能会有差别,需要注意一下。
1、Counting DNA Nucleotides
Problem
碱基是组成遗传密码的基本单元,其中碱基A、G、C、T存在于DNA中,而A、G、C、U存在于RNA中。(A:腺嘌呤,G:鸟嘌呤,C:胞嘧啶,T:胸腺嘧啶,U:尿嘧啶)
DNA双螺旋结构中,位于两条方向相反、相互平行多核苷酸链上的嘌呤嘧啶碱基,围绕着螺旋轴,通过形成氢键,互相搭配成对,称为碱基配对。碱基配对,即一条长链上的A,总是与另一条长链上的T形成氢键; 而G总是与C形成氢键。即A=T、G≡C。
Given: 一条DNA链 s ,其长度不超过1000 nt。
Return: 四个整数(用空格分隔),分别计算符号“A”、“C”、“G”和“T”在 s 中出现的次数。
Sample Dataset
AGCTTTTCATTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTGTCTGATAGCAGC
Sample Output
20 12 17 21
Code
# Counting DNA Nucleotides
def count(s):
A_count = s.count("A")
C_count = s.count("C")
G_count = s.count("G")
T_count = s.count("T")
return A_count, C_count, G_count, T_count
example = "AGCTTTTCATTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTGTCTGATAGCAGC"
A, C, G, T = count(example)
print(f"{A} {C} {G} {T}")
with open('rosalind_dna.txt', 'r') as file:
DNA = file.read()
# print(f"The length of this file is {len(DNA)}")
A, C, G, T = count(DNA)
print(f"{A} {C} {G} {T}")
Output
20 12 17 21
215 243 237 245
注意
- 答题时,会下载一个文件,需要基于下载的文件进行操作
- 每次下载的文件是随机的,所以答案并不固定
- 需要输入正确答案才能下载下一题的文件

2、Transcribing DNA into RNA
Problem
转录(Transcription)是在RNA聚合酶的催化下,遗传信息由DNA复制到RNA(尤其是mRNA)的过程。作为蛋白质生物合成的第一步,转录是合成mRNA以及非编码RNA(tRNA、rRNA等)的途径。
真核生物合成蛋白质的转录过程以特定的单链DNA片段作为模板,RNA聚合酶作为催化剂,合成前mRNA,前mRNA经进一步加工后转为成熟mRNA。
转录时,DNA分子的双链打开,在RNA聚合酶的作用下,游离的4种核糖核苷酸按照碱基互补配对原则结合到DNA单链上,并在RNA聚合酶的作用下形成单链mRNA分子。
A(腺嘌呤)一定与T(胸腺嘧啶)或者在RNA中的U(尿嘧啶)配对,G(鸟嘌呤)与C(胞嘧啶)配对。
Given: 一条DNA链 t ,其长度不超过1000 nt。
Return: 由 t 经转录得到的RNA链。
Sample Dataset
GATGGAACTTGACTACGTAAATT
Sample Output
GAUGGAACUUGACUACGUAAAUU
Code
# Transcribing DNA into RNA
def transcribing(t):
t = t.replace("T", "U")
return t
RNA = "GATGGAACTTGACTACGTAAATT"
print(transcribing(RNA))
with open("rosalind_rna.txt", "r") as file:
RNA = file.read()
print(transcribing(RNA))
Output
GAUGGAACUUGACUACGUAAAUU
CACCAAACAGCCUUACAGCCUCCAUAAAGAGGACAUUUCUACAAGACGCAUGCCGACCCUCGCCGUCUAGUCACCCUCCUAUCGUUCCCUGUAAGUAGUUGGCUUAAGCCACCAAUUGCAAGUGUGAUUAGAUAUUAACUCCAUAUUUCGCUGGAUGUACCCGGCAUGUGCGUCGCCACGAACCUUCUGACCCUUGGACUAUGACACUACGCCGCGCAGUAUGCCUCAAAAGUGUAUGUAUUAUAGGAUUGCUCGUGGCACAAAGCUCGUGGUACCUUAAGAUCAAGUGGCACACAAUUCAUCAUUCGAUACUUAAUCGGGAUUCUACAGCAGUGACGUUGGGAAGACAGGUUCUCAGGUGGGGAUGAAUAGAGACCUAAUGAAAACCUACCAGCUGUGUGACUCGCACAGAAUCCGUGGCGGCAACUACUAUGUAUCAACCCCUGGCAGCACAAGUCUAAUGCAUACCUUUGCCUUGUUGGGCGUCUGUAAUCGUAUGUACCGUCAGUGCCGAUUCGGUUGAACAGAGACUGGGCAUGGCUGUUAGAGUUUGUUCCCACAUAGAAGGGAACGGGGUUACUUUCGAACCAUAGAUGACCACCAGAAUGGAAAGUUCAGAUGGAUGGCCGGGAACCCUUUAUACAGCGACUCCCAUCACGCUGUCUCCUCGGGACUUGUAAGUAGUGGUGUCGCACUGAAGGUAACAAGCGGUAACUCGCUGGUCGUAGUUUACGAGUCACGAGUCGGGAAAGGCGAGUCGCCCCAAUGCGAUACGACUAAAGCGGGUGUCUGAUGAAUCUAUUCCACAGACCACUUUCACAGCCGCAAGGUGGUCCUUAUCCUCACAUAUGUAUGUGAUGGUAACGGAAGACUCGAACGGAAAUCUAAUCCCAAAAUAAACAUCAGGGCGACUAUCCAGUCGCCUAAGAGUAACUUGAUUUGUAGGGGCGAAAGGGUCCGGCCAGAUUUAAGAGUUAUACUUAUAGCU
3、Complementing a Strand of DNA
Problem
转录(Transcription)是在RNA聚合酶的催化下,遗传信息由DNA复制到RNA(尤其是mRNA)的过程。作为蛋白质生物合成的第一步,转录是合成mRNA以及非编码RNA(tRNA、rRNA等)的途径。
真核生物合成蛋白质的转录过程以特定的单链DNA片段作为模板,RNA聚合酶作为催化剂,合成前mRNA,前mRNA经进一步加工后转为成熟mRNA。
转录时,DNA分子的双链打开,在RNA聚合酶的作用下,游离的4种核糖核苷酸按照碱基互补配对原则结合到DNA单链上,并在RNA聚合酶的作用下形成单链mRNA分子。
A(腺嘌呤)一定与T(胸腺嘧啶)或者在RNA中的U(尿嘧啶)配对,G(鸟嘌呤)与C(胞嘧啶)配对。
Given: 一个长度不超过1000 bp的DNA链s。
Return: 与s互补的链sc。
Sample Dataset
AAAACCCGGT
Sample Output
ACCGGGTTTT
Code
# Complementing a Strand of DNA
def complement(s):
s = s[::-1]
sc = ""
for i in s:
if i == "A":
sc += "T"
elif i == "T":
sc += "A"
elif i == "C":
sc += "G"
elif i == "G":
sc += "C"
return sc
DNA = "AAAACCCGGT"
print(complement(DNA))
with open("rosalind_revc.txt", "r") as file:
DNA = file.read()
print(complement(DNA))
Output
ACCGGGTTTT
TTCATGATTGCGAGTCGGGCCCTGGGGACGTCCCCACCCTGGCAGCTTACTAAGGCAAAGTCGCTTGCTGAGGTTTGGGCTTTGAGATAAACGCCTCTTTGGCAGGCGCAAAAGGCCGGTGGACACCGGCTCGTTGCCCATGCCACAGGACTCAATACACGGGGTAAAGTTCGTGCGCTGATATTACGTTGTCAAGCTAACCTTAGGAAAGGTTCTAATTAAAGGGACCCGAGTGACGCGTCTAATATTTTCAACAGATATGTGTTCGGACCCACGAACAGCATTGTACATGCAAGACCTATTAATGGATATGCGTTTTGACTCAGTGACCCAGCGTATAACATATTTCGTCTTCTGCGTCATATCATAAACCAACGGACAATTCGACTGGAGTGCACTGTCTCCAACGCCCGTCATGCGGCTCAGTATCAACTGATAACACTTGGTGCTACCGGTTCGGTACGCCAGTCCAACAGAATGATGGGAACGTGCGCCAGTGGGCATTCACCACACTATTACAGGTAGAGTATGATAGATGAAAGTAAGTTGTACATGACCCTTTCTTATGTAAACCTCCTGTCCGGGCCCGGGGAATCGTGGTTGATCTCCACTTTGCGTGAAAATACGACGTATATACCTCCGTCGGGCGAAAACTCTCTCTCTACTCTAGCACACAAAAGTATGTGCGCGGGCGTACCTGGAACCCCAGACCTCCCTGTAAGAGGGGTAATTCTCCACTAAGCGCGACCTAAAGCCTCGTCATCGGGGGGTAAAGAGTATTGCTTGCTGTATACGGTCAATGAGCCACGATCCTGTGTACCATTTCGTTTCATTTCGGAAGGGGCCAGCCATGGCCATCGAAGTAGCGTAGAGCGTAGGACTATGTGGACCTCCCTCCCAACGAGTGCACGGGGGGCCCTATACTCAACTCCAA
4、Rabbits and Recurrence Relations
Problem
斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89…
这个数列从第3项开始,每一项都等于前两项之和。
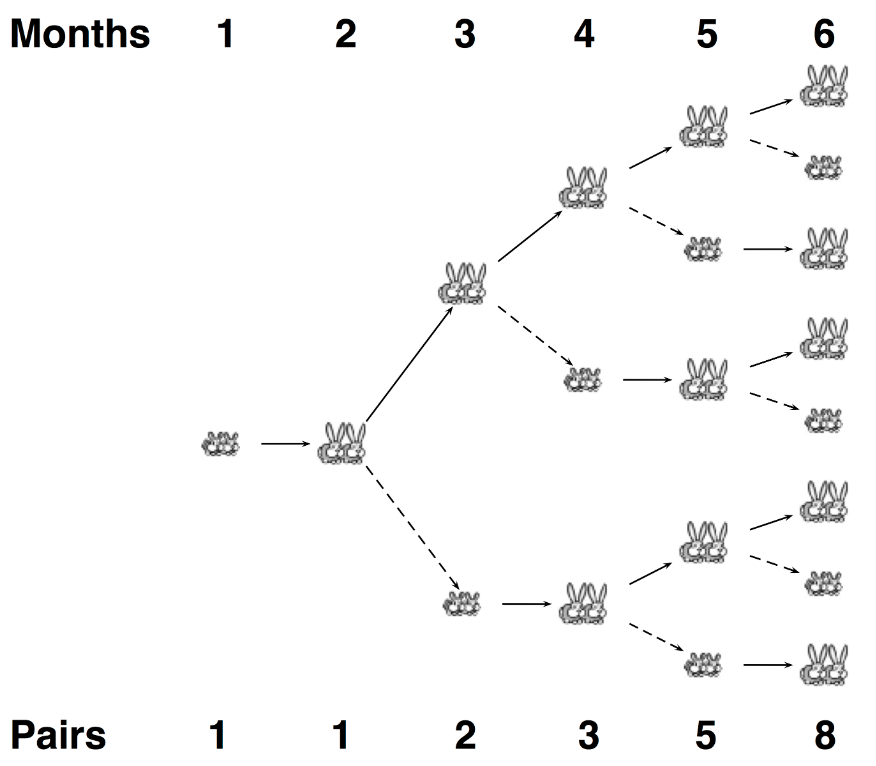
如图所示,最初只有一对未成年兔子,一个月后成年开始生育,每对兔子一次只生一对。生下来的兔子经过一个月之后成年,然后生育,循环往复~
Given: n,k为正整数,n≤40,k≤5
Return: 在n个月之后出现的兔子对的总数。
如果我们从1对开始,在每一代,每对繁殖年龄的兔子生产 k 对兔子(注意是 k 对)。
图中相当于n=1, k=1
Sample Dataset
5 3
Sample Output
19
Code
# Rabbits and Recurrence Relations
def fib_rabbits(n, k):
rabbits = [1, 1]
for i in range(2, n):
current_rabbits = rabbits[i - 1] + rabbits[i - 2] * k
rabbits.append(current_rabbits)
return rabbits[-1]
print(fib_rabbits(5, 3))
with open("rosalind_fib.txt", "r") as file:
text = file.read().split()
n = int(text[0])
k = int(text[1])
print(fib_rabbits(n, k))
Output
19
436390025825
5、Computing GC Content
Problem
GC含量(GC-content,guanine-cytosine content)是分子生物学和遗传学的术语,指研究对象(例如放线菌)的全基因组(DNA 或 RNA 分子)或其片段中,含氮碱基鸟嘌呤(G)或胞嘧啶(C)任何一个所占的百分比。一种生物的基因组或特定DNA、RNA片段有特定的GC含量。
例如,“AGCTATAG”的GC含量为 3/8 * 100% = 37.5%。任何DNA链的互补链都具有相同的GC含量。
在生物信息学中,FASTA格式是一种用于记录核酸序列或肽序列的文本格式,其中的核酸或氨基酸均以单个字母编码呈现。该格式同时还允许在序列之前定义名称和编写注释。
FASTA格式中的一条完整序列,包含开头的单行描述行和多行序列数据。描述行行首前置半角大于号(“>”)以和数据行区分。“>”后紧接的内容为该序列的标识符,该行剩余部分则为序列的描述(标识符与描述均非必须)。“>”和标识符之间不应有空格,且建议将单行内容限制在80字符以内。序列的结束以下一条序列的“>”出现为标识。
Given: n,k为正整数,n≤40,k≤5
Return: 在n个月之后出现的兔子对的总数。
如果我们从1对开始,在每一代,每对繁殖年龄的兔子生产 k 对兔子(注意是 k 对)。
图中相当于n=1, k=1
Sample Dataset
>Rosalind_6404
CCTGCGGAAGATCGGCACTAGAATAGCCAGAACCGTTTCTCTGAGGCTTCCGGCCTTCCC
TCCCACTAATAATTCTGAGG
>Rosalind_5959
CCATCGGTAGCGCATCCTTAGTCCAATTAAGTCCCTATCCAGGCGCTCCGCCGAAGGTCT
ATATCCATTTGTCAGCAGACACGC
>Rosalind_0808
CCACCCTCGTGGTATGGCTAGGCATTCAGGAACCGGAGAACGCTTCAGACCAGCCCGGAC
TGGGAACCTGCGGGCAGTAGGTGGAAT
Sample Output
Rosalind_0808
60.919540
Code
# Computing GC Content
def read_fasta(file):
"""字典存放序列名称和序列"""
sequences = {}
with open(file, "r") as f:
for line in f:
line = line.strip()
if line.startswith(">"):
name = line[1:]
sequences[name] = ""
else:
sequences[name] += line
return sequences
def gc_content(sequence):
"""计算GC含量"""
gc_count = sequence.count("G") + sequence.count("C")
seq_len = len(sequence)
return (gc_count / seq_len) * 100
def highest(sequences):
"""找到GC含量最高的序列"""
highest_name = ""
highest_gc = 0
for name, seq in sequences.items():
if gc_content(seq) > highest_gc:
highest_name = name
highest_gc = gc_content(seq)
return highest_name, round(highest_gc, 6)
example = read_fasta("gc_content_example.txt")
name, gc = highest(example)
print(f"{name}\n{gc}")
sequences = read_fasta("rosalind_gc.txt")
name, gc = highest(sequences)
print(f"{name}\n{gc}")
Output
Rosalind_0808
60.91954
Rosalind_9578
51.348039