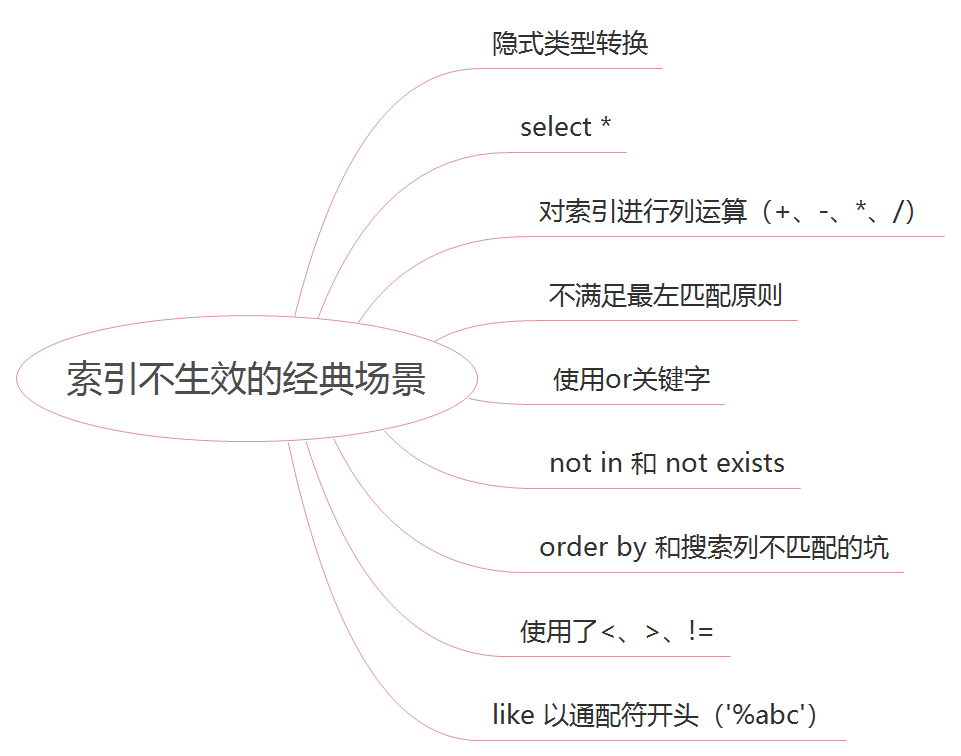
PCL源码剖析 – 欧式聚类
参考:
1. pcl Euclidean Cluster Extraction教程
2. 欧式聚类分析
3. pcl-api源码
4. 点云欧式聚类
5. 本文完整工程地址
可视化结果

一. 理论
聚类方法需要将无组织的点云模型P划分为更小的部分,以便显著减少P的总体处理时间。欧式空间的简单数据聚类方法可以利用固定宽度box的3D网格划分或者一般的八叉树数据结构实现。这种特殊的表征速度快,在体素表征的占据空间。然后,更普遍使用的手段是使用最近邻来实现聚类技术,本质类似于洪水填充(flood fill)算法。
二. 伪码
1. 为点云P 创建KD-Tree的输入表征
2. 创建空的聚类列表C 和 点云的检查队列Q
3. 对于P中的每一个点Pi,执行如下操作:
4. - 将Pi添加到当前队列Q(并标记为已处理);
5. - while处理 Q 中的每一个Pi:
6. - 对Pi进行近邻搜索,查找满足半径 < d 的点集合;
7. - 检查上一步中每一个邻居点,如果标记是未被处理的点,则加入到队列Q中;
8. - 直到Q中的所有点都被标记为已处理,将Q加入到聚类列表C中,将Q重新置为空
9. 当所有的Pi都被处理过之后结束,聚类结果为列表 C
三. 源码分析
3.1 关于主要函数extractEuclideanClusters的一些说明
- 功能说明
根据最大、最小聚类点数,欧式聚类阈值,将点云进行欧式聚类。 - 参数说明
- cloud: 输入点云
- tree: kd-tree
- tolerance: 欧式聚类距离阈值
- clusters: 输出参数,最终聚类结果数组
- min_pts_per_cluster: 每个聚类结果最小点数
- max_pts_per_cluster: 每个聚类结果最大点数
3.2 重点函数extractEuclideanClusters的实现
已为源码添加注释
#include <pcl/segmentation/extract_clusters.h> // 分割模块
#include <pcl/search/organized.h> // for OrganizedNeighbor
//
template <typename PointT> void
pcl::extractEuclideanClusters (const PointCloud<PointT> &cloud,
const typename search::Search<PointT>::Ptr &tree,
float tolerance, std::vector<PointIndices> &clusters,
unsigned int min_pts_per_cluster,
unsigned int max_pts_per_cluster)
{
// 若构建的kd-tree中点数,与输入点云数据点数不同,直接错误打印,并退出
if (tree->getInputCloud ()->size () != cloud.size ())
{
PCL_ERROR("[pcl::extractEuclideanClusters] Tree built for a different point cloud "
"dataset (%zu) than the input cloud (%zu)!\n",
static_cast<std::size_t>(tree->getInputCloud()->size()),
static_cast<std::size_t>(cloud.size()));
return;
}
// 检查kdtree是否经过排序,若结果为true,则不需要检查第一个元素;否则需要检查第一个元素,默认为0
int nn_start_idx = tree->getSortedResults () ? 1 : 0;
// 建立处理队列Q,数目为点数数目,每一个值为false
std::vector<bool> processed (cloud.size (), false);
// nn_indices代表某一个点knn近邻查找,满足距离阈值的点云索引
Indices nn_indices;
std::vector<float> nn_distances;
// 遍历每一个点
for (int i = 0; i < static_cast<int> (cloud.size ()); ++i)
{
// 若该点云被标记为true(处理过),则跳过该点
if (processed[i])
continue;
// 当前某一个聚类的种子队列Q
Indices seed_queue;
int sq_idx = 0; // 种子队列索引
seed_queue.push_back (i); // 将当前点加入种子队列,并标记为true
processed[i] = true;
// 循环处理种子队列Q中的每一个点,进行K近邻查找以及标记工作
while (sq_idx < static_cast<int> (seed_queue.size ()))
{
// 对种子队列中索引的点进行半径距离查找,若半径内没有可查询的点,则索引+1, 跳过后续处理
if (!tree->radiusSearch (seed_queue[sq_idx], tolerance, nn_indices, nn_distances))
{
sq_idx++;
continue;
}
// 半径内有满足条件的点,点云索引保存在nn_indices。遍历这些点,判断是否处理过,若没有处理过,则加入到种子队列Q中
for (std::size_t j = nn_start_idx; j < nn_indices.size (); ++j) // can't assume sorted (default isn't!)
{
// 若该索引为0 或者标记为被处理过之后,则跳过该点
if (nn_indices[j] == UNAVAILABLE || processed[nn_indices[j]]) // Has this point been processed before ?
continue;
// 进行简单的欧式聚类,即将其加入到种子队列中,并标记为true
seed_queue.push_back (nn_indices[j]);
processed[nn_indices[j]] = true;
}
// 跳到队列中下一个需要处理的种子点
sq_idx++;
}
// 当一个聚类结果完成后,若种子队列数目在最大值与最小值之间,则需要将聚类结果加入到聚类列表中
if (seed_queue.size () >= min_pts_per_cluster && seed_queue.size () <= max_pts_per_cluster)
{
pcl::PointIndices r; // PointIndices类中indices是一个vector
r.indices.resize (seed_queue.size ());
// 完成种子队列中索引的赋值操作
for (std::size_t j = 0; j < seed_queue.size (); ++j)
r.indices[j] = seed_queue[j];
// 点云索引值排序和去重,源码注释中表示下面两行可以去掉,并不需要
std::sort (r.indices.begin (), r.indices.end ());
r.indices.erase (std::unique (r.indices.begin (), r.indices.end ()), r.indices.end ());
// 头赋值和点云结果加入到聚类列表中
r.header = cloud.header;
clusters.push_back (r);
}
else
{
// 打印聚类数目超限
PCL_DEBUG("[pcl::extractEuclideanClusters] This cluster has %zu points, which is not between %u and %u points, so it is not a final cluster\n",
seed_queue.size (), min_pts_per_cluster, max_pts_per_cluster);
}
}
}
四. 应用
测试数据table_scene_lms400.pcd 下载
应用完整工程地址
分析:应用整体流程经历了下采样,使用平面模型分割桌面,过滤多个平面;对剩余点云进行欧式聚类,欧式聚类结果可视化。
#include <pcl/ModelCoefficients.h>
#include <pcl/point_types.h>
#include <pcl/io/pcd_io.h>
#include <pcl/filters/extract_indices.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/features/normal_3d.h>
#include <pcl/kdtree/kdtree.h>
#include <pcl/sample_consensus/method_types.h>
#include <pcl/sample_consensus/model_types.h>
#include <pcl/segmentation/sac_segmentation.h>
#include <pcl/segmentation/extract_clusters.h>
#include<pcl/visualization/pcl_visualizer.h>
bool isPushSpace = false;
//键盘事件
void keyboard_event_occurred(const pcl::visualization::KeyboardEvent& event, void * nothing)
{
if (event.getKeySym() == "space" && event.keyDown())
{
isPushSpace = true;
}
}
int main(int argc, char** argv)
{
// 从PCD文件中读取点云数据
pcl::PCDReader reader;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>), cloud_f(new pcl::PointCloud<pcl::PointXYZ>);
reader.read("../../../data/table_scene_lms400.pcd", *cloud);
std::cout << "PointCloud before filtering has: " << cloud->points.size() << " data points." << std::endl; //*
pcl::visualization::PCLVisualizer viewer("Cluster Extraction");
// 注册键盘事件
viewer.registerKeyboardCallback(&keyboard_event_occurred, (void*)NULL);
int v1(1);
int v2(2);
viewer.createViewPort(0, 0, 0.5, 1, v1);
viewer.createViewPort(0.5, 0, 1, 1, v2);
// 使用下采样,分辨率 1cm
pcl::VoxelGrid<pcl::PointXYZ> vg;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_filtered(new pcl::PointCloud<pcl::PointXYZ>);
vg.setInputCloud(cloud);
vg.setLeafSize(0.01f, 0.01f, 0.01f);
vg.filter(*cloud_filtered);
std::cout << "PointCloud after filtering has: " << cloud_filtered->points.size() << " data points." << std::endl; //*
viewer.addPointCloud(cloud, "cloud1", v1);
viewer.addPointCloud(cloud_filtered, "cloud2", v2);
//渲染10秒再继续
viewer.spinOnce(10000);
// 创建平面分割对象
pcl::SACSegmentation<pcl::PointXYZ> seg;
pcl::PointIndices::Ptr inliers(new pcl::PointIndices);
pcl::ModelCoefficients::Ptr coefficients(new pcl::ModelCoefficients);
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_plane(new pcl::PointCloud<pcl::PointXYZ>());
pcl::PCDWriter writer;
seg.setOptimizeCoefficients(true);
seg.setModelType(pcl::SACMODEL_PLANE);
seg.setMethodType(pcl::SAC_RANSAC);
seg.setMaxIterations(100);
seg.setDistanceThreshold(0.02);
// 把点云中所有的平面全部过滤掉,重复过滤,直到点云数量小于原来的0.3倍
int i = 0, nr_points = (int)cloud_filtered->points.size();
while (cloud_filtered->points.size() > 0.3 * nr_points)
{
// Segment the largest planar component from the remaining cloud
seg.setInputCloud(cloud_filtered);
seg.segment(*inliers, *coefficients);
if (inliers->indices.size() == 0)
{
std::cout << "Could not estimate a planar model for the given dataset." << std::endl;
break;
}
// Extract the planar inliers from the input cloud
pcl::ExtractIndices<pcl::PointXYZ> extract;
extract.setInputCloud(cloud_filtered);
extract.setIndices(inliers);
extract.setNegative(false);
// Write the planar inliers to disk
extract.filter(*cloud_plane);
std::cout << "PointCloud representing the planar component: " << cloud_plane->points.size() << " data points." << std::endl;
// Remove the planar inliers, extract the rest
extract.setNegative(true);
extract.filter(*cloud_f);
//更新显示点云
viewer.updatePointCloud(cloud_filtered, "cloud1");
viewer.updatePointCloud(cloud_f, "cloud2");
//渲染3秒再继续
viewer.spinOnce(3000);
cloud_filtered = cloud_f;
}
viewer.removePointCloud("cloud2", v2);
/// 创建KdTree对象作为搜索方法
pcl::search::KdTree<pcl::PointXYZ>::Ptr tree(new pcl::search::KdTree<pcl::PointXYZ>);
tree->setInputCloud(cloud_filtered);
/// 欧式聚类
std::vector<pcl::PointIndices> cluster_indices;
pcl::EuclideanClusterExtraction<pcl::PointXYZ> ec;
ec.setClusterTolerance(0.02); // 2cm
ec.setMinClusterSize(100);
ec.setMaxClusterSize(25000);
ec.setSearchMethod(tree);
ec.setInputCloud(cloud_filtered);
ec.extract(cluster_indices);
//遍历抽取结果,将其显示并保存
int j = 0;
for (std::vector<pcl::PointIndices>::const_iterator it = cluster_indices.begin(); it != cluster_indices.end(); ++it)
{
//创建临时保存点云族的点云
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_cluster(new pcl::PointCloud<pcl::PointXYZ>);
//通过下标,逐个填充
for (std::vector<int>::const_iterator pit = it->indices.begin(); pit != it->indices.end(); pit++)
cloud_cluster->points.push_back(cloud_filtered->points[*pit]); //*
//设置点云属性
cloud_cluster->width = cloud_cluster->points.size();
cloud_cluster->height = 1;
cloud_cluster->is_dense = true;
std::cout << "当前聚类 "<<j<<" 包含的点云数量: " << cloud_cluster->points.size() << " data points." << std::endl;
std::stringstream ss;
ss << "cloud_cluster_" << j << ".pcd";
// writer.write<pcl::PointXYZ>(ss.str(), *cloud_cluster, false); //*
j++;
//显示,随机设置不同颜色,以区分不同的聚类
pcl::visualization::PointCloudColorHandlerCustom<pcl::PointXYZ> cluster_color(cloud_cluster, rand()*100 + j * 80, rand() * 50 + j * 90, rand() * 200 + j * 100);
viewer.addPointCloud(cloud_cluster,cluster_color, ss.str(), v2);
viewer.spinOnce(5000);
}
while (!viewer.wasStopped())
{
viewer.spinOnce();
}
return (0);
}