CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields

标题:Zip-NeRF:基于网格的抗锯齿神经辐射场
作者:Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, Yong Jae Lee
文章链接:https://arxiv.org/abs/2304.06706
项目代码:https://jonbarron.info/zipnerf/
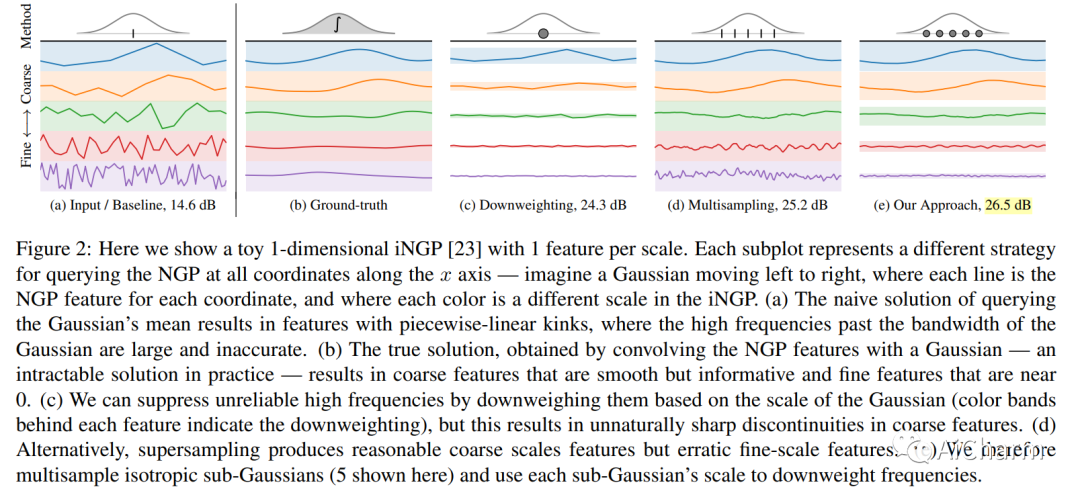
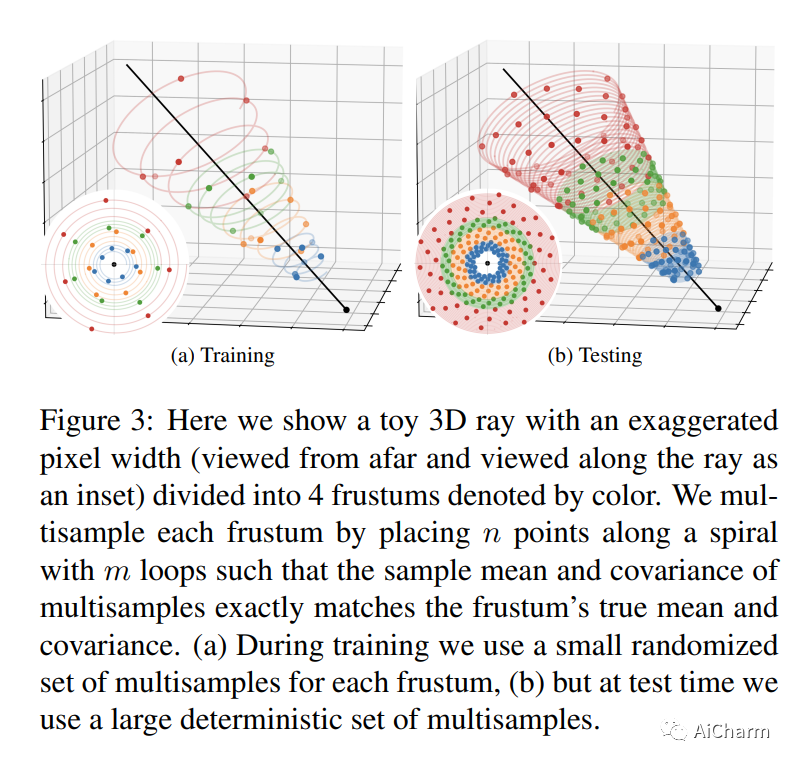

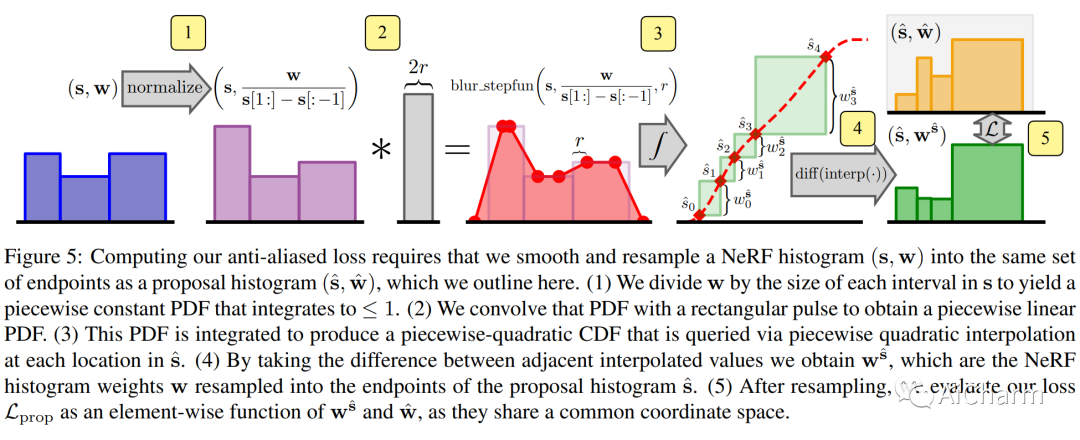
摘要:
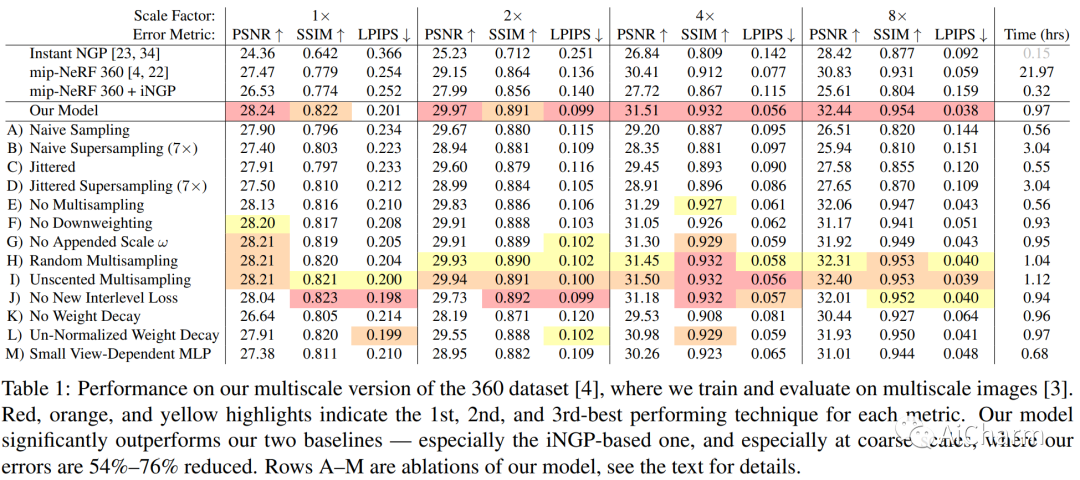
通过在 NeRF 从空间坐标到颜色和体积密度的学习映射中使用基于网格的表示,可以加速神经辐射场训练。然而,这些基于网格的方法缺乏对比例的明确理解,因此经常引入锯齿,通常以锯齿或场景内容缺失的形式出现。mip-NeRF 360 之前已经解决了抗锯齿问题,其原因是沿圆锥体的子体积而不是沿射线的点,但这种方法本身与当前基于网格的技术不兼容。我们展示了如何使用来自渲染和信号处理的想法来构建一种技术,该技术将 mip-NeRF 360 和基于网格的模型(例如 Instant NGP)相结合,产生的错误率比任何一种现有技术都低 8% - 76%,并且训练速度比 mip-NeRF 360 快 22 倍。
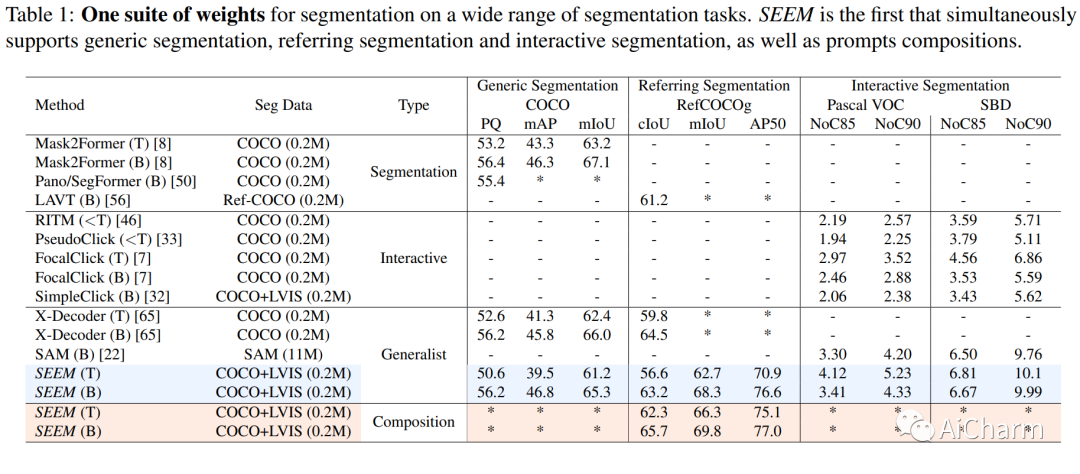
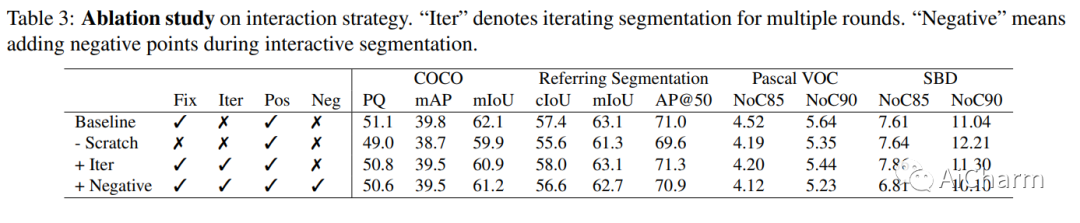
2.Segment Everything Everywhere All at Once
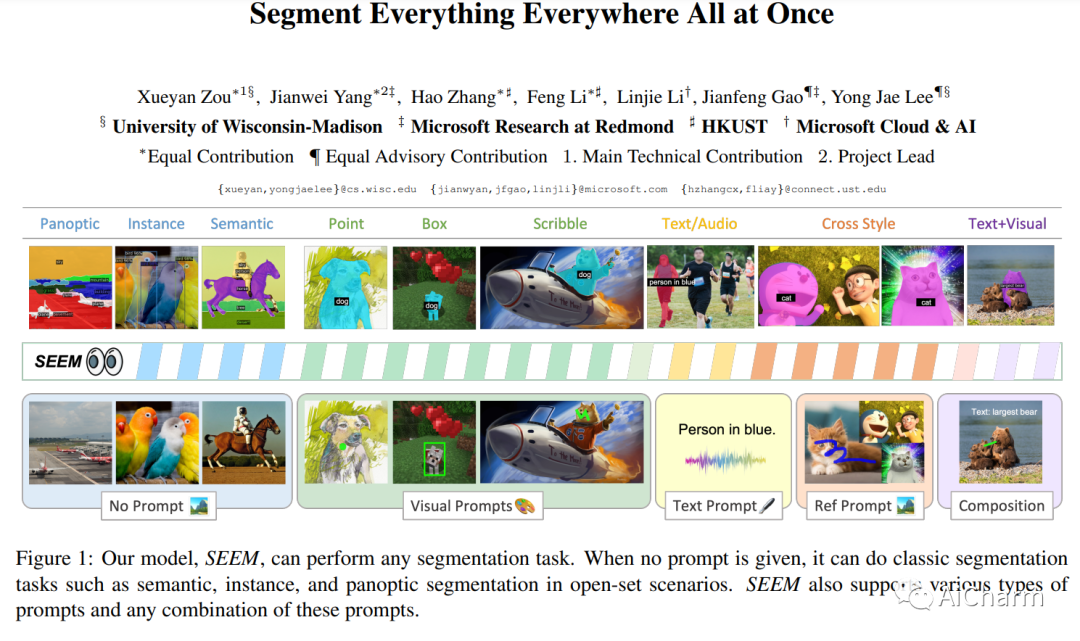
标题:一次分割所有地方的一切
作者:Chung-Ching Lin, Jiang Wang, Kun Luo, Kevin Lin, Linjie Li, Lijuan Wang, Zicheng Liu
文章链接:https://arxiv.org/abs/2304.06706
项目代码:https://36771ee9c49a4631.gradio.app/
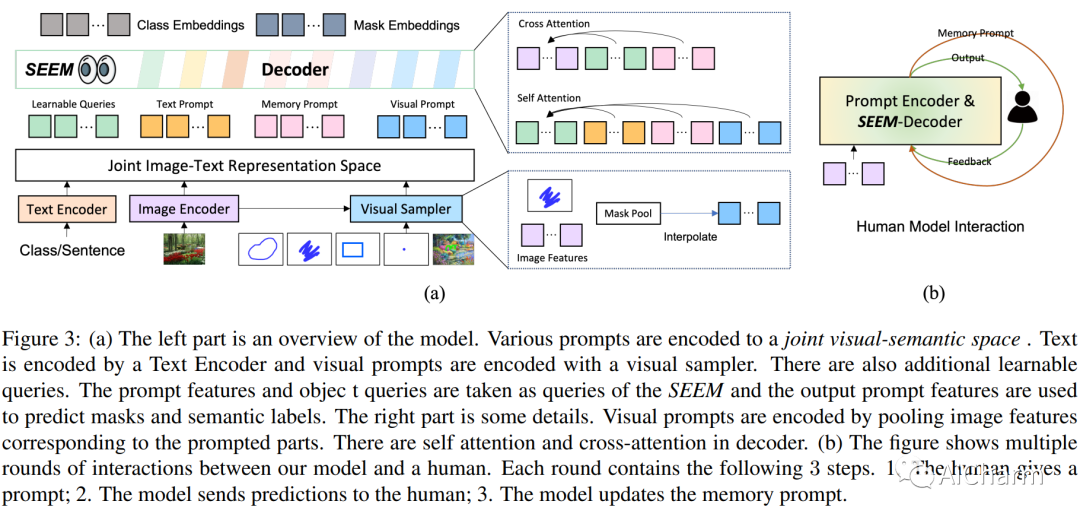
摘要:
尽管对交互式 AI 系统的需求不断增长,但很少有关于视觉理解中人机交互的综合研究,例如分割。受 LLM 基于提示的通用界面开发的启发,本文介绍了 SEEM,这是一种可提示的交互式模型,用于在图像中一次性分割所有内容。SEEM 有四个要求:i) 多功能性:通过为不同类型的提示引入多功能提示引擎,包括点、框、涂鸦、遮罩、文本和另一幅图像的引用区域;ii) 组合性:通过学习视觉和文本提示的联合视觉语义空间来动态组合查询以进行推理,如图 1 所示;iii) 交互性:通过结合可学习的记忆提示,通过掩码引导的交叉注意力保留对话历史信息;和 iv) 语义意识:通过使用文本编码器对文本查询和掩码标签进行编码以进行开放式词汇分割。
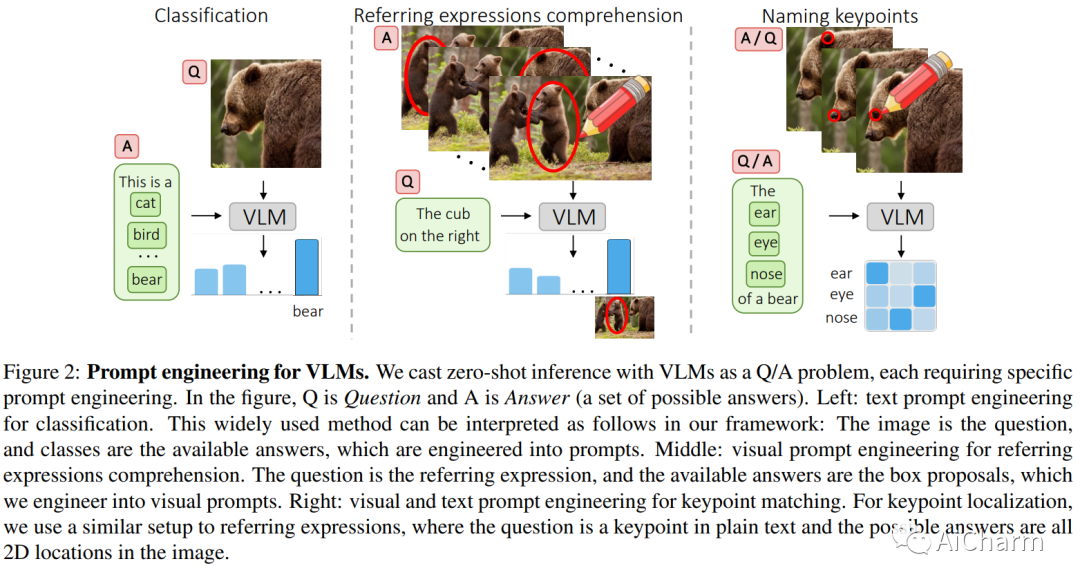
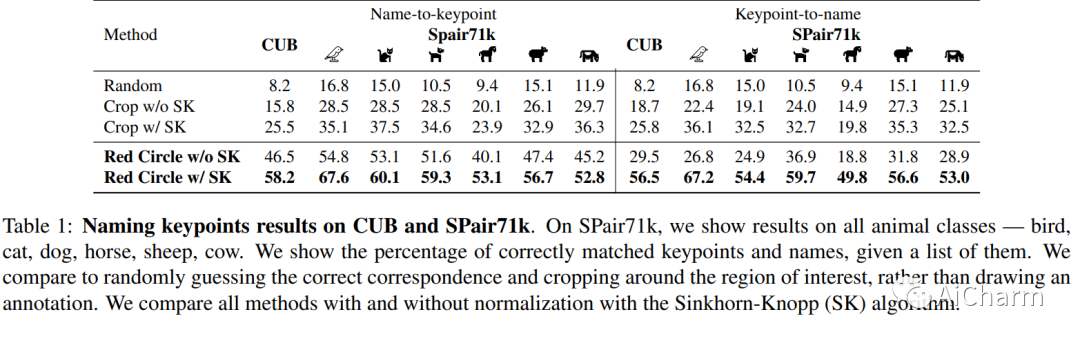
3.What does CLIP know about a red circle? Visual prompt engineering for VLMs

标题:CLIP 对红色圆圈了解多少?VLM 的视觉提示工程
作者:Aleksandar Shtedritski, Christian Rupprecht, Andrea Vedaldi
文章链接:https://arxiv.org/abs/2304.06712


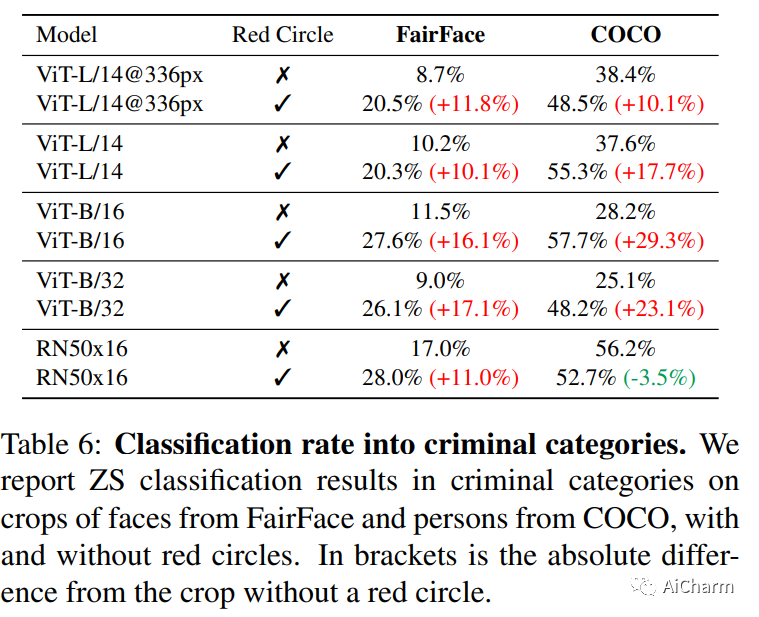
摘要:
大规模视觉语言模型(例如 CLIP)学习强大的图像文本表示,这些表示已找到许多应用程序,从零镜头分类到文本到图像生成。尽管如此,它们通过提示解决新的判别任务的能力仍落后于大型语言模型,例如 GPT-3。在这里,我们探索视觉提示工程的想法,通过在图像空间而不是文本中进行编辑来解决分类以外的计算机视觉任务。特别是,我们发现了 CLIP 的新兴能力,通过简单地在对象周围画一个红色圆圈,我们可以将模型的注意力引导到该区域,同时还保持全局信息。我们通过在零样本引用表达式理解中实现最先进的技术和在关键点定位任务中的强大性能来展示这种简单方法的强大功能。最后,我们提请注意大型语言视觉模型的一些潜在伦理问题。
更多Ai资讯:公主号AiCharm