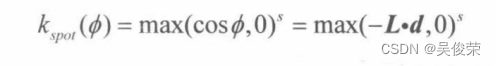AIGC之文生视频及实践应用
(一)序言
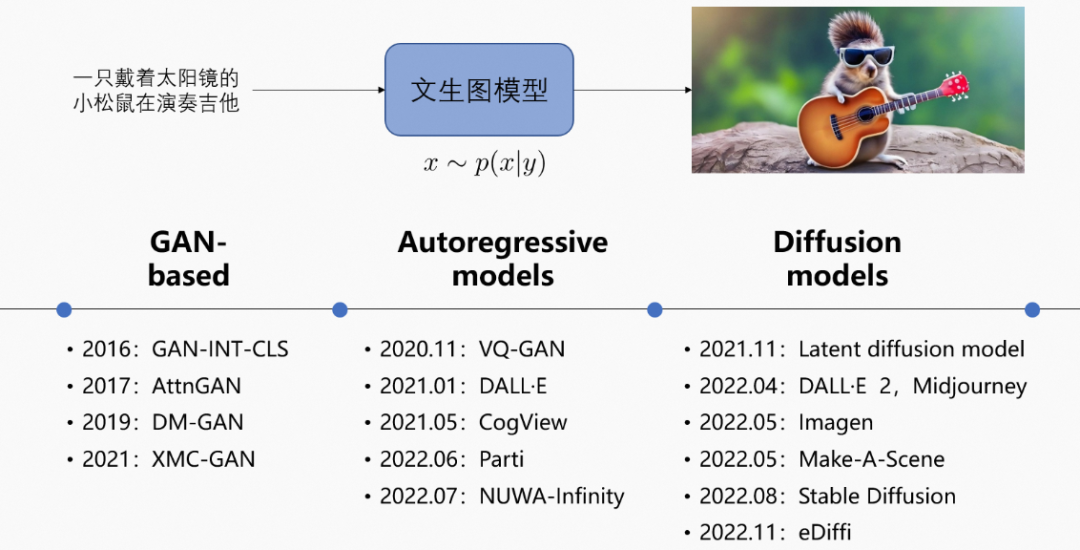
从 Stable Diffusion 到 Midjourney,再到 DALL·E-2,文生图模型已经变得非常流行,并被更广泛的受众使用。随着对多模态模型的不断拓展以及生成式 AI 的研究,业内近期的工作试图通过在视频领域重用文本到图像的扩散模型,将其成功扩展到文本到视频的生成和编辑任务中,使得用户能够仅仅给出提示便能得到想要的完整视频。
早期的文生图方法依赖于基于模板的生成和特征匹配等方法。然而,这些方法生成逼真和多样化图像的能力有限。在 GAN 获得成功之后,还提出了其他几种基于深度学习的文生图方法。其中包括 StackGAN、AttnGAN 和 MirrorGAN,它们通过引入新的架构和增强机制进一步提高了图像质量和多样性。
后来,随着 Transformer 的进步,出现了新的文生图方法。例如,DALL·E-2 是一个 120 亿参数的变换器模型:首先,它生成图像令牌,然后将其与文本令牌组合,用于自回归模型的联合训练。之后,Parti 提出了一种生成具有多个对象的内容丰富的图像的方法。Make-a-Scene 则通过文生图生成的分割掩码实现控制机制。现在的方法建立在扩散模型的基础上,从而将文生图的合成质量提升到一个新的水平。GLIDE 通过添加无分类器引导改进了 DALL·E。后来,DALL·E-2 利用了对比模型 CLIP:通过扩散过程,从 CLIP 文本编码到图像编码的映射,以及获得 CLIP 解码器……
这些模型能够生成具有高质量的图像,因此研究者将目光对准了开发能够生成视频的文生图模型。然而,文生视频现在还是一个相对较新的研究方向。现有方法尝试利用自回归变换器和扩散过程进行生成。
例如,NUWA 引入了一个 3D 变换器编码器-解码器框架,支持文本到图像和文本到视频的生成。Phenaki 引入了一个双向掩蔽变换器和因果关注机制,允许从文本提示序列生成任意长度的视频;CogVideo 则通过使用多帧速率分层训练策略来调整 CogView 2 文生图模型,以更好地对齐文本和视频剪辑;VDM 则联合训练图像和视频数据自然地扩展了文生图扩散模型。
前面展示的 Imagen Video 构建了一系列视频扩散模型,并利用空间和时间超分辨率模型生成高分辨率时间一致性视频。Make-A-Video 在文本到图像合成模型的基础上,以无监督的方式利用了视频数据。Gen-1 则是扩展了 Stable Diffusion 并提出了一种基于所需输出的视觉或文本描述的结构和内容引导的视频编辑方法。
如今,越来越多的文生视频模型不断迭代,我们可以看到,2023 年似乎将要成为 “文生视频” 的一年。
(二)常见算法框架
(1)文本特征提取 + 文本特征到视频隐空间扩散模型 + 视频隐空间到视频视觉空间网络
- 整体模型参数约17亿。支持英文输入。
- 扩散模型采用Unet3D结构,通过从纯高斯噪声视频中,迭代去噪的过程,实现视频生成的功能。
(三)研究里程碑
| 时间 | 所属机构 | 描述 | 体验地址 |
|---|---|---|---|
| 2022年9月29日 | Meta | 公布文生视频工具Make-A-Video,这个工具可以把文字生成视频,也可以将静态图片生成连续图片,然后将这些图片连接成一段视频。 | |
| 2022年10月 | 发布了两个文生视频工具——Imagen Video 与 Phenaki,前者主打视频品质,后者主要挑战视频长度。目前,Imagen Video 可以生成1280x768分辨率、每秒24帧的高清晰片段,而Phenaki可以实现“有故事、有长度”,它生成任意时间长度的视频能力来源于其新编解码器C-ViViT。 | ||
| 2023年2月6日 | Runway | 发布 Gen-1 模型,这个模型可以通过应用文本提示或者参考图像所指定的任意风格,将现有视频转换为新视频。今年的奥斯卡将7项大奖颁给了《瞬息全宇宙》,在影片的制作过程中,就采用了这家公司的技术。 | https://runwayml.com/ |
| 2023年3月21日 | Runway | 发布了Gen-2,更专注于从零开始生成视频。 | |
| 2023年3月22日 | 阿里达摩院 | 在AI模型社区“魔搭”(ModelScope)悄悄放出 “文本生成视频大模型”,在开源模型平台低调对外测试; | |
| 2023年3月16日 | 百度 | 发布文心一言也提供文字生成视频功能。 |
(四)当前挑战
(1)要解决AI生成的图像没有闪烁感、更连贯;
(2)要解决时间效率与算力资源问题。
(3)可能被用来生成虚假、仇恨、露骨或有害的内容,信任与安全等问题也逐渐涌现。
目前将文本生成图像,在高端GPU上,每张图像渲染的时间大约为几秒到十几秒,视频如果按照每秒30帧计算,那么一秒钟的视频就需要几分钟的渲染时间,大大限制其适用场景。这需要硬件技术和算法共同进化解决。
美国麻省理工学院人工智能教授菲利普·伊索拉就表示,如果看到高分辨率的视频,人们很可能会相信它。 也有专家指出,随着人工智能语音匹配的出现,以及逐渐拥有改变和创建几乎触手可及的逼真视频的能力,伪造公众人物和社会大众的言行可能会造成不可估量的伤害。但是,“潘多拉的魔盒已经打开”,作为生成式 AI 的下一站,文生视频的技术需要不断改进,与此同时,依然需要警惕安全与伦理风险。
(五)最新研究进展
- AI作画玩腻了?国产AI文生视频又来了,就是画风有点辣眼睛|封面天天见
- AI大模型下一站:“文生视频”还有多远?|图像|AI|Meta
- AIGC下一站:期待、警惕充斥着AI剪辑师的世界-钛媒体官方网站