brief

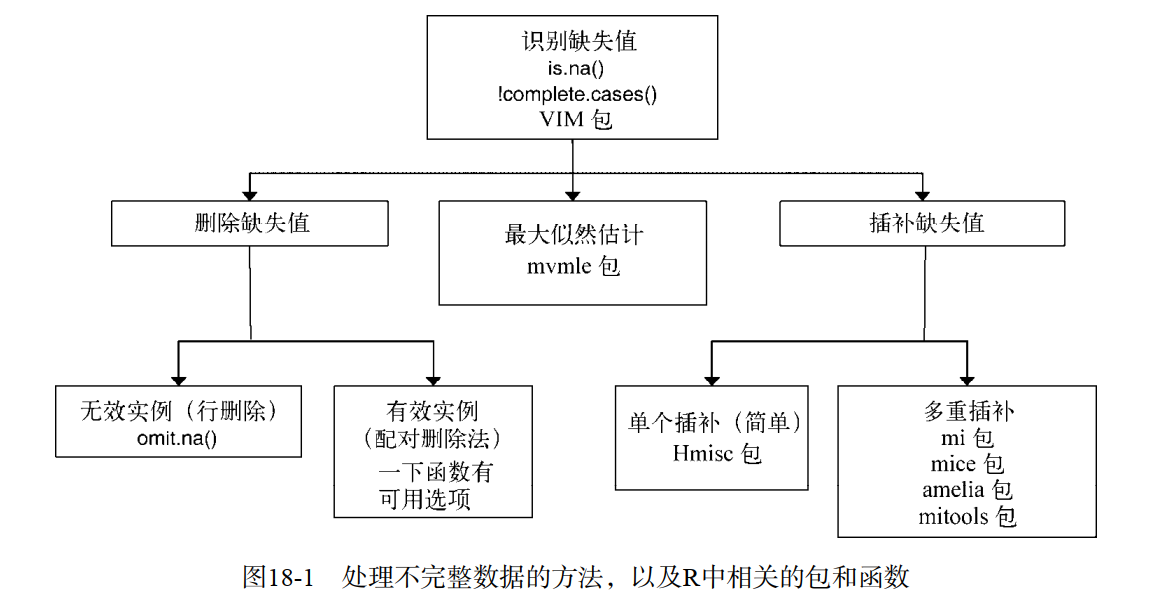
识别缺失值

- 当传入向量,返回的是包含逻辑向量的等长向量。
- complete.cases()用来识别矩阵或者数据框有没有包含缺失值的行,若整行数据完整则返回TRUE,若行数据包含缺失值,不管几个缺失值则返回FALSE。

探索缺失值模式
列表+图形展示缺失值
library(mice)
library(VIM)
data(sleep, package="VIM")
md.pattern(sleep,rotate.names = TRUE)
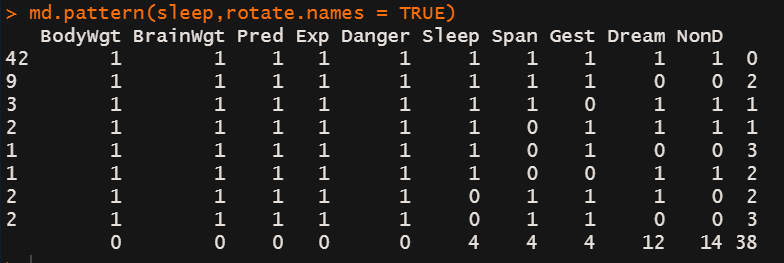

如何理解输出的数据框:1代表未缺失,0代表缺失
- 最左边的一列要和最右侧的一列一起看:
有42个观测缺失0个变量
有9个观测缺失2个变量
有3个观测缺失1个变量
有2个观测缺失1个变量
… - 最下面一行表示每个变量缺失的个数
sleep变量缺失个4个数据
span变量缺失了4个数据
…
总共缺失了38个数据
纯图形探索缺失值
library(VIM)
data(sleep, package="VIM")
aggr(sleep, prop=FALSE, numbers=TRUE) # vim 包
aggr(sleep, prop=TRUE, numbers=TRUE) # 数字变成比例

- 右边barplot表示哪些变量缺失的数值个数
- 左边的图每一行的cell颜色区分是否有缺失值,最下面表示42个完整的观测
NonD+Dream 变量同时缺失的有9个观测
Geet变量缺失4次,仅仅缺失Geet变量的只有3个观测
…
用相关性探索缺失值
x <- as.data.frame(abs(is.na(sleep))) #生成影子矩阵,缺失值为1,未缺失值为0
y <- x[which(apply(x,2,sum)>0)]
cor(y)
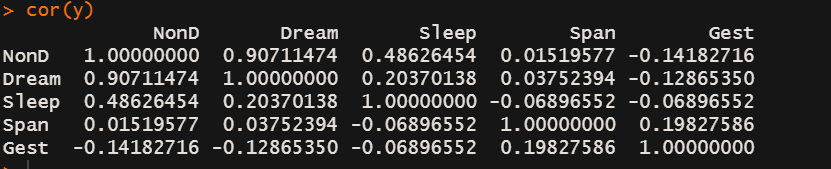
- 相关性系数越大,说明同时缺失的频率越高
理解数据的缺失原因和影响

处理缺失值的几种方法
推理法
- 比如某几个变量之间具有线性关系,缺失的那个可以用其他几个变量推算出来
比如,年龄缺失,可以用出生日期推算
比如,性别缺失,用性别偏向的名字也可以推算
行删除


插补法
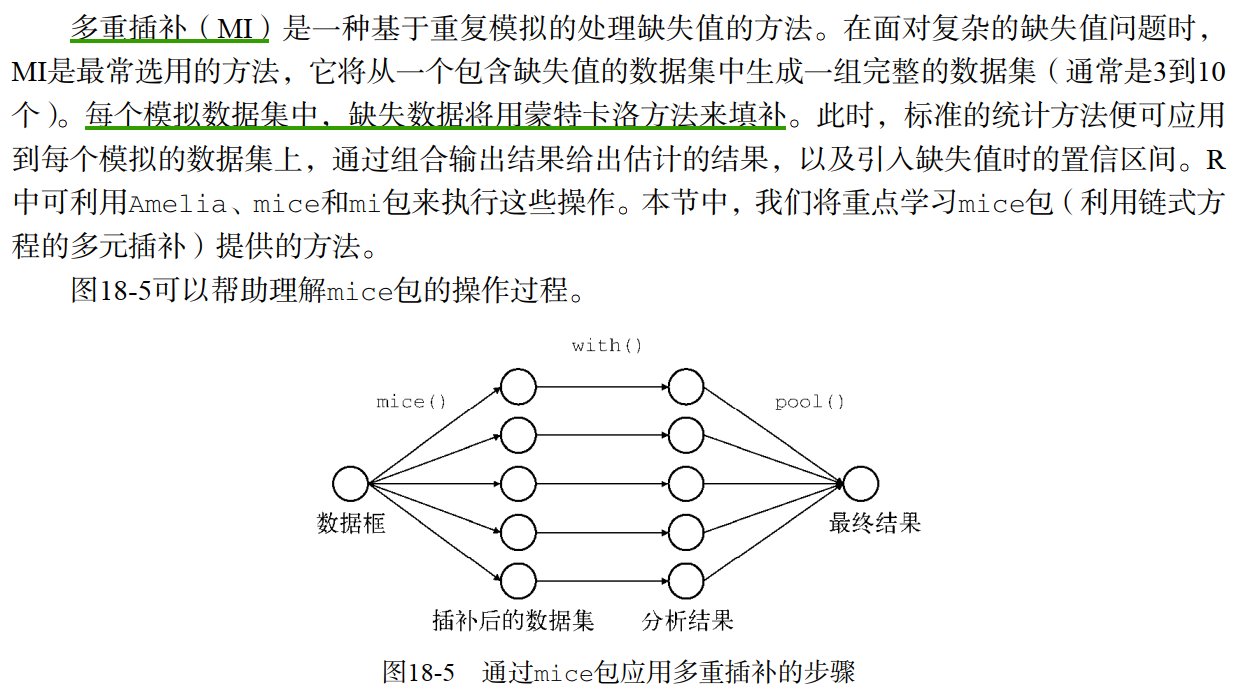


其他方法
- 成对删除
只有用到这个观测 的变量有缺失时才会被剔除,用到这个观测其他变量时并不会删除。
cor(sleep, use="pairwise.complete.obs")

- 简单插补法
就是用均值、中位数、众数等固定值替代缺失值