学习记录,自用。
1. 下载数据集
点击以下链接下载种子文件,然后使用迅雷进行下载,仅下载勾选的文件即可。
https://hyper.ai/datasets/4889/c107755f6de25ba43c190f37dd0168dbd1c0877e
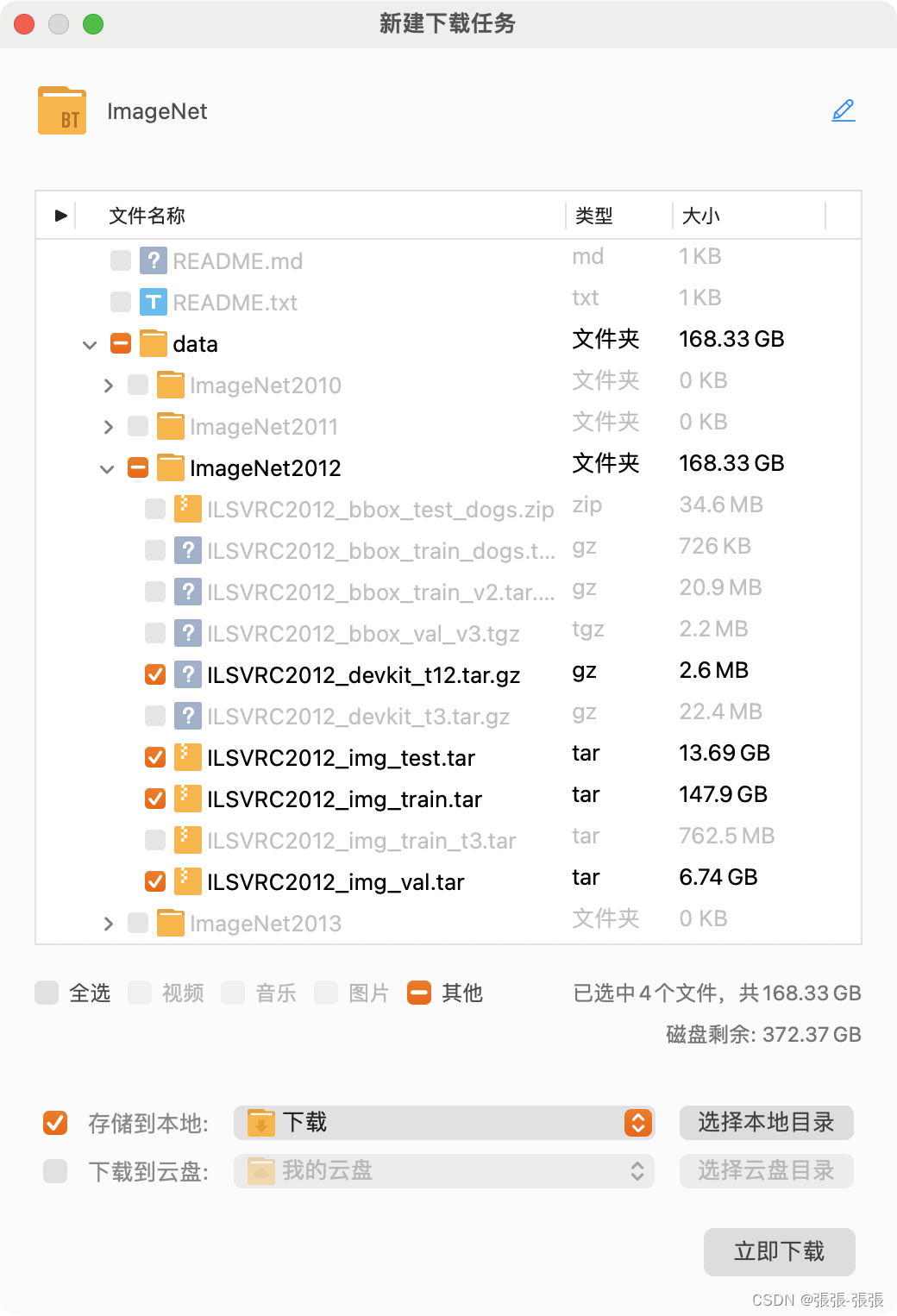
2. 解压
找到下载好的ILSVRC2012_img_train.tar 和 ILSVRC2012_img_val.tar
创建两个用于放训练集和测试集的文件夹⬇️
mkdir train
mkdir val解压文件⬇️
tar xvf ILSVRC2012_img_train.tar -C ./train
tar xvf ILSVRC2012_img_val.tar -C ./valILSVRC2012_img_train.tar解压后为1000个tar压缩包,对应1000类别,需要再次解压,
解压脚本(先创建txt文件,粘贴下面代码,最后保存为.sh文件)⬇️
#!/bin/bash
# 遍历所有以.tar结尾的文件,进行解压
for x in *.tar
do
# 获取文件名(不包括.tar后缀)
filename=$(basename "$x" .tar)
# 创建目录并解压文件
mkdir "$filename"
tar -xvf "$x" -C "$filename"
done
# 删除原来的tar文件
rm *.tar执行脚本之后,就获得了1000个文件夹(每个文件夹对应一种类别)。
目前,已经把所有的 JPEG 图片搞了出来。
3.数据标签
对于训练集,同一类别的数据在同一文件夹下;
验证集没有标签,需要进行处理,下面的步骤都是对验证集标签的处理。
验证集的标签在 Development kit(ILSVRC2012_devkit_t12.tar.gz),
解压ILSVRC2012_devkit_t12.tar.gz⬇️
tar -xvf ILSVRC2012_devkit_t12.tar.gz解压后得到ILSVRC2012_devkit_t12文件夹,在ILSVRC2012_devkit_t12\data\ILSVRC2012_validation_ground_truth.txt找到验证集对应的标签。
之后,在imagenet目录(devkit和val的根目录下)创建并运行如下 python 脚本
from scipy import io
import os
import shutil
def move_valimg(val_dir='./ILSVRC2012_img_val', devkit_dir='./ILSVRC2012_devkit_t12'):
"""
move valimg to correspongding folders.
val_id(start from 1) -> ILSVRC_ID(start from 1) -> WIND
organize like:
/val
/n01440764
images
/n01443537
images
.....
"""
# load synset, val ground truth and val images list
synset = io.loadmat(os.path.join(devkit_dir, 'data', 'meta.mat'))
ground_truth = open(os.path.join(devkit_dir, 'data', 'ILSVRC2012_validation_ground_truth.txt'))
lines = ground_truth.readlines()
labels = [int(line[:-1]) for line in lines]
root, _, filenames = next(os.walk(val_dir))
for filename in filenames:
# val image name -> ILSVRC ID -> WIND
val_id = int(filename.split('.')[0].split('_')[-1])
ILSVRC_ID = labels[val_id-1]
WIND = synset['synsets'][ILSVRC_ID-1][0][1][0]
print("val_id:%d, ILSVRC_ID:%d, WIND:%s" % (val_id, ILSVRC_ID, WIND))
# move val images
output_dir = os.path.join(root, WIND)
if os.path.isdir(output_dir):
pass
else:
os.mkdir(output_dir)
shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))
if __name__ == '__main__':
move_valimg()如果在运行脚本的时候报错,大概率是ILSVRC2012_img_val有非jpeg文件,将其移出即可;
我这里有两个其他文件,使用迅雷下载时产生的额外文件,我执行了一下命令将其移出。
mv .5d6d0df7ed81efd49ca99ea4737e0ae5e3a5f2e5.torrent ..
mv .5D6D0DF7ED81EFD49CA99EA4737E0AE5E3A5F2E5.js ..如何还有其他报错,可以自行调试代码。
4.数据加载
使用 torchvision.datasets.ImageFolder() 就可以直接加载处理好的数据集
import os
import torch
import torchvision.datasets as datasets
root = 'data/imagenet'
def get_imagenet(root, train = True, transform = None, target_transform = None):
if train:
root = os.path.join(root, 'train')
else:
root = os.path.join(root, 'val')
return datasets.ImageFolder(root = root,
transform = transform,
target_transform = target_transform)